NumPy库学习:数据分析Chapter1
数据分析学习笔记
1.基础概念和环境
1.1课程概要
概 要 { 基 础 概 念 和 环 境 m a t p l o t l i b 画图 n u m p y 处理数值型数组 p a n d a s 处理字符串,列表,字典等其他的数据类型 概要\begin{cases} 基础概念和环境\\ matplotlib \quad\text{画图}\\ numpy \qquad\text{处理数值型数组}\\ pandas \qquad\text{处理字符串,列表,字典等其他的数据类型}\\ \end{cases} 概要⎩⎪⎪⎪⎨⎪⎪⎪⎧基础概念和环境matplotlib画图numpy处理数值型数组pandas处理字符串,列表,字典等其他的数据类型
1.2综述
- 学习数据分析的原因:
难以在成千上万的数据中寻找到有用的规律和信息,需要对大量的数据进行统计和分析,总结出有效的规律,绘制出直观的图像,以供应用。

另外数据分析也是python数据科学和机器学习的基础
- 数据分析的概念
用适当的方法对搜集来的大量数据进行分析,帮助人们进行判断,以便采取行动。
- 数据分析的步骤
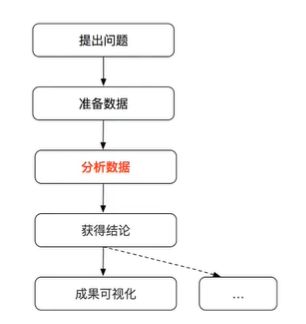
- 摘要的过程
1.3IDE的选择
{ 文 本 工 具 类 I D E { I D L E N o t e p a d + + A t o m S u b l i n e T e x t 集 成 工 具 类 I D E { P y C h a r m W i n g V i s u a l S t d i o A n a c o n d a & S p y d e r C a n o p y \begin{cases} 文本工具类IDE \begin{cases} IDLE\\ Notepad++\\Atom\\ Subline\,Text \end{cases}\\ 集成工具类IDE\begin{cases} PyCharm\\ Wing\\ Visual\,Stdio\\ Anaconda&Spyder\\ Canopy\\ \end{cases} \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧文本工具类IDE⎩⎪⎪⎪⎨⎪⎪⎪⎧IDLENotepad++AtomSublineText集成工具类IDE⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧PyCharmWingVisualStdioAnaconda&SpyderCanopy
-
IDLE
- Python入门
- 简单功能,直接
-
Subline Text
- 第三方编程工具
- 专业程序员prefer
-
Wing
- 适合多人开发
-
Eclipse
-
PyCharm
- 简单,集成度高
针对数据分析的开发环境:
- Canopy
- 工具维护,收费
- Anaconda
- 开源,免费
- 一个集合,包括conda,某版本的Python,一批第三方库等
conda将工具,第三方库,Python版本等都当做包同等对待。
这里安装了Anaconda,在下载安装Anaconda的同时,Spyder和一系列库也被安装好了。
第一次打开Anaconda可能会疑惑快捷方式为什么没有生成,其实可以通过开始菜单栏的Anaconda Navigator打开。需要的话可以打开文件位置,选择exe文件右键,然后发送快捷方式到桌面。
Spyper的开始界面:
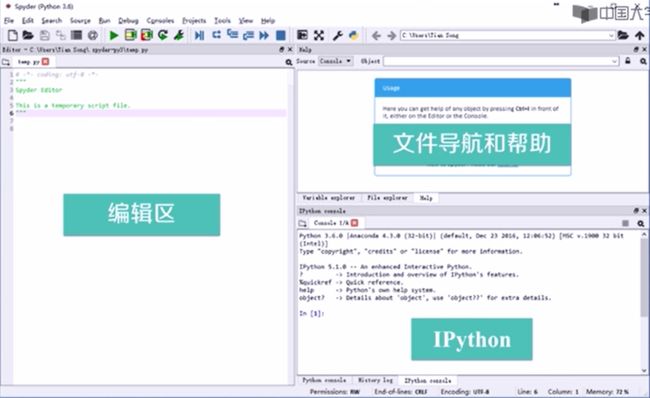
IPython区是一个功能强大的交互式shell
适合进行交互式数据可视化和GUI相关应用。
IPython的一些使用小技巧:
-
在变量后加上?,能够获取该变量的类型等信息;对于函数,后面加上?能够获得函数的使用方法等信息。
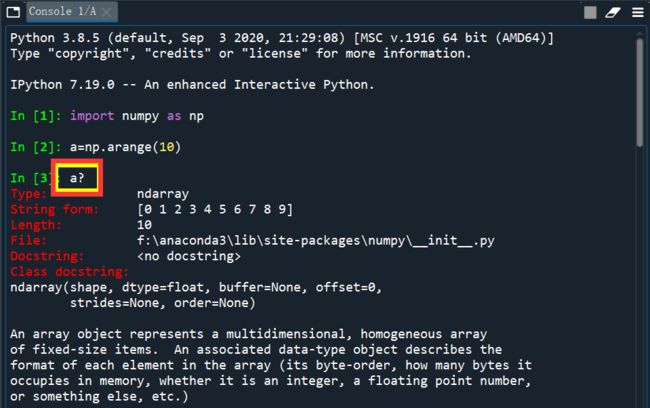
-
IPython中有明显的提示用户输入输出的字段,
In-Out字段
-
IPython的
%run命令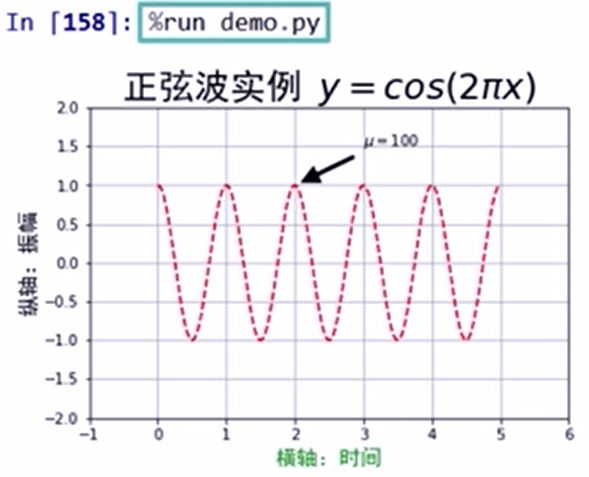
%run命令用于执行.py文件魔法命令:

IPython的本质是什么呢?
能够调用核心的python解释器,只是一个前台的显示的脚本,后台的程序运行还是依靠python的解释器来进行的。
IPython的魔术命令使用实例:
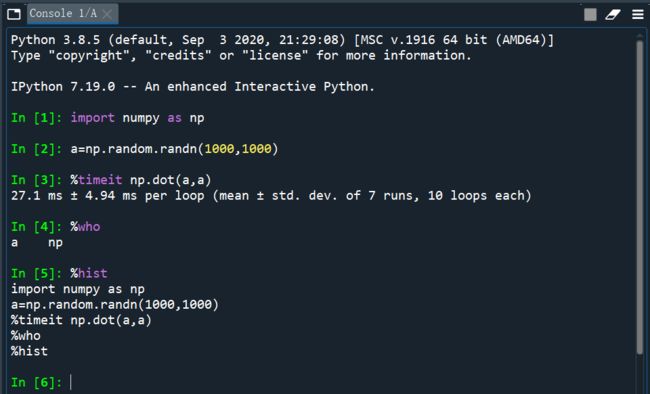

-
Jupyter Notebook部分使用快捷键:
-
shift+enter:运行生成一个新的代码块
-
esc+m/y:markdown和代码模式的切换
-
2.Numpy库
2.1 Numpy库入门
维度:数据的组织形式,在数据之间形成特定关系。表示特定含义。

(1)一维数据
对应列表,数组,集合等概念
- 列表和数组的区别
- 一个列表中数据类型可以是不同的,可以是数字,字符串,甚至是列表多种类型的混合
- 数组要求数据类型全是数组类型,比如全是浮点型
(2)二维数据
由一维数据组合而成,是一维数据的组合形式,如表格
(3)多维数据
由一维或二维数据在新的维度上发展
(4)高维数据
仅由最基本的二维关系展示数据间的复杂结构:键值对

Python中:
- 一维数据
- 列表 有序
- 集合 无序
- 二维数据
- 列表
- 高维数据
- 字典 键值对
2.2 NumPy库
2.2.1N维数组对象 ndarray
1.NumPy的引用:
import numpy as np
其中as np表示起一个别名,可以叫别的,也可以省略,但建议使用这种约定俗成的方式
2.ndarray
例:计算 A 2 + B 3 A^2+B^3 A2+B3
- 传统方式:

- 使用ndarray

ndarray是一个多维数组对象,要求:
- 实际的数据
- 描述这些数据的元数据
ndarray要求数组元素类型相同,数组下标从零开始
注意到我们上面的例子并没有出现ndarray,其实ndarray在程序中的别名就是array,使用np.array即可生成。

轴(axis):保存数据的维度
秩(rank):轴的数量
ndarray对象的属性:

这里我们以上面创建的数组a为例,打印出这些属性:
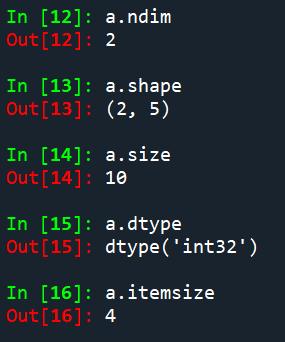
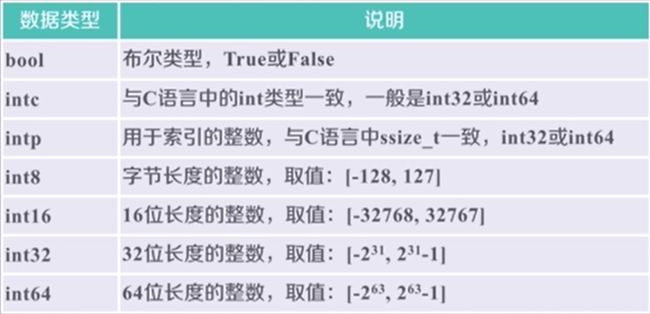
(1)ndarray数组的创建
- 从python中的列表元组等类型创建
这种方式比较简单,直接使用np.array(list/tuple)方法就行,讲list或者tuple传入即可
同时可以指定传入数据的类型:np.array(list/tuple,dtype=np.float32)
当不指定时,NumPy自动根据数据组织情况确定一个dtype
其中,可以只传入list,只传入tuple,也可以都传入:
#ndarray数组对象的创建
import numpy as np
#法①:通过np.array(list/tuple)创建
L1=[1,2,3,4,5]
L2=[4,5,6,7,8]
T1=(1,2,3,4,5)
T2=(3,4,2,1,0)
myArray=np.array([L1,L2,T1])#注意外面那个方括号一定要加上,表示一个整体
print(myArray)
- 使用NumPy中的函数创建ndarray数组,如arange,ones,zeros等
#法②:通过NumPy中的函数创建
#函数有arange() ones() zeros() full() eye() 五种,分别演示
import numpy as np
#类似于range,元素从 0 到 n-1
array1=np.arange(11)
print(array1)
#注意3,4要以括号括起来
array2=np.ones((3,4))
print(array2)
#零矩阵
array3=np.zeros((4,5))
print(array3)
#整个矩阵全是value值
array4=np.full((3,3),8,np.int32)
print(array4)
#对角线矩阵,n*n对角线元素全是1
array5=np.eye(5)
print(array5)
#使用np的函数创建多维数组,并且返回矩阵维度
import numpy as np
array=np.zeros((3,4,5))
print(array.shape)
#输出结果为(3,4,5)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5PsZ6dDC-1611410737007)(C:%5CUsers%5C86180%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20210123163647598.png)]
上述的三个函数在规模计算时非常好用。

linspace函数主观上看上去和切片的功能有些相似,不同的是切片是取,而linspace是生成:
#np的linspace函数和concatenate函数,默认浮点数
#使用linspace函数等间距的填充:
import numpy as np
a=np.linspace(1,10,4)
print(a)#[ 1. 4. 7. 10.]
#在linspace函数中有一个参数叫做endpoint,取值为True或者False
#表示最后一个元素在不在序列中:
b=np.linspace(1,10,4,False)
print(b)#[1. 3.25 5.5 7.75]
#10将不作为末尾元素出现
#将两个元组合并:
c=np.concatenate((a,b))#注意要大括号,表示元组
print(c)#[ 1. 4. 7. 10. 1. 3.25 5.5 7.75]
(2)ndarray数组的维度变换

#使用np的函数对数组的维度进行变化
#这里要注意,什么方法是会改变原来数组的
#什么方法是不会改变原数组,返回一个新数组的
import numpy as np
a=np.ones((2,3,4),dtype=np.int32)
array=a.reshape((3,8))#不改变原数组,回回一个新数组
print("a=\n",a)
print("array=\n",a)
(3)ndarray数组的类型变换
使用方法:a=np.astype(),这个方法是一定会还原一个新的数组


(4)ndarray对象向数组转化
a.tolist()方法

(4)数组的索引和切片
索引:获取数组中特定元素的过程
切片:获取数组元素子集的过程
#一维数组的索引和切片
#和列表相似
import numpy as np
a=np.array([1,2,3,4,5])
#索引:
print("下标为2的元素为:",a[2])
#切片:获取元素的子集
print(a[1:4:2])
#多维数组的索引和切片
import numpy as np
a=np.arange(24).reshape((2,3,4))
print("a=\n",a)
print(a[1,2,3])
print(a[1,0,2])
print(a[-1,-2,-3])


(5)ndarray数组的计算
-
标量运算


-
二元运算

-
从字节流(raw bytes)中创建
-
从文件中读取特定格式,创建ndarray数组
2.3 Numpy数据存取与函数
CSV文件
CSV文件是以逗号分隔值的文件格式,用来批量存储数据
写入CSV文件
写入CSV文件使用方法:np.savetxt(frame,array,fmt='%.18e',delimiter=None),其实可以生成任何的文件
其中:
- frame:文件,字符串或产生器,可以是.gz或者.bz2的压缩文件
- array:要写入的数组
- fmt:写入文件的格式,例如:%d %.2f %.18e默认是保留18位小数的科学计数法
- delimiter:分割字符串,默认是空格
import numpy as np
#写入CSV文件:
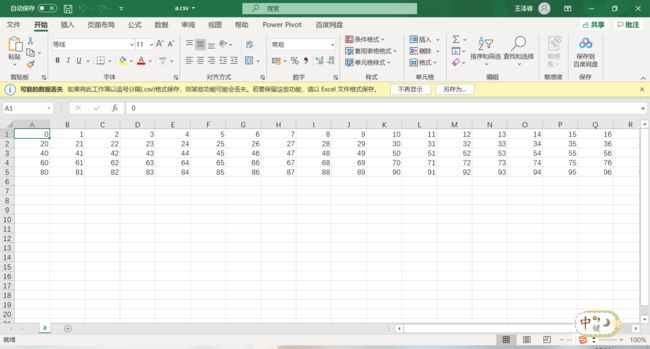
a=np.arange(100).reshape(5,20)
np.savetxt('a.scv',a,fmt='%d',delimiter=',')
运行上述的代码,我们可以看到当前的路径下多了一个叫做a.csv的文件:

并且是可以用excel打开的
载入CSV文件
载入CSV文件使用函数np.loadtxt(frame,dtype=np.float,delimiter=None,uppack=False)
其中:
- frame:文件,字符串或产生器,可以是.gz或者.bz2的压缩文件
- dtype:数据类型,可选,默认是浮点型
- dilimiter:分割字符串,默认是空格,CSV中要改成逗号
- unpack:默认是False,如果是True,读入属性将分别写入不同的变量

局限性
只能限于一维和二维数据
多维数据存取
写入文件
使用函数:np.tofile(frame,sep='',format=%s')函数
-
frame:文件,字符串或产生器,可以是.gz或者.bz2的压缩文件
-
sep:数据分割字符串,如果是空串,写入文件为二进制
-
format:写入数据的格式
读入文件
使用函数:np.fromfile(frame,dtype='float',count=-1,sep='')函数
- frame:文件,字符串
- dtype:读入文件的类型
- count:读入元素的个数,-1表示整个文件
- 数据分割字符串,空表示二进制
#多维数据的存取
import numpy as np
a=np.arange(100).reshape(5,10,2)
a.tofile('b.dat',sep=",",format="%d")#sep=,是文本文件,不是二进制文件
#多维数据的加载
c=np.fromfile("b.dat",dtype=np.int,sep=",").reshape(5,10,2)
print(c)
二进制文件:

注意的是:要知道原数据的维度信息才可储存
NumPy的便捷文件存取

这种存储形式不必知道原来存储的数据的维度信息。
import numpy as np
a=np.arange(100).reshape(5,10,2)
#采用NumPy的便捷文件存储
np.save("a.npy",a)
#直接导入,不需要知道维度信息就可以输出和原数组一样的数组
b=np.load("a.npy")
print(b)
随机数函数

import numpy as np
#均匀分布
a=np.random.rand(3,4,5)
print(a)
#正态分布
sn=np.random.randn(3,4,5)
print(sn)
#均匀分布
b=np.random.randint(100,200,(3,4))
print(b)
#选择种子的均匀分布
#种子相同,随机数数组相同
np.random.seed(10)
b=np.random.randint(100,200,(3,4))
print(b)
高阶函数:


含有特定分布的函数:

#使用含有分布的随机数函数
import numpy as np
#均匀分布
u=np.random.uniform(0,10,(3,4))
print(u)
#正态分布
sn=np.random.normal(10,5,(3,4))
print(sn)
统计函数

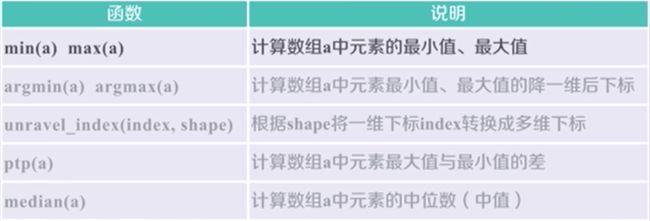
函数示例:

梯度函数
使用函数:np.gradient函数,计算f中元素的梯度,当f为多维时,返回每个维度梯度
梯度:连续值的变化率
[外链图片转存中…(img-DXk06HCt-1611410737017)]
#使用含有分布的随机数函数
import numpy as np
#均匀分布
u=np.random.uniform(0,10,(3,4))
print(u)
#正态分布
sn=np.random.normal(10,5,(3,4))
print(sn)
统计函数
[外链图片转存中…(img-tMtgulOS-1611410737018)]
[外链图片转存中…(img-qzQSEGkq-1611410737019)]
函数示例:
梯度函数
使用函数:np.gradient函数,计算f中元素的梯度,当f为多维时,返回每个维度梯度
梯度:连续值的变化率
