python机器学习之随机森林案例——在乳腺癌数据的调参
在乳腺癌数据的调参
首先导入所用到的库
from sklearn.datasets import load_breast_cancer#数据
from sklearn.ensemble import RandomForestClassifier#分类器
from sklearn.model_selection import GridSearchCV#网格搜索
from sklearn.model_selection import cross_val_score#交叉验证
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
获取数据集
乳腺癌数据集有569条记录,30个特征,单看维度虽然不算太高,但是样本量非常少。过拟合的情况可能存
在
#数据集
data = load_breast_cancer()
data
data.data.shape#查看数据维度
data.target#标签

进行一次简单的建模,看看模型本身在数据集上的效果
rfc = RandomForestClassifier(n_estimators=100,random_state=90)#实例化
score_pre = cross_val_score(rfc,data.data,data.target,cv=10).mean()#交叉验证 取平均数
score_pre#准确度

评分很高,还不错,但是容易引起过拟合。
调参第一步,首先调n_setimators,画出学习曲线。
看见n_estimators在什么取值开始变得平稳,是否一直推动模型整体准确率的上升等信息,第一次的学习曲线,可以先用来帮助我们划定范围,我们取每十个数作为一个阶段,来观察n_estimators的变化如何引起模型整体准确率的变化
scorel = []
for i in range(0,200,10):
rfc = RandomForestClassifier(n_estimators=i+1
,n_jobs = -1
,random_state = 90)
score = cross_val_score(rfc,data.data,data.target,cv = 10).mean()
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*10)+1)#打印出做大的值,并输出其索引位置
plt.figure(figsize=[20,5])#画布
plt.plot(range(1,201,10),scorel)
plt.show()

确定好范围,在细化,在【65,75】之间
scorel = []
for i in range(65,75):
rfc = RandomForestClassifier(n_estimators=i
,n_jobs = -1
,random_state = 90)
score = cross_val_score(rfc,data.data,data.target,cv = 10).mean()
scorel.append(score)
print(max(scorel),([*range(65,75)][scorel.index(max(scorel))]))#打印出做大的值,并输出其索引位置
plt.figure(figsize=[20,5])#画布
plt.plot(range(65,75),scorel)
plt.show()
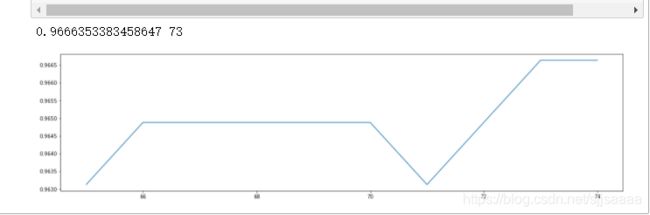
所以,当n_estimators为73的时候效果比较好。
进行网格搜索
调整深度
garam_grid = {
"max_depth":np.arange(1,20,1)}
rfc = RandomForestClassifier(n_estimators=73
,random_state = 90)
GS = GridSearchCV(rfc,garam_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_score_#查看最高评分
GS.best_params_#查看最高评分的数
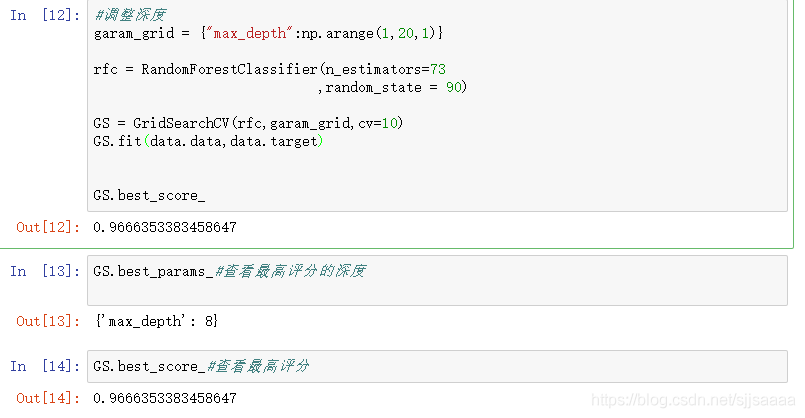
可以看到深度为8时,评分最高,但是没什么效果,和原来一样。
#调整max_feature
garam_grid = {
"max_features":np.arange(8,70,1)}
rfc = RandomForestClassifier(n_estimators=73
,random_state = 90)
GS = GridSearchCV(rfc,garam_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_score_#查看最高评分
GS.best_params_#查看最高评分的数

这个max_featur参数调整到24时是最高的,比原来有所提升,所以保留参数。
调整min_samples_leaf参数
garam_grid = {
"min_samples_leaf":np.arange(1,1+10,1)}
rfc = RandomForestClassifier(n_estimators=73
,random_state = 90)
GS = GridSearchCV(rfc,garam_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_score_#查看最高评分
GS.best_params_#查看最高评分的数

不如原来。
调整min_samples_split
garam_grid = {
"criterion":['gini','entropy']}
rfc = RandomForestClassifier(n_estimators=73
,random_state = 90)
GS = GridSearchCV(rfc,garam_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_score_#查看最高评分
GS.best_params_#查看最高评分的数
也没有提高。
调整criterion
garam_grid = {
"criterion":['gini','entropy']}
rfc = RandomForestClassifier(n_estimators=73
,random_state = 90)
GS = GridSearchCV(rfc,garam_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_score_#查看最高评分
GS.best_params_#查看最高评分的数

总结出模型的最佳参数
rfc = RandomForestClassifier(n_estimators=73
,random_state=90
,max_features=24)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()

调整完参数以后,照原来有所提升0.0017857142857143904,还算可以,因为本身模型精确度就比较高。
sklearn中的集成算法模块ensemble
类 ——> 类的功能
ensemble.AdaBoostClassifier —> AdaBoost分类
ensemble.AdaBoostRegressor —> Adaboost回归
ensemble.BaggingClassifier —> 装袋分类器
ensemble.BaggingRegressor —> 装袋回归器
ensemble.ExtraTreesClassifier—> Extra-trees分类(超树,极端随机树)
ensemble.ExtraTreesRegressor —> Extra-trees回归
ensemble.GradientBoostingClassifier —> 梯度提升分类
ensemble.GradientBoostingRegressor —> 梯度提升回归
ensemble.IsolationForest—> 隔离森林
ensemble.RandomForestClassifier —> 随机森林分类
ensemble.RandomForestRegressor —> 随机森林回归
ensemble.RandomTreesEmbedding—> 完全随机树的集成
ensemble.VotingClassifier —> 用于不合适估算器的软投票/多数规则分类器