Python实战:实现Excel多个工作簿合并及多功能数据透视
Python实现多个工作簿合并及多功能数据透视
大家好,这次项目给大家带来的是Python实现多个Excel工作簿合并,并对合并后的结果集进行数据透视的示例。对于数据透视,Excel当中已经有了比较强大的透视功能,但是缺点是灵活性不足,就是对于时间频率、周期以及计算方式都不够灵活,因此Python正好弥补了这块不足。
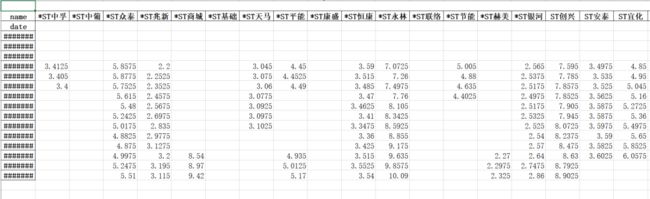
首先看下几天的数据集的样子:
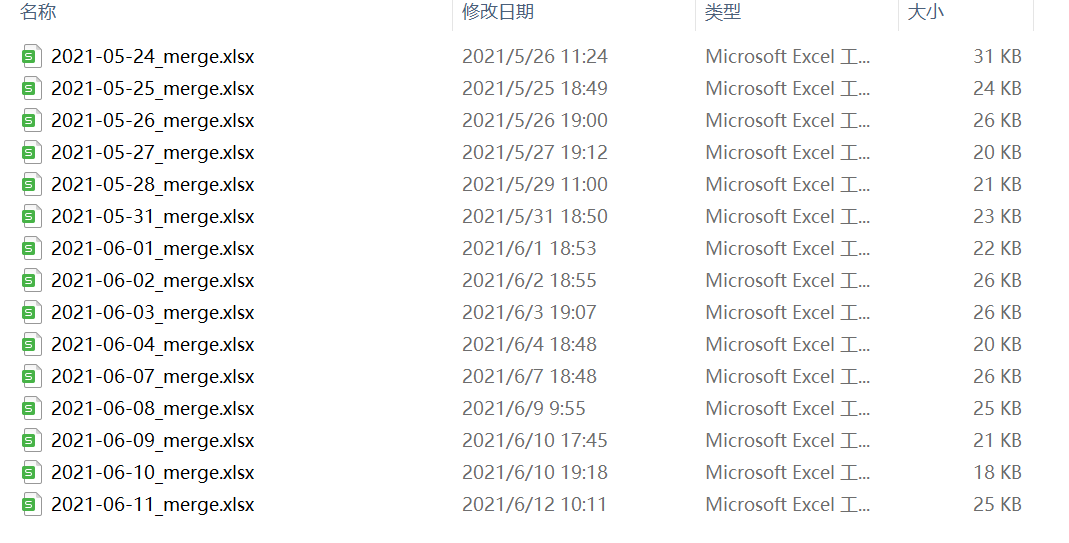
这个是要合并的所有的工作簿
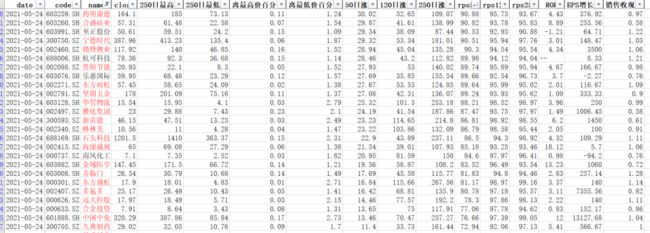
这是每个工作簿的样子,每个文件的内部样式都要保持一致能才能进行完整的合并。
接下来简单谈谈我的功能实现:
1. 功能模块介绍:
使用Path模块:
- 读取指定文件夹下的所有excel文件
使用Pandas
- read_excel()读取所有工作簿
- concat()合并多有数据
- pivot_table() 进行简单数据透视
- resample()日期重采样进行不同时段的数据汇总
- rolling() 探查指定固定时间段数据的变化程度
- to_excel()汇总数据到新的工作簿
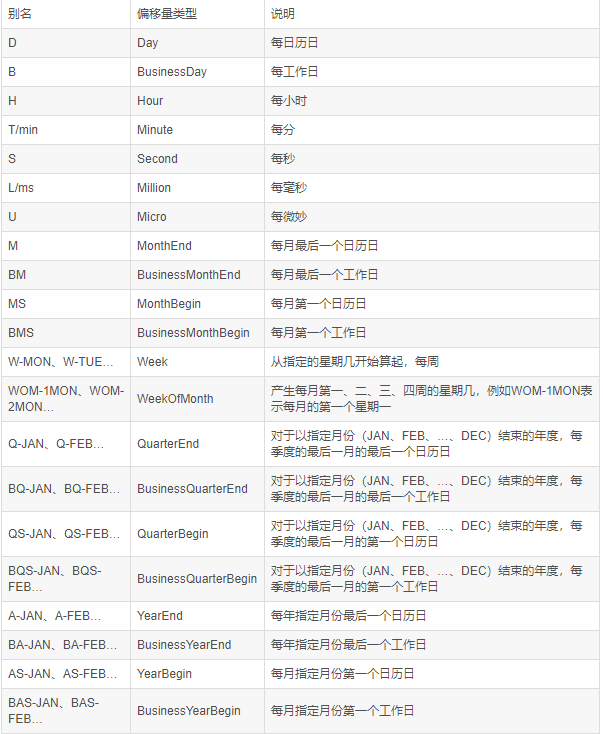
2. 扩展:时间选择
- 按照固定频率:
- 每几天/周/月:例如:‘7D’
- 时间频率设置参数如下:
代码:
导入扩展包
import pandas as pd
from pathlib import Path
数据整合
# 数据整合:
def data_concat():
# 提示用户输入文件夹路径:
folder_path = Path(input('请输入要处理文件的文件夹路径:'))
# 提取所有文件列表:
file_list = folder_path.glob('*merge.xlsx')
# 整合所有列表
df_list = []
for i in file_list:
if not i.name.startswith('~$'):
df = pd.read_excel(i)
df_list.append(df)
dfs = pd.concat(df_list,axis=0) # axis=0 代表上下合并,axis=1代表左右合并
# 提示用户需要提取哪列或者哪几列数据,name和date是必须添加的数据,因此也要进行整合
col_list = input('请输入要提取的列名,多个列名用空格间隔:').split(' ')
if ('name' in col_list)&('date' in col_list):
pass
elif 'name' in col_list:
col_list.append('date')
elif 'date' in col_list:
col_list.append(['name'])
else:
col_list.extend(['name','date'])
df = dfs[col_list]
df.set_index('name',inplace=True)
# 输出数据:
return df
实现简单数据透视
我使用了pivot_table()函数来生成以股票名为行索引,日期为列索引,不同计算汇总添加新列的方式生成透视结果。我将用户指定的多个计算添加到列表中,然后依次执行,并生成新的列添加到透视结果中,这样就能很简单快速的生成透视结果了
# 实现简单数据透视
def pivot_data(df):
# 提示用户需要进行汇总的方法:
method_list = input('请输入要汇总的方法:求和,非重复计数,平均值,最大值,最小值,方差,标准差,多个方法以空格间隔:').split(' ')
table = pd.pivot_table(df,index='name',columns='date',fill_value=0)
for i in range(len(method_list)):
if method_list[i] == '求和':
table[method_list[i]] = table.sum(1)
elif method_list[i] == '平均值':
table[method_list[i]] = table.mean(1)
print(table[method_list[i]])
elif method_list[i] == '最大值':
table[method_list[i]] = table.max(1)
elif method_list[i] == '最小值':
table[method_list[i]] = table.min(1)
elif method_list[i] == '去重计数':
table[method_list[i]] = table.unique(1)
elif method_list[i] == '标准差':
table[method_list[i]] = table.std(1)
elif method_list[i] == '方差':
table[method_list[i]] = table.var(1)
else:
print('方法不存在')
table.to_excel('res.xlsx')
生成的数据集是这样的: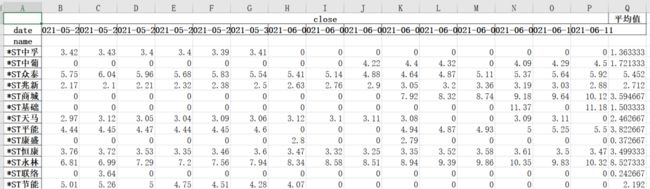
生成具有时间频率透视功能的表格
在实际工作中,我们经常需要对一定时间频率的数据做统计,这里我使用了Python中时间序列相关的内容,对股票数据,进行不同时间频率的数据透视,可以得到以固定时间频率变化的汇总结果。
# 具有时间频率透视功能的表格
def freq_pivot(df):
# 对数据索引重置,使时间作为行索引
date_format= '''
可供选择日期频率:
每几个日历日:nD,例如'7D'
每几个工作日:nB, 例如'7B'
每月最后一个日历日:nM,例如'3M'
每月最后一个工作日:nBM,例如'3BM'
指定每周星期几算起:W-Mon
等等
'''
date_freq = input('请输入你想要的时间频率(输入时间需要小于现有数据时间跨度):')
df['date'] = pd.to_datetime(df['date'])
df2 = df.reset_index().set_index('date')
method_list = input('请输入要汇总的方法:求和,平均值,最大值,最小值,方差,标准差,多个方法以空格间隔:').split(' ')
for i in range(len(method_list)):
if method_list[i] == '求和':
df3 = df2.groupby('name').resample(date_freq).sum()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '平均值':
df3 = df2.groupby('name').resample(date_freq).mean()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '最大值':
df3 = df2.groupby('name').resample(date_freq).max()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '最小值':
df3 = df2.groupby('name').resample(date_freq).min()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '标准差':
df3 = df2.groupby('name').resample(date_freq).std()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '方差':
df3 = df2.groupby('name').resample(date_freq).var()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
else:
print('方法不存在')
def freq_pivot(df):
# 对数据索引重置,使时间作为行索引
date_format= '''
可供选择日期频率:
每几个日历日:nD,例如'7D'
每几个工作日:nB, 例如'7B'
每月最后一个日历日:nM,例如'3M'
每月最后一个工作日:nBM,例如'3BM'
指定每周星期几算起:W-Mon
等等
'''
date_freq = input('请输入你想要的时间频率(输入时间需要小于现有数据时间跨度):')
df['date'] = pd.to_datetime(df['date'])
df2 = df.reset_index().set_index('date')
method_list = input('请输入要汇总的方法:求和,平均值,最大值,最小值,方差,标准差,多个方法以空格间隔:').split(' ')
for i in range(len(method_list)):
if method_list[i] == '求和':
df3 = df2.groupby('name').resample(date_freq).sum()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '平均值':
df3 = df2.groupby('name').resample(date_freq).mean()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '最大值':
df3 = df2.groupby('name').resample(date_freq).max()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '最小值':
df3 = df2.groupby('name').resample(date_freq).min()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '标准差':
df3 = df2.groupby('name').resample(date_freq).std()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
elif method_list[i] == '方差':
df3 = df2.groupby('name').resample(date_freq).var()
df3.to_excel(f'时间频率为{
date_freq}{
method_list[i]}透视.xlsx')
else:
print('方法不存在')
生成的数据集是这样的:
生成具有时间周期的透视表格
有时候我们想要查看每连续一定时间周期数据的变化规律是怎么样的,这时候就需要生成具有时间周期的透视表格,在该方法中,我使用了unstack方法将行索引设定为时间,股票名设置为列索引,最终实现了股票在一定时间周期下的连续变化的数据
# 时间周期透视:
def period_pivot(df):
date_format= '''
可供选择日期周期:
查看每连续几日的数据变化(如每连续10天),请输入:10
'''
print(date_format)
df['date'] = pd.to_datetime(df['date'])
df2 = df.reset_index().set_index(['date','name'])
p = int(input('本功能为观测连续天数的某个数学指标的变化情况,请输入你想要的时间周期(不要超过数据时间跨度):'))
method_list = input('请输入要汇总的方法:求和,平均值,最大值,最小值,方差,标准差,多个方法以空格间隔:').split(' ')
for i in range(len(method_list)):
if method_list[i] == '求和':
df3 = df2.unstack(level=1).rolling(window=p).sum()
df3.to_excel(f'时间周期为{
p}{
method_list[i]}透视.xlsx')
elif method_list[i] == '平均值':
df3 = df2.unstack(level=1).rolling(window=p).mean()
df3.to_excel(f'时间周期为{
p}{
method_list[i]}透视.xlsx')
elif method_list[i] == '最大值':
df3 = df2.unstack(level=1).rolling(window=10).max()
df3.to_excel(f'时间周期为{
p}{
method_list[i]}透视.xlsx')
elif method_list[i] == '最小值':
df3 = df2.unstack(level=1).rolling(window=p).min()
df3.to_excel(f'时间周期为{
p}{
method_list[i]}透视.xlsx')
elif method_list[i] == '标准差':
df3 = df2.unstack(level=1).rolling(window=p).std()
df3.to_excel(f'时间周期为{
p}{
method_list[i]}透视.xlsx')
elif method_list[i] == '方差':
df3 = df2.unstack(level=1).rolling(window=p).var()
df3.to_excel(f'时间周期为{
p}{
method_list[i]}透视.xlsx')
else:
print('方法不存在')
生成的结果集是这样的: