pickle模块学习和一次惨痛(sb)的debug经历
pickle模块实现了把Python对象结构进行序列化和反序列化( serializing and de-serializing a Python object structure)的二进制协议。
pickling: 把对象序列化为字节流a byte stream
unpickling: 把二进制文件binary file的字节流转换为对象
JSON: 文本序列化格式a text serialization format,输出一个Unicode文本, 人类可读(human-readable)
而pickle是二进制的序列化文件,a relatively compact binary representation, 人类不可读,pickle只能用于Python(Python-specific)。
记一次关于pickle的惨痛的debug
教训:debug首先看文档,文档看完整了解决不了再上网搜
第一次用Python的pickle处理数据文件,这次只是涉及读取数据,把数据集(dat文件)解析成numpy数组,方便在Python里面进行后续处理。对pickle不熟悉,所以一直没找到debug的门路和关键方向,实际上还是报错的字面意思,就是编码格式不对,我还舍近求远搞了好多不必要的幺蛾子,,,
不算debug吧, 是想用Python读入一批.dat数据,一直没成功,结果竟然倒腾了一下午还加半个晚上,把网上的博客,百科翻了个底朝天!!!!像每回debug一样,中间再次开始质疑自己智商,这TMD还能搬个啥砖???
幸好最后终于算是解决了,还以为要搞上一两天呢,还好还好
最终正确代码:
# coding: utf-8
import pickle
import numpy as np
# 读入数据
x = pickle.load(open('D:\ProgramData\Anaconda3\MyData\data_preprocessed_python\s01.dat', 'rb'),encoding='latin1')
for key in x.keys():
print(key)
print(x['labels'].shape)
print(x['data'].shape)
输出结果
labels
data
(40, 4)
(40, 40, 8064)
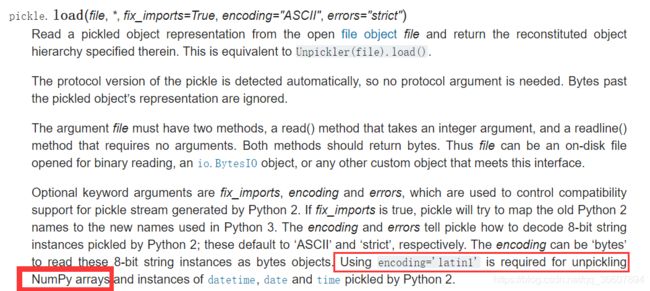
关键就在于pickle.load()那行代码里面最后的encoding参数,应该输入latin1,默认的是ascii, 但会一直报错
UnicodeDecodeError: 'ascii' codec can't decode byte 0xd7 in position 0: ordinal not in range(128)
看看文档里面写的是多么清楚!!!
结果我嫌英文看着烦,看个大概几句就跑去各种搜索,执行各种事倍功半的尝试:
- 刚开始以为问题在于要用cPickle包,一番查询后明白了cPickle包使用C语言写的比较高效,但它是Python2的东西,Python3已经被淘汰了,现在就用pickle就棒棒的没问题
- 中间尝试过文档中的’bytes’编码选项,,都没往后多看一行······为自己的愚蠢默默落下了悔恨的眼泪
确实不报上面那个错了,但不知道为啥读入的字典变量的键成了这个样子:(至今未解这个b和引号是从哪里来的)
b'labels'
b'data'
然后想用某博客的方法改变字典变量的键名不改值,结果由于涉及到字符串的单双引号,改不成功
# coding: utf-8
import pickle
import numpy as np
# 读入数据
x = pickle.load(open('D:\ProgramData\Anaconda3\MyData\data_preprocessed_python\s01.dat', 'rb'), encoding='bytes')
for key in x.keys():
print(key)
x['data'] = x.pop(" b'data' ")
报错:
b'labels'
b'data'
x['data'] = x.pop(" b'data' ")
KeyError: " b'data' "
- 把dat文件转换为txt再用numpy.loadtxt进行读取,不行,因为转为TXT文件后乱码,一堆乱七八糟的,也没法读入
- 直接读取,看到别的博客这样做成功了,我估计我没成功是因为我的dat文件里有两个numpy array.
x = np.fromfile('D:\ProgramData\Anaconda3\MyData\data_preprocessed_python\s01.dat', dtype=int)
- 对dat文件格式感到非常好奇,于是尝试用MATLAB打开,结果MATLAB显示正在打开大型文本文件,打开后也是各种乱码,没用

总结:
对函数/模块不了解先仔细看完官方文档,再去搜索网上的零七八碎的资源,有时候网上资源很好使,但有的时候遇到的难题在网上并不能找到很多共鸣,而且有一些资源用的是python2,结果引入很多误会浪费时间,这次问题虽然花了不少时间,但是是由于自己方法不当导致的