在Maven插件的帮助下,VSCode写Java其实非常方便。这一讲我们介绍如何借助maven用VScode搭建Hadoop开发环境。
1.Java环境安装
首先我们需要搭建好Java开发环境。我们需要从网站 https://www.oracle.com/java/technologies/downloads/ 下载指定版本的Java压缩包或安装包。压缩包需要解压到机器的指定目录,安装包直接傻瓜式安装即可。我这里下载的是Java17的MacOS安装包,运行后它默认给我安装在了/Library/Java/JavaVirtualMachines/temurin-17.jdk/目录下。
然后配置环境变量,Mac用户在~/.zshrc中添加:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/temurin-17.jdk/Contents/Home
然后source ~/.zshrc即可(Linux用户我没记错的话应该是~/.bashrc文件)。
可以运行java -version命令查看当前机器的Java版本。
(base) lonelyprince7@lonelyprince7deMacBook-Pro ~ % java -version
openjdk version "17" 2021-09-14
OpenJDK Runtime Environment Temurin-17+35 (build 17+35)
OpenJDK 64-Bit Server VM Temurin-17+35 (build 17+35, mixed mode)
然后读者需要在VSCode中安装以下Java插件:

其中需要注意,Maven for Java插件是用来构建Java大型项目的(也就是说不只是使用JRE内部的包,而且使用外包的JDK包。内部的包用java命令编译的时候就会自动帮我们导入,但外部的包要稍微复杂一些,最简单的方式就是使用maven工具了)。
2.新建Maven项目
首先,用VSCode打开一个存放用于项目的目录(在我电脑上是 "/Users/lonelyprince7/Documents/LocalCode/Hadoop-MapReduce" ),然后在右键菜单中选择从Maven原型中创建新项目。
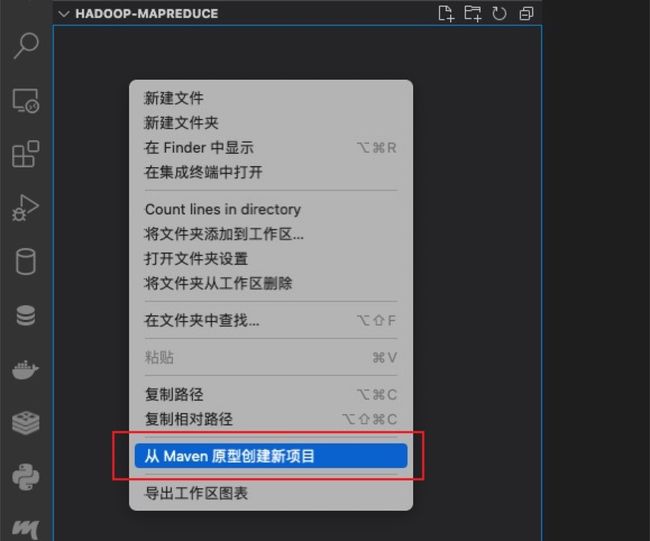
然后从下拉选单中选择“maven-archetype-quickstart”。

然后随便选择一个版本即可。

然后再输入组织的名称(该名称在将你的项目打包发布有用)。组织名称一般命名为com.×××,这里我命名为com.orion。注意组织名称只能由小写字符和下换线组成,不能包括大写字符和空格之类的东西。

接下来输入工程(archetype)的名称,这里我们命名为"hello_world"即可。

然后我们的工程目录就选择 "/Users/lonelyprince7/Documents/LocalCode/Hadoop-MapReduce" 就行。

之后VSCode会提示是否跳转到"hello_world"工程的目录,选择“是”,然后就退跳转到该目录。
进入该目录后,我们会发现控制台正在初始化Maven配置,有以下打印输出:
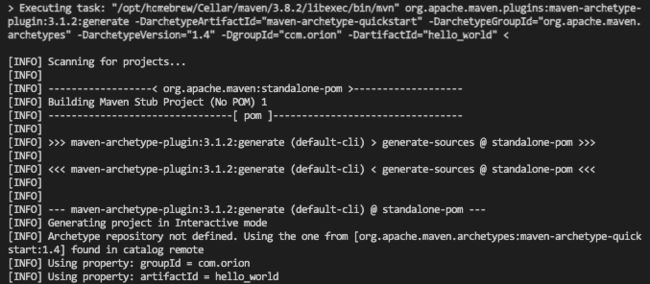
其中,会跳出一些选项让我们选择,我们只需要全部按回车选择默认值即可。

最后,我们看到项目"hello_world"成功创建,项目目录如下:

2.进行测试
我们可以看到App.java已经为我们生成,为如下内容:
package com.orion;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
System.out.println( "Hello World!" );
}
}
pom.xml只引入了最基本的junit依赖包,并配置了一些基本的Maven项目初始化的内容:
4.0.0
com.orion
hello_world
1.0-SNAPSHOT
hello_world
http://www.example.com
UTF-8
1.7
1.7
junit
junit
4.11
test
maven-clean-plugin
3.1.0
maven-resources-plugin
3.0.2
maven-compiler-plugin
3.8.0
maven-surefire-plugin
2.22.1
maven-jar-plugin
3.0.2
maven-install-plugin
2.5.2
maven-deploy-plugin
2.8.2
maven-site-plugin
3.7.1
maven-project-info-reports-plugin
3.0.0
选中App.java文件按F5进行编译并运行,看到控制台成功打印Hello World!:
(base) lonelyprince7@lonelyprince7deMacBook-Pro hello_world % /usr/bin/env /Library/Java/JavaVirtualMachines/temurin-17.jdk/Contents/Home/bin/java -agentlib:jdwp=transport=dt_socket,server=n,suspend=y,address=localhost:50684 -XX:+ShowCodeDetailsInExceptionMessages -cp /Users/lonelyprince7/Documents/LocalCode/Hadoop-MapReduce/hello_world/target/classes com.orion.App
Hello World!
我们接下来试试用Maven导入Hadoop依赖。我们只需要在pom.xml依赖项就行。相关的依赖项的名称和版本号我们可以在Maven仓库的官网 https://mvnrepository.com/ 进行查询,比如我们可以查询到Hadoop-common(3.3.1)版本的依赖项如下:
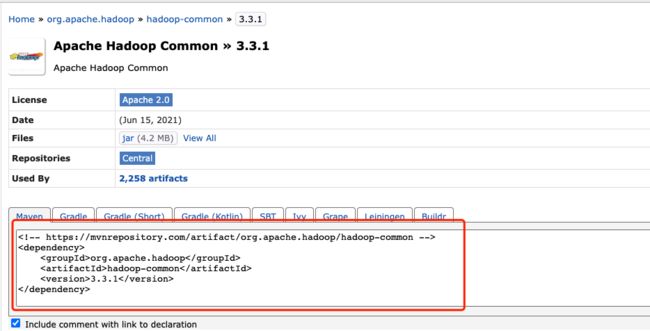
一般来说,Hadoop项目需要引入hadoop-common、hadoop-hdfs、hadoop-client、hadoop-yarn-api这几个api,我们需要将下列标签加入
junit
junit
4.11
test
org.apache.hadoop
hadoop-common
3.3.1
org.apache.hadoop
hadoop-hdfs
3.3.1
org.apache.hadoop
hadoop-mapreduce-client-core
3.3.1
org.apache.hadoop
hadoop-client
3.3.1
org.apache.hadoop
hadoop-yarn-api
3.3.1
但是聪明的逆可能已经注意到了,这样版本号就完全属于“硬编码”了。后期我要修改hadoop的版本号,只能把上面的挨个修改,非常麻烦。好在我们在${变量名}的形式来引用即可。如我们将hadoop的版本号hadoop.version追加到
UTF-8
1.7
1.7
3.3.1
然后后面我们就可以使用${hadoop.version}来替代前面频繁出现的3.3.1了。
最后给出我们完整的pom.xml文件:
4.0.0
com.orion
hello_world
1.0-SNAPSHOT
hello_world
http://www.example.com
UTF-8
1.7
1.7
3.3.1
junit
junit
4.11
test
org.apache.hadoop
hadoop-common
${hadoop.version}
org.apache.hadoop
hadoop-hdfs
${hadoop.version}
org.apache.hadoop
hadoop-mapreduce-client-core
${hadoop.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.hadoop
hadoop-yarn-api
${hadoop.version}
maven-clean-plugin
3.1.0
maven-resources-plugin
3.0.2
maven-compiler-plugin
3.8.0
maven-surefire-plugin
2.22.1
maven-jar-plugin
3.0.2
maven-install-plugin
2.5.2
maven-deploy-plugin
2.8.2
maven-site-plugin
3.7.1
maven-project-info-reports-plugin
3.0.0
s
按ctrl/command+s保存,项目会对pom.xml重新解析,导入我们添加进入的包。
最后我们尝试在App.java中导入hadoop相关的包:
package com.orion;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
System.out.println( "Hello World!" );
}
}
按'F5'重新编译运行,成功打印输出Hello World!,说明我们的包导入成功。
(base) lonelyprince7@lonelyprince7deMacBook-Pro hello_world % /usr/bin/env /Library/Java/JavaVirtualMachines/temurin-17.jdk/Contents/Home/bin/java -agentlib:jdwp=transport=dt_socket,server=n,suspend=y,address=localhost:54181 --enable-preview -XX:+ShowCodeDetailsInExceptionMessages -cp "/Users/lonelyprince7/Library/Application Support/Code/User/workspaceStorage/fe34994f622cdbfbf60e8ed045c6bde3/redhat.java/jdt_ws/jdt.ls-java-project/bin" com.orion.App
Hello World!
注意,如果报错org.apache.hadoop.fs.FileSystem cant be resolved这种错误,则需要先清空项目缓存,然后再重新编译运行。
至此,我们已经成功用VSCode+Maven创建好一个Hadoop的开发环境。在Hadoop编程中,最基本的一种分布式编程范式即MapReduce编程。在后面我们会借由“WordCount”(词频统计)这个MapReduce编程的入门项来讲解Hadoop中MapReduce编程的基本语法,敬请继续关注。