kubernetes (k8s)容器编排系统
Kubernetes作为容器编排生态圈中重要一员,是Google大规模容器管理系统borg的开源版本实现,吸收借鉴了google过去十年间在生产环境上所学到的经验与教训。 Kubernetes提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用。当前Kubernetes支持GCE、vShpere、CoreOS、OpenShift、Azure等平台,除此之外,也可以直接运行在物理机上.kubernetes是一个开放的容器调度管理平台,不限定任何一种言语,支持java/C++/go/python等各类应用程序 。
kubernetes是一个完备的分布式系统支持平台,支持多层安全防护、准入机制、多租户应用支撑、透明的服务注册、服务发现、内建负载均衡、强大的故障发现和自我修复机制、服务滚动升级和在线扩容、可扩展的资源自动调度机制、多粒度的资源配额管理能力,完善的管理工具,包括开发、测试、部署、运维监控,一站式的完备的分布式系统开发和支撑平台。
一. 系统架构
kubernetes系统按节点功能由master和node组成。
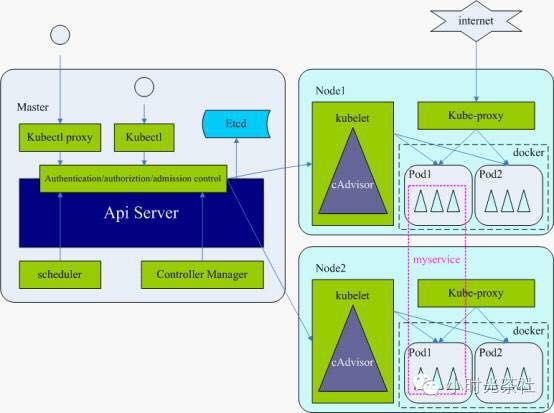
Master
Master作为控制节点,调度管理整个系统,包含以下组件:
API Server作为kubernetes系统的入口,封装了核心对象的增删改查操作,以RESTful接口方式提供给外部客户和内部组件调用。它维护的REST对象将持久化到etcd。
Scheduler:负责集群的资源调度,为新建的pod分配机器。这部分工作分出来变成一个组件,意味着可以很方便地替换成其他的调度器。
Controller Manager:负责执行各种控制器,目前有两类:
- Endpoint Controller:定期关联service和pod(关联信息由endpoint对象维护),保证service到pod的映射总是最新的。
- Replication Controller:定期关联replicationController和pod,保证replicationController定义的复制数量与实际运行pod的数量总是一致的。
Node
Node是运行节点,运行业务容器,包含以下组件:
Kubelet:责管控docker容器,如启动/停止、监控运行状态等。它会定期从etcd获取分配到本机的pod,并根据pod信息启动或停止相应的容器。同时,它也会接收apiserver的HTTP请求,汇报pod的运行状态。
Kube Proxy:负责为pod提供代理。它会定期从etcd获取所有的service,并根据service信息创建代理。当某个客户pod要访问其他pod时,访问请求会经过本机proxy做转发。
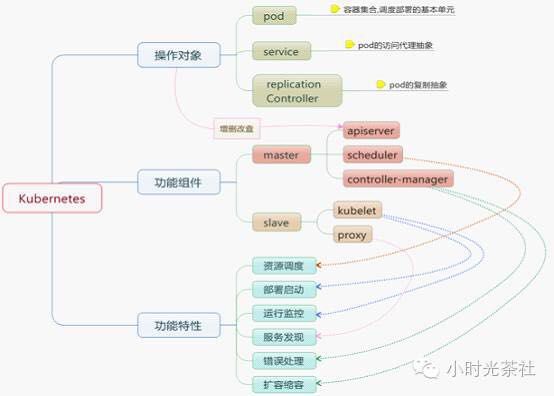
借用一张网图,表达功能组件之间关系:
二.基本概念
Node
node是kubernetes集群中相对于master而言的工作主机,在较早版本中也被称为minion。Node可以是一台物理主机,也可以是一台虚拟机(VM)。在每个node上运行用于启动和管理pod的服务——kubelet,并能够被master管理。在node上运行的服务进程包括kubelet、kube-proxy和docker daemon。
Node的信息如下:
node地址:主机的IP地址或者nodeid。
node的运行状态: pending,running,terminated。
node condition: 描述running状态node的运行条件,目前只有一种条件Ready,表示node处于健康状态,可以接收master发来的创建pod的指令。
node系统容量:描述node可用的系统资源,包括CPU、内存、最大可调度pod数量等。
Pod
pod 是 kubernetes 的最基本操作单元,包括一个或多个紧密相关的容器,一个 pod 可以被一个容器化的环境看作应用层的“逻辑宿主机”( Logical host )。一个 pod 中的多个容器应用通常是紧耦合的。Pod 在 node 上被创建、启动或者销毁。
为什么 kubernetes 使用 pod 在容器之上再封装一层呢?一个很重要的原因是,docker 容器之间通信受到 docker 网络机制的限制。在 docker 的,世界中,一个容器需要通过 link 方式才能访问另一个容器提供的服务(端口)。大量容器之间的 link 将是一个非常繁重的工作。通过 pod 的概念将多个容器组合在一个虚拟的“主机”内,可以实现容器之间仅需通过 localhost 就能相互通信了。
一个pod中的应用容器共享一组资源,如:
pid命名空间:pod中的不同应用程序可以看到其他的进程PID
网络命名空间:pod中的多个容器能够访问同一个IP和端口范围
IPC命名空间:pod中的多个容器能够使用systemV ipc 或POSIX消息队列进行通信。
UTS命名空间:pod中的多个容器共享一个主机名。
Volumes(共享存储卷):pod中的各个容器可以访问在pod级别定义的volumes。
Label
label是kubernetes系统中的一个核心概念。Label以key/value键值对的形式附加到各种对象上,如pod、service、RC、Node等。Label定义了这些对象的可识别属性,用来对它们进行管理和选择。Label可以在创建对象时附加到对象上,也可以在对象创建后通过API进行管理。
在为对象定义好label后,其他对象就可以使用label selector来定义其他作用的对象了。
label selector的定义由多个逗号分隔的条件组成: “label”: { “key1”: ”value1”, “key2”: ”value2” }
Resource controller(RC)
Resource controller(RC)是kubernetes系统中的核心概念,用于定义pod副本的数量。在master的Controller manager进程通过RC的定义来完成pod的创建、监控、启停等操作。
根据replication controller的定义,kubernetes能够确保在任意时刻都能运行用户指定的pod“副本”(replica)数量。如果有过多的的pod副本在运行,系统会停掉一些pod;如果运行的pod副本数量太少,系统就会再启动一些pod,总之,通过RC的定义,kubernetes总是保证集群中运行着用户期望副本数量。
Service(服务)
在kubernetes的世界里,虽然每个pod都会被分配一个单独的IP地址,但这个IP地址会随着pod的销毁而消失。这就引出一个问题:如果有一组pod组成一个集群来提供服务,那么如何来访问它们呢?
kubernetes的service就是用来解决这个问题的核心概念。一个service可以看作一组提供相同服务的pod的对外访问接口。Service作用于哪些pod是通过label selector 来定义的。
pod的IP地址是docker daemon根据docker0网桥的IP地址段进行分配的,但service的Cluster IP地址是kubernetes系统中的虚拟IP地址,由系统动态分配。 Service的ClusterIP地址相对于pod的IP地址来说相对稳定,service被创建时即被分配IP地址,在销毁该service之前,这个IP地址都不会再变化。
由于service对象在Cluster IP Range池中分配到的IP只能在内部访问,所以其他pod都可以无障碍地访问到它。但如果这个service作为前端服务,准备为集群外的客户端提供服务,我们就需要给这个服务提供公共IP了。
kubernetes支持两种对外提供服务的service的type定义:nodeport和loadbalancer。
Volume(存储卷)
volume是pod中能够被多个容器访问的共享目录。Kubernetes的volume概念与docker的volume比较类似,但并不完全相同。Kubernetes中的volume与pod生命周期相同,但与容器的生命周期不相关。当容器终止或重启时,volume中的数据也不会丢失。另外,kubernetes支持多种类型的volume,并且一个pod可以同时使用任意多个volume。
(1)EmptyDir:一个EmptyDir volume是在pod分配到Node时创建的。从它的名称就可以看出,它的初始内容为空。在同一个pod中所有容器可以读和写EmptyDir中的相同文件。当pod从node上移除时,EmptyDir中的数据也会永久删除。
(2)hostPath:在pod上挂载宿主机上的文件或目录。通常用于: 容器应用程序生成的日志文件需要永久保存,可以使用宿主机的高速文件系统进行存储; 需要访问宿主机上的docker引擎内部数据结构的容器应用,可以通过定义hostPath为宿主机/var/lib/docker目录,使容器内部应用可以直接访问docker的文件系统。
(3)gcePersistentDick:使用这种类型的volume表示使用谷歌计算引擎(Google Compute Engine, GCE)上永久磁盘(persistent disk,PD)上的文件。与EmptyDir不同,PD上的内容会永久保存,当pod被删除时,PD只是被卸载(unmount),但不会被删除。需要注意的是,你需要先创建一个永久磁盘(PD)才能使用gcePersistentDisk。
(4)awsElasticBlockStore:与GCE类似,该类型的volume使用Amazon提供的Amazon Web Service(AWS)的EBS Volume,并可以挂载到pod中去。需要注意的是,需要先创建一个EBS Volume才能使用awsElasticBlockStore。
(5)nfs:使用NFS(网络文件系统)提供的共享目录挂载到Pod中。在系统中需要一个支行中的NFS系统。
(6)iscsi:使用iSCSI存储设备上的目录挂载到pod中。
(7)glusterfs:使用开源BlusterFS网络文件系统的目录挂载到pod中。
(8)rbd:使用Linux块设备共享存储(Rados Block Device)挂载到pod中。
(9)gitRepo:通过挂载一个空目录,并从GIT库clone一个git repository以供pod使用。
(10)secret:一个secret volume用于为pod提供加密的信息,你可以将定义在kubernetes中的secret直接挂载为文件让pod访问。Secret volume是通过tmfs(内存文件系统)实现的,所以这种类型的volume总是不会持久化的。
(11)persistentVolumeClaim:从PV(persistentVolume)中申请所需的空间,PV通常是种网络存储,如GCEPersistentDisk、AWSElasticBlockStore、NFS、iSCSI等。
Namespace(命名空间)
namespace(命名空间)是kubernetes系统中另一个非常重要的概念,通过将系统内部的对象“分配”到不同的namespace中,形成逻辑上分组的不同项目、小组或用户组,便于不同的分组在共享使用整个集群的资源的同时还能分别管理。
kubernetes集群在启动后,会创建一个名为“default”的namespace。接下来,如果不特别指明namespace,则用户创建的pod、RC、Service都将被系统创建到名为“default”的namespace中。
使用namespace来组织kubernetes的各种对象,可以实现对用户的分组,即“多租户”管理。对不同的租房还可以进行单独的资源配额设备和管理,使得整个集群配置非常灵活、方便。
Annotation(注解)
annotation与label类似,也使用key/value键值对的形式进行定义。Label具有严格的全名规则,它定义的是kubernetes对象的元数据(metadata),并且用于label selector。Annotation则是用户任意定义的“附加”信息,以便于外部工具进行查找。
用annotation来记录的信息包括: build信息、release信息、docker镜像信息等,如时间戳、release id号、PR号、镜像hash值、docker Controller地址等。
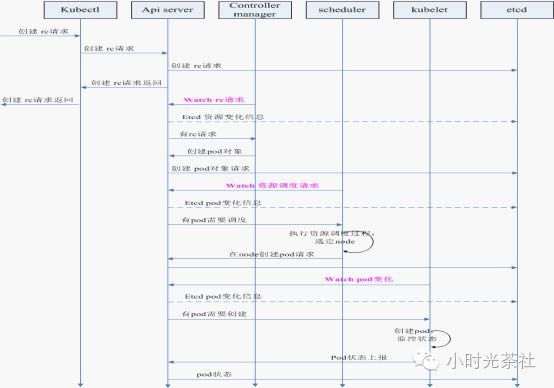
典型流程
以创建一个Pod为例,kubernetes典型的流程如下图所示:
三.组件
Replication Controller
为了区分Controller Manager中的Replication Controller(副本控制器)和资源对象Replication Controller,我们将资源对象简写为RC,而Replication Controller特指“副本控制器”。
Replication Controller的核心作用是确保在任何时间集群中一个RC所关联的pod都保持一定数量的pod副本处于正常运行状态。如果该类pod的pod副本数量太多,则Replication Controller会销毁一些pod副本;反之Replication Controller会添加pod副本,直到该类pod的pod副本数量达到预设的副本数量。最好不要超过RC直接创建pod,因为Replication Controller会通过RC管理pod副本,实现自动创建、补足、替换、删除pod副本,这样就能提高系统的容灾能力,减少由于节点崩溃等意外状况造成的损失。即使应用程序只用到一个pod副本,也强烈建设使用RC来定义pod。
Replication Controller管理的对象是pod,因此其操作与pod的状态及重启策略息息相关。
副本控制器的常用使用模式:
(1)重新调度:不管想运行1个副本还是1000副本,副本控制器能够确保指定pod数量的副本存在于集群中,如果节点故障或副本被终止运行等意外情况,将会重新调度直到达到预期的副本正常运行。
(2)弹性伸缩:手动或通过自动扩容代理修改副本控制器的spec.replicas属性值,非常容易实现扩大或缩小副本的数量。
(3)滚动更新:副本控制器被设计成通过逐个替换pod的方式来辅助服务的滚动更新。推荐的方式是创建一个新的只有一个副本的RC,若新的RC副本数量加1,则旧的RC的副本数量减1,直到这个旧的RC副本数量为零,然后删除该旧的RC。
在滚动更新的讨论中,我们发现一个应用在滚动更新时,可能存在多个版本的release。事实上,在生产环境中一个已经发布的应用程序存在多个release版本是很正常的现象。通过RC的标签选择器,我们能很方便地实现对一个应用的多版本release的跟踪。
node controller
Node Controller负责发现、管理和监控集群中的各个node节点。Kubelet在启动时通过API Server注册节点信息,并定时向API Server发送节点信息。API Server接收到这些信息后,将这些信息写入etcd。存入etcd的节点信息包括节点健康状况、节点资源、节点名称、节点地址信息、操作系统版本、docker版本、kubelet版本等。节点健康状况包含“就绪(true)”、“未就绪(false)”和“未知(unknown)”三种。
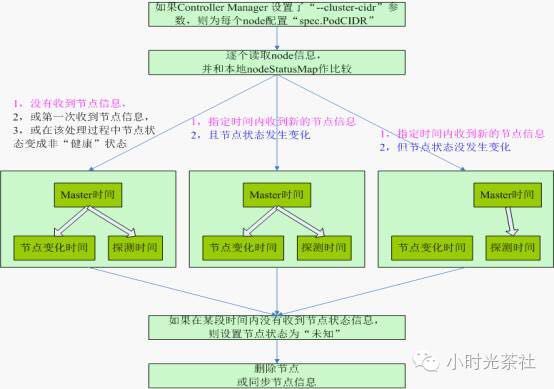
(1)Controller Manager 在启动时如果设置了—cluster-cidr参数,那么为每个没有设置spec.podCIDR的node生成一个CIDR地址,并用该CIDR设置节点的spec.PodCIDR属性,这样的目的是防止不同节点的CIDR地址发生冲突。
(2)逐个读取节点的信息,多次尝试修改nodeStatusMap中的节点状态信息,将该节点信息和node controller的nodeStatusMap中保存的节点信息比较。如果判断中没有收到kubelet发送的节点信息、第一次收到节点kubelet发送的节点信息,或在该处理过程中节点状态变成非“健康”状态,则在nodeStatusMap中保存该节点的状态信息,并用node controller所在节点的系统时间作为探测时间和节点状态变化时间。 如果判断出在某一段时间内没有收到节点的状态信息,则设置节点状态为“未知(unknown)”,并且通过api server保存节点状态。
(3)逐个读取节点信息,如果节点状态变为非“就绪”状态,则将节点加入待删除队列,否则将节点从该队列中删除。如果节点状态为非“就绪”状态,且系统指定了Cloud Provider,则node controller调用Cloud Provider查看节点,若发现并节点故障,则删除etcd中的节点信息,并删除和该节点相关的pod等资源的信息。
ResourceQuota controller
作为容器集群的管理平台, kubernetes也提供了资源配额管理这一高级功能,资源配额管理确保指定的对象在任何时候都不会超量占用系统资源,避免了由于某些业务进程的设计或实现的缺陷导致整个系统运行紊乱甚至意外宕机,对整个集群的平稳运行和稳定性有非常重要的作用。
目前kubernetes支持三个层次的资源配额管理:
(1)容器级别,可以对CPU和内存的资源配额管理。
(2)pod级别,可以对pod内所有容器的可用资源进行限制。
(3)namespace级别,为namespace(可以用于多租户)级别的资源限制,包括:pod数量、replication Controller数量、service数量、ResourceQuota数量、secret数量、可持有的PV(persistent volume)数量。 kubernetes的配额管理是通过准入机制(admission control)来实现的,与配额相关的两种准入控制器是LimitRanger和ResoureQuota,其中LimitRanger作用于pod和container上,ResourceQuota则作用于namespace上。此外,如果定义了资源配额,则scheduler在pod调度过程中也会考虑这一因素,确保pod调度不会超出配额限制。
典型的资源控制流程如下图所示:
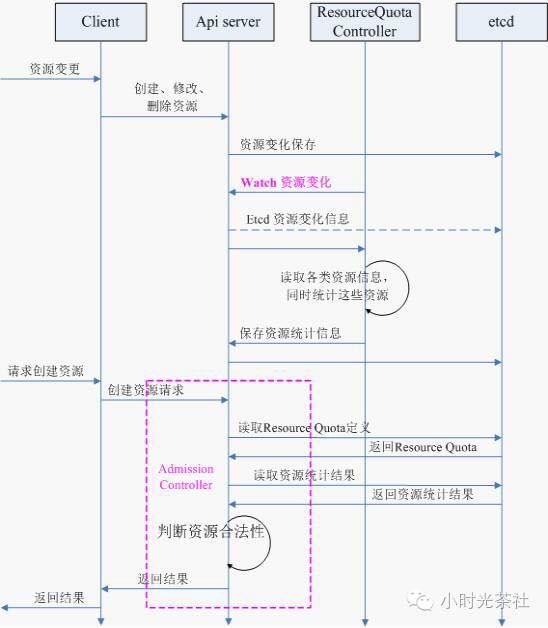
namaspace controller
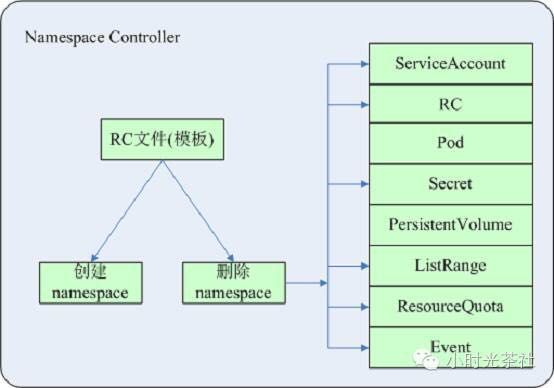
用户通过API Server可以创建新的namespace并保存在etcd中,namespace controller定时通过api server读取这些namespace信息。如果namespace被API标识为优雅删除(设置删除期限,deletionTimestamp属性被设置),则将该namespace的状态设置为“terminating”并保存到etcd中。同时namespace controller删除该namespace下的serviceAccount、RC、Pod、Secret、PersistentVolume、ListRange、SesourceQuota和event等资源对象。 当namespace的状态被设置为“terminating”后,由Adminssion Controller的NamespaceLifecycle插件来阻止为该namespace创建新的资源。同时,在namespace controller删除完该namespace中的所有资源对象后,Namespace Controller对该namespace执行finalize操作,删除namespace的spec.finalizers域中的信息。
如果Namespace Controller观察到namespace设置了删除期限(即DeletionTimestamp属性被设置),同时namespacer 的spec.finalizers域值是空的,那么namespace controller将通过API Server删除该namespace资源。
kubernetes安全控制
ServiceAccount Controller和token Controller是与安全相关的两个控制器。ServiceAccount Controller在Controller Manager启动时被创建。它监听Service Account的删除事件和Namespace的创建、修改事件。如果在该Service Account的namespace中没有default Service Account,那么ServiceAccount Controller为该Service Account的namespace创建一个default ServiceAccount。
在API Server的启动中添加“—admission_control=ServiceAccount”后,API Server在启动时会自己创建一个key和crt(/var/run/kubernetes/apiserver.crt和apiserver.key),然后在启动./kube-controller-manager时添加参数service_account_privatge_key_file=/var/run/kubernetes/apiserver.key,这样启动kubernetes master后,就会发现在创建Service Account时系统会自动为其创建一个secret。
如果Controller Manager在启动时指定参数为service-account-private-key-file,而且该参数所指定的文件包含一个PEM-encoded的编码的RSA算法的私钥,那么,Controler Manager会创建token controller对象。
Token controller
token controller对象监听Service Account的创建、修改和删除事件,并根据事件的不同做不同的处理。如果监听到的事件是创建和修改Service Account事件,则读取该Service Account的信息;如果该Service Account没有Service Account Secret(即用于访问Api server的secret),则用前面提及的私钥为该Service Account创建一个JWT Token,将该Token和ROOT CA(如果启动时参数指定了该 ROOT CA)放入新建的secret中,将该新建的secret放入该Service Account中,同时修改etcd中Service Account的内容。如果监听到的事件是删除Service Account事件,则删除与该Service Account相关的secret。
token controller对象同时监听secret的创建、修改和删除事件,并根据事件的不同做不同的处理。如果监听到的事件是创建和修改secret事件,那么读取该secret中annotation所指定的Service Account信息,并根据需要为该secret创建一个和其Service Account相关的token;如果监听到的事件是删除secret事件,则删除secret和相关的Service Account的引用关系。
service controller&endpoint controller
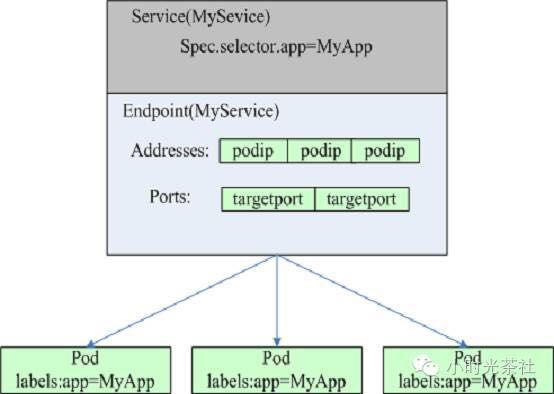
Kubernetes service是一个定义pod集合的抽象,或者被访问都看作一个访问策略,有时也被称为微服务。 kubernetes中的service是种资源对象,各所有其他资源对象一样,可以通过API Server的POST接口创建一个新的实例。在下面的例子代码中创建了一个名为“MyServer”的Service,它包含一个标签选择器,通过该标签选择器选择所有包含标签为“app=MyApp”的pod作为该service的pod集合。Pod集合中的每个pod的80端口被映射到节点本地的9376端口,同时kubernetes指派一个集群IP(即虚拟IP)给该service。
{
“kind”: ”service”,
“apiVersion”: ”v1”,
“metadata”: {
“name”: ”MyService”
},
“spec”: {
“selector”: {
“app”: ”MyApp”
},
“ports”: [
{
“protocol”: ”TCP”,
“port”: 80,
“targetPort”: 9376
}
]
},
}
四.功能特性
Service 集群访问流程(服务发现)
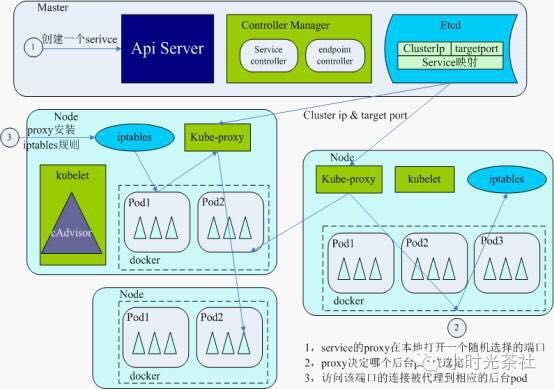
在kubernetes集群中的每个node上都运行着一个叫“kube-proxy”的进程,该进程会观察master节点添加和删除“service”和“endpoint”的行为,如图中第1步所示。
kube-proxy为每个service在本地主机上开一个端口(随机选择)。任何访问该端口的连接都被代理到相应的一个后端pod上。Kube-proxy根据round robin算法及service的session粘连(SessionAffinity)决定哪个后台pod被选中,如第2步所示。
最后,如第3步所示,kube-proxy在本机的iptables中安装相应的规则,这些规则使得iptables将捕获的流量重定向到前面提及的随机端口。通过该端口流量再被kube-proxy转到相应的后端pod上。
在创建了服务后,服务endpoint模型会创建后端pod的IP和端口列表(包含中endpoint对象中),kube-proxy就是从这个endpoint列表中选择服务后端的。集群内的节点通过虚拟IP和端口能够访问service后台的pod。
在默认情况下,kubernetes会为server指定一个集群IP(或虚拟IP、cluster IP),但在某些情况下,希望能够自己指定该集群IP。为了给service指定集群IP,用户只需要在定义service时,在service的spec.clusterIP域中设置所需要的IP地址即可。
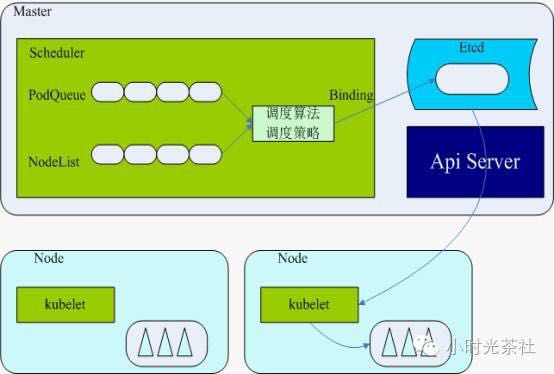
Scheduler(调度)
scheduler在整个kubernetes系统中承担了“承上启下”的重要功能,“承上”是指它负责接收Controller Manager创建的新pod,为其安排一个落脚的“家”——目标node;“启下”是指安置工作完成后,目标node上的kubelet服务进程接管后继工作,负责pod生命周期中的“下半生”。
具体来说,scheduler的作用是将待调度的pod(API新创建的Pod、Controller Manager为补足副本而创建的pod等)按照特定的调度算法和调度策略绑定(binding)到集群中的某个合适的node上,并将绑定信息写入etcd中。在整个调度过程中涉及三个对象,分别是:待调度的pod列表、可用node列表、以及调度算法和策略。简单地说,就是通过调度算法调度,为待调度pod列表中的每个pod从node列表中选择一个最适合的node。
随后,目标node上的kublet通过API Server监听到scheduler产生的pod绑定事件,然后获对应的取pod,下载image镜像,并启动容器。
Scheduler(调度策略)
scheduler当前提供的默认调度流程分为两步:
(1)预选调度过程,即遍历所有目标node,筛选出符合要求的候选节点。为此kubernetes内置了多种预先策略(xxx predicates)供用户选择。
(2)确定最优节点,在第一步的基础上,采用优先策略(xxx priority)计算出每个候选节点的积分,积分最高都胜出。 scheduler的调度流程是通过插件方式加载的“调度算法提供者(AlgorithmProvider)”具体实现的。一个AlgorithmProvider其实就是包括了一组预选策略与一组优选策略的结构体,注册AlgorithmProvider的函数如下: func RegisterAlgorithmProvider(name string, predicateKeys, priorityKeys util.StringSet) 它包含3个参数,name string 参数为算法名;
predicateKeys参数为算法集合用到的预选策略集合 priorityKeys 参数为算法用到的优选策略集合 scheduler 中可用的预选策略包含7个,每个节点只有通过PodFitsPorts、PodFitsResources、NoDiskConflict、PodSelectorMatches、PodFitsHost 5个默认预先策略后,才能初步被选中,进入下一个流程。
每个节点通过优选策略时都会算出一个得分,计算各项得分,最终选出得分值最大的节点作为优选的结果(也是调度算法的结果)。LeastRequestedPriority,选择资源消耗最小节点:
(1)计算出所有备选节点上运行的pod和备选pod的CPU占用量totalMilliCPU
(2)计算出所有备选节点上运行的pod和备选pod的内存占用量totalMomory
(3)计算每个节点的得分,计算规则大致如下: score=int(((nodeCpuCapacity-totalMilliCPU)*10)/nodeCpuCapacity+((nodeMemoryCapacity-totalMemory)*10/nodeMemoryCapacity)/2) CalculateNodeLabelPriority,根据CheckNodeLabelPresence策略打分 BalancedResourceAllocation,选择资源使用最均衡节点
(1)计算出所有备选节点上运行的pod和备选pod的CPU占用量totalMilliCPU
(2)计算出所有备选节点上运行的pod和备选pod的内存占用量totalMomory
(3)计算每个节点的得分,计算规则大致如下: score=int(10-math.abs(totalMilliCPU/nodeCpuCapacity-totalMemory/nodeMemoryCapacity) * 10)
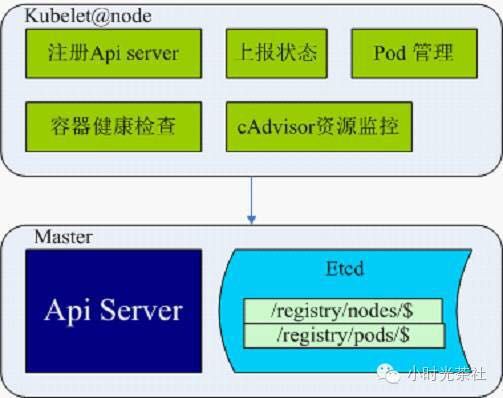
节点管理
节点管理包含节点的注册、状态上报、Pod管理、容器健康检查、资源监控等部分。
节点注册
在kubernetes集群中,在每个node节点上都会启动一个kubelet服务进程。该进程用于处理master节点下发到本节点的任务,管理pod及pod中的容器。每个kubelet进程会在API Server上注册节点自身信息,定期向master节点汇报节点资源使用情况,并通过cAdvisor监控容器和节点资源。
节点通过设置kubelet的启动参数“—register-node”,来决定是否向API Server注册自己。如果该参数为true,那么kubelet将试着通过API Server注册自己。作为自注册,kubelet启动还包含下列参数:
--api-servers,告诉kubelet API Server的位置; --kubeconfig,告诉kubelet在哪儿可以找到用于访问API Server的证书; --cloud-provider,告诉kubelet如何从云服务商(IAAS)那里读取到和自己相关的元数据。
状态上报
kubelet在启动时通过API Server注册节点,并定时向API Server发送节点新消息,API Server在接收到这些信息后,将这些信息写入etcd。通过kubelet的启动参数“—node-status-update-frequency”设置kubelet每隔多少时间向API Server报告节点状态,默认为10秒。
Pod管理
kubelet通过以下几种方式获取自身node上所要运行的pod清单: (1)文件:kubelet启动参数“--config”指定的配置文件目录下的文件。通过—file-check-frequency设置检查该文件目录的时间间隔,默认为20秒。
(2)HTTP端点(URL):通过“—manifest-url”参数设置。通过—http-check-frequency设置检查该HTTP端点的数据时间间隔,默认为20秒。
(3)API Server:kubelet通过API Server监听etcd目录,同步pod清单。
所有以非API Server方式创建的pod都叫作static pod。Kubelet将static pod的状态汇报给API Server,API Server为static pod创建一个mirror pod和其相匹配。Mirror pod的状态将真实反映static pod的状态。当static pod被删除时,与之相对应的mirror pod也会被删除。Kubelet通过API Server client使用watch+list的方式监听“/registry/node/<当前node名称>”和“/registry/pods”目录,将获取的信息同步到本地缓存中。
kubelet监听etcd,所有针对pod的操作将会被kubelet监听到。如果发现有新的绑定到本节点的pod,则按照pod清单的要求创建该pod。如果发现本地的pod被修改,则kubelet会做出相应的修改,如删除pod中的某个容器时,则通过docker client删除该容器。如果发现删除本节点的pod,则删除相应的pod,并通过docker client删除pod中的容器。
kubelet读取监听到的信息,如果是创建和修改pod任务,则做如下处理:
(1)为该pod创建一个数据目录。
(2)从API Server读取该pod清单。
(3)为该pod挂载外部卷(Extenal Volume)。
(4)下载pod用到的secret。
(5)检查已经运行在节点中的pod,如果该 pod没有容器或pause容器没有启动,则先停止pod里所有容器进程。如果在pod中有需要删除的容器,则删除这些容器。
(6)用“kubernetes/pause”镜像为每个pod创建一个容器,该pause容器用于接管pod中所有其他容器的网络。
(7)为pod中的每个容器做如下处理:
为容器计算一个hash值,然后用容器的名字去docker查询对应容器的hash值。若查到容器,且两者hash值不同,则停止docker中容器进程,并停止与之关联的pause容器进程;若两者相同不做任何处理。
如果容器被中止了,且容器没有指定的restartPolicy(重启策略),则不做任何处理。
调用docker client下载容器镜像,调用docker client运行容器。
容器健康检查
pod通过两类探针来检查容器的健康状态。一个是LivenessProbe探针,用于判断容器是否健康,告诉kubelet一个容器什么时候处于不健康的状态。如果LivenessProbe探针探测到容器不健康,则kubelet将删除容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是“success”.另一类是ReadinessProbe探针,用于判断容器是否启动完成,且准备接收请求。如果ReadinessProbe探针检测到失败,则pod的状态将被修改。Endpoint controller将从service的endpoint中删除包含该容器所在pod的IP地址的endpoint条目。
参考
《kubernetes权威指南》