分布式数据库(一) :分布式数据库架构
目录
- 分布式数据库架构
-
- 分布式数据库发展梗概
- 关于数据库文件系统
-
- 了解一下LSM-Tree
- B+Tree VS LSM-Tree
- 第一代分布式数据库——分库分表及分布式中间件
-
- 普通分布式中间件
- 阿里OceanBase数据库
- 第二代分布式数据库——NoSQL
- 第三代分布式数据库——NewSQL
-
- Aurora流派
-
- 华为云Taurus数据库
- 阿里双十一存储引擎X-Engine
- Spanner流派
- 总结
分布式数据库架构
这个系列文章是笔者自己学习分布式数据库的记录,共有两篇,分别是:
(一)分布式数据库架构
(二)分布式数据库事务
本篇是该系列的第一篇,将从分布式的概念出发,阐述笔者理解的分布式数据库三个发展阶段,并分别介绍每个阶段的代表性的数据库及其架构,这些数据库也会在后面对分布式事务的介绍中作为样例分析。
笔者水平有限,如有错误恳请指正。文中的部分图片获取自网络,侵删。
分布式数据库发展梗概
分布式是面向业务扩展而出现的一个概念,而分布式数据库,就是为了解决存储可扩展性的一类数据库。笔者认为除了最初的分库分表方案,分布式数据库经历了三个主要发展阶段。第一代是分布式中间件的形式,大多数是基于MySQL数据库做Data Sharding和水平扩展;第二代是以Cassandra、MongoDB为代表的NoSQL;第三代是以AWS Aurora和Google Spanner为代表的云数据库,或者称作NewSQL。
这三个阶段在分布式这个概念上没有本质上的区别,但是在具体的实现上有不同的侧重点,比如NoSQL就不支持跨分片的ACID事务。大家要注意并不是越新的概念的就越先进,实际上,现在市面上主流的分布式数据库,大多是分布式中间件的形式。
关于数据库文件系统
在具体介绍各类分布式数据库之前,我们先来了解一下在数据库中实际存储数据的数据库文件系统。
目前主流的数据库文件系统有两类,一类是关系型数据库(如MySQL)使用的B+Tree,另一类是多用于键值存储数据库(如NoSQL)的LSM-Tree数据结构。分布式数据库建立在分布式文件系统之上,在底层实现上也是依赖于这两类数据结构的。
了解一下LSM-Tree
相信大家对B+Tree都有一定程度的了解,但对LSM-Tree可能就没那么熟悉了,这里我们简单介绍一下LSM-Tree。
LSM-Tree,全称Log Structured Merge Tree,是一种写入操作不做原地更新,而是以追加的方式写入内存,每次写到一定程度,即冻结为一层,然后写入持久化存储的数据结构。
我们可以简单描述一下一条数据在LSM-Tree中的写入过程:写入Log -> 写入memtable -> flush入持久化存储 -> 经compaction操作进入持久化存储的更新层 -> 同一key的新数据到来时丢弃。
下面是一张LSM-Tree的结构图。

B+Tree VS LSM-Tree
我们来比较一下这两类数据结构,明确它们的特性和适用场景。
B+Tree将数据拆分为固定大小的Block或Page,Page是读写的最小单位。B+Tree可以做到原地更新和删除,因此对数据库事务的支持更加友好,因为一个key只会出现一个Page页里面。
而LSM-Tree的设计思路是将数据拆分为几百M大小的Segment,并顺序写入。LSM-Tree只能追加写,并且在L0层key的range会重叠,所以对事务支持较弱,只能在Segment Compaction的时候真正地更新和删除。
B+Tree的优点是支持高效的读(稳定的O(logN)的复杂度),但对大规模的写请求的效率就比较低(O(logN)复杂度),这是因为在大规模写的情况下,为了维护B+Tree的结构,B+Tree的节点就会不断分裂,操作磁盘的随机读写概率会变大,从而导致写性能降低。
LSM-Tree则相反,支持高吞吐量的写(O(1)),但普通LSM-Tree读取的复杂度是O(n),在使用索引或者缓存优化后可以达到O(logN)。
我们可以粗略的认为未优化的LSM-Tree的写比B+Tree快一个数量级,未优化的LSM-Tree的读比B+Tree慢一个数量级。
第一代分布式数据库——分库分表及分布式中间件
最初面对存储扩展问题,一个比较直接的思路就是分库分表——一个库装不下,我就用多个库装。
假设一开始我们有一个单点的MySQL数据库,随着业务增长,达到了单库的存储性能瓶颈,准备使用三到五个MySQL来重新安排存储。在最理想的情况下,我们可以在拥有原来三到五倍存储空间的情况下,也能有三到五倍的并发来提升存储性能。
但这有两个很明显的问题:第一个是我要对业务进行大量的改造,找到一个合适的维度打散业务进入多个库(而且这种完美的方案还不一定存在),而且跨库的业务也要重新写业务逻辑。第二个是一旦库又满了,我想再做一次扩容的工作,我就又要把这部分的工作再做一次——包括重写业务。
上面两个问题的代价显然是不可承受的,这时候就有分布式数据库厂家来说了:我们来做整合并管理多个库的工作,你们应用只要把多个数据库当作原来的一个库使用即可。
这就诞生了分布式中间件的概念,或者称作分布式关系型数据库。分布式中间件,是从关系型数据库出发,加入分布式技术,实现分布式的高可用性和高扩展性等特性。本文把此类数据库称为分布式中间件,不代表它们就没有对底层数据库(通常是MySQL)做任何改动。实际上,目前市面上的分布式关系型数据库几乎都对底层数据库有自己的修改,甚至有阿里的OceanBase那样自己实现一个关系型底层的情况。
但是,分布式中间件 有根本解决上面的两个问题吗?显然并没有。分布式中间件没有把数据自动分片的能力,应用也不能真真正正的把分布式数据库当作一个单库来使用——除非你完全不在乎跨片的性能损耗。
但分布式中间件也确确实实有很大的作用,它极大的减少了业务的改造量,也保证了了分布式事务的ACID特性。在各类分布式中间件迭代发展的过程中,这一技术路线也在逐渐进步:厂家开始探索对底层数据库的改造,以使其更适应分布式特性;中间件层也吸收了后面NewSQL的一些技术思路,在全局事务管理、数据增量写入等方面做了很多优化。
普通分布式中间件
大部分分布式中间件的架构一般有以下三个部分:
客户端:通常为MySQL5.7或8.0版本的客户端,支持JDBC访问。
存储层:由多个MySQL实例组成,引擎为InnoDB。
计算层(中间件层):组织并管理存储层的MySQL实例,接受并解析客户端传来的SQL请求。计算层通常用片的概念把存储层的MySQL分割,然后以片为单位进行多副本来实现高可用。计算层显式或隐式的有一个事务管理组件,负责给事务赋一个全局唯一的ID,这个组件是实现分布式事务一致性的一种重要的解决方案。计算层对客户端屏蔽多副本和事务ID,会对客户端发来的普通SQL进行拆分和改造,并生成分布式的执行计划,然后下发到存储层的MySQL实例执行。
阿里OceanBase数据库
OceanBase的总体架构如下图。

可以看到OceanBase主要由五部分组成:
客户端:用户使用OceanBase的方式和MySQL数据库完全相同,支持JDBC、C客户端访问等。
RootServer:管理集群中的所有服务器,子表(tablet)数据分布以及副本管理。RootServer一般为一主一备,主备之间由数据强同步。
UpdateServer:存储OceanBase系统的增量更新数据。UpdateServer一般为一主一备,主备之间可以配置不同的同步模式。部署时,UpdateServer进程和RootServer进程往往共用物理服务器。
ChunkServer:存储OceanBase系统的基线数据。基线数据一般存储两份或者三份,可配置。
MergeServer:接收并解析用户的SQL请求,经过词法分析、语法分析、查询优化等一系列操作后转发给响应的ChunkServer或者UpdateServer。如果请求的数据分布在多台ChunkServer上,MergeServer还需要对多台ChunkServer返回的结果进行合并。
OceanBase借鉴了BigTable的做法,相比于普通的分布式中间件引入了UpdateServer这种增量更新机制,在不需要使用两阶段提交的情况下实现了分布式事务,这点下一篇分布式事务部分会详细展开。
第二代分布式数据库——NoSQL
在早期分库分表方案发展过程中,好多公司都面临了因扩容而无限次改造业务的痛苦。他们再次观察业务,发现业务并不复杂——至少没复杂到需要使用高级SQL的地步。这样NoSQL干脆就抛弃了高级SQL(分布式ACID特性),从而换来对业务透明的特性和强水平扩展的能力。
这样做的好处显而易见——只要你能忍受不用高级SQL这一点,那么你只要进行一次到NoSQL的改造,后面就可以近乎无限的扩容,无需任何业务的适配。
各种NoSQL,如HBase,Cassandra,Leveldb,RocksDB底层的数据结构,都是LSM-Tree。
因为NoSQL不支持分布式ACID特性,和其他分布式数据库差别较大,所以不列入后面对事务的讨论。
第三代分布式数据库——NewSQL
上面的分库分表、分布式中间件和NoSQL都不可避免的由一个业务侵入性的问题,有些前沿厂家就产生了把二者结合起来,设计一个兼具分布式事务一致性和强可扩展性的数据库的想法——这就是NewSQL的诞生。
在NewSQL领域,有两个流派,分别是Amazon的Aurora和Google的Spanner。这两者之前的区别实际上是非常大的,所以我们在后文中也把他们看作两种完全不同的数据库。
Aurora流派
Aurora流派也被称作Shared Everything,目前这个流派,多是被部署到虚拟计算环境中的云数据库,本文涉及的云数据库有阿里的PolarDB,Amazon的Aurora以及华为云数据库Taurus。
知乎上有个很有意思的问题:为什么AWS云计算服务是亚马逊先做出来,而不是Google?
这个问题的回答也都很专业,这里简单总结一下。Amazon的核心业务电子商务有太强的季节性,可以理解成,Amazon要维持的服务器数量是根据每年黑五的需求决定的,而一年的其他时间完全不需要这么多服务器。于是就诞生了AWS的想法,也成为后来“云”这一概念的雏形。
另外还有一点就是两者商业哲学的不同。Amazon更倾向于提供近似于水电的基础设置服务,成本应该越低越好,价格也应该越低越好;而Google零几年的时候主营的业务广告利润非常之高,并且Google一向只喜欢提供终端的服务,既没有压力也没有动力去做云。
Aurora流派最重要的一个概念就是Log is Database。这个概念是把log写到存储层,由存储层负责重放log、回写page并尽量减少写放大。
下面一个表格列出了Aurora一系列数据库的特性对比.
| 数据库 | 计存分离解决方案 | 架构特点 | 架构缺点 |
|---|---|---|---|
| PolarDB | 将InnoDB的log和page存放带类POSIX接口的分布式文件系统 | CPU负载小;采用基于RDMA实现的ParallelRaft技术来复制数据;对于InnoDB的侵入非常小,便于跟进MySQL社区的新版本 | Page刷脏网络压力大; |
| Aurora | Log is Database | 将db的数据(也就是所有的page)分成若干个10GB大小的shard,相应的log也随data一起保存在shard中;持久化、page读取都只需要一跳网络传输。 | 存储节点需要大量的CPU做redo log到innodb page的转换 |
| Socrates | Log is Database | 相比于Aurora单独了一个log层用于持久化log,避免受到重放log、回写page的影响;PageServer层从log层拉取log进行重放、回写page,并向计算节点提供读取page服务。 | 存储节点需要大量的CPU做redo log到innodb page的转换 |
| CynosDB | Log is Database | 相比于Aurora存储层为计算节点提供了Log IO接口与Page IO接口,前者负责持久化log,后者负责page的读取 | 存储节点需要大量的CPU做redo log到innodb page的转换 |
| Taurus | Log is Database | 有独特的Log Store设计;使用了raft复制协议 | 存储节点需要大量的CPU做redo log到innodb page的转换 |
需要专门说明的一点是Aurora和PolarDB理念上的区分。Aurora认为网络会成为云数据库的瓶颈;PolarDB则认为网络传输速度会快速发展,后续软件代码(CPU)才是性能的瓶颈。
这两种思路的区别导向了两种架构。Aurora的设计是日志即数据,在保证日志落盘的前提下,尽量减少磁盘IO,所以整个Aurora只写一份Redo log到底层存储,由底层存储来实现把rodo log‘恢复’成数据页的行为;PolarDB则把数据页和rodo log都写入底层存储,PolarDB的底层存储PolarStore更像一个通用的高可用存储,不需要进行类似Aurora一样把Redo日志恢复出数据文件的操作。
从同行的表现来看,后面一系列的云原生数据库基本都跟进了Aurora的架构,看起来还是Log is Database架构更合理。不过,也有一种说法是PolarDB在早期没有过分考虑技术的长远性,而是直接选择一种易实现的架构来抢占市场。从这种角度看,PolarDB是成功的。
华为云Taurus数据库
我们这里以2020年六月份华为云Taurus在Sigmod上发表的论文来看一下Aurora流派的结构。下图是Taurus的结构图。

可以看到Taurus主要由四部分组成:
客户端:目前是一个改版的MySQL8.0;
SAL:全称Storage Abstraciton Layer,可以理解为存储层的前端和存储数据分布式管理组件,负责DB引擎与存储的Log Store/Page Store交互,同时也负责创建、管理、删除Page Store的Slices以及管理page在Slices上的映射关系;
Log Store:负责持久化log以及为只读实例提供log内容;
Page Store:存储真正的数据并为SQL前端提供page读取服务,向SAL提供4个API:WriteLogs,ReadPage,SetRecycleLSN,GetPersistentLSN。
阿里双十一存储引擎X-Engine
X-Engine是阿里专为双十一设计的存储引擎,因为其特殊性,我们这里也简单介绍以下它的架构。我们可以从2019年阿里发布的论文《X-Engine:An Optimized Storage Engine for Large-scale E_commerce Transaction Processing》中看到其具体的设计。
X-Engine主要是为了解决双十一面临的三个问题而研发的,这三个问题是:
海啸问题,活动开始时每秒交易量(TPS)激增;
泄洪问题,缓存很快被大量数据填满;
访问热点急速变化问题,随着促销活动的改变,数据的冷热会发生迅速的切换。
这种特殊的场景使X-Engine相比于其他的分布式数据库更加重视insert和update性能,从而使用了具有杰出写入性能的LSM-Tree这种数据结构。
X-Engine的架构见下图。(大家可以对照上文普通LSM-Tree的结构图)
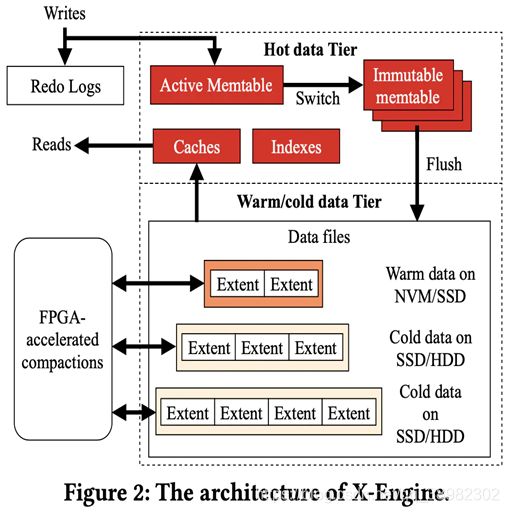
基于LSM-Tree分层存储能够做到写的高吞吐,带来的副作用是整个系统必须频繁的进行compaction,写入量越大,Compaction操作越频繁。而Compaction操作非常消耗CPU和IO,在高吞吐的情况下,大量的Compaction操作占用大量系统资源,必然带来整个系统性能断崖式下跌,对应用系统产生巨大影响。
X-Engine为了优化这个问题,引入了异构硬件设备FPGA来代替CPU完成compaction操作,使系统整体性能维持在高水位并避免抖动,是存储引擎得以服务业务苛刻要求的关键。
Spanner流派
Spanner流派也称作Shared Nothing。与分布式中间件不同的是,它是从分布式系统出发,再来做存储,做查询,利用天然的扩展能力和列存的性能优势,实现基于KV存储的支持关系型查询的数据库。如TiDB,就是一个NewSQL的商业化的实现。
我们对Spanner的所有了解都来自Google于2012年发表的论文《Spanner: Google’s Globally-Distributed Database》。
Spanner论文中有两个点需要十分重视:一个是TrueTime API的实现,给Spanner提供了全局的时钟接口,在此基础上Spanner才能实现强的全局一致性保证;另一个是论文中对Spanner的分布式事务实现细节进行了详细的描述。第一点在本文中会有详细的阐述,第二点详见下一篇分布式事务部分。
Spanner的总体(全球)架构见下图。

universe是Spanner的全球部署实例,并被分成多个zone,zone是Spanner管理部署和物理隔离的单元。
一个zone包含一个zonemaster,若干个location proxy,和一百至几千个spanserver。zonemaster把数据分配给spanserver,spanserver把数据提供给客户端。客户端使用每个zone上面的location proxy来定位可以为自己提供数据的spanserver。
spanserver的架构见下图。

每个spanserver负载管理了100到1000个tablet(BigTable提出的一种数据结构),tablet实现了下面的映射:
(key:string,timestamp:int64) -> string
为了支持复制,每个spanserver会在每个tablet上面实现一个单个的Paxos状态机。Paxos协议会选举出一个领导者(上图中中间的那个replica),写操作必须在领导者上初始化Paxos协议,读操作可以直接从底层任何副本的tablet中访问状态信息,只要这个副本足够新。副本的集合称为一个Paxos group。
此外,Spanner实现分布式事务一致性是靠两阶段提交,所以一个分布式事务还会选举出一个participant leader。transaction manager就是用来实现participant leader的。
lock table则用来实现并发控制,这个锁表包含了两阶段锁机制的状态:它把键的值域映射到锁状态上面。
下图是Spanner TrueTime的三个API。

TrueTime会显式地把时间表达成TTinterval,这是一个时间区间,具有有界限的时间不确定性。
TT.now()返回的结果是当前时间的一个闭区间[earliest,latest]。用函数tabs(e)表示一个事件e的绝对事件,那么对于一个调用tt=TT.now(),TrueTime可以保证tt.earliest <= tabs(e) <= tt.latest。
底层上,TrueTime使用GPS和原子钟两种方式来获取时间,增加可靠性。在Google的线上应用环境中,TrueTime的误差边界是一个关于时间的锯齿形函数,在1到7ms之间变化,其中1ms来自网络通讯延迟。
总结
本文从分布式的概念出发,阐述笔者理解的分布式数据库三个发展阶段,并分别介绍每个阶段的代表性的数据库及其架构,主要包括普通分布式中间件、OceanBase、华为云Taurus、X-Engine引擎和Spanner。下一篇,我会详解这些分布式数据库分布式事务的的实现。