学习笔记——跑crf需要用到的库和包(持续更新中)
import scipy
import sklearn_crfsuite
from sklearn.metrics import make_scorer
from sklearn.model_selection import train_test_split
from sklearn_crfsuite import scorers
from sklearn_crfsuite import metrics
from collections import Counter
from sklearn. model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV一.关于scipy有很多的库这里着重绝对指数分布介绍(scipy.stats.expon)
1、指数分布问题:
有一种品牌的路由器,据厂家统计知该路由器平均寿命是50000小时,现在有2个问题:
(1)、去年我买了一个这样的路由器,使用到现在已经8000小时了一点问题都没有,那我这台路由器还能用40000小时以上的概率是多少?
(2)、 我现在推荐邻居也买了一个这样的路由器,邻居这台路由器可以用40000小时以上的概率是多少?
2、 指数分布
泊松分布描述的是事件发生次数,而指数分布描述的是事件发生的时间间隔。
指数分布主要用于描述电子元器件的寿命,其为连续型分布,概率密度函数为:
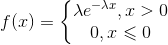
分布函数为:
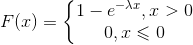
期望: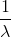 , 方差:
, 方差: 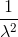
 表示事件发生的频率,在这里路由器平均寿命是50000小时,那么可以认为路由器平均50000小时坏一次,那么路由器坏的频率是=1/50000。
表示事件发生的频率,在这里路由器平均寿命是50000小时,那么可以认为路由器平均50000小时坏一次,那么路由器坏的频率是=1/50000。
此外,指数分布有一个十分重要的性质,无记忆性:
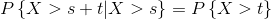
在上面问题中,路由器已使用时间与后续还能使用的时间无关,即我的路由器与邻居家的路由器后续使用寿命是没有差别的,即问题1和2的概率是一样的。
3.用python计算概率密度,可以直接使用公式计算,或者用scipy.stats.expon计算:
(1)
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
作用为:在指定的大间隔内,返回固定间隔的数据。他将返回“num”个等间距的样本,在区间[start,stop]中。其中,区间的结束端点可以被排除在外。start : scalar(标量)
队列的开始值stop : scalar
队列的结束值。当‘endpoint=False’时,不包含该点。在这种情况下,队列包含除了“num+1"以外的所有等间距的样本。
要注意的是,当‘endpoint=False’时,步长会发生改变。
(2) 很显然import matplotlib.pyplot as plt是用来可视化的
from scipy import stats
import math
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False#用来正常显示负号
r = 1/50000
X = []
Y = []
for x in np.linspace(0, 1000000, 100000):
if x==0:
continue
# p = r*math.e**(-r*x) #直接用公式算
p = stats.expon.pdf(x, scale=1/r) #用scipy.stats.expon工具算,注意这里scale参数是标准差
X.append(x)
Y.append(p)
plt.plot(X,Y)
plt.xlabel("间隔时间")
plt.ylabel("概率密度")
plt.show() 结果:
针对这个图该如何理解呢?连续型随机变量的概率密度在某个点的概率密度并不是在这一点发生的概率。这里引用一张图
这张图说明事件发生的时间间隔大于1的概率是0.37,那么时间间隔小于1的概率是0.63,这一点用下面的累积概率分布来看更直观。
原文链接:https://blog.csdn.net/lanhezhong/article/details/105844724
二我们的老大哥sklearn_crfsuite
(1)sklearn_crfsuite.CRF()常用参数
algorithm (str, optional (default='lbfgs')) :训练算法。
允许值:
'lbfgs' - Gradient descent using the L-BFGS method
使用L-BFGS方法的梯度下降
lbfgs - unlimited;——无限制的
'l2sgd' - Stochastic Gradient Descent with L2 regularization term
- 带L2正则项的随机梯度下降
- l2sgd - 1000;
'ap' - Averaged Perceptron
- 平均感知器
- ap - 100;
'pa' - Passive Aggressive (PA)
- 消极对抗(PA)
- pa - 100;
'arow' - Adaptive Regularization Of Weight Vector (AROW)
- 权向量自适应正则化
- arow - 100.
- min_freq (float, optional (default=0)) :特征出现频率的截止阈值。CRFsuite将忽略训练数据中出现频率不大于min\u freq的特征。默认值为no cut-off。同CRF++中的-f参数。
- all_possible_states (bool, optional (default=False)) :指定 CRFsuite 是否生成在训练数据中甚至不出现的状态特征(即,负状态特征)。当为 True 时,CRFsuite 生成状态特征,这些特征将属性和标签之间的所有可能组合相关联。假设属性和标签的数量分别为 A 和 L,该函数将生成 (A * L) 个特征。 启用此功能可能会提高标记准确性,因为 CRF 模型可以学习到一个item预测的label与参考label不一致的情况。 但是,此功能也可能会增加特征数量并大大减慢训练过程。 默认情况下禁用此功能。
- all_possible_transitions (bool, optional (default=False)) :指定CRFsuite是否生成训练数据中甚至没有出现的转移特征(即负转移特征)。如果为True,CRFsuite将生成关联所有可能标签对的转移特征,f(s', s, o=null),其中s为t时刻的的标签(y),o为t时刻的上下文(x)。假设训练数据中的标签个数为L,该函数将生成(L*L)个转移特征。默认情况下禁用此功能。
- c1 (float, optional (default=0)) :L1 正则化的系数。如果指定了非零值,CRFsuite 将切换到 Orthant-Wise Limited-memory Quasi-Newton (OWL-QN,Orthant-Wise 有限记忆拟牛顿) 方法。默认值为零(无 L1 正则化)。支持的训练算法:lbfgs。
- c2 (float, optional (default=1.0)):L2 正则化的系数。 支持的训练算法:l2sgd、lbfgs。
- max_iterations (int, optional (default=None)) :优化算法的最大迭代次数。默认值取决于训练算法:
- num_memories (int, optional (default=6)) :用于逼近逆 Hessian 矩阵的有限内存数量。 支持的训练算法:lbfgs。
- epsilon (float, optional (default=1e-5)):确定收敛条件的 epsilon 参数。 支持的训练算法:ap、arow、lbfgs、pa
- period (int, optional (default=10)) :测试停止标准的迭代持续时间。 支持的训练算法:l2sgd、lbfgs
- delta (float, optional (default=1e-5)) :停止标准的阈值;当最后一个周期迭代中对数似然的改进不大于此阈值时,迭代停止。 支持的训练算法:l2sgd、lbfgs
这个博主有很多干货,尊重原创,先赞后看。可以关注一波
原文链接:https://blog.csdn.net/qq_27586341/article/details/118519937
(2)sklearn.metrics.make_scorer
2.2.1,sklearn.metrics.make_scorer介绍
模型评估-sklearn中的评估函数
from sklearn_crfsuite import metrics
from sklearn.metrics import make_scorer从性能指标或损失函数中创建一个记分标准。
这个函数封装了用于GridSearchCV和cross_val_score的评分函数,它接受一个评分函数,如accuracy_score、mean_squared_error、adjusted_rand_index或average_precision,并返回一个可调用的值,该值对学习器的输出进行评分。
它的使用形式如下:
sklearn.metrics.make_scorer(score_func,
greater_is_better=True,
needs_proba=False,
needs_threshold=False,
**kwargs)
参数如下:
这个函数返回的是一个可调用的记分对象。
2.2.2实例
model = LGBMRegressor(max_depth=5,num_leaves=10,objective="regression")
score_ = cross_val_score(model,X = X_train,y=Y_train,verbose=0,scoring=make_scorer(mean_squared_error))
print(score_)
输出结果:[0.46157155 0.47102463 0.47506401 0.44817591 0.46550807]
(3)sklearn.metrics.f1_score 使用方法
在多类别和多标签的情况下,这是每个类别的F1分数的平均值,其权重取决于average 参数。
F1分数可以解释为精度和查全率的加权平均值,其中F1分数在1时达到最佳值,在0时达到最差值。精度和查全率对F1分数的相对贡献相等。F1分数的公式为:
F1 = 2 * (precision * recall) / (precision + recall)
sklearn.metrics.f1_score(y_true, y_pred, labels=None,
pos_label=1, average='binary', sample_weight=None,
zero_division='warn')
参数说明:
y_true:1d数组,或标签指示符数组/稀疏矩阵
基本事实(正确)目标值。
y_pred:1d数组,或标签指示符数组/稀疏矩阵
分类器返回的估计目标。
labels:list,optional
包括when的标签集,以及if的顺序。可以排除数据中存在的标
签,例如,以忽略多数否定类别的方式计算多类平均值,而数
据中不存在的标签将导致宏平均值中的0成分。对于多标签目
标,标签是列索引。默认情况下,和 中的所有标签均按排序顺
序使用。
average != 'binary'average is Noney_truey_pred
pos_label:str或int,默认值为1
要报告是否average='binary'以及数据是否为二进制的类。如果数据是
多类或多标签的,则将被忽略;设置,labels=[pos_label]并且只会报
告该标签的得分。average != 'binary'
average:string, [None, ‘binary’ (default), ‘micro’, ‘macro’, ‘samples’, ‘weighted’]
对于多类/多标签目标,此参数是必需的。如果为None,则返
回每个班级的分数。否则,这将确定对数据执行的平均类型:
'binary':仅报告由指定的类的结果pos_label。
仅在目标(y_{true,pred})为二进制时适用。
'micro':通过计算正确,错误和否定的总数来全局计算指标。
'macro':计算每个标签的指标,并找到其未加权平均值。
这没有考虑标签不平衡。
'weighted':计算每个标签的指标,并找到其平均权重(受支持)
(每个标签的真实实例数)。
这改变了“宏观”以解决标签的不平衡。
这可能导致F得分不在精确度和召回率之间。
'samples':计算每个实例的指标,并找到其平均值
(仅对不同于的多标签分类有意义 accuracy_score)。
sample_weight:array-like of shape (n_samples,), default=None
样品重量。
zero_division:“warn”, 0 or 1, default=”warn”
设置除法为零(即所有预测和标签均为负)时
返回的值。如果设置为“ warn”,则该值为0,
但也会发出警告。
三,cross_val_score——K折验证交叉验证
(1)K折验证交叉验证介绍
想用交叉验证,只需将 cross_validation 改为 model_selection 即可

总的来说,交叉验证既可以解决数据集的数据量不够大问题,也可以解决参数调优的问题。这块主要有三种方式:简单交叉验证(HoldOut检验)、k折交叉验证(k-fold交叉验证)、自助法.
sklearn.model_selection.cross_val_score(estimator,
X,
y=None,
groups=None,
scoring=None,
cv=’warn’,
n_jobs=None,
verbose=0,
fit_params=None,
pre_dispatch=‘2*n_jobs’,
error_score=’raise-deprecating’)
- estimator: 需要使用交叉验证的算法
- X: 输入样本数据
- y: 样本标签
- groups: 将数据集分割为训练/测试集时使用的样本的组标签(一般用不到)
- scoring: 交叉验证最重要的就是他的验证方式,选择不同的评价方法,会产生不同的评价结果。具体可用哪些评价指标,官方已给出详细解释,链接:https://scikitlearn.org/stable/modules/model_evaluation.html#scoring-parametercv: 交叉验证折数或可迭代的次数
- n_jobs: 同时工作的cpu个数(-1代表全部)
- verbose: 详细程度
- fit_params: 传递给估计器(验证算法)的拟合方法的参数
- pre_dispatch: 控制并行执行期间调度的作业数量。减少这个数量对于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。该参数可以是:
没有,在这种情况下,所有的工作立即创建并产生。将其用于轻量级和快速运行的作业,以避免由于按需产生作业而导致延迟
一个int,给出所产生的总工作的确切数量
一个字符串,给出一个表达式作为n_jobs的函数,如’2 * n_jobs
- error_score: 如果在估计器拟合中发生错误,要分配给该分数的值(一般不需要指定)
(2)分析
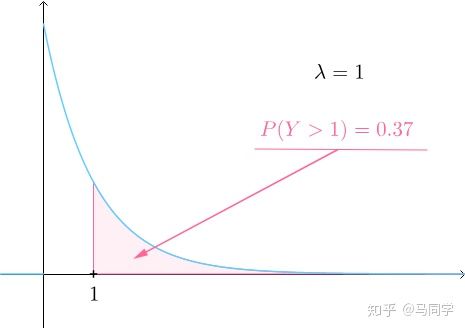
举个例子:这里取k=10,如下图所示:
(1)先将原数据集分成10份
(2)每一将其中的一份作为测试集,剩下的9个(k-1)个作为训练集
此时训练集就变成了k * D(D表示每一份中包含的数据样本数)
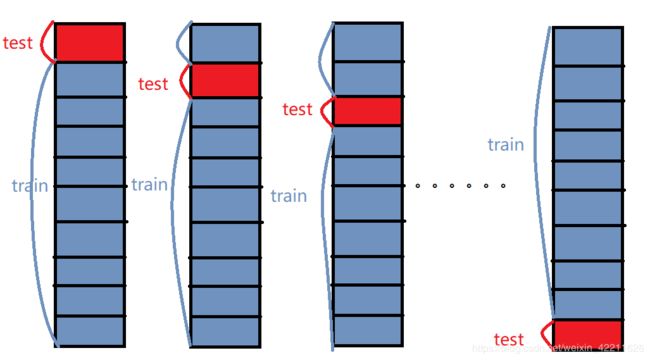
(3)最后计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率
(3)示例
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsRegressor
import matplotlib.pylab as plt
train_data = pd.read_csv("E:/competitions/kaggle/House Price/train.csv")
X = pd.DataFrame(train_data["GrLivArea"].fillna(0))
y = train_data["SalePrice"]
score = []
alphas = []
for alpha in range(1,100,1):
alphas.append(alpha)
rdg = KNeighborsRegressor(alpha)
sc = np.sqrt( -cross_val_score(rdg,X,y,scoring = "neg_mean_squared_error", cv = 10))
score.append(sc.mean())
plt.plot(alphas,score)
plt.show()
这里使用了neg_mean_squared_error作为评分,画出损失——alpha的关系图如下:
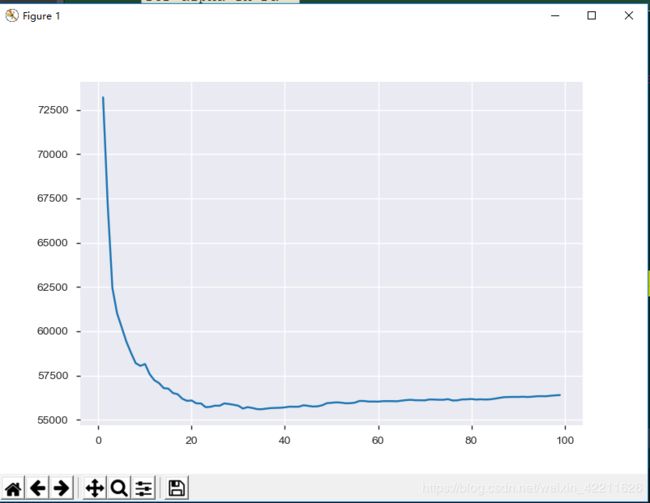
由上图可以看到,在alpha = 23的时候,其损失是最小的。这样便完成了选择参数的任务。
原文链接:https://blog.csdn.net/weixin_42211626/article/details/100064842
四,sklearn.grid_search——模型调参利器 gridSearchCV(网格搜索)
(1)GridSearchCV简介
网格搜索(GridSearch)用于选取模型的最优超参数。获取最优超参数的方式可以绘制验证曲线,但是验证曲线只能每次获取一个最优超参数。如果多个超参数有很多排列组合的话,就可以使用网格搜索寻求最优超参数的组合。
网格搜索针对超参数组合列表中的每一个组合,实例化给定的模型,做cv次交叉验证,将平均得分最高的超参数组合作为最佳的选择,返回模型对象。
(2)sklearn.model_selection.GridSearchCV参数详解
sklearn.model_selection.GridSearchCV(
estimator,
param_grid,
scoring=None,
n_jobs=None,
iid=’warn’,
refit=True,
cv=’warn’,
verbose=0,
pre_dispatch=‘2*n_jobs’,
error_score=’raise-deprecating’,
return_train_score=False)
(1) estimator
选择使用的分类器,并且传入除需要确定最佳的参数之外的其他参数。
(2) param_grid
需要最优化的参数的取值,值为字典或者列表。
(3) scoring=None
模型评价标准,默认None。
根据所选模型不同,评价准则不同。比如scoring=”accuracy”。
如果是None,则使用estimator的误差估计函数。
(4) n_jobs=1 进程个数,默认为1。 若值为 -1,则用所有的CPU进行运算。 若值为1,则不进行并行运算,这样的话方便调试。
(5) iid=True
默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
(6) refit=True
默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
(7) cv=None
交叉验证参数,默认None,使用三折交叉验证。
(8) verbose=0,
verbose:日志冗长度
0:不输出训练过程,
1:偶尔输出,>1:对每个子模型都输出。
(9) pre_dispatch=‘2*n_jobs’
指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
(3)以鸢尾花数据集为例,基于网格搜索得到最优模型
import numpy as np
import sklearn.model_selection as ms
import sklearn.svm as svm #导入svm函数
from sklearn.datasets import load_iris #导入鸢尾花数据
iris = load_iris()
x = iris.data
y = iris.target
# 可以看到样本大概分为三类
print(x[:5])
print(y)
输出:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
(4) 扩展:基于svm,实现分类
# 基于svm 实现分类
model = svm.SVC(probability=True)
# 基于网格搜索获取最优模型
params = [
{'kernel':['linear'],'C':[1,10,100,1000]},
{'kernel':['poly'],'C':[1,10],'degree':[2,3]},
{'kernel':['rbf'],'C':[1,10,100,1000],
'gamma':[1,0.1, 0.01, 0.001]}]
model = ms.GridSearchCV(estimator=model, param_grid=params, cv=5)
model.fit(x, y)
# 网格搜索训练后的副产品
print("模型的最优参数:",model.best_params_)
print("最优模型分数:",model.best_score_)
print("最优模型对象:",model.best_estimator_)
模型的最优参数: {'C': 1, 'kernel': 'linear'}
最优模型分数: 0.98
最优模型对象: SVC(C=1, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='linear', max_iter=-1, probability=True, random_state=None,
shrinking=True, tol=0.001, verbose=False)
# 输出网格搜索每组超参数的cv数据
for p, s in zip(model.cv_results_['params'],
model.cv_results_['mean_test_score']):
print(p, s)
输出:
{'C': 1, 'kernel': 'linear'} 0.98
{'C': 10, 'kernel': 'linear'} 0.9733333333333334
{'C': 100, 'kernel': 'linear'} 0.9666666666666667
{'C': 1000, 'kernel': 'linear'} 0.9666666666666667
{'C': 1, 'degree': 2, 'kernel': 'poly'} 0.9733333333333334
{'C': 1, 'degree': 3, 'kernel': 'poly'} 0.9666666666666667
{'C': 10, 'degree': 2, 'kernel': 'poly'} 0.9666666666666667
{'C': 10, 'degree': 3, 'kernel': 'poly'} 0.9666666666666667
{'C': 1, 'gamma': 1, 'kernel': 'rbf'} 0.9666666666666667
{'C': 1, 'gamma': 0.1, 'kernel': 'rbf'} 0.98
{'C': 1, 'gamma': 0.01, 'kernel': 'rbf'} 0.9333333333333333
{'C': 1, 'gamma': 0.001, 'kernel': 'rbf'} 0.9133333333333333
{'C': 10, 'gamma': 1, 'kernel': 'rbf'} 0.9533333333333334
{'C': 10, 'gamma': 0.1, 'kernel': 'rbf'} 0.98
{'C': 10, 'gamma': 0.01, 'kernel': 'rbf'} 0.98
{'C': 10, 'gamma': 0.001, 'kernel': 'rbf'} 0.9333333333333333
{'C': 100, 'gamma': 1, 'kernel': 'rbf'} 0.94
{'C': 100, 'gamma': 0.1, 'kernel': 'rbf'} 0.9666666666666667
{'C': 100, 'gamma': 0.01, 'kernel': 'rbf'} 0.98
{'C': 100, 'gamma': 0.001, 'kernel': 'rbf'} 0.98
{'C': 1000, 'gamma': 1, 'kernel': 'rbf'} 0.9333333333333333
{'C': 1000, 'gamma': 0.1, 'kernel': 'rbf'} 0.9533333333333334
{'C': 1000, 'gamma': 0.01, 'kernel': 'rbf'} 0.9666666666666667
{'C': 1000, 'gamma': 0.001, 'kernel': 'rbf'} 0.98
(5)网格搜索实例
import pandas as pd # 数据科学计算工具
import numpy as np # 数值计算工具
import matplotlib.pyplot as plt # 可视化
import seaborn as sns # matplotlib的高级API
from sklearn.model_selection import StratifiedKFold #交叉验证
from sklearn.model_selection import GridSearchCV #网格搜索
from sklearn.model_selection import train_test_split #将数据集分开成训练集和测试集
from xgboost import XGBClassifier #xgboost
pima = pd.read_csv("pima_indians-diabetes.csv")
print(pima.head())
x = pima.iloc[:,0:8]
y = pima.iloc[:,8]
seed = 7 #重现随机生成的训练
test_size = 0.33 #33%测试,67%训练
X_train, X_test, Y_train, Y_test = train_test_split(x, y, test_size=test_size, random_state=seed
model = XGBClassifier()
learning_rate = [0.0001,0.001,0.01,0.1,0.2,0.3] #学习率
gamma = [1, 0.1, 0.01, 0.001]
param_grid = dict(learning_rate = learning_rate,gamma = gamma)#转化为字典格式,网络搜索要求
kflod = StratifiedKFold(n_splits=10, shuffle = True,random_state=7)#将训练/测试数据集划分10个互斥子集,
grid_search = GridSearchCV(model,param_grid,scoring = 'neg_log_loss',n_jobs = -1,cv = kflod)
#scoring指定损失函数类型,n_jobs指定全部cpu跑,cv指定交叉验证
grid_result = grid_search.fit(X_train, Y_train) #运行网格搜索
print("Best: %f using %s" % (grid_result.best_score_,grid_search.best_params_))
#grid_scores_:给出不同参数情况下的评价结果。best_params_:描述了已取得最佳结果的参数的组合
#best_score_:成员提供优化过程期间观察到的最好的评分
#具有键作为列标题和值作为列的dict,可以导入到DataFrame中。
#注意,“params”键用于存储所有参数候选项的参数设置列表。
means = grid_result.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean,param in zip(means,params):
print("%f with: %r" % (mean,param))
结果如下:

