学习笔记——基于条件随机场的医疗电子病例的命名实体识别
from sklearn import preprocessing
feature = [[0,1], [1,1], [0,0], [1,0]]
label= ['yes', 'no', 'yes', 'no']
lb = preprocessing.LabelBinarizer() #构建一个转换对象
Y = lb.fit_transform(label)
re_label = lb.inverse_transform(Y)
print(Y)
print(re_label)
(一)代码使用方法及介绍
基于条件随机场的医疗电子病例的命名实体识别
medical_ner_crfsuite是[CCKS2017全国知识图谱与语义大会](http://www.ccks2017.com/),医疗电子病例命名实体识别评测任务的一个可执行demo,采用的方法是条件随机场(CRF),实现CRF的第三方库为[python-crfsuite](https://github.com/scrapinghub/python-crfsuite)。目前该demo准确率为68%,召回率为62%,F1值为64.8%。
(二)MOODLE
1. 数据预处理。调用reader.py中的text2nerformat方法,将data中的数据集转换成NER任务中常用的数据格式
import jieba.posseg
import re
import codecs
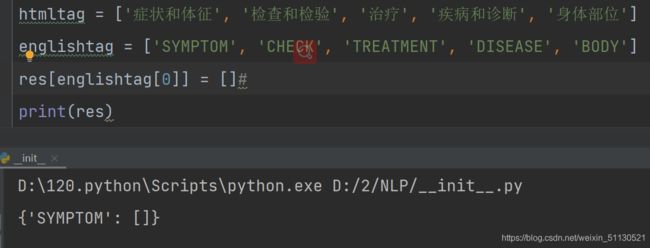
htmltag = ['症状和体征', '检查和检验', '治疗', '疾病和诊断', '身体部位']
englishtag = ['SYMPTOM', 'CHECK', 'TREATMENT', 'DISEASE', 'BODY']
def readFileUTF8(filename):
fr = codecs.open(filename, 'r', 'utf-8')
text = ''
for line in fr:
text += line.strip()
return text
def extract_tag_information(text):
res = {}
for i, html in enumerate(htmltag):
res[englishtag[i]] = []
pattern = re.compile(r'<' + html + '>(.*?)', re.S)
contents = pattern.findall(text)
for content in contents:
content = re.compile('<[^>]+>', re.S).sub('', content)
res[englishtag[i]].append(content)
return res
def extract_all_information(text):
pattern = re.compile('<(.*?)>(.*?)', re.S)
contents = pattern.findall(text)
ans = ''
for content in contents:
content = re.compile('<[^>]+>', re.S).sub('', content[1])
ans += content
print (content)
return ans
def getType(type):
if type == '症状和体征':
return 'SIGNS'
elif type == '检查和检验':
return 'CHECK'
elif type == '疾病和诊断':
return 'DISEASE'
elif type == '治疗':
return 'TREATMENT'
elif type == '身体部位':
return 'BODY'
else:
return 'OTHER'
def split(text):
"""以标签数据分割成list"""
res = []
start = 0
end = 0
while end < len(text):
if text[end] == '<':
# < 前面的信息写入
if start != end:
res.append(text[start: end])
start = end + 1
else:
start += 1
# <>中的信息
end = go(text, start)
res.append(text[start: end])
start = end + 1
end = start
else:
end += 1
if start != end:
res.append(text[start: end])
return res
# 将标签数据集转换成ner格式的标准数据集
def text2nerformat(text):
# 过滤掉所有的标签
# content = re.compile('<[^>]+>', re.S).sub('', text)
segment = jieba.posseg.cut(text)
# 采用BIOSE方式
# B: 开始,I:中间,O:无关词,S:单个词,E:结尾
# 将训练数据转换为标准的ner格式的数据
start = 0
type = ''
stack = []
flag = 0
features = []
pieces = split(text)
pre = 0
for seg in segment:
if seg.word == '<':
flag = 1
pre = 0
continue
elif seg.word == '>':
flag = 0
pre = 0
continue
if flag == 0:
while start < len(pieces) and getType(pieces[start]) != 'OTHER':
stack.append(getType(pieces[start]))
start += 1
while start < len(pieces) and getType(pieces[start][1:]) != 'OTHER':
stack.pop()
start += 1
while start < len(pieces) and getType(pieces[start]) != 'OTHER':
stack.append(getType(pieces[start]))
start += 1
index = pieces[start].find(seg.word, pre)
pre = index + 1
if len(stack) == 0:
type = 'O'
if start < len(pieces) and index + len(seg.word) == len(pieces[start]):
start += 1
else:
if start < len(pieces):
if index == 0 and len(seg.word) == len(pieces[start]):
type = 'S-' + stack[-1]
start += 1
elif index == 0 and len(seg.word) != len(pieces[start]):
type = 'B-' + stack[-1]
elif index != -1 and len(pieces[start]) - index == len(seg.word):
if start + 1 == len(pieces) or getType(pieces[start + 1]) == 'OTHER':
type = 'E-' + stack[-1]
else:
type = 'I-' + stack[-1]
start += 1
elif index != -1:
type = 'I-' + stack[-1]
features.append([seg.word, seg.flag, type])
# print '%s, %s, %s' % (seg.word, seg.flag, type)
return features
def go(text, i):
while i < len(text):
if text[i] == '>':
break
else:
i += 1
return i
# 将标注过的ner数据集,提取出实体
def getNamedEntity(word, ner):
ans = []
cur = ''
for i, tag in enumerate(ner):
if 'B' == tag.split('-')[0]:
cur += word[i]
elif 'I' == tag.split('-')[0]:
cur += word[i]
elif 'E' == tag.split('-')[0]:
cur += word[i]
ans.append(cur)
cur = ''
elif 'S' == tag.split('-')[0]:
if len(cur) == 0:
ans.append(word[i])
else:
cur += word[i]
return ans
if __name__ == '__main__':
# fw = file('test1.txt', 'w')
# for i in range(100, 101):
# filename = 'data/病史特点-' + str(i) + '.txt'
# answer = text2nerformat(readFileUTF8(filename))
# for [word, pos, ner] in answer:
# fw.write(word + '\t' + pos + '\t' + ner + '\n')
# print 'file ' + str(i) + ' has already finished!'
# fw.flush()
# fw.close()
fr = codecs.open('test1.txt', 'r', 'utf-8')
data = []
for line in fr:
fields = line.strip().split('\t')
if len(fields) == 3:
data.append(fields)
word = [w for w, tag, label in data]
ner = [label for w, tag, label in data]
ans = getNamedEntity(word, ner)
for a in ans:
print (a)
(1)python模块之codecs: 自然语言编码转换:
如果我们处理的文件里的字符编码是其他类型的呢?这个读取进行做处理也需要特 殊的处理的。codecs也提供了方法.
参考文章: python模块之codecs: 自然语言编码转换_Mingz技术博客-CSDN博客
在使用NLPIR分词的时候,对输入文档的编码格式是有严格要求的,在函数初始化的时候可以设置输入源文档的编码格式。
但是源文档的编码可能一会儿是utf-8一会儿是gbk,这就要求统一一下格式,不能格式一乱就报错了,
参考文章: https://blog.csdn.net/chixujohnny/article/details/51782826

(2)open
关于open相关内容请参考博主这篇文章
参考链接:https://blog.csdn.net/weixin_51130521/article/details/119614510
(3)line.strip()
line.strip()会把'\\n'(空行)替换为''
参考链接:https://blog.csdn.net/u010565244/article/details/19193635
(4)enumerate
enumerate()使用
如果对一个列表,既要遍历索引又要遍历元素时,首先可以这样写:
上述方法有些累赘,利用enumerate()会更加直接和优美:
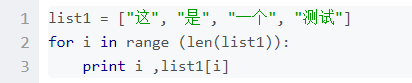
list1 = ["这", "是", "一个", "测试"] for index, item in enumerate(list1): print index, item >>> 0 这 1 是 2 一个 3 测试- enumerate还可以接收第二个参数,用于指定索引起始值,如:
list1 = ["这", "是", "一个", "测试"] for index, item in enumerate(list1, 1): print index, item >>> 1 这 2 是 3 一个 4 测试参考链接:https://blog.csdn.net/churximi/article/details/51648388
(5)res[englishtag[i]] = []
(6)re.compile
正则表达式re.compile()
compile()与findall()一起使用,返回一个列表。
eg:
import re def main(): content = 'Hello, I am Jerry, from Chongqing, a montain city, nice to meet you……' regex = re.compile('\w*o\w*') x = regex.findall(content) print(x) if __name__ == '__main__': main() # ['Hello', 'from', 'Chongqing', 'montain', 'to', 'you']参考链接:https://blog.csdn.net/Darkman_EX/article/details/80973656
Python中正则表达式re.S的作用
import re a = """sdfkhellolsdlfsdfiooefo: 877898989worldafdsf""" b = re.findall('hello(.*?)world',a) c = re.findall('hello(.*?)world',a,re.S) print ('b is ' , b) print ('c is ' , c) # 输出结果: # b is [] # c is ['lsdlfsdfiooefo:\n877898989']注意:只有三单引或者三双引号的情况下,可以直接回车(\n)换行写。其他双引号,单引号写法不同。这里不做其他解释。
在字符串a中,包含换行符\n,在这种情况下:
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配
原文链接:https://blog.csdn.net/weixin_42781180/article/details/81302806re.compile与sub
import re eliminate = re.compile('[!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~\s]+') text = eliminate.sub("@", "你!好!") text # 输出:'你@好@' text = eliminate.sub("", "你!好!") text # 输出:'你好'如图所示:compile与sub组合替换掉已经匹配的字符串
2,训练模型。通过crf_unit.py,训练CRF模型,目前CRF中的特征包括上下两个词语及其词性,分词和词性标注调用[jieba](https://github.com/fxsjy/jieba)
import codecs
import pycrfsuite
import string
import zhon.hanzi as zh
from sklearn.model_selection import ShuffleSplit, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
import reader
from sklearn.metrics import classification_report
from sklearn.preprocessing import LabelBinarizer
# 获取数据
def readData(filename):
fr = codecs.open(filename, 'r', 'utf-8')
data = []
for line in fr:
fields = line.strip().split('\t')
if len(fields) == 3:
data.append(fields)
return data
train = readData('train.txt')
test = readData('test.txt')
# 判断是否为标点符号
# punctuation
def ispunctuation(word):
punctuation = string.punctuation + zh.punctuation
if punctuation.find(word) != -1:
return True
else:
return False
# 特征定义
def word2features(sent, i):
"""返回特征列表"""
word = sent[i][0]
postag = sent[i][1]
features = [
'bias',
'word=' + word,
'word_tag=' + postag,
]
if i > 0:
features.append('word[-1]=' + sent[i-1][0])
features.append('word[-1]_tag=' + sent[i-1][1])
if i > 1:
features.append('word[-2]=' + sent[i-2][0])
features.append('word[-2, -1]=' + sent[i-2][0] + sent[i-1][0])
features.append('word[-2]_tag=' + sent[i-2][1])
if i < len(sent) - 1:
features.append('word[1]=' + sent[i+1][0])
features.append('word[1]_tag=' + sent[i+1][1])
if i < len(sent) - 2:
features.append('word[2]=' + sent[i+2][0])
features.append('word[1, 2]=' + sent[i+1][0] + sent[i+2][0])
features.append('word[2]_tag=' + sent[i+2][1])
return features
def sent2feature(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2label(sent):
return [label for word, tag, label in sent]
def sent2word(sent):
return [word for word, tag, label in sent]
X_train = sent2feature(train)
y_train = sent2label(train)
X_test = sent2feature(test)
y_test = sent2label(test)
# 训练模型
model = pycrfsuite.Trainer(verbose=True)
model.append(X_train, y_train)
model.set_params({
'c1': 1.0, # coefficient for L1 penalty
'c2': 1e-3, # coefficient for L2 penalty
'max_iterations': 100, # stop earlier
# include transitions that are possible, but not observed
'feature.possible_transitions': True,
'feature.minfreq': 3
})
model.train('./medical.crfsuite')
# 预测数据
tagger = pycrfsuite.Tagger()
tagger.open('./medical.crfsuite')
# 一份测试数据集
print (' '.join(sent2word(readData('test1.txt'))))
predicted = tagger.tag(sent2feature(readData('test1.txt')))
correct = sent2label(readData('test1.txt'))
# 预测结果对比
print ('Predicted: ', ' '.join(predicted))
print ('Correct: ', ' '.join(correct))
# 预测准确率
num = 0
for i, tag in enumerate(predicted):
if tag == correct[i]:
num += 1
print( 'accuracy: ', num * 1.0 / len(predicted))
# 实体抽取结果
ans = reader.getNamedEntity(sent2word(readData('test1.txt')), predicted)
for a in ans:
print (a)
(1)import zhon.hanzi as zh
见博主这篇文章:https://blog.csdn.net/weixin_51130521/article/details/119729670
(2)re.sub
该函数主要用于替换字符串中的匹配项。
本文链接:https://blog.csdn.net/jackandsnow/article/details/103885422
(3)Python中的 .join()用法
Python中的 .join() 函数经常被大家使用到,之前面试的时候也被问到过,在这里记录一下:
这个函数展开来写应该是str.join(item),join函数是一个字符串操作函数
str表示字符串(字符),item表示一个成员,注意括号里必须只能有一个成员,比如','.join('a','b')这种写法是行不通的
举个例子:
','.join('abc')上面代码的含义是“将字符串abc中的每个成员以字符','分隔开再拼接成一个字符串”,输出结果为:
'a,b,c'join里放列表、元组、字典也是可以的
';'.join([a,b,c]) >> 'a;b;c'
(4) sklearn.preprocessing.LabelBinarizer()的用法
对于标称型数据来说,preprocessing.LabelBinarizer是一个很好用的工具。比如可以把yes和no转化为0和1,或是把incident和normal转化为0和1。当然,对于两类以上的标签也是适用的。这里举一个简单的例子,说明将标签二值化以及其逆过程。
from sklearn import preprocessing feature = [[0,1], [1,1], [0,0], [1,0]] label= ['yes', 'no', 'yes', 'no'] lb = preprocessing.LabelBinarizer() #构建一个转换对象 Y = lb.fit_transform(label) re_label = lb.inverse_transform(Y) print(Y) print(re_label)结果
[[1] [0] [1] [0]] ['yes' 'no' 'yes' 'no']
3,评估模型。调用crf_unit.py中的bio_classification_report方法,评估模型。
'''''
# 评估模型
用这个会报错 Recall and F-score are ill-defined and being set to 0.0 in samples with
no true labels. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
def bio_classification_report(y_true, y_pred):
"""
Classification report for a l ist of BIOSE-encoded sequences.
It computes token-level metrics and discards 'O' labels.
:param y_true:
:param y_pred:
:return:
"""
lb = LabelBinarizer()
y_true_combined = lb.fit_transform(y_true)
y_pred_combined = lb.transform(y_pred)
tagset = set(lb.classes_) - {'O'}
tagset = sorted(tagset, key=lambda tag: tag.split('-', 1)[::-1])
class_indices = {
cls: idx for idx, cls in enumerate(lb.classes_)
}
return classification_report(
y_true_combined,
y_pred_combined,
labels=[class_indices[cls] for cls in tagset],
target_names=tagset
)
y_pred = list(tagger.tag(X_test))
print (bio_classification_report(y_test, y_pred))
'''''
def knn(self,X_train,X_test,Y_train,Y_test):
#implementación del algoritmo
knn = KNeighborsClassifier(n_neighbors=3).fit(X_train,Y_train)
#10XV
cv = ShuffleSplit(n_splits=10, test_size=0.3, random_state=0)
puntajes = sum(cross_val_score(knn, X_test, Y_test,
cv=cv,scoring='f1_weighted'))/10
print(puntajes)
参考链接
immense8342/medical_ner_crfsuite: 基于条件随机场的医疗电子病例的命名实体识别 (github.com)