Nginx服务器--Nginx服务器的使用笔记
1、Nginx简介
Nginx("engine x") 一个具有高性能的【HTTP】和【反向代理】的【WEB服务器】,同时它也是一个【POP3/SMTP/IMAP代理服务器】,由伊戈尔 • 赛索耶夫(俄罗斯人)使用【C语言】编写的,Nginx的第一个版本是2004年10月4日发布的0.1.0版本。另外值得一提的是伊戈尔 • 赛索耶夫将Nginx的源码进行了开源,这也为Nginx的发展提供了良好的保障。
1.1、一些名词的解释
正向代理和反向代理:以下图说明
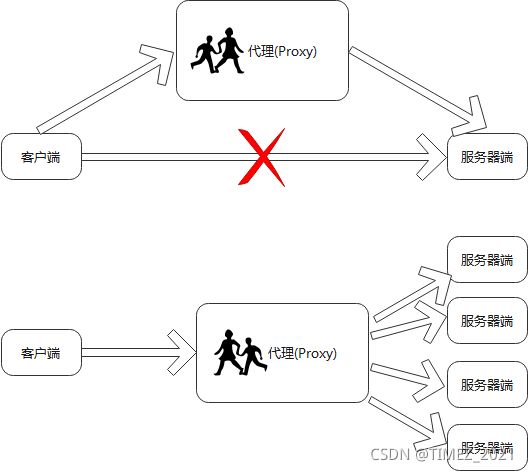
正向代理是上面的情况,我们无法直接的访问某个服务,于是我们访问另外的一台代理服务器,让其代理我们去访问,然后将访问结果返回。我们经常使用的VPN工具就是这个原理。我们无法访问的Google服务可以通过代理的方式去实现。注意这里我们已知真实的目标服务器的ip地址,也知道代理服务器的ip地址。
反向代理是这张图下面的情况,不同的我们只知道代理服务器的地址,并不知道在其后面隐藏的服务,因此反向代理代理的是目标服务器,我们只知道一个地址,通过这个地址就可以访问代理服务器,代理服务器再访问它代理的目标服务器为我们服务。
综上我们可以这也理解,正向代理更强调的是代理服务器代理我们发送接收请求,反向代理更强调代理服务器为目标服务器代理对外提供服务。
1.2、常见服务器对比
在介绍这一节内容之前,我们先来认识一家公司叫Netcraft。
Netcraft公司于1994年底在英国成立,多年来一直致力于互联网市场以及在线安全方面的咨询服务,其中在国际上最具影响力的当属其针对网站服务器、SSL市场所做的客观严谨的分析研究,公司官网每月公布的调研数据(web server survey)已成为当今人们了解全球网站数量以及服务器市场分额情况的主要参考依据,时常被诸如华尔街杂志,英国BBC,Slashdot等媒体报道或引用。
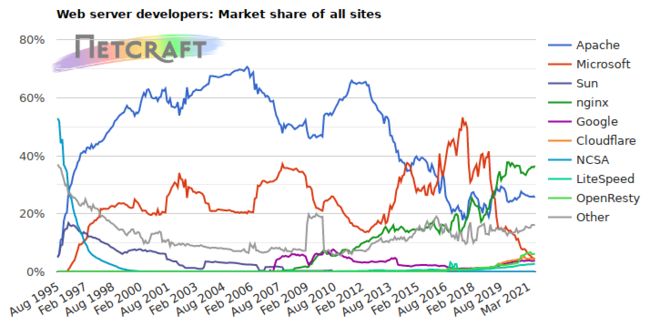
上面这张图展示了1995年以来全球主流Web服务器的市场情况,其中有Apache、Microsoft-
llS、google Servers、Nginx、Tomcat等,而我们在了解新事物的时候,往往习惯通过类比来帮助自己理解事物的概貌。所以下面我们把几种常见的服务器来给大家简单介绍下:
IIS
全称(Internet Information Services)即互联网信息服务,是由微软公司提供的基于windows系统的互联网基本服务。windows作为服务器在稳定性与其他一些性能上都不如类UNIX操作系统,因此在需要高性能Web服务器的场合下,IIS可能就会被"冷落"。
Tomcat
Tomcat是一个运行Servlet和SP的Web应用软件,Tomcat技术先进、性能稳定而且开放源代码,因此深受Java爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的Web应用服务器。但是Tomcat天生是一个重量级的Web服务器,对静态文件和高并发的处理比较弱。并发能力一二百。
Apache
Apache的发展时期很长,同时也有过一段辉煌的业绩。从上图可以看出大概在2014年以前都是市场份额第一的服务器。Apache有很多优点,如稳定、开源、跨平台等。但是它出现的时间太久了,在它兴起的年代,互联网的产业规模远远不如今天,所以它被设计成一个重量级的、不支持高并发的Web服务器。在Apache服务器上,如果有数以万计的并发HTTP请求同时访问,就会导致服务器上消耗大量能存,操作系统内核对成百上千的Apache进程做进程间切换也会消耗大量的CUP资源,并导致HTTP请求的平均响应速度降低,这些都决定了Apache不可能成为高性能的Web服务器。这也促使了Lighttpd和Nginx的出现。历史久远,设计之初没有考虑太多高并发性能
Lighttpd
Lighttpd是德国的一个开源的Web服务器软件,它和Nginx一样,都是轻量级、高性能的Web服务器,欧美的业界开发者比较钟爱Lighttpd,而国内的公司更多的青睐Nginx,同时网上Nginx的资源要更丰富些。
1.3、Nginx的优点
速度更快、并发更高
单次请求或者高并发请求的环境下,Nginx都会比其他Web服务器响应的速度更快。一方面在正常情况下,单次请求会得到更快的响应,另一方面,在高峰期(如有数以万计的并发请求),Nginx比其他Web服务器更快的响应请求。Nginx之所以有这么高的并发处理能力和这么好的性能原因在于Nginx采用了多进程和I/O多路复用(epoll)的底层实现。
配置简单,扩展性强
Nginx的设计极具扩展性,它本身就是由很多模块组成,这些模块的使用可以通过配置文件的配置来添加。这些模块有官方提供的也有第三方提供的模块,如果需要完全可以开发服务自己业务特性的定制模块。
高可靠性
Nginx采用的是多进程模式运行,其中有一个master主进程和N多个worker进程,worker进程的数量我们可以手动设置,每个worker进程之间都是相互独立提供服务,并且master主进程可以在某一个worker进程出错时,快速去"拉起"新的worker进程提供服务。
热部署
现在互联网项目都要求以7*24小时进行服务的提供,针对于这一要求,Nginx也提供了热部署功能,即可以在Nginx不停止的情况下,对Nginx进行文件升级、更新配置和更换日志文件等功能。
成本低、BSD许可证
BSD是一个开源的许可证,世界上的开源许可证有很多,现在比较流行的有六种分别是GPL、BSD、MIT、Mozilla、Apache、LGPL。这六种的区别是什么,我们可以通过下面一张图来解释下:

Nginx本身是开源的,我们不仅可以免费的将Nginx应用在商业领域,而且还可以在项目中直接修改Nginx的源码来定制自己的特殊要求。这些点也都是Nginx为什么能吸引无数开发者继续为Nginx来贡献自己的智慧和青春。OpenRestry [Nginx+L] 、 Tengine
1.4、Nginx的功能特性及常见功能
基本HTTP服务
Nginx可以提供基本HTTP服务,可以作为HTTP代理服务器和反向代理服务器,支持通过缓
存加速访问,可以完成简单的负载均衡和容错,支持包过滤功能,支持SSL等。
- 处理静态文件、处理索引文件以及支持自动索引;
- 提供反向代理服务器,并可以使用缓存加上反向代理,同时完成负载均衡和容错;
- 提供对FastCGl、memcached等服务的缓存机制,,同时完成负载均衡和容错;
- 使用Nginx的模块化特性提供过滤器功能。Nginx基本过滤器包括gzip压缩、ranges支持、chunked响应、XSLT、SSI以及图像缩放等。其中针对包含多个SSI的页面,经由FastCGl或反向代理,SSI过滤器可以并行处理。
- 支持HTTP下的安全套接层安全协议SSL.
- 支持基于加权和依赖的优先权的HTTP/2
高级HTTP服务
- 支持基于名字和IP的虚拟主机设置
- 支持HTTP/1.0中的KEEP-Alive模式和管线(PipeLined)模型连接
- 自定义访问日志格式、带缓存的日志写操作以及快速日志轮转。
- 提供3xx~5xx错误代码重定向功能
- 支持重写(Rewrite)模块扩展
- 支持重新加载配置以及在线升级时无需中断正在处理的请求
- 支持网络监控
- 支持FLV和MP4流媒体传输
邮件服务
Nginx提供邮件代理服务也是其基本开发需求之一,主要包含以下特性:
- 支持IMPA/POP3代理服务功能
- 支持内部SMTP代理服务功能
2、Nginx基础学习
2.1、Nginx环境准备
打开Nginx官网:http://nginx.org
也可以直接进入:http://nginx.org/en/download.html
- Mainline version:Mainline 是 Nginx 目前主力在做的版本,可以说是开发版
- Stable version:最新稳定版,生产环境上建议使用的版本
- Legacy versions:遗留的老版本的稳定版
![]()
图片中其中CHANGES是记录版本变更日志,包括功能新增、修改、优化的说明。pgp是PGP加密计算后的签名,公钥文件用以验证你下载的nginx是否被篡改过。nginx-1.18.0是nginx的linux版本的源码
或者在更全版本的的:http://nginx.org/download/ 这个里面有所有的版本的源码
2.1.1、准备一台Linux服务器
没有网上买在线服务器的可以安装VMWare代替。有关VMWare的一些东西例如VMWare的几种网络模式的区别(需要有计算机网络基础),VMWare安装Linux虚拟机和Windows虚拟机的方法,以及一些Linux虚拟机初始化时一些勾选项一些初始配置项等都可以自行搜索。最后总结需要以下软硬件环境:
VMWare 、CentOS7、 远程Sheel工具:MobaXterm、xsheel、SecureCRT等
(1)确认centos内核
准备一个内核为2.6及以上版本的操作系统,因为linux2.6及以上内核才支持epoll,而Nginx需要解决高并发压力问题是需要用到epoll,所以我们需要有这样的版本要求。
使用uname -a命令来查询Linux内核版本
[root@192 download]# uname -a
Linux 192.168.111.135 3.10.0-693.el7.x86_64 #1 SMP Tue Aug 22 21:09:27 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux(2)确保联网,并且能够用主机ping通
使用ifconfig查看Linux虚拟机的ip地址,连接Vmware虚拟交换机的那个ip地址,一般默认是ens33.
打开主机cmd,使用 ping 命令确保连通性。
你可以使用ping命令ping以下百度试一试能否接如互联网。
(3)确保关闭了防火墙
这一项的要求仅针对于那些对linux系统的防火墙设置规则不太清楚的,建议大家把防火墙都关闭掉,因为我们此次课程主要的内容是对Nginx的学习,把防火墙关闭掉,可以省掉后续Nginx学习过程中遇到的诸多问题。
防火墙操作的有关命令:
systemctl stop firewalld #关闭一次防火墙服务,系统重启后将重新打开
systemctl status firewalld #查看防火墙状态
systemctl disable firewalld #永久关闭防火墙
systemctl enable firewalld #解除禁用
systemctl start firewalld #开启防火墙(4)确认停用selinux
selinux(security-enhanced linux),美国安全局对于强制访问控制的实现,在linux2.6内核以后的版本中,selinux已经成功内核中的一部分。可以说selinux是linux史上最杰出的新安全子系统之一。虽然有了selinux,我们的系统会更安全,但是对于我们的学习Nginx的历程中,会多很多设置,所以这块建议大家将selinux进行关闭。
查看selinux状态命令
[root@192 download]# sestatus
SELinux status: disabled如果你的状态的enable你可以这也修改配置后重启即可关闭
修改配置:
[root@192 download]# vim /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
#SELINUX=enforcing
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted注释掉SELINUX=enforcing添加一行SELINUX=disabled 之后重启即可
2.2、Nginx安装和卸载
Nginx的安装方式有如下:
通过Nginx源码
通过Nginx源码简单安装
通过Nginx源码复杂安装
通过yum安装如果使用Nginx源码安装需要做如下提前准备:
GCC编译器
Nginx是使用C语言编写的程序,因此想要运行Nginx就需要安装一个编译工具。GCC就是一个开源的编译器集合,用于处理各种各样的语言,其中就包含了C语言。
你可以使用gcc --version查看系统是否已经安装了gcc编译器。如果没有安装可以使用如下命令安装gcc编译器(需要连接互联网 -y是对一些询问是否的情况下免于手动输入y)
yum install -y gccPCRE
Nginx在编译过程中需要使用到PCRE库(perlCompatible Regular Expressoin兼容正则表达式库),因为在Nginx的Rewrite模块和http核心模块都会使用到PCRE正则表达式语法。
可以使用如下命令安装
yum install -y pcre pcre-devel #pcre-devel是开发包类似于于c头文件作用可以通过rpm -q pcre pcre-devel查看是否安装成功。
rpm –qa
其中
–a选项是查询所有已经安装的软件包。
-q是查询一个包是否安装
更多有关rpm指令:http://c.biancheng.net/view/817.html
zlib
zlib库提供了开发人员的压缩算法,在Nginx的各个模块中需要使用gzip压缩,所以我们也需要提前安装其库及源代码zlib和zlib-devel
可以使用下面的命令安装检查:
yum install zlib zlib-devel #安装
rpm -q zlib zlib-devel #检查是否安装成功OpenSLL
OpenSSL是一个开放源代码的软件库包,应用程序可以使用这个包进行安全通信,并且避免被窃听。
可以使用下面的命令安装:
yum install openssl openssl-devel #安装
rpm -q openssl openssl-devel #检查是否安装成功#可以一次性安装多个就像 xxx xxx-devel一样
yum install -y gcc pcre pcre-devel zlib zlib-devel openssl openssl-devel
#安装之前使用rpm检查一下系统是否都有,我都没安装,这些都有2.1.1、源码简单安装
(1)下载源码
你可以使用windows下载后上传到你的linux服务器,你也可以使用如下命令下载
wget 链接 #默认下载到当前路径下,也就是pwd命令显示的路径 wget -P 指定目录 链接 #下载到指定目录,wget支持http,https,ftp等,支持断点续传wget后加的是资源的URL
(2)解压缩
tar -xf nginx-xxxx.tar.gz压缩相关基础知识
#两个压缩工具的命令 gzip 路径文件 或 bzip2 路径文件 #都不支持目录,且会删除原文件 gunzip 路径文件.gz 或 bunzip2 路径文件.bz2 #解压缩文件到当前目录 #因为这两种压缩方式都不支持压缩整个目录,所以有了tar #注意tar只是个打包工具,也就是把一个目录以及里面的文件打包成一个文件 tar -cf 生成tar文件路径 要打包的文件 #打包生成tar文件,这个文件没有压缩 #tar配合两个压缩工具的命令 tar -zcf/-jcf 生成tar文件路径 要打包压缩文件或文件夹 ”-”可加可不加 z是合并gzip j是合并bzip2 #-c 是create (-f 路径文件名)表示要输出的文件要放在哪 zcf和jcf顺序不可变 f后面一定是文件名更多有关压缩知识请自行搜索
(3)进入解压后的文件夹,ls之后发现configure文件
相信你并不陌生整个文件,它会检查系统配置以及依赖信息生成目标代码和makefile文件就是
./configure(4)编译安装
make && make install #你也可以分开执行 make 和 make install
2.2.1、Nginx简单源码安装的卸载
将nginx进程关闭
./nginx -s stop将安装的nginx进行删除
rm -rf /usr/local/nginx将安装包之前编译的环境清除掉
make clean
2.2.3、yum安装
使用源码进行简单安装,我们会发现安装的过程比较繁琐,需要提前准备GCC编译器.PCRE兼容正则表达式库、zlib压缩库、OpenSSL安全通信的软件库包,然后才能进行Nginx的安装。
yum相关知识:https://developer.aliyun.com/article/53630
#yum全称Yellow dog Updater, Modified,是为了简化安装,解决包之间的依赖关系的。
#yum命令基本用法如下
yum 功能(install/search/list/...) 包名(nginx /tomcat/.... 可多个) [-y]
yum install docker #安装docker
yum update docker #升级docker
yum remove docker #删除docker
yum clean packages #清除rpm包文件缓存
yum clean headers #清除rpm后文件缓存
yum clean all #清除所有
yum info docker #列出docker信息
yum info installed #列出所有安装了的包的信息
yum repolist #列出yum源信息
yum search docker #搜索包信息
yum list docker #列出docker的包,包括yum源上可安装的包,和已经安装的包信息。
yum list updates #列出可以升级的所有包
yum list installed #列出已经安装的所有包
yum -y install yum-utils #下载yum-utils,有时我们只是想把rpm包下下来。比如要copy到另一台机器上
装啊等等。我们可以用yum-utils来解决。
yumdownloader docker #yum-utils里面的工具,下载docker包,亦可以找到repo文件,找到地址直接wget它
yum install yum-fastestmirror -y #安装yum源选择插件,自动寻找最快的源。
#yum默认都是安装最新版的软件,这样可能会出一些问题,或者我们希望yum安装指定(特定)版本(旧版本)软件包.所以,就顺带分享yum安装指定(特定)版本(旧版本)软件包的方法。只要安装时指明软件包完整的名字即可。
在nginx的这个地址http://nginx.org/en/linux_packages.html
根据上面的方法,首先检查是否安装了yum-utils
(1)安装yum-utils
rpm -q yum-utils #检查是否安装了yum-utils yum install yum-utils #如果没安装,就安装(2)创建yum源文件到指定文件夹
vim /etc/yum.repos.d/nginx.repo先输入一个字符“i”进入插入模式再粘贴下面的内容到这个文件
[nginx-stable] name=nginx stable repo baseurl=http://nginx.org/packages/centos/$releasever/$basearch/ gpgcheck=1 enabled=1 gpgkey=https://nginx.org/keys/nginx_signing.key module_hotfixes=true [nginx-mainline] name=nginx mainline repo baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/ gpgcheck=1 enabled=0 gpgkey=https://nginx.org/keys/nginx_signing.key module_hotfixes=true看这个文件的内容它默认enable的是稳定版,所以我们就不做修改了。
官网说如果你想更换成最新测试版(mainline)版本你就执行下面的命令
sudo yum-config-manager --enable nginx-mainline(3)安装
sudo yum install nginx(4)可以使用如下命令查看yum安装的nginx的目录
whereis nginx
可能的一些问题:当你安装的时候可能会提示没有软件包。通过 yum list 可以看到很多软件包在yum里面没有的。我们可以使用epel源(EPEL : Extra Packages for Enterprise Linux是基于Fedora的一个项目,为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux.)。网上有说这样解决,但是我这样做没有解决掉,所以这种安装方式我就没成功了:
(1)安装epel
sudo yum install epel-release(2)更新系统
yum update(3)再次安装
2.2.4、源码简单安装和yum安装的差异
首先提前学一下 ./nginx -V 命令,通过该命令可以看安装的nginx的版本及相关配置信息。
简单源码安装后使用该命令的结果:
[root@192 sbin]# ./nginx -V
nginx version: nginx/1.20.1
built by gcc 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
configure arguments:yum安装后使用该命令的结果(由于我yum没有安装成功,这是网上找的yum安装后执行该命令的类似结果):
[root@localhost sbin]#./nginx -V
nginx version:nginx/1.16.i
built by gcc 4.8.5 20150623 (Red Hat 4.8.5-36)(GCC)
built with openssL 1.0.2k-fips26 Jan 2017
TLS SNI support enabled
configure arguments: --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf--error-log-path=/var/log/nginx/error.log -http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/ run/nginx.lock--http-client-body-temp-path=/var/cache/nginx/client_temp'--http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp --user=nginx --group=nginx --with-compat--with-file-aio --with-threads --with-http_addition_module --with-http_auth_request_module--with-http_dav_module --with-http_flv_module--with-http_9unzip_module --with-http_gzip_static_module --with-http_mp4_module --with-http_randomindex_module --with-http_realip_module --with-http_secure_link_module --with-http_slice_module --with-http_ssl_module--with-http_stub_status_module --with-http_sub_module --with-http_v2_module --with-mail--with-mail_ssl_module --with-stream --with-stream_realip_module --with-stream_ssl_module --with-stream_ssl_preread_module --with-cc-opt='-02 -g -pipe -wall -wp, -D_FORTIFY_$OURCE=2-fexceptions .fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches-m64 -mtune=generic -fPIC' --with-ld-opt='-wl,-z,relro -wl,-z,now -pie'从两个结果的对比,我们可以看出其中yum安装会给出特别多的配置参数,这个配置参数就是我们在源码安装第一步执行configure时可以在其后面指定的参数,我们简单安装并没有指定这些参数。
2.2.5、Nginx的源码复杂安装
这种方式和简单的安装配置不同的地方在第一步,通过./configure来对编译参数进行设置,需要我们手动来指定。那么都有哪些参数可以进行设置,接下来我们进行一个详细的说明。
其中带PATH的:一般是和路径相关的配置信息
以with开通的参数:是安装时要求启动的模块,默认是关闭的
以without开通的参数:是安装时要求关闭的模块,默认是开启的
先简单的认识一些路径配置,通过这些配置进行一个简单的编译安装
--prefix = PATH #指向Nginx的安装目录,默认值为/usr/local/nginx
--sbin-path = PATH #指向(执行)程序文件(nginx)的路径,默认/sbin/nginx
--modules-path = PATH #指向Nginx动态模块安装目录,默认为/modules
--conf-path = PATH #指向配置文件(nginx.conf)的路径,默认/conf/nginx.conf
--error-log-path = PATH #指向错误日志文件的路径,默认值/logs/error.log
--http-log-path = PATH #指向访问日志文件的路径,默认值/logs/access.log
--pid-path = PATH #指向Nginx启动后进程id(Pid),默认/logs/nginx.pid
--lock-path = PATH #指向Nginx锁文件的存放路径,默认/logs/nginx.lock
#注意写参数时不应该写,应该写全 这里只是简单的罗列了几个,总的参数有百十个,可以在安装包解压后的目录使用查看全部参数以及解释信息
./configure --help我们可以使用参数来编译一次源码,自己定义默认的目录位置,不过建议与默认统一方便学习
./configure --prefix=/usr/local/nginx \
--sbin-path=/usr/local/nginx/sbin/nginx \
--modules-path=/usr/local/nginx/modules \
--conf-path=/usr/local/nginx/conf/nginx.conf \
--error-log-path=/usr/local/nginx/logs/error.log \
--http-log-path=/usr/local/nginx/logs/access.log \
--pid-path=/usr/local/nginx/logs/nginx.pid \
--lock-path=/usr/local/nginx/logs/nginx.lock #注意右斜线前面有空格,等号两边没有空格make && make install2.3、Nginx目录结构分析
在使用Nginx之前,我们先对安装好的Nginx目录文件进行一个分析,在这块给大家介绍一个工具tree,通过tree我们可以很方面的去查看centos系统上的文件目录结构,当然,如果想使用tree工具,就得先通过以下命令来进行安装:
yum insta1l -y tree安装成功后,可以通过执行
tree /usr/loca1/nginx(tree后面跟的是Nginx的安装目录),获取的结果如下:
[root@localhost nginx]# tree /usr/local/nginx
/usr/local/nginx
├── conf
│ ├── fastcgi.conf
│ ├── fastcgi.conf.default
│ ├── fastcgi_params
│ ├── fastcgi_params.default
│ ├── koi-utf
│ ├── koi-win
│ ├── mime.types
│ ├── mime.types.default
│ ├── nginx.conf
│ ├── nginx.conf.default
│ ├── scgi_params
│ ├── scgi_params.default
│ ├── uwsgi_params
│ ├── uwsgi_params.default
│ └── win-utf
├── html
│ ├── 50x.html
│ └── index.html
├── logs
└── sbin
└── nginx
下面对该目录的结构进行简单的介绍:
首先所有的配置文件都有一个副本为的是在我们把配置文件改的很乱的时候可以用来恢复到一个默认配置文件的状态其命名为配置文件名.default,下面的说明中就不做介绍
一级子目录conf是nginx的所有配置文件目录,里面的结构如下
CGI(Common Gateway Interface)通用网关【接口】,主要解决的问题是从客户端发送一个请求和数据,服务端获取到请求和数据后可以调用调用CGl【程序】处理及相应结果给客户端的一种标准规范。
fastcgi.conf #是fastcgi相关的配置文件
fastcgi_params #fastcgi的参数备份文件
scgi_params #scgi的参数文件
uwsgi_params #uwsgi的参数备份文件
mime.types #记录的是HTTP协议中Content-Type的值和文件后缀的对应关系
nginx.conf #nginx的核心配置文件,非常重要
koi-utf、koi-win、win-utf #这三个文件都是与编码转换映射相关的配置文件,用来将一种编码转化成另一种编码
一级子目录html下存放是nginx自带的两个静态页面
50x.html #访问失败后的失败页面
index.html #成功访问默认的首页
一级子目录logs记录入门文件,启动nginx后里面会有access.log、error.log、nginx.pid三个文件分别是访问日志,错误日志、nginx的进程号
sbin里面存放的是nginx执行文件,用以执行命令
2.4、Nginx服务的信号量控制
主要需要搞清楚以下几点:
- Nginx中的master和worker进程?
- Nginx的工作方式?
- 如何获取进程的PID?
- 信号有哪些?
- 如何通过信号控制Nginx的启停等相关操作?
Nginx的高性能与其架构模式有关,Nginx默认采用的是多进程的方式来工作的,启动Nginx服务后,可以通过如下命令查看Nginx相关的进程信息:
ps -ef|grep nginx #-e entire完全的,显示有关其他用户进程的信息,包括那些没有控制终端的进程
#-f 格式化显示,uid, pid, parent pid, recent CPU usage, process start time, controlling tty,elapsed CPU usage, and the associated command
首先启动nginx
cd /usr/local/nginx/sbin
./nginx结果如下:
[root@localhost sbin]# ps -ef|grep nginx
root 14892 1 0 06:41 ? 00:00:00 nginx: master process ./nginx
nobody 14894 14892 0 06:41 ? 00:00:00 nginx: worker process
root 15531 3248 0 06:48 pts/0 00:00:00 grep --color=auto nginx
从上图中可以看到,Nginx后台进程中包含一个master进程和多个(图中只有一个,可以有多个)worker进程,master进程主要用来管理worker进程,包含接收外界的信息,并将接收到的信号发送给各个worker进程,监控worker进程的状态,当worker进程出现异常退出后,会自动重新启动新的worker进程。而worker进程则是专门用来处理用户请求的,各个worker进程之间是平等的并且相互独立,处理请求的机会也是一样的。
root 15531 3248 0 06:48 pts/0 00:00:00 grep --color=auto nginx这行是因为你使用ps -ef|grep nginx导致的的一个与nginx字样有关的grep的进程
nginx的进程模型,我们可以通过下图来说明下:

作为管理员,只需要通过给master进程发送控制信号就可以控制Nginx,这个时候我们需要有两个前提条件,一个是mater进程在运行,一个是我们发信号(操作系统叫信号量)控制
(1)要想要操作Nginx的master进程,就需要获取到master进程的进ID,获取方式可以从前面我们一直提到过的nginx.pid文件。主要方式有两种:
ps -ef | grep nginx #根据结果查看master进程的pid
#使用nginx.pid文件
cat /usr/local/nginx/logs/nginx.pid
more /usr/local/nginx/logs/nginx.pid
#使用"`"这个符号将命令引住,就可以实现将其输出作为其他命令的参数值输入(2)信号表
| 信号 | 作用 |
|---|---|
| TERM/INT | 立即关闭整个服务 |
| QUIT | 优雅的关闭服务,即处理完最后的请求后关闭 |
| HUP | 重新读取配置文件,重新创建worker进程使得配置生效 |
| USR1 | 重新链接到另一个日志文件,可以搭配周期任务做日志切割 |
| USR2 | 平滑升级到最新版本的nginx,不中断服务 |
| WINCH | 所有子进程不在接收新连接,相当于给work的QUIT指令,但是与QUIT的区别是master进程不退出,也就是程序不关闭 |
发送信号的方法是
kill -signal PID #例如 kill -INT 123456所以有如下命令
kill -INT `cat /usr/local/nginx/logs/nginx.pid` #立即关闭nginx
kill -TERM `cat /usr/local/nginx/logs/nginx.pid` #立即关闭nginx
kill -QUIT `cat /usr/local/nginx/logs/nginx.pid` #优雅关闭
kill -HUP `cat /usr/local/nginx/logs/nginx.pid` #让nginx动态读取配置
kill......使用USR1信号重新链接日志文件
这里要强调一下这个信号量,首先需要的是在Linux中我们的程序和文件的关联并不是通过文件的名字,其实文件的名字只是文件的一个属性,在磁盘中存储的也是描述符里面的文件名而已,我们的系统与文件关联的是文件的物理存储地址,“所以有些同学想的直接把access.log改个名字,之后的访问不就直接会写入新的access.log这种想法其实是不正确的”。无论我们的文件怎么改名字你都会发现访问日志都会追加在你改过名字的文件里面,这点你可以看我下面的验证,所以有了这个信号量我们就可以控制程序链接到新的文件中,进而做日志分割,当然可以搭配上周期任务+shell脚本,自动化完成定时日志分割。下面做一个小验证:
首先开启nginx服务器
./nginx此时你的nginx链接的访问日志默认是access.log,你可以使用浏览器访问一下nginx,用你的主机输入虚拟机ip作为网址访问即可。可以发现access.log文件有新的内容增加,使用如下命令将文件改名:
cd /usr/local/nginx/logs/ # 进入这个文件夹
mv access.log abc.log # 重命名为abc.log
可以使用如下命令追踪这个abc.log的变化
tail -f abc.log #-f 是follow追踪的意思接着你再访问一次nginx,你会发现虽然你改过名字但是还是会向这个文件增加内容。
你给它发个USR1的信号量
kill -USR1 `cat /usr/local/nginx/logs/nginx.pid`你直接ls一下就能发现access.log又被新建了一个,并且新的访问记录被写入了这个新建的文件,顺滑的切换了。
使用USR2信号给master进程,实现平滑的升级,添加新模块,移除模块等等操作
下面是一个简单的描述执行之后会发生什么。
发送USR2信号给master进程,告诉master进程要平滑升级,这个时候,会重新开启对应的master进程和work进程,整个系统中将会有两个master进程,并且新的master进程的PID会被记录在/usr/loca1/nginx/logs/nginx.pid而之前的旧的/usr/loca1/nginx/logs/nginx.pid会被重命名为/usr/loca1/nginx/1ogs/nginx.pid.oldbin,接着再次发送QUIT信号给旧的master进程,让其处理完请求后再进行关闭
[root@192 logs]# ps -ef | grep nginx
root 22928 1 0 07:57 ? 00:00:00 nginx: master process ./nginx
nobody 22930 22928 0 07:57 ? 00:00:00 nginx: worker process
root 24500 22928 0 08:17 ? 00:00:00 nginx: master process ./nginx
nobody 24503 24500 0 08:17 ? 00:00:00 nginx: worker process
root 24533 16221 0 08:17 pts/0 00:00:00 grep --color=auto nginx
可以看到下面这个 master process的父进程id是22928,也就是第一个master process。 ↵
所以读到现在了,聪明的你有没有想到怎么平滑的升级,没错就是用源码的configure重新编译,这是更改参数进行模块的添加和减少,重新编译后生成的目标文件中的心得nginx执行文件替换原来的sbin下的nginx执行文件,也可以将原来的sbin下的nginx文件重命名备份起来,之后将新编译的nginx执行文件复制到sbin目录下,发送USR2信号,再发送QUIT信号给旧的mstaer进程,实现升级。具体的再后面会讲,这里只做了解。
2.5、Nginx命令控制
此方式是通过Nginx安装目录下的sbin下的可执行文件nginx来进行Nginx状态的控制,我们可以通过nginx -h来查看都有哪些参数可以用:
[root@192 sbin]# ./nginx -?
nginx version: nginx/1.20.1
Usage: nginx [-?hvVtTq] [-s signal] [-p prefix]
[-e filename] [-c filename] [-g directives]
Options:
-?,-h : this help
-v : show version and exit
-V : show version and configure options then exit
-t : test configuration and exit
-T : test configuration, dump it and exit
-q : suppress non-error messages during configuration testing
-s signal : send signal to a master process: stop, quit, reopen, reload
-p prefix : set prefix path (default: /usr/local/nginx/)
-e filename : set error log file (default: /usr/local/nginx/logs/error.log)
-c filename : set configuration file (default: /usr/local/nginx/conf/nginx.conf)
-g directives : set global directives out of configuration file
#翻译后的
Options:
-?,-h : 帮助选项
-v : 显示版本,然后退出
-V : 显示版本和安装时的configure agrs,然后退出,我们之前就用的这个选项
-t : 测试配置文件是否正确,如果错误就提示错误地方
-T : 测试配置文件是否正确,如果正确就打印出所有配置内容,如果错误那么和 -t效果一样
-q : 测试期间禁止显示非错误的信息
#对nginx -t/T 如果后面没有配置文件的路径则测试的是默认路径,如果有文件路径,则测试的这个路径指定的文件
-s signal : 发信号量给主进程,可以发的有: stop, quit, reopen, reload 分别对应INT/TERM QUIT USR1 HUP
-p prefix : 设置prefix 路径 (默认: /usr/local/nginx/)
-e filename : 设置错误日志文件位置(default: /usr/local/nginx/logs/error.log)
-c filename : 设置配置文件位置 (default: /usr/local/nginx/conf/nginx.conf)
-g directives : 设置在配置文件外补充的配置,使用命令行的方式
#后面这几种都是启动时给的本次启动有效的参数,仅对本次启动有效所以下面是一些基本的命令
./nginx -s stop #立即停止nginx
./nginx -s reopen #重新链接日志文件
./nginx -s quit #优雅的退出
./nginx -s reload #重新加载配置
./nginx -t #测试默认位置配置文件是否有错误
./nginx -t /nginx.conf #测试根目录下nginx.conf文件是否有配置错误2.6、Nginx使用USR2进行平滑升级
在前面讲到USR2信号的时候,我们说过,其作用就是在Nginx改动模块或是升级新版本时可以在不停止服务的情况下进行。下面以新增模块为例进行演示:
在后面的一个章节中我们会使用一个叫ngx_http_gzip_static_module模块
1、运行nginx,模拟正在运行中的nginx,此时需要升级的需求:进入sbin下执行./nginx
2、还是在这个文件夹中执行./nginx -V查看当时源码安装时指定的configure args信息,然后找个文本文件把这些参数给备份起来。然后还是在这个目录下把这个可执行文件nginx重命名一下如重命名为nginxold
mv nginx nginxold3、进入当时源码安装时的源码文件夹
4、因为当时我们已经执行过configure了,所以先执行make clean删除原来预编译生成的makefile和objs文件夹。
5、重新执行configure在原来参数基础上加上新增模块
./configure 你原来的参数信息+空格+--with-http_gzip_static_module#例如 [root@localhost nginx-1.20.1]# ./configure --prefix=/usr/local/nginx --with-http_gzip_static_module6、执行make命令进行编译
7、进入objs文件夹,此时由configure生成的源码在执行make指令后被编译成如下
[root@localhost objs]# ls autoconf.err nginx ngx_auto_config.h ngx_modules.c src Makefile nginx.8 ngx_auto_headers.h ngx_modules.o8、将nginx可执行文件(这已经是升级以后的可执行文件了)复制到我们的/usr/local/nginx/sbin这个文件夹(这是我的nginx安装目录,因人而异)
cp nginx /usr/local/nginx/sbin9、进入源码目录(就是configure所在目录,此时你可能是在objs下)执行make upgrade
[root@localhost nginx-1.20.1]# make upgrade /usr/local/nginx/sbin/nginx -t nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful kill -USR2 `cat /usr/local/nginx/logs/nginx.pid` sleep 1 test -f /usr/local/nginx/logs/nginx.pid.oldbin kill -QUIT `cat /usr/local/nginx/logs/nginx.pid.oldbin`
整个过程下来我们就已经升级完成了,乍一看和USR2有啥关系,其实看最后一步执行结果的屏幕回显信息,其实make upgrade里面会首先去测试一下nginx.conf是否有错误,之后给这个时候的nginx(旧的进程)发一个USR2的信号,我们在之前学过,当这个信号发出后,nginx会重新启动一套nginx进程里面有nginx新的master进程和若干个worker(和配置的woker的数量有关),并且有关原来的进程的pid会被重命名为nginx.pid.oldbin,那么回到回显信息,是不是最后一步就是给这个进程id号发了一个QUIT信号让其优雅的退出。其实make update的整个过程我们都可以自己一步一步执行对应的指令去完成,nginx给我们一个指令让其可以通过一个指令来完成。升级的过程类似,就是之间的一些参数不需要新增,直接对新的源码编译,将安装源码的最后一步的make install改为 “将原来sbin下nginx执行文件备份,移动nginx文件到sbin下。执行make upgrade等操作”
2.7、Nginx的配置文件的简单介绍
首先,你可以将conf下的nginx.conf拷贝一份到windows系统中使用记事本等打开来学习。
#默认配置文件
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
这是一个我删掉所有注释掉的参数后的配置文件,它可以被分为三个大区域,全局区、events区和http区,并且http中可以有多个sever块,每个sever块里面可以有多个location块。
指令名 指令值; #全局块,主要设置Nginx服务器整体运行的配置指令
#events块,主要设置,Nginx服务器与用户的网络连接,这一部分对Nginx服务器的性
能影响较大
events {
指令名 指令值;
}
#http块,是Nginx服务器配置中的重要部分,代理、缓存、日志记录、第三方模块配置...
http {
指令名 指令值;
server {
#server块,是Nginx配置和虚拟主机相关的内容
指令名 指令值;
location/ .{
#location块,基于Nginx服务器接收请求字符串后与location后面的值进行匹配,对特定请求进行处理
指令名 指令值;
}
...
}
...
}2.7.1、全局块配置简单介绍
user指令
(1)、user:用于配置运行Nginx服务器的worker进程的用户和用户组。
| 语法 | user user[group] |
| 默认值 | nobody |
| 位置 | 全局块 |
当执行ps -ef | grep nginx的时候那个 创建子进程worker的用户名默认是nobody这个在之前的时候一定会有朋友可能就已经发现了,我们使用这个指令可以更改创建worker的用户,从而达到访问权限的管理。
该属性可以在编译时规定语法如下
./configure --user=user --group=user'group如果在两个地方都进行了设置,最终生效的是配置文件中的配置。
使用示例:
1、在全局块中设置一个用户信息如www(不要忘记分号)
user www;此时你进行 ./nginx -t测试是不能通过的因为系统中没有www名字的用户
2、创建www用户
useradd www3、在html目录下创建index1.html,并且改变其访问权限
To Be The No.1
chmod 640 index1.html4、更改配置文件,添加默认主页index1.html
location / { root html; index index1.html index.html index.htm; }5、访问nginx,发现403 Forbidden没有权限。
6、更改index1.html访问权限chmod 644 index1.html之后可以访问。
这个例子其实很勉强,主要是想说明创建worker进程的用户要有访问页面的读的权限才能给用户提供服务访问这个页面。还有一些其他的操作也需要这个用户有权限才可以。这样的设计可以使得系统的网页访问权限更加的精细,更加的安全。
master_process以及worker_processes
master_process用来控制是否开启工作进程,worker_processes用来指定开启的工作进程的数量。
| 语法 | master_process on|off; |
| 默认值 | on |
| 位置 | 全局块 |
| 语法 | worker_processes Num/auto |
| 默认值 | 1 |
| 位置 | 全局块 |
当你指定master_process为off时那么nginx启动是不会创建worker进程的(此配置修改,通过reload指令不能重读配置,需要真正的重启nginx才能生效)(此配置作用后,worker_processes会失效)。
worker_processes用于指定Nginx生成工作进程的数量,这个是Nginx实现并发处理服务的关键所在。理论上这个值越大越好,然而这个值的设置效果受到服务器的处理器等硬件设备的限制,建议是cpu数*单cpu内核数
daemon:设定Nginx是否以守护进程的方式运行
所谓守护进程就是一种可以在后台执行的服务进程,特点是可以独立于控制终端,不会随着终端的关闭而停止。
| 语法 | daemon on|off |
| 默认值 | on |
| 位置 | 全局块 |
默认情况是以守护进程运行,所有我们每次执行./nginx时命令行没有阻塞,可以尝试将其改为off测试,此时执行./nginx后控制终端会阻塞,当关闭终端后进程也就被停止了。
pid:用来配置Nginx当前master进程的进程号id的存储位置
| 语法 | pid file |
| 默认值 | logs/nginx.pid |
| 位置 | 全局块 |
该属性也可以通过 ./configure --pid-path=PATH来指定,同时指定以配置文件为准
error_log:指定Nginx错误日志存放路径
| 语法 | error_log file[日志级别] |
| 默认值 | logs/error.log error |
| 位置 | 全局块、http、server、location |
该属性可以通过 ./configure --error-log-path=PATH来指定
其中日志级别有:debug、info、notice、warn、error、crit、alert、emerg,不建议设置成info以下级别,因为会造成大量日志写入造成巨大的IO消耗,影响Nginx的性能。
include:用来引入其他的配置文件,使得Nginx的配置更加灵活
| 语法 | include file |
| 位置 | any |
例如最上面示例配置文件中的
include mime.types;就是引入外部的mime对应,以达到灵活配置的。
2.7.2、events块配置简单介绍
accept_mutex:用来设置Nginx网络连接序列化
accept_mutex_delay:当启用accept_mutex时,只有一个具有互斥锁的worker程序接受连接,而其他工作程序则轮流等待。 accept_mutex_delay对应于worker等待的时间帧,然后它尝试获取互斥锁并开始接受新的连接。 默认值为500毫秒
| 语法 | accept_mutex on|off |
| 默认值 | on |
| 位置 | events块 |
| 语法 | accept_mutex_delay Num+单位 |
| 默认值 | 500ms |
| 位置 | events块 |
这个配置主要可以用来解决常说的"惊群"问题。大致意思是在某一个时刻,客户端发来一个请求连接,Nginx后台是以多进程的工作模式,也就是说有多个worker进程会被同时唤醒,但是最终只会有一个进程可以获取到连接,如果每次唤醒的进程数目太多,就会影响Nginx的整体性能。如果将上述值设置为on(开启状态),将会对多个Nginx进程接收连接进行序列号,一个个来唤醒接收,就防止了多个进程对连接的争抢。(在操作系统同步部分mutex就是那个互斥量,只能有指定数量的线程/进程获取,当其数量被减少到0则线程/进程再获取会被放入阻塞后的等待队列)
multi_accept:用来设置是否允许同时接收多个网络连接
| 语法 | multi_accept on|off |
| 默认值 | off |
| 位置 | events块 |
如果multi_accept被设置成off,那么nginx一个工作进程只能同时接受一个新的连接。否则,一个工作进程可以同时接受所有的新连接,或者这样说:multi_accept指令使得NGINX worker能够在获得新连接的通知时尽可能多的接受连接。 此指令的作用是立即接受所有连接放到监听队列中。 如果指令被禁用,worker进程将逐个接受连接。
worker_connections:用来配置单个worker进程最大连接数
| 语法 | worker_connections Num |
| 默认值 | 512 |
| 位置 | events块 |
这里的连接数不仅仅包括和前端用户建立的连接数,而是包括所有可能的连接数。另外,num值不能大于操作系统支持打开的最大文件句柄数量。
use:用来设置Nginx服务器选择哪种事件驱动来处理网络消息
| 语法 | use method |
| 默认值 | 根据操作系统来定 |
| 位置 | events块 |
注意:此处所选择事件处理模型是Nginx优化部分的一个重要内容,method的可选值有select/poll/epoll/kqueue等,之前在准备centos环境的时候,我们强调过要使用linux内核在2.6以上,就是为了能使用epoll函数来优化Nginx。另外这些值的选择,我们也可以在编译的时候使用
--with-select_module、 --without-select_module 、
--with-poll_module、 --without-po11_module
来设置是否需要将对应的事件驱动模块编译到Nginx的内核。
events块配置示例
events{
accept_mutex on;
multi_accept on;
worker_connections 1024;
use epoll;
}2.7.3、http块配置简单介绍
自定义MIME-Type
我们都知道浏览器中可以显示的内容有HTML、XML、GIF等种类繁多的文件、媒体等资源,浏览器为了区分这些资源,就需要使用MIME Type。所以说MIME Type是网络资源的媒体类型。Nginx作为web服务器,也需要能够识别前端请求的资源类型。
在Nginx的配置文件中,默认有两行配置
include mime.types;
default_type application/octet-stream;(1)、default_type:用来配置Nginx响应前端请求的MIME类型。
| 语法 | default_type mime-type |
| 默认值 | text/plain |
| 位置 | http、server、location |
include mime.types指令的作用是引入mime.types文件的内容到这个位置,该文件的结构如下
types{
MIME类型 文件拓展名
}配置文件中给的配置application/octet-stream是指可以响应任意的二进制流数据,下面给一个关于default_type配置的例子。
在默认sever(第一个sever)中添加如下location
location /getText { default_type text/plain; return 200 "哈哈哈哈哈
"; }
使用浏览器访问 192.168.111.135/getText的结果是这样的
If there is Chinese,The display will make you mistunderstand!
这个会以文本的方式显示到浏览器的页面上,并不是大标题形式,这也就是浏览器识别到 text/plain的响应头,所处理的方式。配置中的return是直接返回给浏览器内容,而不再找对应目录或目录下的默认首页。
修改配置文件
location /getText { default_type text/html; return 200 "If there is Chinese,The display will make you mistunderstand!
"; }
重新加载配置
oot@192 conf]# cd ../sbin [root@192 sbin]# ./nginx -s reload结果文字以HTML的形式展示在页面(加粗标题)
自定义服务日志
Nginx中日志类型分access.log、error.log。
access.log用来记录用户所有访问请求,error.log用来记录nginx运行时的错误信息。
Nginx服务器支持对服务日志的格式、大小、输出等进行设置,需要使用如下指令:
(1)、access_log:用来设置用户访问日志的相关属性。
| 语法 | access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]]; |
| 默认值 | logs/access.log combined |
| 位置 | http、server、location |
在configure时也可以指定,两者都配置的情况下,配置文件为准,另外所有的有多个位置都可以配置的参数,都是作用于具体的作用域中。
参数中的format是指定的下面这个log_format指令的name的值用来绑定具体的log_format.
(2)、log_format:用来指定日志的输出格式。
| 语法 | log_format name [escape=default|json|none] string...; |
| 默认值 | logs_format combined "..." |
| 位置 | http |
#log_format的默认值
# log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';更多请看:https://www.cnblogs.com/Mr-Ding/p/9539867.html
有关log_format里面的部分变量的含义(这些变量是nginx的变量,别的地方也可以用)
$remote_addr 记录访问网站的客户端地址;
$http_x_forwarded_for 当前端有代理服务器时,设置web节点记录客户端地址的配置,此参数生效的前提是代理服务器上也进行了相关的x_forwarded_for设置;
$remote_user 远程客户端用户名称;
$time_local 记录访问时间与时区;
$request 用户的http请求起始行信息;
$status http状态码,记录请求返回的状态,例如200、404、301等;
$body_bytes_sent 服务器发给客户端的响应body字节数;
$http_referer 记录此次请求是从哪个链接访问呢过来的,可以根据referer进行防盗链设置;
$http_user_agent 记录客户端访问信息,例如:浏览器、手机客户端等;更多变量见:http://nginx.org/en/docs/http/ngx_http_log_module.html
下面是一个示例:
修改配置:
#在http块中添加 log_format test '我的ip:$remote_addr 我的浏览器信息:$http_user_agent'; #更改location如下 location / { root html; index index.html index.htm; access_log logs/abc.log test; }测试并重新加载配置
[root@192 sbin]# ./nginx -t [root@192 sbin]# ./nginx -s reload进入logs目录执行tail -f abc.log,进行追踪
使用浏览器访问 192.168.111.135/,文件会多出如下信息
我的ip:192.168.111.1 我的浏览器信息:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36我们访问其他的地址,如上节写的 192.168.111.135/getText,它的日志依然是在默认日志access.log中,这也就是说配置到哪个作用域下,只对该作用域有效。这样设计的目的也为不同服务器,甚至是不同的链接的访问日志做了划分。
其他配置指令
(1)sendfile:用来设置Nginx服务器是否使用sendfile()传输文件,该属性可以大大提高Nginx处理静态资源的性能,有关sendfile的更多原理部分,请看Nginx静态资源部分(后面)
| 语法 | sedfile on | off |
| 默认值 | off |
| 位置 | http、server、location |
(2)keepalive_timeout:用来设置长连接的超时时间。
为什么使用长连接???
我们都知道HTTP是一种无状态协议,客户端向服务端发送一个TCP请求,服务端响应完毕后断开连接。
如何客户端向服务端发送多个请求,每个请求都需要重新创建一次连接,效率相对来说比较多,使用keepalive模式,可以告诉服务器端在处理完一个请求后保持这个TCP连接的打开状态,若接收到来自这个客户端的其他请求,服务端就会利用这个未被关闭的连接,而不需要重新创建一个新连接,提升效率,但是这个连接也不能一直保持,这样的话,连接如果过多,也会是服务端的性能下降,这个时候就需要我们进行设置其的超时时间。
| 语法 | keepalive_timeout time |
| 默认值 | keepalive_timeout 75s |
| 位置 | http、server、location |
(3)、keepalive_requests:用来设置一个keep-alive连接的次数。
一个长连接可以被客户端使用的次数,使用次数超过这个限制,将断开连接,重新进行tcp握手。
| 语法 | keepalive_requests Num |
| 默认值 | 100 |
| 位置 | http、server、location |
2.7.4、http-server和http-location块配置
server块和location块都是我们要重点讲解和学习的内容,因为我们后面会对Nginx的功能进行详细讲解,所以这块内容就放到静态资源部署的地方给大家详细说明。本节我们主要来认识下Nginx默认给的nginx.conf中的相关内容,以及server块与location块在使用的时候需要注意的一些内容。
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}listen是该服务器(服务器可以有多个)需要监听的端口以及一些其他的配置,有关listen的配置在nginx静态资源那一块再聊。
location是匹配用户浏览器的地址,详细信息也要等到后边聊,error_page是发生错误时跳转的页面(对浏览器来说不是重定向,这是是nginx服务器给重定向的页面)。sever_name配置指定域名,只有使用该域名才能访问得到此服务器部署的资源。
在location里面的root是指当你访问路径命中之后会进入这个文件夹去找你访问的静态资源,index是在你没有访问静态资源(你访问的是个路径类似“/”时)配置的默认首页,这个默认首页会触发Nginx的再一次匹配也就是说如果你的默认首页是index.html,nginx会使用你的访问路径拼接上index.html再次匹配这里面的所有location,具体location的匹配规则在后面的部分讲解。
3、Nginx进阶学习
3.1、Nginx服务器基础配置演练
前面我们已经对Nginx服务器默认配置文件的结构和涉及的基本指令做了详细的阐述。通过这些指令的合理配置,我们就可以让一台Nginx服务器正常工作,并且提供基本的web服务器功能。
接下来我们将通过一个比较完整和最简单的基础配置实例,来巩固下前面所学习的指令
及其配置。
(1)有如下访问:
http://192.168.111.135:8081/server1/location1
访问的是: location1目录下index.html
http://192.168.111.135:8081/server1/location2
访问的是: location2目录下 index.html
http://192.168.111.135:8082/server2/location1
访问的是: location1目录下index.html
http://192.168.111.135:8082/server2/location2
访问的是: location2目录下 index.html
(2)如果访问资源不存在
返回一个自定义的404页面
(3)将/sever1和/sever2的配置使用不同的配置文件分割
(4)为/sever1和/sever2各自创建一个日志访问文件这是整个目录结构,具体的位置你可以自定义
[root@192 my]# tree www www ├── 404.html ├── conf │ ├── server1.conf │ └── server2.conf ├── logs │ ├── server1.log │ └── server2.log ├── server1 │ ├── location1 │ │ └── index.html │ └── location2 │ └── index.html └── server2 ├── location1 │ └── index.html └── location2 └── index.htmlserver1.conf
server { listen 8081; server_name localhost; access_log /my/www/logs/server1.log combined; location /server1/location1 { root /my/www; index index.html; } location /server1/location2 { root /my/www; index index.html; } error_page 404 /404.html; location = /404.html { root /my/www; index 404.html; } }server2.conf
server { listen 8082; server_name localhost; error_page 404 /my/www/404.html; location = /404.html { root /my/www; index 404.html; } location /server2/location1{ root /my/www; index index.html; } location /server2/location2{ root /my/www; index index.html; } access_log /my/www/logs/server2.log; }在nginx.conf中的html块添加
include /my/www/conf/*.conf;最后访问测试
再对前面的配置文件简单的复习
##全局块 begin##
user www; #配置允许运行Nginx工作进程的用户和用户组
worker_processes 2; #配置运行Nginx进程生成的worker进程数
error_log logs/error.log; #配置Nginx服务器运行对错误日志存放的路径
pid logs/nginx.pid; #配置Nginx服务器允许时记录Nginx的master进程的PID文件路径和名称
#daemon on; #配置Nginx服务是否以守护进程方法启动,默认就是
##全局块 end##
##events块 begin##
events{
accept_mutex on; #设置Nginx网络连接序列化,避免惊群现象
multi_accept on; #设置Nginx的worker进程是否可以同时接收多个请求
worker_connections 1024; #设置Nginx的worker进程同时连接的最大的连接数,受系统套接字限制
use epoll; ##设置Nginx使用的事件驱动模型
}
##events块 end##
##http块 start##
http{
include mime.types;
default_type application/octet-stream;
sendfile on; #配置允许使用sendfile方式运输
keepalive_tirleout 65; #配置连接超时时间
log_format server1 'xxx'; #配置请求处理日志格式
##server块开始#转
include /my/www/conf/*.conf;
##server块结束##
}
##http块 end##3.2、将Nginx配置成系统服务并且添加到环境变量
经过前面的操作,我们会发现,如果想要启动、关闭或重新加载nginx配置文件,都需要先进入到nginx的安装目录的sbin目录,然后使用nginx的二级制可执行文件来操作,相对来说操作比较繁琐,这块该如何优化?另外如果我们想把Nginx设置成随着服务器启动就自动完成启动操作,又该如何来实现?
3.2.1、Nginx配置成系统服务
把Nginx应用服务设置成为系统服务,方便对Nginx服务的启动和停止等相关操作,具体实现步骤:
(1)、在 /usr/lib/systemd/system 目录下添加nginx.service,内容如下:
vim /usr/lib/systemd/system/nginx.service[Unit] Description=nginx web service' Documentation=http://nginx.org/en/docs/ After=network.target [Service] Type=forking PIDFile=/usr/local/nginx/logs/nginx.pid ExecStartPre=/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.conf ExecStart=/usr/local/nginx/sbin/nginx ExecReload=/usr/local/nginx/sbin/nginx -s reload ExecStop=/usr/local/nginx/sbin/nginx -s stop PrivateTmp=true [Install] wantedBy=default.target(2)、添加完成后如果权限有问题需要进行权限设置
chmod 755 /usr/lib/systemd/system/nginx.service(3)、经过上面的配置就可以使用系统命令来操作Nginx服务了
启动: systemctl start nginx 停止: systemctl stop nginx 重启: systemctl restart nginx 重新加载配置文件: systemctl reload nginx 查看nginx状态: systemctl status nginx 开机启动: systemctl enable nginx
3.2.2、Nginx命令配置到系统环境变量
前面我们介绍过Nginx安装目录下的二级制可执行文件nginx的很多命令,要想使用这些命令前提是需要进入sbin目录下才能使用,很不方便,如何去优化,我们可以将该二进制可执行文件加入到系统的环境变量,这样的话在任何目录都可以使用nginx对应的相关命令。具体实现步骤如下:
(1)、修改 /etc/profile 文件
vim /etc/profile #在最后一行添加 export PATH=$PATH:/usr/local/nginx/sbin #就是让现在的PATH = 原来的PATH+nginx的sbin目录,Linux是使用“:”分割不同路径(2)、使之生效
source /etc/profile(3)、测试直接使用nginx命令
3.3、Nginx静态资源部署
3.3.1、Nginx静态资源概述
上网去搜索访问资源对于我们来说并不陌生,通过浏览器发送一个HTTP请求实现从客户端发送请求到服务器端获取所需要内容后并把内容回显展示在页面的一个过程。这个时候,我们所请求的内容就分为两种类型,一类是静态资源、一类是动态资源。
静态资源即指在服务器端真实存在并且能直接拿来展示的一些文件,比如常见的html页面、css文件、is文件、图片、视频等资源;
动态资源即指在服务器端真实存在但是要想获取需要经过一定的业务逻辑处理,根据不同的条件展示在页面不同这一部分内容,比如说报表数据展示、根据当前登录用户展示相关具体数据等资源;
Nginx处理静态资源的内容,我们需要考虑下面这几个问题:
- 静态资源的配置指令
- 静态资源的配置优化
- 静态资源的压缩配置指令
- 静态资源的缓存处理
- 静态资源的访问控制,包括跨域问题和防盗链问题
3.3.2、Nginx静态资源的配置指令-server块
listen指令:用来配置监听端口的
| 语法 | listen address[:port] [default_server] ...; listen port [default_server]...; |
| 默认值 | listen *:80 | *:8080 |
| 位置 | server |
listen的设置比较灵活,我们通过几个例子来熟悉以下
listen 127.0.0.1:8080; #监听指定ip和端口
listen localhost:8080;
listen 127.0.0.1; #监听指定ip的所有端口
listen 8000; #监听指定端口
listen *:8000; #同上default_server属性是标识符,用来将此虚拟主机设置成默认主机。所谓的默认主机指的是如果没有匹配到对应的address:port,则会默认执行的。如果不指定默认使用的是第一个server。
listen 8000 default_server; #监听8000端口,并且还是默认服务器,http块中如果没有默认服务器,那么第一个服务器就是默认服务器更多有关listen的用法请看官网:http://nginx.org/en/docs/http/ngx_http_core_module.html#listen
server_name :用来设置虚拟机服务名称。
| 语法 | server_name name... ; name可以有多个,空格分割 |
| 默认值 | server_name "" |
| 位置 | server |
关于server_name的配置方式有三种,分别是 精确匹配、通配符匹配、正则表达式匹配
I、精确匹配方式
server{
listen 80;
server_name www.a.com www.b.com;
...
}此处测试可以使用host文件来做域名解析:
windows的host文件目录:C:\Windows\System32\drivers\etc(所在文件夹)
centos下host文件目录:/etc/hosts(该文件)
对于精确匹配方式,必须客户机在访问时使用匹配的域名访问才可使用,否则不能访问。
II、使用通配符的配置
server_name中支持通配符"*",但需要注意的是通配符不能出现在域名的中间,只能出现在首段或尾段,如:
server {
listen 80;
server_name *.a.cn www.b.*;
...
}下面的配置是错误的配置,使用 nginx -t检测会报错
server {
listen 80;
server_name www.*.cn www.b.c* ww*.abc.com;
...
}但是当你的配置中只有一个sever配置时,就不会报错,因为就它一个,它也就是默认的服务器,所以它的server_name整个都不起作用了。
III、使用正则表达式配置
server_name中可以使用正则表达式,并且使用~作为正则表达式字符串的开始标记。常见的正则表达式
| 代码 | 说明 |
| ^ | 匹配搜索字符串开始位置,换句话例如 ^a表示以a开头的匹配 那么 abc匹配 def不匹配 |
| $ | 匹配搜索字符串结束位置 k$表示以k结尾的匹配 |
| . | 匹配除了换行符之外任何单个字符 |
| \ | 转义字符,与下一个字符构成特殊字符 |
| [xyz] | 字符集,与任意一个指定字符匹配即可 |
| [a-z] | 字符范围,匹配指定范围内的任何字符 |
| \w | 与以下字符匹配A-Z a-z 0-9和下划线_ ,等效于[A-Za-z0-9_] |
| \d | 数字字符匹配,等效[0-9] |
| {n} | 正好匹配n次 |
| {n,} | 至少匹配n次 |
| {n,m} | 至少匹配n次,至多匹配m次 |
| * | 0次、1次、或多次 相当于{0,} |
| + | 1次或多次 相当于{1,} |
| ? | 零次或1次,相当于{0,1} |
举例配置如下
server{
listen 80;
server_name ~^www\.(\w+)\.com$;
default_type text/plain;
return 200 $1;
}其作用就是匹配 www.*.com的地址, 细心的你一定发现(\w+)有个括号,这个括号的作用就是在后面的任何地方你可以使用 "$+序号"的方式引用,如配置中的"$1" 将会是你访问域名的中间部分,也就是你括号内匹配的部分,可以有多个括号,之后的你可以使用"$2、$3"分别去表示
匹配顺序
由于server_name指令支持通配符和正则表达式,因此在包含多个虚拟主机的配置文件中,可能会出现一个名称被多个虚拟主机的server_name匹配成功,当遇到这种情况,当前的请求交给谁来处理呢?
经过实验得到的结论就是
精确匹配>前通配符匹配>后通配符匹配>第一个匹配的正则匹配>默认服务器
例如 www.a.com 将优先匹配 www.a.com > *.a.com >www.a.* > 第一个正则匹配成功的服务器 > default_server
3.3.3、Nginx静态资源的配置指令-location块
location:用来设置请求URI
| 语法 | location [= | ~ | ~* | ^~ | @ ] uri {} |
| 位置 | server、location |
url变量是待匹配的请求字符串,可以不包含正则表达式,也可以包含正则表达式,那么nginx服务器在搜索匹配location的时候,是先使用不包含正则表达式进行匹配,找到一个匹配度最高的一个(使用等号的匹配后优先级最高,就不需要匹配其他的以指定模式开头的匹配,匹配的开头字符最多的优先级最高),然后在通过包含正则表达式的进行匹配,如果能匹配到直接访问,匹配不到,就使用刚才匹配度最高的那个location来处理请求。
不带符号,要求必须以指定的模式开始
location /abc{
...
}
可以匹配 /abcd /abc/d /abc/d/e /abcd/e 等= :用于不包含正则表达式的url前,必须于指定的url匹配,(访问时问号后边的参数匹配)
location =/abc {
...
}
匹配 /abc /abc?a=1&b=2
不能匹配 /abc/~ :用于表示当前的url中包含了正则表达式,并且区分大小写
~* :用于表示当前的url包含了正则表达式,不区分大小写
location ~^/abc\w${
...
}
匹配 /abce /abcd ...
不匹配 /ABCd /Abce ...
location ~*/abc\w{
...
}
匹配 /abcd /Abcd /abCd /ABCd ...
^~ :用在不包含正则表达式的uri前面,功能和不加符号一致,唯一的不同是,如果模式匹配,就不再搜索其他的模式了。
最后你可能疑惑 ^~是否会比 = 的优先级高,经过测试,精准匹配的优先级是最高的
location ^~/abc/{
return 200 "^~abc";
}
location =/abc/{
return 200 "=abc";
}
使用浏览器访问/abc/得到的是 "=abc",注意谷歌浏览器会自动在url后面加“/”,所以如果测试的地址没有以"/'结尾,请使用火狐浏览器测试。另外请一定要记住,在location里面配置的index,是会引起nginx新一轮的匹配,匹配的方式是原来访问的地址加上默认首页资源名称,大概率不会匹配到相同的location块。
设置请求资源的目录root / alias
root:设置请求的根目录
| 语法 | root path |
| 默认值 | root html; |
| 位置 | http、server、location |
path为Nginx服务器收到请求以后查找资源的根目录路径。
alias:用来更改location的URI
| 语法 | alias path |
| 位置 | location |
path为修改后的路径前缀
root和alias的区别
location =/abc/ {
root /my/www/html;
index index.html;
}
location /abc/def/ {
alias /my/www/html;
index index.html
}
location /abc/{
root /my/www/html;
index index.html;
}
如上三个location,从上到下依次编号为①②③号location,假设访问地址是 /abc/ 那么毫无疑问根据上面我们学习的几种匹配规则,①号location匹配,因为我们访问的是一个目录,那么nginx就会将我们访问的目录+该匹配location的index进行组合重新进行匹配,那么此时我们的链接是 /abc/index.html,大家看这个目录,很明显匹配它的只有③号location,此时因为这个链接访问的是资源,而此时匹配的③号location中配置的是root,那么nginx会返回的资源在我们系统真正的位置就是 /my/www/html/abc/index.html。也就是root + 你访问的链接。
如果访问的地址是 /abc/def/ ,那么此匹配的有②号location,但是②是一个前缀匹配,所以nginx会记下这个匹配,继续往下匹配,之后发现③也能匹配,但是对比之下。②匹配的多,所以会最终匹配上②,访问的是一个目录,所以会连接上 ②号location的index重新匹配,此时匹配上的还有②和③,但是②匹配的多,最终使用的是②,②号location里面使用的是alias,那么nginx会返回的静态资源的真正位置就是 /my/www/html/index.html。使用alias可以使得uri和真实的系统路径分开,更加的安全。
注意:用alias时里面加/,外面就要加/;里面不加外面也不能加;alias代理的时整个完整路径,包括最后的/.这里面就是一些加减字符的事情,请仔细搞清楚
小结:
- root的处理结果是: root路径+location路径
- alias的处理结果是: 使用alias路径替换1ocation路径
- alias是一个目录别名的定义,root则是最上层目录的含义。
- 如果location路径是以/结尾,则alias也必须是以/结尾,root没有要求
index:设置网站的默认首页
| 语法 | index file ...; |
| 默认值 | index index.html; |
| 位置 | http、server、location |
index后面可以跟多个设置,如果访问的时候没有指定具体访问的资源,则会依次进行查找,找到第一个为止。
location / {
root /usr/local/nginx/html;
index index.htm1 index.htm;
}
访问该location的时候,可以通过http://ip:port/,地址后面如果不添加任何内容,则默认依次访问index.html和index.htm,找到第一个来进行返回error_page:设置网站的错误页面
| 语法 | error_page code [code[ code...]] [=[response]] uri |
| 位置 | http、server、location ... |
当出现对应的响应code之后,就会在nginx内部重定向到指定的uri,这个uri也需要走location匹配,匹配规则见location匹配规则。
server {
error_page 404 http://www.baidu.com; #直接跳到百度
}
server {
error_page 404 /50x.html;
error_page 500 502 503 504 /50x.html;
location =/50x.html{
root html;
}
}
#使用location的@符号完成错误提示
server {
error_page 404 @jump_to_error;
location @jump_to_error {
default_type text/plain;
return 404 'Not Found Page...';
}
}可选项=[response]的作用是用来将相应代码更改为另外一个
server { error_page 404 =200 /50x/html # =200的前面有空格 }客户端收到的响应码是200,虽然它访问的网页不存在。
3.3.4、静态资源优化配置
Nginx对静态资源如何进行优化配置。这里从三个属性配置进行优化:
- sendfile on;
- tcp_nopush on ;
- tcp_nodeplay on;
(1)、sendfile:用来开启高效文件传输模式
| 语法 | sendfile on|off; |
| 默认值 | off |
| 位置 | http、server、location... |
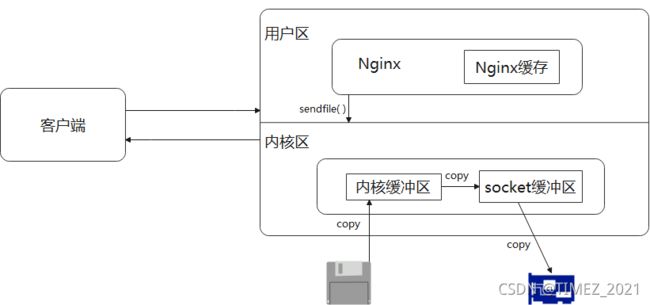
请求静态资源的过程:客户端通过网络接口向服务端发送请求,操作系统将这些客户端的请求传递给服务器端应用程序,服务器端应用程序会处理这些请求,请求处理完成以后,操作系统还需要将处理得到的结果通过网络适配器传递回去。
没有使用sendfile的情况

使用sendfile的情况:
(2)、tcp_nopush:该指令必须在sendfile打开的状态下才会生效,主要是用来提升网络包的传输效率,因为tcp的每一个包都有很多的附加字段(http下层协议的tcp包头ip包头mac帧头帧尾),如果真实有效的数据不多,那么传输中效率就不高,这个指令可以使得每次传输的有效数据尽量缓存到一定大小再push,可以提高效率。
| 语法 | tcp_nopush on | off |
| 默认值 | off |
| 位置 | http、server、location |
(3)、tcp_nodelay:该指令必须再keep-alive连接开启的情况下才生效,来提高网络包传输的实时性。
| 语法 | tcp_nodelay on|off; |
| 默认值 | on |
| 位置 | http、server、location |
经过刚才的分析,"tcp_nopush"和"tcp_nodelay"看起来是"互斥的",那么为什么要将这两个值都打开,这个大家需要知道的是在linux2.5.9以后的版本中两者是可以兼容的,三个指令都开启的好处是,sendfile可以开启高效的文件传输模式,tcp_nopush开启可以确保在发送到客户端之前数据包已经充分"填满",这大大减少了网络开销,并加快了文件发送的速度。然后,当它到达最后一个可能因为没有“填满而暂停的数据包时,Nginx会忽略tcp_nopush参数,然后,tcp_nodelay强制套接字发送数据。由此可知,TCP_NOPUSH可以与TCP_NODELAY一起设置,它比单独配置TCP_NODELAY具有更强的性能。所以我们可以使用如下配置来优化Nginx静态资源的处理
3.3.5、Nginx静态资源压缩
经过上述内容的优化,我们再次思考一个问题,假如在满足上述优化的前提下,我们传送一个1M的数据和一个10M的数据那个效率高?,答案显而易见,传输内容小,速度就会快。那么问题又来了,同样的内容,如果把大小降下来,我们脑袋里面要蹦出一个词就是"压缩",接下来,我们来学习Nginx的静态资源压缩模块。
在Nginx的配置文件中可以通过配置gzip来对静态资源进行压缩,相关的指令可以配置在http块、server块和location块中,Nginx可以通过一些模块对指令进行解析处理
- ngx_http_gzip_module模块.
- ngx_http_gzip_static_module模块
- ngx_http_gunzip_module模块
Gzip模块配置指令
下面这个小部分学习的指令都来自 ngx_http_gzip_module模块,该模块在nginx安装的时候内置到nginx的安装环境了,我们不需要更新模块配置了可以直接使用下面的指令。
(1)、gzip指令:该指令用于开启或关闭gzip功能
| 语法 | gzip on|off; |
| 默认值 | off |
| 位置 | http、server、location... |
只有在gzip为打开的状态,下面学习的指令才有效果。
(2)、gzip_types指令:该指令可以根据响应页的MIME类型选择性的开启Gzip压缩功能
| 语法 | gzip_types mime-type |
| 默认值 | gzip_type text/html; |
| 位置 | http、server、location |
所选择的值可以多个,空格隔开,mime的值从配置文件目录下mime.types中可以找到。也可以使用*来配置所有,但是生产环境不建议配置为*,因为我们知道压缩会消耗cpu性能,对于图片等已经是高度压缩的文件,再压缩的话投入和产出就不成正比,没有必要压缩。
(3)、gzip_comp_level指令:该指令用于设置gzip压缩程度,级别从1到9,1表示的程度最低,效率最高,9反之。
| 语法 | gzip_comp_level level; |
| 默认值 | 1 |
| 位置 | http、server、location |
建议6,
(4)、gzip_vary指令:该指令用于设置使用Gzip进行压缩发送的响应数据是否加入“Vary:Accept-Encoding”响应头,以告诉对方数据经过Gzip压缩处理了
| 语法 | gzip_vary on|off; |
| 默认值 | off |
| 位置 | http、server、location |
对比效果:

(5)、gzip_buffers:该指令用于配置处理请求压缩的缓冲区数量和大小
| 语法 | gzip_buffers Num size |
| 默认值 | gzip_buffers 32 4k | 16 8k |
| 位置 | http、server、location |
其中num:指定Nginx服务器向系统申请缓存空间个数,size指的是每个缓存空间的大小。主要实现的是申请num个每个大小为size的内存空间。这个值的设定一般会和服务器的操作系统有关,所以建议此项不设置,使用默认值即可。
(6)、gzip_disable:针对不同种类的客户端发起的请求,可以选择性的开启和关闭gzip功能。
| 语法 | gzip_disable regex |
| 位置 | http、server、location |
regex:根据客户端的浏览器标志(user-agent)来设置,支持使用正则表达式。指定的浏览器标志不使用Gzip.该指令一般是用来排除一些明显不支持Gzip的浏览器。
gzip disable "Mozilla/5.0.*"(7)、gzip_http_version:针对不同的HTTP协议版本,可以选择性的开启和关闭gzip功能
| 语法 | gzip_http_version 1.0|1.1 |
| 默认值 | 1.1 |
| 位置 | http、server、location |
(8)、gzip_min_length:该指令针对传输数据的大小,可以选择性的开启和关闭gzip功能
| 语法 | gzip_min_length byte| k byte | M byte |
| 默认值 | gzip_min_length 20; |
| 位置 | http、server、location |
默认值是20字节,计量单位可以是 字节|千字节|兆字节,例如 20 | 20k | 20K | 20m | 20M
Gzip压缩功能对大数据的压缩效果明显,但是如果要压缩的数据比较小的化,可能出现越压缩数据量越大的情况,因此我们需要根据响应内容的大小来决定是否使用Gzip功能,响应页面的大小可以通过头信息中的content-Length来获取。但是如何使用了Chunk编码动态压缩,该指令将被忽略。建议设置为1k或以上。
(9)、gzip_proxied指令:该指令设置是否对服务端返回的结果进行gzip压缩。
| 语法 | gzip_proxied off | expired | no-cache | no-store | private | no_last_modified | no_etag | auth | any |
| 默认值 | gzip_proxied off; |
| 位置 | http、server、location |
off #关闭Nginx服务器对后台服务器返回结果的Gzip压缩
expired #启用压缩,如果header头中包含"Expires"头信息
no-cache #启用压缩,如果header头中包含"Cache-Control:no-cache"头信息
no-store #启用压缩,如果header头中包含"Cache-Control:no-store"头信息
private #启用压缩,如果header头中包含"Cache-Control:private"头信息
no_last_modified #启用压缩,如果header头中不包含"Last-Modified"头信息
no_etag #启用压缩,如果header头中不包含"ETag"头信息
auth #启用压缩,如果header头中包含"Authorization"头信息
any #无条件启用压缩gzip压缩功能配置示例
#可抽取到一个压缩的配置文件,再主配置中include
gzip on; #开启gzip功能
gzip_types *; #压缩源文件类型,根据具体的访问资源类型设定
gzip_comp_leve1 6; #gzip压缩级别
gzip_min_length 1024; #进行压缩响应页面的最小长度,content-length
gzip_buffers 4 16K; #缓存空间大小
gzip_http_version 1.1; #指定压缩响应所需要的最低HTTP请求版本
gzip_vary on; #往头信息中添加压缩标识
gzip_disable "MSIE [1-6]\.""; #对IE6以下的版本都不进行压缩(它们不支持)
gzip_proxied off; #nginx作为反向代理压缩服务端返回数据的条件gzip和sendfile共存问题
前面在讲解sendfile的时候,提到过,开启sendfile以后,在读取磁盘上的静态资源文件的时候,可以减少拷贝的次数,可以不经过用户进程将静态文件通过网络设备发送出去,但是Gzip要想对资源压缩,是需要经过用户进程进行操作的。所以如何解决两个设置的共存问题。
可以使用ngx_http_gzip_static_module模块的gzip_static指令来解决。
注意:这个模块默认安装没有添加,我们需要手动添加这个模块,具体方法请参照前面的使用USR2信号量升级部分,讲的就是添加这个模块。
gzip_static:检查与访问资源同名的.gz文件时,response中返回gzip相关的header,返回.gz文件的内容。
| 语法 | gzip_static on | off | always |
| 默认值 | gzip_static off; |
| 位置 | http、server、location |
注意一定要添加http_gzip_static_module模块。另外你需要给定资源的gz压缩包,也就是说你需要对资源进行压缩



3.3.6、静态资源的缓存处理
什么是浏览器web缓存
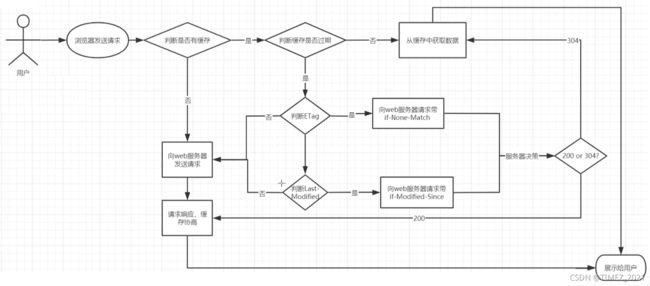
web缓存是指一个web资源(如htm1页面,图片,js,数据等)存在于web服务器和客户端(浏览器)之间的副本。缓存会根据进来的请求保存输出内容的副本;当下一个请求来到的时候,如果是相同的URL,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。比较常见的就是浏览器会缓存访问过网站的网页,当再次访问这个URL地址的时候,如果网页没有更新,就不会再次下载网页,而是直接使用本地缓存的网页。只有当网站明确标识资源已经更新,浏览器才会再次下载网页。
web缓存的种类
- 客户端缓存: 浏览器缓存
- 服务端缓存:Nginx / Redis / Memcached等
浏览器缓存的执行流程
HTTP协议中和页面缓存相关的字段,我们先认识一下:
| header | 说明 |
| Expires | 缓存过期的日期和时间 |
| Cache-Control | 设置和缓存相关的配置信息 |
| Last-Modified | 请求资源最后修改时间 |
| ETag | 请求变量的实体标签的当前值,比如文件的MD5值 |
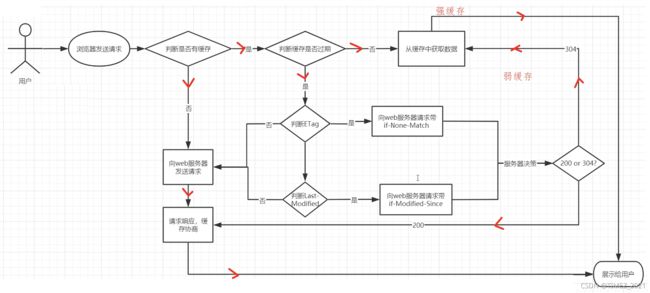
浏览器缓存相关Nginx指令
expires:该指令用来控制页面缓存的作用。可以通过该指令控制HTTP应答中的"Expires"和"Cache-Control"
| 语法 | expires [modified] time expires epoch | max | off |
| 默认值 | expires off; |
| 位置 | http、server、location |
time:可以整数也可以是负数,指定过期时间,如果是负数,Cache-Control则为no-cache,如果为整数或0,则Cache-Control的值为max-age=time;
epoch:指定Expires的值为 '1 January,1970,00:00:01GMT'(1970-01-01 00:00:00),Cache-Control的值no-cache
max:指定Expires的值为'31 December,2037,23:59:59 GMT'(2037-12-3123:59:59),Cache-Control的值为10年(强缓存)
add_header指令用来添加指定的响应头和响应值。
| 语法 | add_header name value [always] |
| 位置 | http、server、location |
Cache-Control的响应值可以设置如下值:
Cache-control: must-revalidate #可缓存但必须再向源服务器进行确认
Cache-control: no-cache #缓存使用前必须确认其有效性
Cache-control: no-store #不缓存请求或响应的任何内容
Cache-control: no-transform #代理不可更改媒体类型
Cache-contro1: public #可向任意方提供响应的缓存
Cache-control: private #仅向特定用户返回响应
Cache-contro1: proxy-revalidate #要求中间缓存服务器对缓存的响应有效性再进行确认
Cache-control: max-age= #响应最大Age值
Cache-contro7: s-maxage= #公共缓存服务器响应的最大Age值 3.3.7、Nginx的跨域问题解决
同源策略
浏览器的同源策略:是一种约定,是浏览器最核心也是最基本的安全功能,如果浏览器
少了同源策略,则浏览器的正常功能可能都会受到影响。
同源:协议、域名(IP)、端口相同即为同源
http://192.168.111.135/user/1
https://192.168.111.135/user/1 #协议不同,不是同源
http://192.168.111.131/user/1
http://192.168.111.132/user/1 #ip不同,不是同源
http://192.168.200.131/user/1
http://192.168.200.131:8080/user/1 #主机不同,不是同源
http://www.nginx.com/user/1
http://www.nginx.org/user/1 #域名不同不是同源
http://192.168.200.131/user/1
http://192.168.200.131:8080/user/1 #端口不同不是同源
http://www.nginx.org:80/user/1
http://www.nginx.org/user71 #是同源
http://127.0.0.1/abc
http://localhost/abc #不是同源跨域问题:
有两台服务器分别为A,B,如果从服务器A的页面发送异步请求到服务器B获取数据,如果服
务器A和服务器B不满足同源策略,则就会出现跨域问题。浏览器报错内容一般是下面这种:
![]()
解决方案:
使用add_header指令,添加一些头信息
此处用来解决跨域问题,需要添加两个头信息,一个是Access-Control-Allow-origin、Access-Control-Allow-Methods
Access-Control-Allow-Origin:直译过来是允许跨域访问的源地址信息,可以配置多个(多个用逗号分隔),也可以使用 * 代表所有源
Access-Control-Allow-Methods:直译过来是允许跨域访问的请求方式,值可以为GET、POST、PUT、DELETE 可以全部设置,也可以根据需要设置,多个用逗号分隔
location /getuser{
add_header Access-Control-A1low-Origin *;
add_header Access-Control-Allow-Methods GET,POST,PUT,DELETE;
default_type application/json;
return 200 '{"id":1,"name":"TOM","age":18}';
}3.3.8、静态资源防盗链
资源盗链指的是此内容不在自己服务器上,而是通过技术手段,绕过别人的限制将别人的内容放到自己页面上最终展示给用户。以此来盗取大网站的空间和流量。简而言之就是用别人的东西成就自己的网站。
Nginx防盗链的实现原理
了解防盗链的原理之前,我们得先学习一个HTTP的头信息Referer,当浏览器向web服务器发送请求的时候,一般都会带上Referer,来告诉浏览器该网页是从哪个页面链接过来的。后台服务器可以根据获取到的这个Referer信息来判断是否为自己信任的网站地址,如果是则放行继续访问,如果不是则可以返回403(服务端拒绝访问)的状态信息。
Nginx防盗链的具体实现
valid_referers:nginx会通就过查看referer自动和valid_referers后面的内容进行匹配,如果匹配到了就将$invalid_referer变量置0,如果没有匹配到,则将$invalid_referer变量置为1,匹配的过程中不区分大小写。
| 语法 | valid_referers none | blocked | server_names | string ... 可以多个,空格分开 |
| 位置 | server、location |
none:如果Header中的Referer为空,允许访问。
blocked:在Header中Referer不为空,但是该值被防火墙或代理进行伪装过,如不带"http://"、"https://" 等协议头的资源允许访问。
server_names:指定具体的域名或者IP
string:可以支持正则表达式和*的通配符字符串。如果是正则表达式要以~开头
location ~\.(png|jpg|gif){
valid_referers none blocked www.baidu.com 192.168.200.222 *.example.com www.example.* www.example.org ~\.google\.;
if ($invalid_referer){
return 403;
}
root /usr/local/nginx/html;
}