【学习记录】在Ubuntu部署Yolox踩坑
1.我的系统环境是Ubuntu 18.04,python3.7,cuda10.2

2.为了让我服务器上安装的东西不产生版本冲突,我们使用conda创建一个yolox的环境变量来专门安装yolox需要的依赖。
#创建名为yolox的python版本为3.7的虚拟环境。
conda create -n yolox python=3.7
#通过下面的命令进入创建的虚拟环境。
conda activate yolox3.然后按照官方(https://github.com/Megvii-BaseDetection/YOLOX)给的给的安装示例,配置必须的包:
git clone [email protected]:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -U pip && pip3 install -r requirements.txt
pip3 install -v -e . # or python3 setup.py develop
4. 然后安装pycocotools,我这一步比较顺利,直接通过:
pip3 install cython; pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
5.demo测试。通过测试官方给的例子来看看自己的环境配置是否成功了。
首先我们从官网上下载人家提供好的权重。我只下载了其中我标红框的权重,如下图所示:
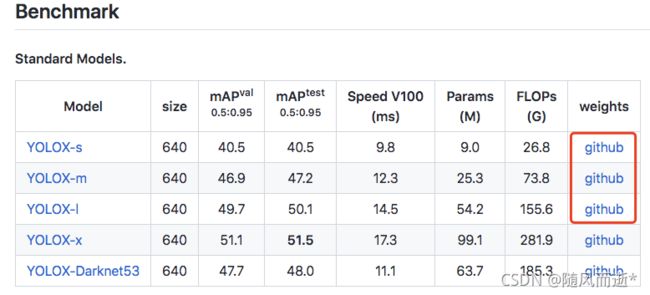
我给下载后的权重直接放在YOLO-main的目录下。如下图所示:其中YOLOX_outputs是测试后的结果路径。
然后运行下面官网给的测试demo。结果如下图所示:
#这是官网给的示例,我们需要修改一下其中的一些参数路径。
python tools/demo.py image -n yolox-s -c /path/to/your/yolox_s.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]
#我们自己运行的示例。
python tools/demo.py image -n yolox-s -c ./yolox_s.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device gpu

其中:
- image是推理模式,如果是输入视频则为video
- -n 是模型的名字
- -c 为权重文件地址
- –path是测试的图片路径
- –conf 置信度阈值
- –nms nms的iou阈值
- –tsize 测试图片大小
- –save_result 是否保存推理结果
这步之后环境基本上没问题了,接下来准备数据开始训练吧。
6.数据准备和配置修改。
官方给的配置方法(https://github.com/Megvii-BaseDetection/YOLOX/blob/main/docs/train_custom_data.md)
程序中提供了voc和coco两种格式的数据训练,我这里用的是voc格式训练,voc格式的文件结构如下:
├── datasets #手动创建VOCdevkit、VOC2007、Annotations、JPEGImages、ImageSets、Main这些文件夹
│ ├── VOCdevkit
│ │ ├── VOC2007
│ │ │ ├── Annotations #把val.txt、train.txt对应的xml文件放在这
│ │ │ ├── JPEGImages #把val.txt、train.txt对应的图片放在这
│ │ │ ├── ImageSets
│ │ │ │ ├── Main
│ │ │ │ │ ├── val.txt
│ │ │ │ │ ├── train.txt
通常标注完后只有这两个文件夹(Annotations和JPEGImages),所以新建一个ImageSets文件,并在其子目录再新建一个Main文件,然后运行如下代码,划分数据集,得到val.txt和train.txt文件。注意:我们这里写好的get_train_val.py脚本要和Annotations,JPEGImages,ImageSets在同一目录下,如下图所示:
# 对数据集进行拆分,分为train.txt和val.txt
import os
import random
images_path = "JPEGImages/"
xmls_path = "Annotations/"
train_val_txt_path = "ImageSets/Main/"
val_percent = 0.1
images_list = os.listdir(images_path)
random.shuffle(images_list)
# 划分训练集和验证集的数量
train_images_count = int((1-val_percent)*len(images_list))
val_images_count = int(val_percent*len(images_list))
# 生成训练集的train.txt文件
train_txt = open(os.path.join(train_val_txt_path,"train.txt"),"w")
train_count = 0
for i in range(train_images_count):
text = images_list[i].split(".jpg")[0] + "\n"
train_txt.write(text)
train_count+=1
print("train_count: " + str(train_count))
train_txt.close()
# 生成验证集的val.txt文件
val_txt = open(os.path.join(train_val_txt_path,"val.txt"),"w")
val_count = 0
for i in range(val_images_count):
text = images_list[train_images_count + i].split(".jpg")[0] + "\n"
val_txt.write(text)
val_count+=1
print("val_count: " + str(val_count))
val_txt.close()要严格按照这个格式制作数据集,因为程序中是按照这个结构读取,然后把exps/example/yolox_voc/yolox_voc_s.py文件复制一份到YOLOX-main目录下,防止我们直接在源文件上修改会报错。然后我们需要修改yolox_voc_s.py下面这些地方。
#1.在文件的第14行,我们需要给类别改成我们自己数据集合的类别。我的数据集合泪类别是4类,所以我改c成4
11 class Exp(MyExp):
12 def __init__(self):
13 super(Exp, self).__init__()
14 self.num_classes = 4
15 self.depth = 0.33
16 self.width = 0.50
17 self.warmup_epochs = 1
#2.我们需要修改45行,把数据路径改为我们自己数据集的绝对路径,修改47行的image_sets如下所示。
43 with wait_for_the_master(local_rank):
44 dataset = VOCDetection(
45 data_dir='/home/jsj/yolox/YOLOX-main/datasets/VOCdevkit',
46 #data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"),
47 image_sets=[('2007', 'train')],
48 img_size=self.input_size,
#3.我们需要修改105行,把数据路径改为我们自己数据集的绝对路径,修改107行的image_sets如下所示。
104 valdataset = VOCDetection(
105 data_dir='/home/jsj/yolox/YOLOX-main/datasets/VOCdevkit',
106 #data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"),
107 image_sets=[('2007', 'val')],
108 img_size=self.test_size然后修改yolox/data/datasets/voc_classes.py,这里加上自己的类别,删除掉(或者注释掉)原始类别:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.
# VOC_CLASSES = ( '__background__', # always index 0
VOC_CLASSES = (
"f1_c",
"f2_o",
"b3_c",
"b4_o",
)然后按照如下修改yolox/data/datasets/voc.py
#注释掉316行,重新改为314和315行。
311 def _do_python_eval(self, output_dir="output", iou=0.5):
312 rootpath = os.path.join(self.root, "VOC" + self._year)
313 name = self.image_set[0][1]
314 annopath = os.path.join(rootpath, "Annotations")
315 annopath = annopath + "/{:s}.xml"
316 #annopath = os.path.join(rootpath, "Annotations", "{:s}.xml")
317 imagesetfile = os.path.join(rootpath, "ImageSets", "Main", name + ".txt")最好修改yolox/exp/yolox_base.py,训练中一些超参数也在这个文件中修改。
class Exp(BaseExp):
def __init__(self):
super().__init__()
# ---------------- model config ---------------- #
self.num_classes = 4 #我们需要给类别修改成我们自己的类别。
self.depth = 0.33
self.width = 0.50
# ---------------- dataloader config ---------------- #
# set worker to 4 for shorter dataloader init time
self.data_num_workers = 4
self.input_size = (1920, 1088) # (height, width)我们需要给出我们原始图片的像素信息。
# Actual multiscale ranges: [640-5*32, 640+5*32].
# To disable multiscale training, set the
# self.multiscale_range to 0.
self.multiscale_range = 5
# You can uncomment this line to specify a multiscale range
self.random_size = (14, 26)
self.data_dir = None
self.train_ann = "instances_train2017.json"
self.val_ann = "instances_val2017.json"
# --------------- transform config ----------------- #
self.mosaic_prob = 1.0
self.mixup_prob = 1.0
self.hsv_prob = 1.0
self.flip_prob = 0.5
self.degrees = 10.0
self.translate = 0.1
self.mosaic_scale = (0.1, 2)
self.mixup_scale = (0.5, 1.5)
self.shear = 2.0
self.perspective = 0.0
self.enable_mixup = True
# -------------- training config --------------------- #
self.warmup_epochs = 5
self.max_epoch = 300
self.warmup_lr = 0
self.basic_lr_per_img = 0.01 / 64.0
self.scheduler = "yoloxwarmcos"
self.no_aug_epochs = 15
self.min_lr_ratio = 0.05
self.ema = True
self.weight_decay = 5e-4
self.momentum = 0.9
self.print_interval = 20
self.eval_interval = 20
self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]
# ----------------- testing config ------------------ #
self.test_size = (1920, 1088) #验证集的图片测试像素也要改成我们图片自己的像素。
self.test_conf = 0.01
self.nmsthre = 0.65然后我们可以开始训练了,训练提交代码如下:
#因为我是在服务器上跑的所以我直接nohup提交到后台开始运行。
nohup python tools/train.py -f ./yolox_voc_s.py -d 4 -b 32 --fp16 -c yolox_s.pth --cache >>log.log &
- -d 使用多少张显卡训练
- -b 批次大小
- –fp16 是否开启半精度训练
- -f 为训练约束文件的路程
- -c 为预训练集权重文件路径
- --cache 利用RAM加速训练,请确保电脑内存足够,可以不写该指令
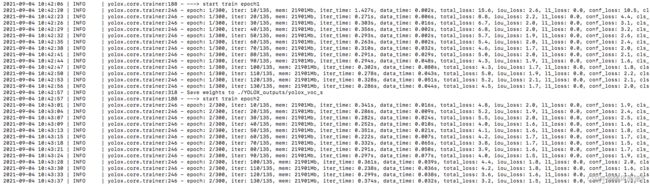
训练结果存放在YOLOX_outputs文件夹中,训练结束后会生成best_ckpt.pth.tar,一般取这个为最终的权重文件 。训练过程如下:
本博主新开公众号,希望大家扫码关注支持一下。
