pandas库读取多个excel文件数据并进行筛选合并处理后导入到新表格中
一、说明:
通过pandas库解决生活中的实际问题,关键词:pandas:Series/DataFrame
实际场景:
①前几日家中的服装店部分库存需要补货,店长向厂家下了部分订单;
②几日后到了一批货物,其中系统中共收到3张收货明细单;
③收到后业务员对实际的货物进行了清点,最终形成了一张纸质的收货单据,样式如下:
货号00000001:15件;货号000000002:13件…
④我打开系统中的收货单发现问题,店长下的订单厂家部分缺货并未发货,但是在其发货清单中这部分数据中的发货数量为0,且其中存在大量统计时的无效数据;
⑤通过Python实现高效率的从三张电子货单中筛选所需数据并进行合并计算,最终得出厂家的发货单明细数据;
⑥同业务员的纸质单据进行逐一核实。
二、数据截图:
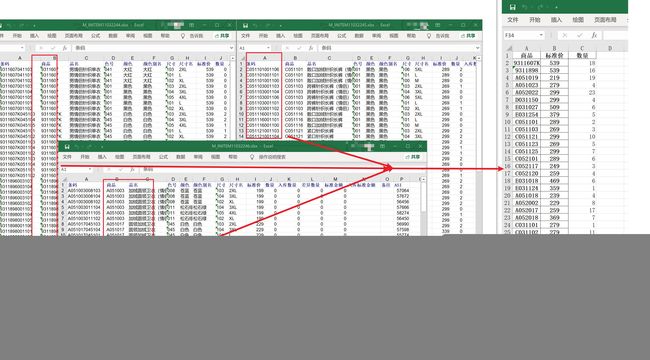 取出图片中部分数据经过处理后导出到新表格中
取出图片中部分数据经过处理后导出到新表格中
三、代码实现
# 日期:2021-11-05
# 作者:Skyler
# 说明:读取多个表格中指定列数据并进行筛选计算,最终将结果导出到excel表格
# 方法:如需求和我一致(具体可参考图片内容),则修改路径变量即可:1.将所有文件放到指定路径的文件夹内;2.注意最终输出的路径
#导入所需要的模块
import pandas as pd
import os
#定义文件路径
path='E:/4.Python/8.files/'
#通过函数取出所有文件名称
files=os.listdir(path)
df4=pd.DataFrame()
#循环拼接路径>读取所有文件>条件筛选所需数据>分组聚合进行计算>转换数据类型>添加到定义的变量中
for i in range(0,len(files)):
file_name=path+files[i]
df=pd.read_excel(file_name)
df=df[df['数量']>0]
df=df[df['标准价']>0]
df2=df.groupby(['商品','标准价'])['数量'].sum()
print('----------------------------------------------------------')
df3=pd.DataFrame(df2)
#print(df3)
df4=df4.append(df3)
#print(df4)
#导出最终结果到excel表格中
df4.to_excel(r'C:\Users\Skyler\Desktop\info.xlsx')