ELK+Filebeat+Kafka,SpringBoot异常日志收集
ELK+Filebeat+Kafka,SpringBoot异常日志收集
- 概述
- SpringBoot项目日志输出格式化
- 配置Filebeat汇集换行的日志为一行
- Logstash格式化项目日志
- 参考资料
概述
FileBeat + Kafka + ELK,收集SpringBoot项目的日志输出,有几个地方需要注意:
- 项目日志输出格式化
- Filebeat将多行日志汇集成一行
- Logstash将项目日志格式化为json
SpringBoot项目日志输出格式化
logback-spring.xml
[%d] [%p] [%t] [%c] - %m%n
UTF-8
...
xml配置文件中,[%d] [%p] [%t] [%c] - %m%n 确定了日志的规则,实际的日志输出格式如下:
[2021-04-25 09:50:58,255] [INFO] [RMI TCP Connection(23)-10.10.20.248] [org.springframework.web.servlet.DispatcherServlet] - Initializing Servlet 'dispatcherServlet'
[2021-04-25 09:50:58,324] [INFO] [RMI TCP Connection(23)-10.10.20.248] [org.springframework.web.servlet.DispatcherServlet] - Completed initialization in 69 ms
[2021-04-25 09:50:58,565] [WARN] [RMI TCP Connection(24)-10.10.20.248] [org.springframework.boot.actuate.elasticsearch.ElasticsearchHealthIndicator] - Elasticsearch health check failed
org.elasticsearch.client.transport.NoNodeAvailableException: None of the configured nodes are available: [{
#transport#-1}{
haxOm4fCQzaVW60mmuR-4w}{
10.10.50.84}{
10.10.50.84:9300}]
at org.elasticsearch.client.transport.TransportClientNodesService.ensureNodesAreAvailable(TransportClientNodesService.java:349)
at org.elasticsearch.client.transport.TransportClientNodesService.execute(TransportClientNodesService.java:247)
at org.elasticsearch.client.transport.TransportProxyClient.execute(TransportProxyClient.java:60)
at org.elasticsearch.client.transport.TransportClient.doExecute(TransportClient.java:381)
at org.elasticsearch.client.support.AbstractClient.execute(AbstractClient.java:407)
at org.elasticsearch.client.support.AbstractClient.execute(AbstractClient.java:396)
at org.elasticsearch.client.support.AbstractClient$ClusterAdmin.execute(AbstractClient.java:708)
at org.elasticsearch.client.support.AbstractClient$ClusterAdmin.health(AbstractClient.java:730)
at org.springframework.boot.actuate.elasticsearch.ElasticsearchHealthIndicator.doHealthCheck(ElasticsearchHealthIndicator.java:79)
at org.springframework.boot.actuate.health.AbstractHealthIndicator.health(AbstractHealthIndicator.java:84)
at org.springframework.boot.actuate.health.CompositeHealthIndicator.health(CompositeHealthIndicator.java:98)
at org.springframework.boot.actuate.health.HealthEndpoint.health(HealthEndpoint.java:50)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
配置Filebeat汇集换行的日志为一行
vi filebeat.yml
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: true
# lms 8301
paths:
- /var/logs/xapi/8301/*.log
tail_files: true
fields:
logtopic: elk-lms-8301
### Multiline options
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
#================================ Kafka ========================================
output.kafka:
enabled: true
# initial brokers for reading cluster metadata
hosts: ["10.10.20.26:9092"]
# message topic selection + partitioning
#topic: elk-lms-xapi
topic: '%{[fields.logtopic]}'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
name: 10.10.20.26_filebeat
这里的multiline.pattern,表示以‘[’开始的行为新一行。新一行之前的输出,算为当前行的内容。
Logstash格式化项目日志
vi logstash-8301.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
kafka {
bootstrap_servers => "10.10.20.26:9092"
topics => ["elk-lms-8301"]
# consumer_threads => 5
# decorate_events => true
auto_offset_reset => "latest"
# auto_offset_reset => "earliest"
client_id => "client-xapi-8301"
group_id => "group-xapi-8301"
}
}
filter {
# 将message转为json格式
grok {
match => {
"message" => "\[%{TIMESTAMP_ISO8601:log_time}\]\s\[%{LOGLEVEL:log_level}\]\s\[%{GREEDYDATA:log_from}\]\s\[%{JAVACLASS:log_classname}\]\s\-\s%{GREEDYDATA:log_detail}"
}
}
# 正则替换日志中的换行符, 最后一个参数是双引号包围的回车键
mutate {
gsub => ["log_detail", "\\n", "
"]
}
# 移动log_detail字符串中的系统属性 begin
if [log_detail] =~ "\"beat\"" {
grok {
match => {
"log_detail" => "(?(.*)(?=\" beat\")/?)"
}
overwrite => ["log_detail"]
}
}
if [log_detail] =~ "\"offset\"" {
grok {
match => {
"log_detail" => "(?(.*)(?=\" offset\")/?)"
}
overwrite => ["log_detail"]
}
}
if [log_detail] =~ "\"source\"" {
grok {
match => {
"log_detail" => "(?(.*)(?=\" source\")/?)"
}
overwrite => ["log_detail"]
}
}
if [log_detail] =~ "\"fields\"" {
grok {
match => {
"log_detail" => "(?(.*)(?=\" fields\")/?)"
}
overwrite => ["log_detail"]
}
}
if [log_detail] =~ "\"input\"" {
grok {
match => {
"log_detail" => "(?(.*)(?=\" input\")/?)"
}
overwrite => ["log_detail"]
}
}
if [log_detail] =~ "\"prospector\"" {
grok {
match => {
"log_detail" => "(?(.*)(?=\" prospector\")/?)"
}
overwrite => ["log_detail"]
}
}
# 移动log_detail字符串中的系统属性 end
}
output {
# 处理后的日志入es
if [fields][logtopic] == "elk-lms-8301" {
elasticsearch {
hosts => "10.10.20.26:9200"
index => "elk-lms-8301"
}
}
stdout {
codec => rubydebug
}
}
这里的关键配置是grok部分。
[%{TIMESTAMP_ISO8601:log_time}]\s[%{LOGLEVEL:log_level}]\s[%{GREEDYDATA:log_from}]\s[%{JAVACLASS:log_classname}]\s-\s%{GREEDYDATA:log_detail} 逐节解析如下:
- [%{TIMESTAMP_ISO8601:log_time}] :表示 [时间戳],如[2021-04-25 09:50:58,255]
- [%{LOGLEVEL:log_level}]:表示日志级别,如[INFO]
- [%{GREEDYDATA:log_from}]:表示来源,如[RMI TCP Connection(23)-10.10.20.248]
- [%{JAVACLASS:log_classname}]:表示java全路径的类名,如org.springframework.web.servlet.DispatcherServlet
- {GREEDYDATA:log_detail}:表示日志内容,如Initializing Servlet ‘dispatcherServlet’
所以,象下面的日志:
[2021-04-25 09:50:58,255] [INFO] [RMI TCP Connection(23)-10.10.20.248] [org.springframework.web.servlet.DispatcherServlet] - Initializing Servlet 'dispatcherServlet'
就会被格式化为:
{
"classname": "org.springframework.web.servlet.DispatcherServlet",
"level": "INFO",
"from": "RMI TCP Connection(23)-10.10.20.248",
"detail": "Initializing Servlet 'dispatcherServlet'",
"timestamp": "2021-04-25 09:50:58,255"
}
在kibana的Grok Debugger中,可以看到格式化的效果:
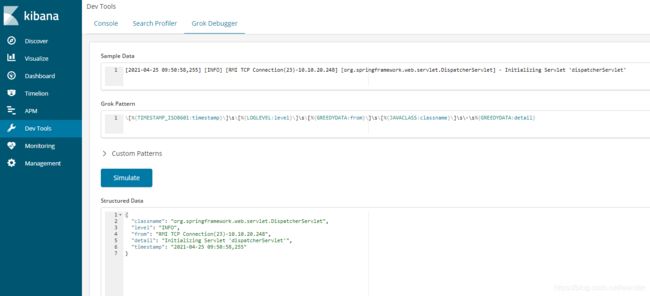
另,按如下方式启动Logstash,可以在修改配置文件时,自动重启Logstash,比较适合调试
nohup /home/wender/app/logstash-6.4.3/bin/logstash -f /home/wender/app/logstash-6.4.3/config/logstash.conf --config.reload.automatic &
参考资料
Logstash Grok patterns
ELK集群+Filebeat+Kafka
Kibana 用户手册
开始使用 Elasticsearch