ShardingCore
ShardingCore 一款ef-core下高性能、轻量级针对分表分库读写分离的解决方案,具有零依赖、零学习成本、零业务代码入侵。
Github Source Code 助力dotnet 生态 Gitee Source Code
介绍
在分表分库领域java有着很多的解决方案,尤其是客户端解决方案(ShardingSphere),因为客户端解决方案有着极高的性能,但是缺点也很明显数据库链接的消耗相对较高,使用语言的限制让我们.Net望而却步,但是哪怕是有着这些缺点其实也不足以掩盖客户端分表分库带来的便捷与高效。
目前本人所开发的ShardingCore 是.Net下基于efcore2+的所有版本的分表分库很多都是借鉴了ShardingSphere,并且对其很多缺点进行了弥补。这边可能有人就要说了,你为什么做个efcore的不做个ado.net的呢,说实话我这边确实有一个ado.net版本的分表分库,你可以理解为ShardingSphere的.Net复刻版本sharding-conector 最最最初版本的分表聚合已经实现底层原理和ShardingSphere一致使用的Antlr4的分词。为什么不对这个版本进行推进转而对efcore的sharding-core版本进行升级维护呢,这边主要有两点,第一点如果我是在ado.net上进行的推进那么势必可以支持更多的orm框架,但是orm框架下的很多特性将可能无法使用,并且需要维护各个数据库版本之间的差异。比如efcore下的批量操作等一些列优化语法是很难被支持的。第二点针对某个orm的扩展性能和使用体验上远远可以大于通用性组件。这就是我为什么针对ShardingCore进行有段优化和升级的原因。
性能
其实性能一直是大家关注的一个点,我用了ShardingCore那么针对特定的查询他的损耗是多少是一个比较令人关注的话题。接下来我放出之前做的两次性能比较,当然这两次比较并不是特意准备的,是我边开发边跑的一个是sqlserver 一个是mysql
性能测试
以下所有数据均在开启了表达式编译缓存的情况下测试,并且电脑处于长时间未关机并且开着很多vs和idea的情况下仅供参考,所有测试都是基于ShardingCore x.3.1.63+ version
以下所有数据均在源码中有案例
efcore版本均为6.0 表结构为string型id的订单取模分成5张表
N代表执行次数
sql server 2012,data rows 7734363 =773w
// * Summary *
BenchmarkDotNet=v0.13.1, OS=Windows 10.0.18363.1500 (1909/November2019Update/19H2)
AMD Ryzen 9 3900X, 1 CPU, 24 logical and 12 physical cores
.NET SDK=6.0.100
[Host] : .NET 6.0.0 (6.0.21.52210), X64 RyuJIT
DefaultJob : .NET 6.0.0 (6.0.21.52210), X64 RyuJIT
| Method | N | Mean | Error | StdDev | Median |
|---|---|---|---|---|---|
| NoShardingIndexFirstOrDefaultAsync | 10 | 2.154 ms | 0.1532 ms | 0.4443 ms | 1.978 ms |
| ShardingIndexFirstOrDefaultAsync | 10 | 4.293 ms | 0.1521 ms | 0.4485 ms | 4.077 ms |
| NoShardingNoIndexFirstOrDefaultAsync | 10 | 823.382 ms | 16.0849 ms | 18.5233 ms | 821.221 ms |
| ShardingNoIndexFirstOrDefaultAsync | 10 | 892.276 ms | 17.8131 ms | 16.6623 ms | 894.880 ms |
| NoShardingNoIndexCountAsync | 10 | 830.754 ms | 16.5309 ms | 38.6405 ms | 821.736 ms |
| ShardingNoIndexCountAsync | 10 | 915.630 ms | 8.8511 ms | 7.3911 ms | 914.107 ms |
| NoShardingNoIndexLikeToListAsync | 10 | 7,008.918 ms | 139.4664 ms | 166.0248 ms | 6,955.674 ms |
| ShardingNoIndexLikeToListAsync | 10 | 7,044.168 ms | 135.3814 ms | 132.9626 ms | 7,008.057 ms |
| NoShardingNoIndexToListAsync | 10 | 787.129 ms | 10.5812 ms | 8.8357 ms | 785.798 ms |
| ShardingNoIndexToListAsync | 10 | 935.880 ms | 16.3354 ms | 15.2801 ms | 940.369 ms |
mysql 5.7,data rows 7553790=755w innerdb_buffer_size=3G
// * Summary *
BenchmarkDotNet=v0.13.1, OS=Windows 10.0.18363.1500 (1909/November2019Update/19H2)
AMD Ryzen 9 3900X, 1 CPU, 24 logical and 12 physical cores
.NET SDK=6.0.100
[Host] : .NET 6.0.0 (6.0.21.52210), X64 RyuJIT
DefaultJob : .NET 6.0.0 (6.0.21.52210), X64 RyuJIT
| Method | N | Mean | Error | StdDev | Median |
|---|---|---|---|---|---|
| NoShardingIndexFirstOrDefaultAsync | 10 | 5.020 ms | 0.1245 ms | 0.3672 ms | 4.855 ms |
| ShardingIndexFirstOrDefaultAsync | 10 | 7.960 ms | 0.1585 ms | 0.2514 ms | 7.974 ms |
| NoShardingNoIndexFirstOrDefaultAsync | 10 | 11,336.083 ms | 623.8044 ms | 1,829.5103 ms | 11,185.590 ms |
| ShardingNoIndexFirstOrDefaultAsync | 10 | 5,422.259 ms | 77.5386 ms | 72.5296 ms | 5,390.019 ms |
| NoShardingNoIndexCountAsync | 10 | 14,229.819 ms | 82.8929 ms | 77.5381 ms | 14,219.773 ms |
| ShardingNoIndexCountAsync | 10 | 3,085.268 ms | 55.5942 ms | 49.2828 ms | 3,087.704 ms |
| NoShardingNoIndexLikeToListAsync | 10 | 27,046.390 ms | 71.2034 ms | 59.4580 ms | 27,052.316 ms |
| ShardingNoIndexLikeToListAsync | 10 | 5,707.009 ms | 106.8713 ms | 99.9675 ms | 5,672.453 ms |
| NoShardingNoIndexToListAsync | 10 | 26,001.850 ms | 89.2787 ms | 69.7030 ms | 25,998.407 ms |
| ShardingNoIndexToListAsync | 10 | 5,490.659 ms | 71.8199 ms | 67.1804 ms | 5,477.891 ms |
具体可以通过first前两次结果来计算得出结论单次查询的的损耗为0.2-0.3毫秒之间,通过数据聚合和数据路由的损耗单次在0.3ms-0.4ms,其中创建dbcontext为0.1毫秒目前没有好的优化方案,0.013毫秒左右是路由表达式解析和编译,复杂表达式可能更加耗时,剩下的0.2毫秒为数据源和表后缀的解析等操作包括实例的反射创建和数据的聚合,
sqlserver的各项数据在分表和未分表的情况下都几乎差不多可以得出在770w数据集情况下数据库还并未是数据瓶颈的关键,但是mysql可以看到在分表和未分表的情况下如果涉及到没有索引的全表扫描那么性能的差距将是分表后的表数目之多,测试中为5-6倍,也就是分表数目
如果你可以接受单次查询的损耗在0.2ms-0.3ms的那相信这款框架将会是efcore下非常完美的一款分表分库组件
链接模式
说了这么多这边需要针对ShardingCore在查询下面涉及到N表查询后带来的链接消耗是一个不容小觑的客观因素。所以这边参考ShardingSphere进行了类似原理的实现。就是如果查询涉及不同库那么直接并发,如果是同库的将根据用户配置的单次最大链接进行串行查询,并且动态选择使用流式聚合和内存聚合。
首先我们看下ShardingSphere的链接模式在限制链接数的情况下是如何进行处理的
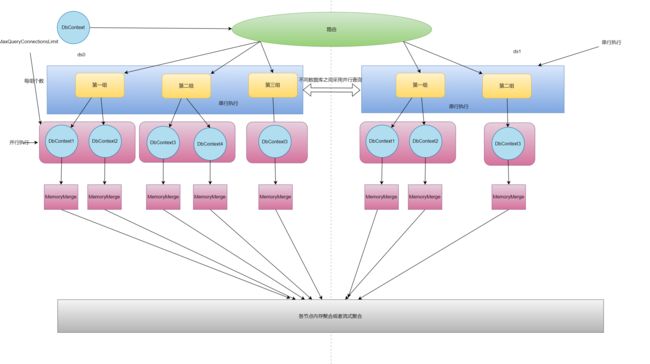
针对不同的数据库采用并行执行,针对同一个数据库根据用户配置的最大连接数进行分库串行执行,并且因为需要控制链接数所以会将结果集保存在内存中,最后通过合并返回给客户端数据。
之后我们会讲这个模式的缺点并且ShardingCore是如何进行优化的
你可能已经蒙了这么多名称完全没有一个概念。接下来我将一一进行讲解,首先我们来看下链接模式下有哪些参数
MaxQueryConnectionsLimit
最大并发链接数,就是表示单次查询sharding-core允许使用的dbconnection,默认会加上1就是说如果你配置了MaxQueryConnectionsLimit=10那么实际sharding-core会在同一次查询中开启11条链接最多,为什么是11不是10因为sharding-core会默认开启一个链接用来进行空dbconnection的使用。如果不设置本参数那么默认是cpu线程数Environment.ProcessorCount
ConnectionMode
链接模式,可以由用户自行指定,使用内存限制,和连接数限制或者系统自行选择最优
链接模式,有三个可选项,分别是:
MEMORY_STRICTLY
内存限制模式最小化内存聚合 流式聚合 同时会有多个链接
MEMORY_STRICTLY的意思是最小化内存使用率,就是非一次性获取所有数据然后采用流式聚合
CONNECTION_STRICTLY
连接数限制模式最小化并发连接数 内存聚合 连接数会有限制
CONNECTION_STRICTLY的意思是最小化连接并发数,就是单次查询并发连接数为设置的连接数MaxQueryConnectionsLimit。因为有限制,所以无法一直挂起多个连接,数据的合并为内存聚合采用最小化内存方式进行优化,而不是无脑使用内存聚合
SYSTEM_AUTO
系统自动选择内存还是流式聚合
系统自行选择会根据用户的配置采取最小化连接数,但是如果遇到分页则会根据分页策略采取内存限制,因为skip过大会导致内存爆炸
解释
MEMORY_STRICTLY
MEMORY_STRICTLY内存严格模式,用户使用本属性后将会严格控制查询的聚合方式,将会采用流式聚合的迭代器模式,而不是一次性全部去除相关数据在内存中排序获取,通过用户配置的MaxQueryConnectionsLimit连接数来进行限制,比如MaxQueryConnectionsLimit=2,并且本次查询涉及到一个库3张表,因为程序只允许单次查询能并发2个链接,所以本次查询会被分成2组每组两个,其中第二组只有一个,在这种情况下第一次并发查询2条语句因为采用内存严格所以不会将数据获取到内存,第二次在进行一次查询并将迭代器返回一共组合成3个迭代器后续通过流式聚合+优先级队列进行返回所要的数据,在这种情况下程序的内存是最少的但是消耗的链接也是最大的。当用户手动选择MEMORY_STRICTLY后MaxQueryConnectionsLimit将变成并行数目.
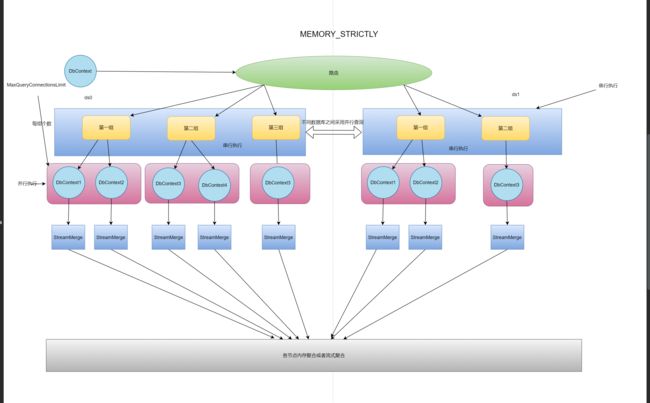
CONNECTION_STRICTLY
CONNECTION_STRICTLY连接数严格模式,用户使用本属性后将会严格控制查询后的同一个数据库下的同时查询的链接数,不会因为使用流式内存而导致迭代器一致开着,因为一个迭代器查询开着就意味着需要一个链接,如果查询需要聚合3张表那么就需要同时开着三个链接来迭代保证流式聚合。通过用户配置的MaxQueryConnectionsLimit连接数来进行限制,比如MaxQueryConnectionsLimit=2,并且本次查询涉及到一个库3张表,因为程序只允许单次查询能并发2个链接,所以本次查询会被分成2组每组两个,其中第二组只有一个,在这种情况下第一次并发查询2条语句因为采用连接数严格所以不会一直持有链接,会将链接结果进行每组进行合并然后将连接放回,合并时还是采用的流式聚合,会首先将第一组的两个链接进行查询之后将需要的结果通过流式聚合取到内存,然后第二组会自行独立查询并且从第二次开始后会将上一次迭代的内存聚合数据进行和本次查询的流式聚合分别一起聚合,保证在分页情况下内存数据量最少。因为如果每组都是用独立的内存聚合那么你有n组就会有n*(skip+take)的数目,而ShardingSphere采用的是更加简单的做法,就是将每组下面的各自节点都自行进行内存聚合,那么如果在skip(10).take(10)的情况下sql会被改写成各组的各个节点分别进行skip(0).take(20)的操作那么2组执行器的第一组将会有40条数据第二组将会有20条数据一共会有60条数据远远操作了我们所需要的20条。所以在这个情况下ShardingCore第一组内存流式聚合会返回20条数据,第二组会将第一组的20条数据和第二组的进行流式聚合内存中还是只有20条数据,虽然是连接数严格但是也做到了最小化内存单元。当用户手动选择CONNECTION_STRICTLY后MaxQueryConnectionsLimit将是正则的最小化链接数限制

SYSTEM_AUTO
SYSTEM_AUTO系统自行选择,这是一个非常帮的选择,因为在这个选择下系统会自动根据用户配置的MaxQueryConnectionsLimit来自行控制是采用流式聚合还是内存聚合,并且因为我们采用的是同数据库下面最小化内存相比其他的解决方案可以更加有效和高性能的来应对各种查询。仅仅只需要配置一个最大连接数限制既可以适配好连接模式。
这边极力推荐大家在不清楚应该用什么模式的时候使用SYSTEM_AUTO并且手动配置MaxQueryConnectionsLimit来确定各个环境下的配置一直而不是采用默认的cpu线程数。
首先我们通过每个数据库被路由到了多少张表进行计算期望用户在配置了xx后应该的并行数来进行分组,sqlCount :表示这个数据库被路由到的表数目,exceptCount :表示计算出来的应该的单次查询并行数
//代码本质就是向上取整
int exceptCount =
Math.Max(
0 == sqlCount % maxQueryConnectionsLimit
? sqlCount / maxQueryConnectionsLimit
: sqlCount / maxQueryConnectionsLimit + 1, 1);
第二次我们通过判断sqlCount和maxQueryConnectionsLimit的大小来确定链接模式的选择
private ConnectionModeEnum CalcConnectionMode(int sqlCount)
{
switch (_shardingConfigOption.ConnectionMode)
{
case ConnectionModeEnum.MEMORY_STRICTLY:
case ConnectionModeEnum.CONNECTION_STRICTLY: return _shardingConfigOption.ConnectionMode;
default:
{
return _shardingConfigOption.MaxQueryConnectionsLimit < sqlCount
? ConnectionModeEnum.CONNECTION_STRICTLY
: ConnectionModeEnum.MEMORY_STRICTLY; ;
}
}
}
比较
针对ShardingSphere的流程图我们可以看到在获取普通数据的时候是没有什么问题的,但是如果遇到分页也就是
select * from order limit 10,10
这种情况下会被改写成
select * from order limit 0,20
我们可以看到如果是ShardingSphere的流程模式那么在各个节点处虽然已经将连接数控制好了但是对于每个节点而言都有着20条数据,这种情况下其实是一种非常危险的,因为一旦节点过多并且limit的跳过页数过多每个节点储存的数据将会非常恐怖。
所以针对这种情况ShardingCore将同库下的各个节点组的查询使用StreamMerge而不是MemoryMerge,并且会对各个节点间建立联系进行聚合保证在同一个数据库下只会有20条数据被加载到内存中,大大降低了内存的使用,提高了内存使用率。
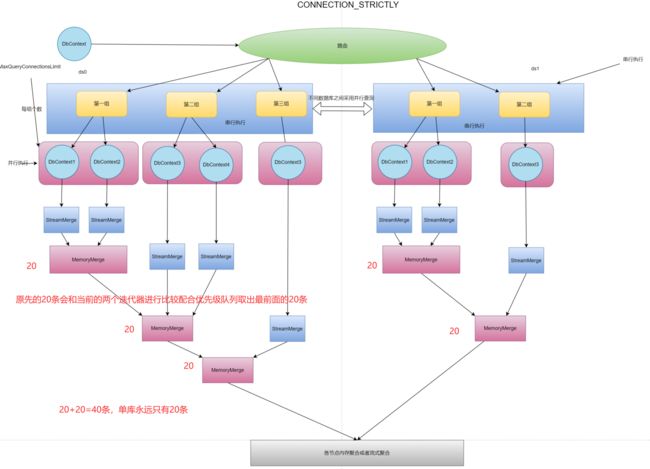
当然具体情况应该还需要再次进行优化并不是简单的一次优化就搞定的比如当跳过的页数过多之后其实在内存中的一部分数据也会再次进行迭代和新的迭代器比较,这个中间的性能差距可能需要不断地尝试才可以获取一个比较可靠的值
总结
目前已经有很多小伙伴已经在使用SharidingCore了并且在使用的时候也是相对比较简单的配置既可以“完美”目前她在使用的各种框架譬如:AbpVNext....基本上在继承和使用方面可以说是目前efcore生态下最最最完美的了真正做到了三零的框架:零依赖,零学习成本,零业务代码入侵
分表分库组件求赞求star
您的支持是开源作者能坚持下去的最大动力
- Github ShardingCore
- Gitee ShardingCore
博客
QQ群:771630778
个人QQ:326308290(欢迎技术支持提供您宝贵的意见)
个人邮箱:[email protected]