sklearn 机器学习性能分析指标
分类是机器学习中比较常见的任务,对于分类任务常见的评价指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 score、P-R曲线、ROC曲线(Receiver Operating Characteristic Curve)等。
- 混淆矩阵
sklearn接口:sklearn.metrics.confusion_matrix(y_true, y_pred)
在了解这几个性能指标之前,需要先了解混淆矩阵,混淆矩阵中的P表示Positive,即正例或者阳性,N表示Negative,即负例或者阴性。
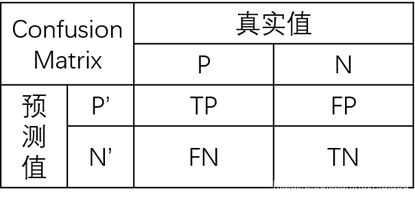
表中FP表示实际为负但被预测为正的样本数量,TN表示实际为负被预测为负的样本的数量,TP表示实际为正被预测为正的样本数量,FN表示实际为正但被预测为负的样本的数量。
另外,TP+FP=P’表示所有被预测为正的样本数量,同理FN+TN=N’为所有被预测为负的样本数量,TP+FN为实际为正的样本数量,FP+TN为实际为负的样本数量。
- 准确率
sklearn接口:sklearn.metrics.accuracy_score(y_true, y_pred)
准确率是分类正确的样本占总样本个数的比例,即

其中,ncorrect为被正确分类的样本个数,ntotal为总样本个数。
结合上面的混淆矩阵,公式还可以这样写:
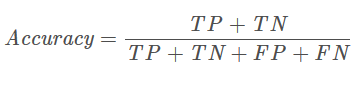
准确率是分类问题中最简单直观的评价指标,但存在明显的缺陷。比如如果样本中有99%的样本为正样本,那么分类器只需要一直预测为正,就可以得到99%的准确率,但其实际性能是非常低下的。也就是说,当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
- 精确率
sklearn接口:sklearn.metrics.precision_score(y_true, y_pred)
精确率指模型预测为正的样本中实际也为正的样本占被预测为正的样本的比例。计算公式为:
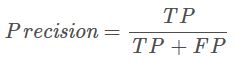
- 召回率
sklearn接口:sklearn.metrics.recall_score(y_true, y_pred)
召回率指实际为正的样本中被预测为正的样本所占实际为正的样本的比例。

- F1 score
sklearn接口:sklearn.metrics.f1_score(y_true, y_pred)
F1 score是精确率和召回率的调和平均值,计算公式为:
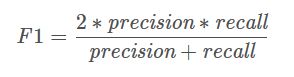
Precision体现了模型对负样本的区分能力,Precision越高,模型对负样本的区分能力越强;Recall体现了模型对正样本的识别能力,Recall越高,模型对正样本的识别能力越强。F1 score是两者的综合,F1 score越高,说明模型越稳健。
- P-R曲线
sklearn接口:sklearn.metrics.precision_recall_curve(y_true, y_pred)
评价一个模型的好坏,不能仅靠精确率或者召回率,最好构建多组精确率Precision和召回率Recall,绘制出模型的P-R曲线。
下面说一下P-R曲线的绘制方法。P-R曲线的横轴是召回率,纵轴是精确率。P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。整条P-R曲线是通过将阈值从高到低移动而生成的。原点附近代表当阈值最大时模型的精确率和召回率。
- 根据P-R曲线比较学习器性能
a.若一个学习器的P-R曲线被另一个学习器曲线完全包住,那么可以确定后者性能优于前者;
b.若两个学习器的P-R曲线存在交集,那么可以比较面积(计算复杂)
c.基于平衡点(查全率等于准确率的点)衡量性能。平衡点越大,性能越好
d.基于F1 score度量
e. 基于 Fβ,Fβ可以对查全率和查准率的不同偏重衡量学习器的性能
- ROC曲线
sklearn接口:sklearn.metrics.roc_curve(y_true, y_pred)
根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出假正例率(TPR)和真正例率(FPR),以这两个值为坐标绘制曲线即为ROC(Receiver Operating Characteristic)
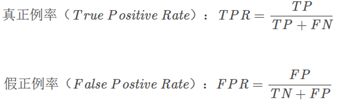
ROC曲线的绘制原理与P-R曲线一样,只是横纵坐标的指标不一样而已。
- 分类报告
sklearn接口:sklearn.metrics.classification_report(y_true, y_pred)
分类报告是将分类器得到的准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 score等信息以报告的形式给出来,如下图所示:
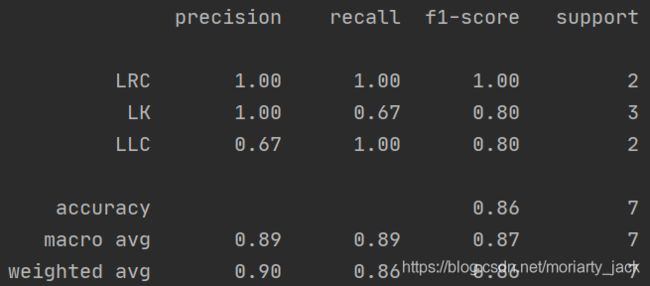
- 代码示例
from sklearn import svm
import numpy as np
from sklearn.metrics import f1_score, accuracy_score, precision_score, recall_score, confusion_matrix
from sklearn.metrics import classification_report
x = np.array([[0.1], [0.5], [0.6], [0.15], [1.3], [0.42], [1.13], [0.31], [0.86], [0.84], [2.12]])
y = [0, 1, 1, 0, 2, 0, 2, 0, 1, 1, 2]
clf = svm.SVC(C=200, kernel='linear', decision_function_shape='ovo', probability=True)
clf.fit(x, y)
test_x = [[0.4], [1.1], [0.3], [0.8], [0.84], [2.1], [1.0]]
test_y = [0, 2, 0, 1, 1, 2, 1]
pred_y = clf.predict(test_x)
print("pred_y:", pred_y)
pro_y = clf.predict_proba(test_x)
print("pro_y:", pro_y)
# 计算准确率
print(accuracy_score(test_y, pred_y))
# 计算精确率
print("precision_score")
print(precision_score(test_y, pred_y, average='macro'))
# print(precision_score(test_y, pred_y, average='micro'))
# 计算召回率
print(recall_score(test_y, pred_y, average='macro'))
# 计算F1 score
# 综合评价指标:精确率和召回率的调和均值(harmonic mean),或加权平均值,也称为F-measure或F-score。
# F-measure 平衡了精确率和召回率。当F-measure较高的时候,说明模型效果比较好。
# (精确率和召回率都越高越好,但在一些极端情况下,两者是矛盾的)
# F-measure = 2 * Precision * Recall / (Precision + Recall)
print(f1_score(test_y, pred_y, average='macro'))
# 混淆矩阵
print(confusion_matrix(test_y, pred_y, labels=None, sample_weight=None))
# 分类报告
target_names = ['LRC', 'LK', 'LLC']
print(classification_report(test_y, pred_y, target_names=target_names))
参考博客:https://blog.csdn.net/hfutdog/article/details/88085878