python sklearn无监督数据分析测试
数据如下格式,这些数据没有标签,需求是想把它们做个聚类,但又不知道可以分几类,那就只能尝试下无监督的方法。

python的sklearn包中有很多无监督聚类方法,下面先做下简单的测试,代码如下
from sklearn.cluster import KMeans, Birch, DBSCAN, MeanShift, estimate_bandwidth, SpectralClustering
from sklearn import metrics
from sklearn.metrics.pairwise import pairwise_distances
from scipy.spatial.distance import pdist, squareform
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import random
from canopy import Canopy
dat = pd.read_csv("./kuse.csv")
data = dat.T
# data = data.drop([''])
# print(len(data))
x = []
count = 0
while True:
try:
x.append(data[count].values.tolist())
count += 1
except:
break
X = np.array(x)
print('\n')
print('#######################K-Means########################')
km = KMeans(n_clusters=5).fit(X)
# 标签结果
rs_labels = km.labels_
# 每个类别的中心点
rs_center_ids = km.cluster_centers_
print(rs_center_ids)
print(rs_labels)
km_y = KMeans(n_clusters=5).fit_predict(X)
print("Calinski-Harabasz Score", metrics.calinski_harabasz_score(X, km_y))
print('###############################################')
print('\n')
print('#########################Birch######################')
bc = Birch(threshold=0.4, branching_factor=30, n_clusters=5, compute_labels=True, copy=True).fit(X)
# 标签结果
rs_labels = bc.subcluster_labels_
# 每个类别的中心点
rs_center_ids = bc.subcluster_centers_
all_labels = bc.labels_
print(rs_center_ids)
print(rs_labels)
bc_y = Birch(threshold=0.4, branching_factor=30, n_clusters=5, compute_labels=True, copy=True).fit_predict(X)
print("Calinski-Harabasz Score", metrics.calinski_harabasz_score(X, bc_y))
print('###############################################')
print('\n')
print('######################DBSCAN#########################')
dbscan = DBSCAN(eps=0.8, min_samples=5, metric='euclidean', metric_params=None, algorithm='ball_tree', leaf_size=30, p=None, n_jobs=1).fit(X)
#'auto', 'ball_tree', 'kd_tree', 'brute'
all_labels = dbscan.labels_
print(all_labels)
dbscan_y = DBSCAN(eps=0.8, min_samples=5, metric='euclidean', metric_params=None, algorithm='ball_tree', leaf_size=30, p=None, n_jobs=1).fit_predict(X)
print("Calinski-Harabasz Score", metrics.calinski_harabasz_score(X, dbscan_y))
print('###############################################')
print('\n')
print('#######################MeanShift########################')
bandwidth = estimate_bandwidth(X, quantile = 0.3, n_samples = None)
ms = MeanShift(bandwidth = bandwidth, bin_seeding = True, max_iter=500)
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
print(cluster_centers)
ms_y = ms.fit_predict(X)
print("Calinski-Harabasz Score", metrics.calinski_harabasz_score(X, ms_y))
print('###############################################')
print('\n')
print('#######################SpectralClustering########################')
sc = SpectralClustering(n_clusters=5, assign_labels='discretize', random_state=0).fit(X)
#'auto', 'ball_tree', 'kd_tree', 'brute'
all_labels = sc.labels_
print(all_labels)
sc_y = SpectralClustering(n_clusters=5, assign_labels='discretize', random_state=0).fit_predict(X)
print("Calinski-Harabasz Score", metrics.calinski_harabasz_score(X, sc_y))
print('###############################################')
scores = []
s = dict()
for index, gamma in enumerate((0.01, 0.1, 1, 5)):
for index, k in enumerate((3, 4, 5, 6, 7)):
pred_y = SpectralClustering(n_clusters=k).fit_predict(X)
print("Calinski-Harabasz Score with gamma=", gamma, "n_cluster=", k, "score=",
metrics.calinski_harabasz_score(X.data, pred_y))
tmp = dict()
tmp['gamma'] = gamma
tmp['n_cluster'] = k
tmp['score'] = metrics.calinski_harabasz_score(X, pred_y)
s[metrics.calinski_harabasz_score(X, pred_y)] = tmp
scores.append(metrics.calinski_harabasz_score(X, pred_y))
print(np.max(scores))
print("max score:")
print(s.get(np.max(scores)))说明:有些人肯定会疑惑,既然是无监督,比如KMeans居然还要给出类别数,那我怎么知道一开始给几类,那你可以参考这个博客的做法
sklearn谱聚类Spectral Clustering(一)运行:以coco标签为例_祥瑞的技术博客-CSDN博客背景:我们需要对多标签的问题,标签进行谱聚类,然后看相应的聚类结果。官方API描述:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.SpectralClustering.html#sklearn.cluster.SpectralClustering目录一、安装sklearn1.1 scikit-le...https://blog.csdn.net/weixin_36474809/article/details/89855869
用迭代的方式配合评价方法metrics.calinski_harabasz_score,得分最高的情况下的类别数就是最佳类别数,具体就是类似于这段代码:
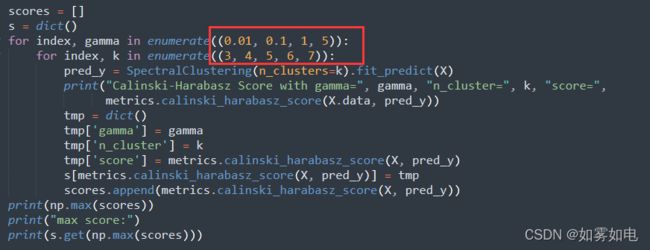
你遍历了最有可能的几个参数就可以了,你会发现一个峰值,除了那个峰值对应的参数,其它参数肯定不行的,得分较低。可以参考我最后给出的结果部分
学习这些的方式:
学习已有的包最好的办法当然是直接去官网,链接:
API Reference — scikit-learn 1.0.1 documentationhttps://scikit-learn.org/stable/modules/classes.html#module-sklearn.cluster打开以后就是官网提供的那些方法
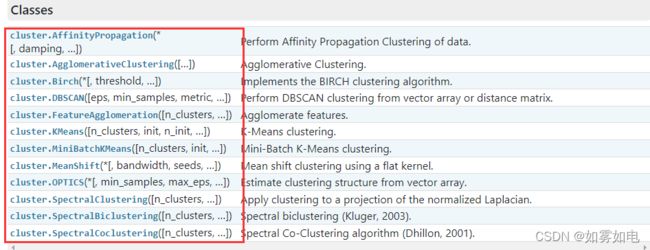
以上这些方法全是无监督聚类方法, 随便点开一个方法后里面会有详细的介绍,几乎不用你再去查怎么用

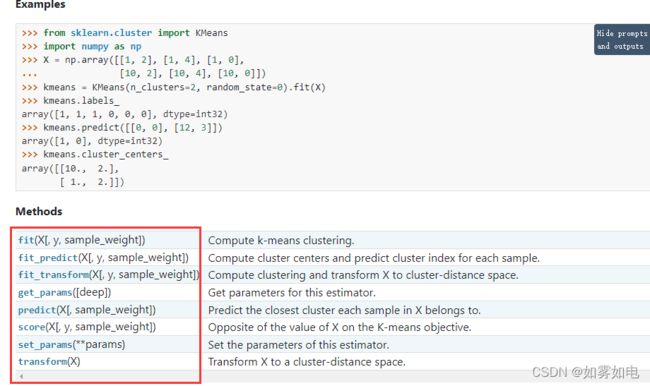
接着就是这个算法包含的属性,有些是你可能会用到的,比如下面红色圈出来的是调用这个类以后的聚类中心属性,具体得到聚类中心怎么得到可以往后看实践部分。

再往后看就是算法类包含的方法,还给了例子,所有算法都是这个套路,你会用一个别的就都会用,具体观察下代码就知道了。
下面是各个算法的分类结果还有官方的评价指标评价的结果,Calinski-Harabasz Score这个值越大说明聚类越好。
#######################K-Means########################
[[0.10238661 0.04652876 0.64257175 0.56025887 0.04940799 0.44693049
0.44693049 0.30257996 3. 0.30351089]
[0.03910997 0.05882337 0.66510772 0.13391711 0.02917814 0.42322102
0.42322102 0.30111248 1. 0.20353977]
[0.07116973 0.11768102 0.29993584 0.14146421 0.06498572 0.29048064
0.29048064 0.51616101 5. 0.20508759]
[0.08476444 0.10926822 0.28438275 0.19259887 0.07765074 0.42020786
0.42020786 0.27644649 2. 0.20605626]
[0.03629227 0.06192236 0.6608674 0.1130219 0.03068587 0.27501765
0.27501765 0.57433743 4. 0.20771638]]
[0 2 4 ... 2 2 2]
Calinski-Harabasz Score 93795.02483707225
###############################################
#########################Birch######################
[[0.10238661 0.04652876 0.64257175 0.56025887 0.04940799 0.44693049
0.44693049 0.30257996 3. 0.30351089]
[0.07116973 0.11768102 0.29993584 0.14146421 0.06498572 0.29048064
0.29048064 0.51616101 5. 0.20508759]
[0.03629227 0.06192236 0.6608674 0.1130219 0.03068587 0.27501765
0.27501765 0.57433743 4. 0.20771638]
[0.03910997 0.05882337 0.66510772 0.13391711 0.02917814 0.42322102
0.42322102 0.30111248 1. 0.20353977]
[0.08476444 0.10926822 0.28438275 0.19259887 0.07765074 0.42020786
0.42020786 0.27644649 2. 0.20605626]]
[2 4 3 1 0]
Calinski-Harabasz Score 93795.02483707225
###############################################
######################DBSCAN#########################
[0 1 2 ... 1 1 1]
Calinski-Harabasz Score 75670.64330246476
###############################################
#######################MeanShift########################
[[0.05766018 0.09578076 0.43784817 0.13046477 0.0517502 0.28505013
0.28505013 0.53773785 4.61677161 0.20477811]
[0.08411639 0.10860097 0.28453402 0.19230271 0.07725466 0.42016314
0.42016314 0.27657423 2. 0.20500095]
[0.03889024 0.05820553 0.66499059 0.13398581 0.02920016 0.42325589
0.42325589 0.301198 1. 0.20301746]
[0.09761513 0.044748 0.64576806 0.55686585 0.04546649 0.44765525
0.44765525 0.30046192 3. 0.29609165]
[0.96625754 0.38837888 0.46391063 0.89552544 0.58666431 0.19630818
0.19630818 0.69882809 3. 1.277805 ]]
Calinski-Harabasz Score 35545.65353257847
###############################################
#######################SpectralClustering########################
[3 4 1 ... 4 4 4]
Calinski-Harabasz Score 93795.02483707225
###############################################
Calinski-Harabasz Score with gamma= 0.01 n_cluster= 3 score= 45354.4481194343
Calinski-Harabasz Score with gamma= 0.01 n_cluster= 4 score= 58594.380870988265
Calinski-Harabasz Score with gamma= 0.01 n_cluster= 5 score= 93795.02483707225
Calinski-Harabasz Score with gamma= 0.01 n_cluster= 6 score= 64379.22511356569
Calinski-Harabasz Score with gamma= 0.01 n_cluster= 7 score= 54295.142816210384
Calinski-Harabasz Score with gamma= 0.1 n_cluster= 3 score= 45354.44811943432
Calinski-Harabasz Score with gamma= 0.1 n_cluster= 4 score= 58594.38087098827
Calinski-Harabasz Score with gamma= 0.1 n_cluster= 5 score= 93795.02483707225
Calinski-Harabasz Score with gamma= 0.1 n_cluster= 6 score= 64435.39142011564
Calinski-Harabasz Score with gamma= 0.1 n_cluster= 7 score= 54337.07322606031
Calinski-Harabasz Score with gamma= 1 n_cluster= 3 score= 45354.4481194343
Calinski-Harabasz Score with gamma= 1 n_cluster= 4 score= 58594.38087098827
Calinski-Harabasz Score with gamma= 1 n_cluster= 5 score= 93795.02483707225
Calinski-Harabasz Score with gamma= 1 n_cluster= 6 score= 64435.39142011564
Calinski-Harabasz Score with gamma= 1 n_cluster= 7 score= 54295.142816210384
Calinski-Harabasz Score with gamma= 5 n_cluster= 3 score= 45354.4481194343
Calinski-Harabasz Score with gamma= 5 n_cluster= 4 score= 58594.38087098827
Calinski-Harabasz Score with gamma= 5 n_cluster= 5 score= 93795.02483707225
Calinski-Harabasz Score with gamma= 5 n_cluster= 6 score= 64435.391420115644
Calinski-Harabasz Score with gamma= 5 n_cluster= 7 score= 54295.14281621037
93795.02483707225
max score:
{'gamma': 5, 'n_cluster': 5, 'score': 93795.02483707225}结果分析:通过对这几个方法的观察发现,最佳的类别数是5类,每个方法得到的结果很一致,就连聚类中心点也一摸一样,唯一不同的是,这些方法具体到每个数据的预测结果时在类别的划分上会有所区别,比如某个数据在KMeans时被划分为第一类,而在用meansift方法时却被分为了第5类。具体怎么验证对错那肯定是要把所有数据都预测了,然后根据你自己的需求判定用哪个方法