同任务但不同domain数据的统一模型
前言
我们在实际工作中免不了遇到这样的场景,假设当前我们要开发一个分类任务,但是呢?我们手头有很多不同领域(domain)的数据。
不同的domain之间存在特征交集,比如电商领域的CTR(曝光给用户预测其点击的概率)任务存在着部分相同的用户群体和商品,这部分信息其实在不同的domain任务中可以共享,但是又不完全相同,比如同一用户在不同的domain中的行为是不一样的。所以简单的混合不同domain数据训练一个共享model(完全不区分domain任务)是不够的,必须要有区分。容易想到的就是每个domain训练一个model,但是这样显而易见的缺点就是(1)有的domain训练数据量少,导致很难学到一个理想效果(2)训练这么多model,维护起来也很麻烦,而且需要更多的计算和存储资源。
总体来说就是既要融合但是也要有区分。所以本文介绍的阿里这篇论文的着眼点就是去学一个模型,同时其又可以区分不同domain任务。目前其已经被应用在了阿里的广告系统,CTR提高了8%,RPM收入提高了6%。所以还是非常不错的一篇工业实践,一起来看看吧。
论文题目:
《One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》
论文链接:https://arxiv.org/pdf/2101.11427.pdf
记得关注笔者微信公众号:算法让生活更美好;会有更多前沿paper和代码解读以及trick哦~
分析问题
背景就不多说了,主要就是解决不同domain的问题,论文集中解决的是CTR任务,这里具体举了淘宝APP中两个domain场景例子如下:
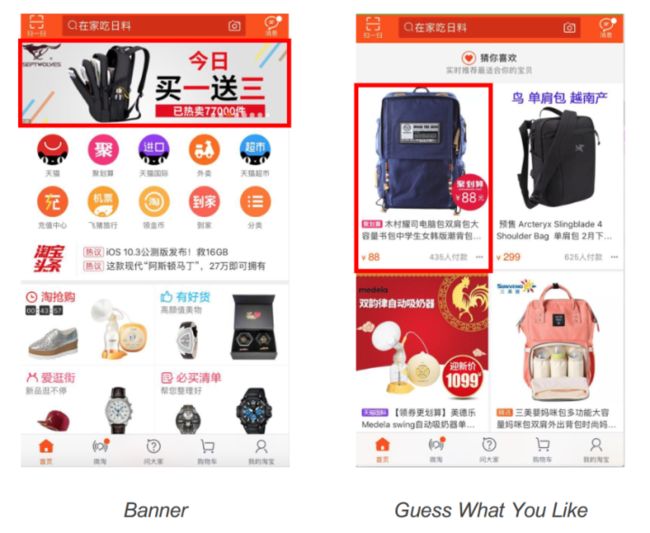
左边的Banner就是首页置顶的推荐,右边的就是“猜你推荐”,这两个场景虽说都是CTR任务,但是不能使用完全相同的一个模型来完成,因为用户在这两个domain下的行为习惯还是有所差别的。所以必须区分。
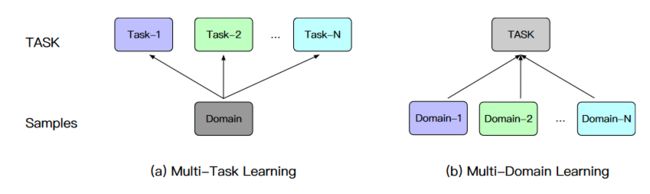
这里容易想到的一个手段就是多任务学习,多任务学习基本的范式就是网络底层layer共享,然后在最后的输出层针对不同任务设计一些不同的layer达到目的。但是本文所说的背景和多任务学习还是有一定的区别,本文说的场景其实本质上是同一类任务比如CTR任务,但数据是不同domain的,而多任务一般是同时解决不同任务,比如CTR和CVR,但数据通常是同一个domain的,换句话说多任务的label空间通常是不一样的,但是输入数据通常一样,而本文的场景恰恰相反,如果直接将多任务的思路用到本文场景会导致忽略或者不能充分利用不同domain之间信息。区别如下图:
为此作者设计了三个trick,分别是partitioned normalization (PN),star topology fully-connected neural network (star topology FCN), auxiliary network,下面我们一个一个看。整体框架如下:
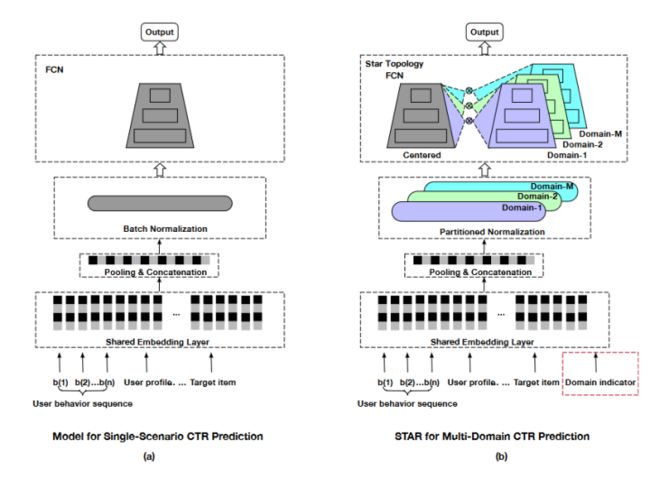
图(a)是传统的单domain模型框架,图(b)就是本文提出的多domain框架。
PN
batch normalization 这是大家再熟悉不过的操作,具体到公式如下
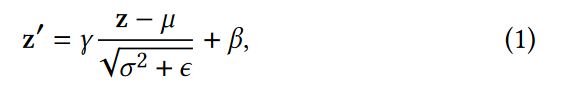
其中γ和β是可学习的参数。但是作者却注意到了本文的场景可以在这个点进行优化。作者的理由是:用batch normalization的前提是样本满足i.i.d条件即样本是独立同分布的,但是不同的domain间显然不满足同分布,所以提出了如下的朴素改进:
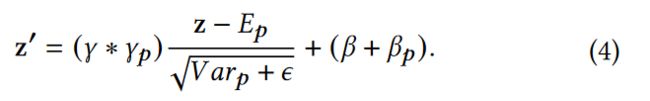
即给每个domain单独学习一下γ和β,例如上述公式的γp就是第p个domain的参数 ,即不同的domain都应该有适配自己分布的参数进行归一化。
star topology FCN
在经过上述的PN层后得到向量表征,这时候就会被送到star topolopy FCN,总体框图如下图:
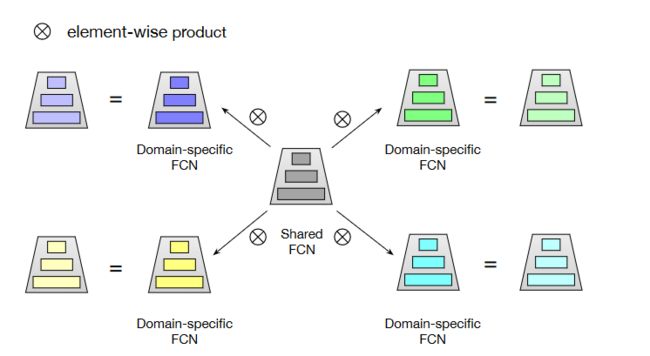
总体来说就是包含一个共享的centered FCN和各自independent FCN,所以总数应该是M+1(假设一共M个domain),作者这里聚合采用的是element-wise multiplication如下公式:
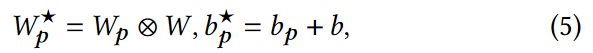
W和Wp分别代表的是centered和第p个domain的权重,W*就是最终参数值的结果。当然了除了element-wise multiplication这种聚合,还可以尝试一些其他的。
auxiliary network
作者针对不同domain这一存在的根源问题进一步提出了优化,试想模型其实很难自动的学到不同domain的不同分布,那怎么办?那我就进一步的告诉网络或者说进一步给网络一些信息让它知道要去着重学习这个差异。
这个差异点在哪里呢?那就是不同domain,说白了就是做一个关于不同domain的分类任务,于是就设计了一个简单的辅助任务,这个简单辅助任务的网络就是两个全连接层。
具体的过程是:加一个是domain ID的类别特征,embedding化后和之前其他特征拼接进而过辅助网络得到表征Sa,假设上节star topolopy FCN得到的表征是Sm,那么最后通过如下公式作为模型预测结果,通过和domain ID label交叉熵更新网络。

说白了就是通过domain分类这个任务进一步让模型得到不同domain不同分布这个信息。
实验
实验数据是在如下19个domain进行的:

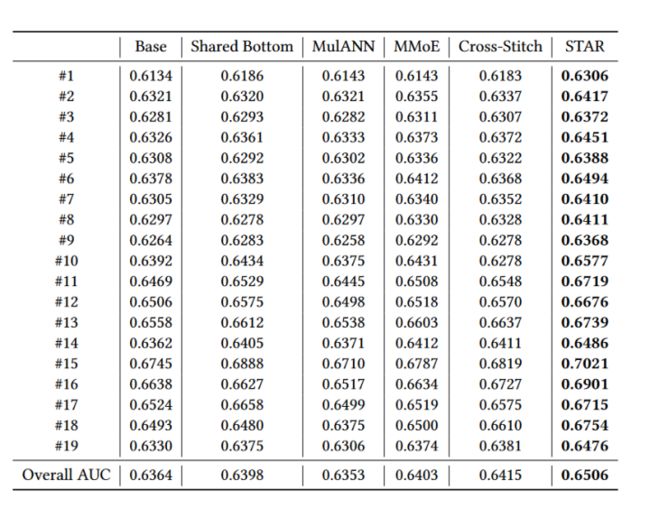
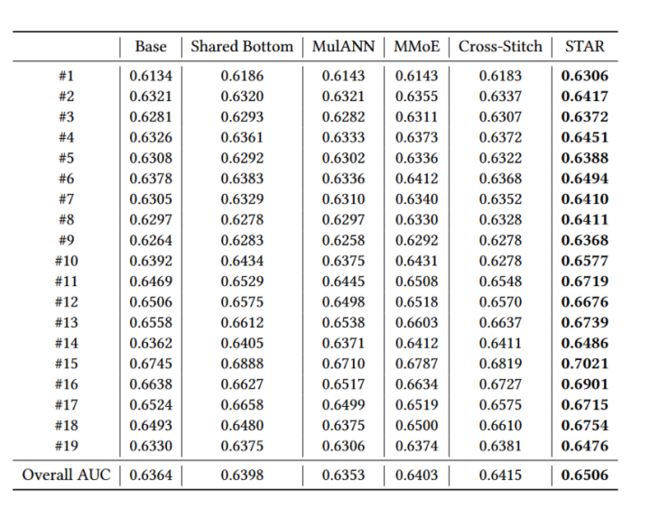
(1)首先是模型整体的效果对比实验如下图,对比的baseline方法基本上都是多任务学习。
(2)这部分主要就是针对提出的三个trick的消融实验,下面的前两个表格证明了前两个trick的有效性,第三个柱状图证明了最后一个trick的有效性,其中w/代表用了辅助网络,w/o代表没用。

(1)首先是模型整体的效果对比实验如下图,对比的baseline方法基本上都是多任务学习。
(2)这部分主要就是针对提出的三个trick的消融实验,下面的前两个表格证明了前两个trick的有效性,第三个柱状图证明了最后一个trick的有效性,其中w/代表用了辅助网络,w/o代表没用。
总结
(1)其实这篇paper所介绍的场景还是比较常见的,比如我们在做不同垂类(科技,财经等)下的分类任务,那为了效果,之前我们都要在不同垂类下训练一个单独的模型,那借鉴一下这里的思路是不是可以搞一波?当然了还要看一下你的不同domain是不是有信息交集,可以彼此利用上,这也比较重要,即centered parameters。
(2)其实centered parameters和domain-specific parameters的思路不是特别耀眼,本质上就是共享一部分网络,在最后再流向不同网络,这和多任务的思路一脉相承,但是PN的设计确实是抓住了多domain的根本问题。
(3)不管怎么样,三个设计都牢牢围绕了要解决的核心问题进行的即多domain,所以要牢牢明白当前的核心问题是什么才有可能想到解决办法。
(4)最后一个辅助任务其实就是相当于加了一个任务,这里说白了就是开头所说的多任务学习。
欢迎关注
笔者微信公众号

知乎:
小小梦想 - 知乎ML/NLP研究员,欢迎关注微信公众号“算法让生活更美好” 回答数 75,获得 46 次赞同 https://www.zhihu.com/people/sa-tuo-de-yisheng/posts
https://www.zhihu.com/people/sa-tuo-de-yisheng/posts
github:
Mryangkaitong · GitHub