前言
单阶段目标检测通常通过优化目标分类和定位两个子任务来实现,使用具有两个平行分支的头部,这可能会导致两个任务之间的预测出现一定程度的空间错位。本文提出了一种任务对齐的一阶段目标检测(TOOD),它以基于学习的方式显式地对齐这两个任务。
TOOD在MS-CoCO上实现了51.1Ap的单模型单尺度测试。这大大超过了最近的单阶段检测器,如ATSS(47.7AP)、GFL(48.2AP)和PAA(49.0AP),它们的参数和FLOPs更少。
本文来自公众号CV技术指南的
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。

论文:TOOD: Task-aligned One-stage Object Detection
代码:https://github.com/fcjian/TOOD
Background
目标检测通常被表示为通过联合优化目标分类和定位的多任务学习问题。由于分类和定位的学习机制不同,两个任务学习到的特征的空间分布可能不同,当使用两个单独的分支进行预测时,会导致一定程度的错位。
最近的一级目标检测器试图通过聚焦于目标的中心来预测两个独立任务的一致输出。他们假设位于对象中心的锚(即,无锚检测器的锚点,或基于锚的检测器的锚盒)可能给出分类和定位两者的更准确的预测。
例如,最近的FCOS和ATSS都使用中心度分支来增强从对象中心附近的锚点预测的分类分数,并为相应锚点的定位损失分配更大的权重。此外,FoveaBox将对象的预定义中心区域内的锚视为正样本。这样的启发式设计已经取得了很好的效果,但这些方法可能会受到两个限制:
(1)分类和定位独立。目前的单级检测器通过两个独立的分支(即头部)并行独立地进行目标分类和定位。这种由两个分支组成的设计可能会导致两个任务之间缺乏交互,从而导致在执行它们时预测不一致。如图1的“result”栏所示,TSS检测器(左上角)识别“餐桌”的对象(用红色块显示的锚点表示),但更准确地定位“披萨”的另一个对象(红色边界框)。
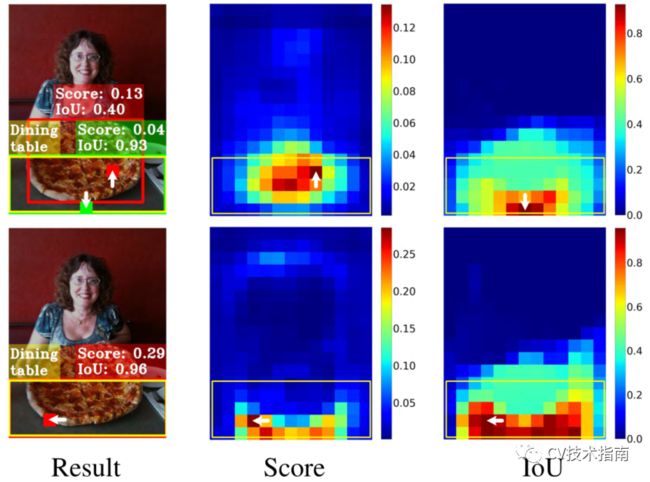
图1:由ATSS(顶行)和TOOD(底行)预测的检测结果(‘Result’)以及分类得分(‘Score’)和定位得分(‘IoU’)的空间分布图示。
(2)与任务无关的样本分配。大多数无锚点检测器使用基于几何的分配方案来选择对象中心附近的锚点进行分类和定位,而基于锚点的检测器通常通过计算锚框和ground truth之间的IoUs来分配锚盒。然而,用于分类和定位的最佳锚点通常是不一致的,并且可能根据对象的形状和特征而变化很大。广泛使用的样本分配方案是与任务无关的,因此可能很难对这两个任务做出准确而一致的预测,如图1中ATSS的 ‘Score’ 和 ‘IOU’ 分布所示。‘Result’列还说明最佳定位锚(绿色块)的空间位置可能不在对象的中心,并且它与最佳分类锚(红色块)不能很好地对齐。因此,在非最大值抑制(NMS)过程中,精确的bounding box可能会被精度较低的bounding box所抑制。
创新思路
为了解决这些局限性,论文提出了一种任务对齐的一阶段目标检测(Task-aligned One-stage Object Detection, TOOD),旨在通过设计一种新的头部结构和面向对齐的学习方法来更精确地对齐这两个任务:
针对传统的一步法目标检测中分类和定位分别采用两个分支并行实现的特点,设计了一种任务对齐头(T-Head),以增强两个任务之间的交互性。这使得这两项任务能够更协作地工作,进而更准确地调整它们的预测。T-Head在概念上很简单:它计算任务交互特征,并通过一种新颖的任务对齐预测器(TAP)进行预测。然后,它根据任务对齐学习提供的学习信号对两个预测的空间分布进行对齐,如下所述。
为了进一步克服未对齐问题,论文提出了一种任务对齐学习(TAL)来明确两个任务的最优锚点之间的距离。它是通过设计一个样本分配方案和一个与任务相关的损失来执行的。样本分配通过计算每个锚点的任务对齐度来收集训练样本(正样本或负样本),而任务对齐损失逐渐统一最佳锚点,以便在训练期间预测分类和定位。因此,在推断时,可以保留分类得分最高并且共同具有最精确定位的边界框。
提出的T-Head和学习策略可以协同工作,在分类和定位两个方面做出高质量的预测。论文的主要贡献可以概括为:
(1)设计了一种新的T-Head,在保持分类和定位特征的同时,增强了分类和定位之间的交互,并进一步将两个任务在预测上对齐;
(2)论文提出了TAL,在识别出的任务对齐锚点上显式地对齐两个任务,并为所提出的预测器提供学习信号;
(3)论文在MSCOCO上进行了广泛的实验,TOOD达到了51.1AP,超过了现有的单级检测器,如ATSS。定性结果进一步验证了任务对齐方法的有效性。
Methods
与最近的单级探测器类似,TOOD具有一个“主干-FPN-头”的整体流水线。此外,考虑到效率和简单性,TOOD在每个位置使用一个锚点(与ATSS相同),其中“锚”是指anchor-free检测器的锚点,或者是anchor-based检测器的锚盒。
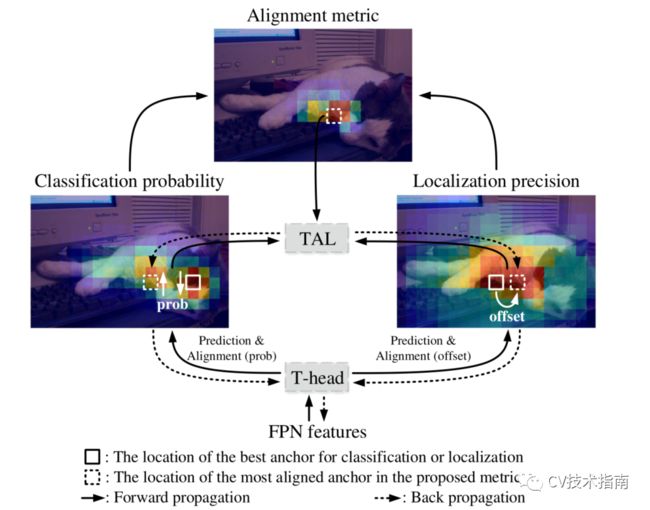
首先,T-Head对FPN特征进行预测。其次,使用预测来计算每个锚点处的任务对齐度量,基于该度量,TAL为T-Head产生学习信号。最后,T-Head对分类和定位的分布进行了相应的调整。具体地说,对齐程度最高的锚点通过“Prob”(概率图)获得更高的分类分数,并通过学习的“偏移量”获得更准确的边界框预测。
如图2所示,T-Head和TAL可以协作改进两项任务的一致性。具体地说,T-Head首先对FPN特征进行分类和定位预测。然后,TAL基于一种新的任务对齐度量来计算任务对齐信号,该度量度量测量两个预测之间的对齐程度。最后,T-Head在反向传播过程中使用TAL计算的学习信号自动调整其分类概率和定位预测。
Task-aligned Head
为了设计一种高效的head结构,以改进单级探测器中head的传统设计(如图3(A)所示)。论文通过考虑两个方面来实现这一点:(1)增加两个任务之间的交互,(2)增强检测器学习比对的能力。T-Head如图3(B)所示,它有一个简单的特征提取器和两个任务对齐的预测器(TAP)。

图3.传统的并行头和提出的T-Head之间的比较。
为了增强分类和定位之间的交互,论文使用特征提取器来学习来自多个卷积层的任务交互特征堆栈,如图3(B)中的蓝色部分所示。这种设计不仅方便了任务的交互,而且为这两个任务提供了多层次的特征和多尺度的有效感受野。形式上,Xfpn表示FPN特征。特征提取器使用具有激活函数的N个连续卷积层来计算任务交互特征:
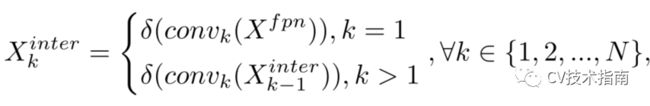
其中,conv k和δ分别指第k个卷积层和ReLU函数。因此,论文利用head的单个分支从FPN特征中提取丰富的多尺度特征。然后,将计算出的任务交互特征送入两个TAP进行分类定位。
Task-aligned Predictor(TAP)
论文对计算出的任务交互特征进行目标分类和定位,这两个任务可以很好地感知彼此的状态。然而,由于单一分支的设计,任务交互功能不可避免地在两个不同的任务之间引入了一定程度的功能冲突,这在其它论文中也有讨论。

直观地说,对象分类和定位的任务具有不同的目标,因此聚焦于不同类型的特征(例如,不同的层次或感受野)。因此,论文提出了一种层注意机制(layer attention mechanism),通过在层级动态计算任务特征来鼓励任务分解。如图4所示,针对每个分类或定位任务分别计算特定于任务的功能:


![]()
Prediction Alignment
在预测阶段,通过调整两个预测的空间分布来进一步明确地对齐这两个任务:P和B。与以往只能基于分类特征或局部特征调整分类预测的中心度分支或IOU分支不同,论文通过使用计算的任务交互特征联合考虑两个任务来对这两个预测进行对齐。值得注意的是,分别对这两个任务执行对齐方法。
如图4所示,论文使用空间概率图M∈(H×W×1)来调整分类预测:
![]()
其中M是从交互特征计算的,从而允许它学习在每个空间位置的两个任务之间的一致性程度。同时,通过交互特征进一步学习空间偏移量映射O∈(H×W×8),用于调整每个位置的预测bounding box,从而对定位预测进行对齐。具体地说,学习的空间偏移使对齐程度最高的锚点能够识别其周围的最佳边界预测:

值得注意的是,每个通道的偏移量都是独立学习的,这意味着对象的每个边界都有自己的学习偏移量。这允许对四个边界进行更准确的预测,因为它们中的每一个都可以单独从其附近最精确的锚点学习。因此,不仅协调了这两个任务,而且通过为每边确定一个精确的锚点来提高定位精度。
对齐图M和O是从交互特征堆栈中自动学习的:

T-Head是一个独立的模块,可以在没有TAL的情况下正常工作。它可以方便地以即插即用的方式应用于各种一级物体检测器,以提高检测性能。
Task Alignment Learning
TAL与以前的方法有两个不同之处。首先,从任务对齐的角度,它基于设计的度量动态地选择高质量的锚。其次,它同时考虑锚点分配和权重。它包括一个样本分配策略和专门为协调这两项任务而设计的新损失。
为了应对NMS,训练实例的锚点分配应该满足以下规则:(1)对齐的锚点应该能够预测高分类分数,并进行精确的联合定位;(2)对齐错误的锚点应该具有低分类分数并随后被抑制。基于这两个目标,论文设计了一个新的锚点对齐度量来明确地度量锚点级别的任务对齐程度。对准度量被集成到样本分配和损失函数中,以动态地改进每个锚点处的预测。
![]()
其中,s和u分别表示分类分数和IOU值。α和β用于控制锚点对齐度量中这两个任务的影响。
对于每个实例,选择取值最大的锚点作为正样本,而将剩余的锚点作为负样本。同样,训练是通过计算专门为调整分类和定位任务而设计的新损失函数来执行的。
Task-aligned Loss
为了显式提高对齐锚点的分类得分,同时降低未对齐锚点(即t值较小)的分类得分,我们在训练过程中使用了替换正锚点的二进制标签。使用归一化t,即ˆt来代替正锚点的二进制标签,其中ˆt由以下两个性质来归一化:(1)确保硬实例的有效学习(对于所有对应的正锚点,这些硬实例通常具有较小的值);(2)基于预测bounding box的精度来保持实例之间的排序。
因此,论文采用简单的实例级归一化来调整ˆt的规模:ˆt的最大值等于每个实例中的最大IOU值(u)。分类任务的损失函数定义如下:
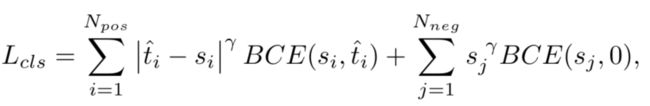
采用焦点损失进行分类,以缓解训练期间负样本和正样本之间的不平衡。其中i表示对应于一个实例的第i个锚点与负值锚点,j表示来自负负锚点的第j个锚点,γ是聚焦参数。
与分类目标类似,根据ˆt重新加权为每个锚点计算的bounding box回归损失,并且GIoU loss(L_GIoU)可以重新表示如下:

其中b和~b表示预测的边界框和相应的ground truth。TAL的总训练损失是L_cli和L_reg的总和。
Conclusion
1. 论文在MS-Coco上进行了广泛的实验,TOOD在MS-CoCO上实现了51.1AP的单模型单尺度测试。这大大超过了最近的单阶段检测器,如ATSS(47.7AP)、GFL(48.2AP)和PAA(49.0AP),它们的参数和FLOPs更少。


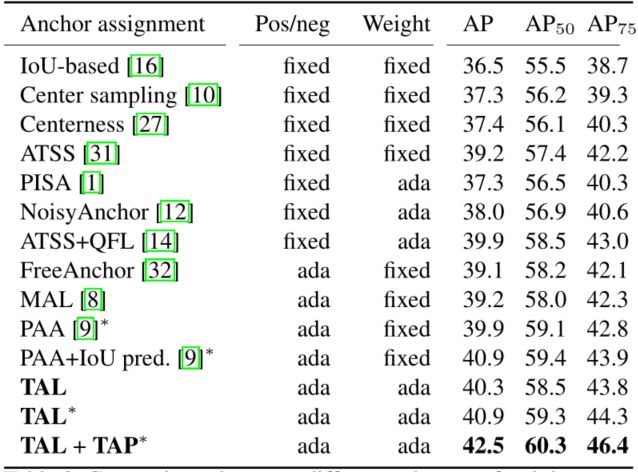
2.不同训练样本分配方案之间的比较。‘Pos/neg’:正/负锚定分配。‘Weight’:锚定权重分配。‘fixed’:固定分配。‘ada’:自适应赋值。在这里,TAP根据最后head tower的分类和定位特征对齐预测。
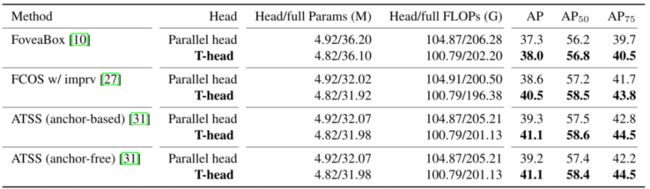
3.不同检测器中不同head结构的比较。
4.可视化

欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章