相信在座的大家应该都听说过云原生了,这是近三四年一直热门的一个东西。什么是云原生呢?现在的云原生是个很宽泛的定义,可以简单理解为你的服务是为云而生,或者说因为现在云原生都是以 Kubernetes 容器技术作为基础设施,那只要你的服务运行在 Kubernetes 上,它们就可以算云原生。
而今天我跟大家分享的主题是 Luffy3 利用云原生技术,实现的灰度更新,主要从以下 4 个方面进行介绍:
- 什么是灰度更新
- 灰度更新的现状
- 云原⽣实践
- 总结与展望
什么是灰度更新
为了让大家更好的理解,我通过一个简单的例子和大家说一下什么是灰度更新。

假设你有⼀个关于酒店预定的项⽬,需要对外提供⼀个 Web 网站,供用户预定房间。为了保证业务的⾼可⽤,该项⽬研发的服务端是⽀持分布式的。因此,你在⽣产环境,组了⼀个酒店预定 Web 集群,⼀共起了 3 个服务端,通过 Nginx 反向代理的方式对外提供服务。
左图是传统意义上的灰度更新,即先将部分流量导到新版本上进行测试,如果可以就全面推广,如果不行就退回上一个版本。具体举例来说的话,有三台机器分别部署了服务端,IP 地址分别为 0.2、0.3、0.4。日常更新的话,选择先在 0.4 服务端更新并看一下是否有问题出现,在确定没有问题后才进行 0.3 和 0.2 的更新。
右图则是使用容器技术,它会比物理机部署的方式更加灵活。它用到的概念是 instance,也就是实例,同一台机器上可以起多个实例。访问流量会如图从左往右的方向,先经过网关,通过在网关上添加一些策略,让 95% 的流量走上面的原服务,5% 的流量走下面的灰度服务。通过观察灰度服务是否有异常,如果没有异常,则可以把原服务的容器镜像版本更新到最新,并删掉下面的灰度服务。这和左图是不一样的,它不是滚动式一台接一台的更新,而是借助一个弹性资源平台直接把原服务全部更新掉。
灰度更新现状
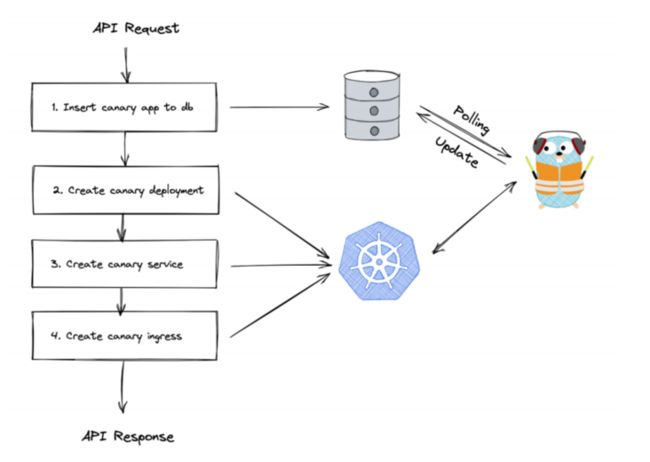
上图是灰度更新在 Luffy2 上面的现状,主要问题出现在 API 处理这一块,因为之前的状态是靠数据库来维护的,容易出现状态不统一的问题。
左图是一个简略的处理流程。当一个 API 请求服务过来要求进行服务灰度更新时,第一步会先生成一个带灰度名称的 App。
第二步这里给大家细说,首先要将生成的 App 放入数据库,同时在 Kubernetes 创建无状态服务,这通常需要 10 分钟左右的时间。这期间会通过一个 Go 语言程序对 App 表进行不间断扫描以确认服务是否完成创建。同时还需要使用 Kubernetes 创建转发规则等,等待所有需求都创建完成后就返回原版 ok 给调用方。
这里涉及到性能问题,因为数据库内有很多条要处理的东西,这些要等待挨个处理,而这其中有很多都是无用数据,在扫到 App 前的这 10 分钟里,就算去 Kubernetes 那边调用,也是在做无用操作。
另外还有一个调用链很长的问题,在 Kubernetes 里创建的很多东西都会包含在同一次 API 请求里,这就导致随时可能出现在一步完成后,下一步崩溃的情况。这种时候可能要考虑是否回滚的问题,而如果回滚就要删掉相关服务和数据库。这种情况在调用外部组件越多时,越容易出现。比较直观的解决方法是简化 API 流程,针对这个方法 Kubernetes 提供了 CRD。
云原生实践
CRD

上图是从 Kubernetes 官网上摘抄下来的关于 CRD 的说明。这个大家应该都比较熟悉了。Kubernetes 里最重要的概念就是资源,它里面所有的东西都是一个资源或者对象。右图是相关的无状态服务的例子,里面包含了服务的版本、类型、标签以及镜像版本和容器对外提供的端口。在 Kubernetes 里创建无状态服务,你只需要完成定义即可,而 CRD 则可以帮助我们自定义 spec 内的内容。
需要注意的是,定制资源本身只能⽤来存取结构化的数据。只有与定制控制器(Custom Controller)相结合时,才能提供真正的声明式 API (Declarative API)。通过使用声明式 API, 你可以声明或者设定资源的期望状态,并让 Kubernetes 对象的当前状态同步到其期望状态。也就是控制器负责将结构化的数据解释为⽤户所期望状态的记录,并持续地维护该状态。
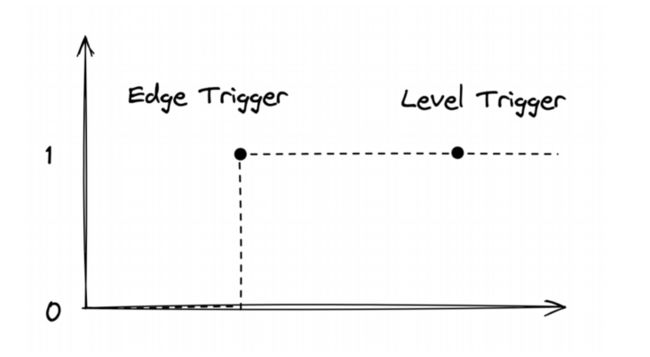
上图是关于声明式 API 的相关实践,采用水平触发的方式。简单举例,电视使用的遥控器是边缘触发,只要你按了更改频道就会立即触发更改。而闹钟则是水平触发,无论在闹钟响动之前更改了多少次,它只会在你最后定好的时间点触发。总结来说就是边缘触发更注重时效性,在更改时会立即反馈。而水平触发则只关注最终的一致性,无论前面如何,只保证最后状态和我们设置的一样就好。
Luffy3.0 CRD

上图是又拍云使用 luffy3.0 做的整体结构,它是架在 Kubernetes 上的,其中和 Kubernetes 的服务相关交互都由 apiserver 完成。
图中右下角的是关系式数据库,关系相关比如用户关系、从属关系,都在这里面。它上面带一层 redis 缓存,来提高热点数据查询效率。左图是我们实现的几个自己的 CRD。第二个 projects 就是相关项目。当年在创立项目时,就是背靠 CRD 的。首先在数据库里写了,然后在 Kubernetes 创建了 projects 这个 CRD 对象。
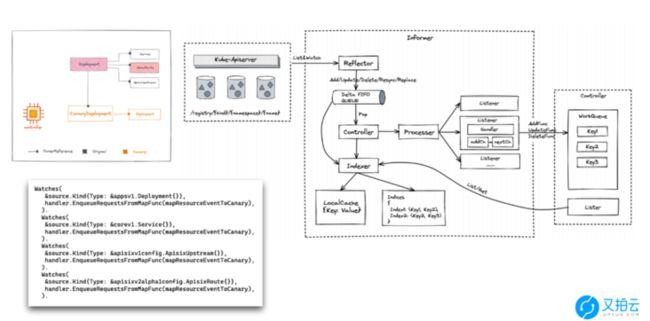
Kubernetes client-go informer 机制

接下来和,大家谈一下 informer 的实现逻辑,informer 是 Kubernetes 官方提供的,方便大家和 Apiserver 做交互的一套 SDK,它比较依赖水平触发的机制。
上图左边是我们的 apiserver,所有的数据都存在 Key-value 的数据库 ETCD 里。在存储时它使用以下结构:
/registry/{kind}/{namespace}/{name}这之中前缀 registry 是可以修改的,用于防止冲突,kind 是类型,namespace 为命名空间或者说项目名,对应 Luffy3。再后面的 name 是服务名称。在通过 apiserver 对这个对象进行了创建、更新、删除等操作时,ETCD 都会将这个事件反馈给 apiserver。然后 apiserver 会将更改对象开放给 informer。而 informer 是基于单个类型 {kind} 的,这也就说如果你有多个类型,那么你必须对应每一个类型起一个对应的 informer,当然这个可以通过代码来生成。
回到 informer 实现逻辑,当 informer 运行起来后,它会先去 Kubernetes 中获取全量数据,比如当前 informer 对应的类型是无状态服务,那它会获取全部的无状态服务。然后持续 watch apiserver,一旦 apiserver 有新的无状态服务,它都会收到对应事件。收到新事件后,informer 会将时间放入先进先出的队列,让 controller 进行消费。而 controller 会将事件交递给模块 Processer 进行特殊处理。在模块 Processer 上有很多监听器,这些监听器是对特定类型设置的回调函数。
然后来看一下为什么 controller 中的 lister 和 indexer 关联。因为 namespace 和目录很像,在这个目录下会有很多的无状态服务,如果想根据某一规则进行处理,在原生服务上处理肯定是最差的选择,而这就是 lister 所要做的。它会将这部分进行缓存,并做一个索引,也就是 inderxer,这个索引和数据库很像,是由一些 key 组成的。
而对于 CRD 来说,要实现的就是 contorller,以及 informer 和 controller 交互的部分。其他的部分由代码自己生成。

如果代码没有生成,那就会用到上图了。前三条是写代码相关,其中 API type 需要我们填写 CRD 的定义、灰度更新定义等,完成定义后要将定义注册到 Kubernetes 上,不然就不会起效。接着,代码会生成下方的 4 项,包括 deepcopy 深度拷贝函数,使用 CRD 的 client,informer 和 lister。
第三块是自定义控制器相关的 controller,包括和 Apiserver 打交道的 Kubernetes rest client,时间控制器或时间函数 eventhandler 和 handlerfuncs 等。这其中需要写的是调和函数 reconciliation,因为其他官方都已经为我们封装好了,只需要定义好调和函数就可以。
全部封装完成后需要把这些东西串起来,当前主流的选择有两个,OperatorSDK 和 Kubebuilder。
OperatorSDK vs Kubebuilder

接下来来看一下代码是如何生成的

以 OperatorSDK 为例看一下是如何生成代码的。当然大家也可以选择使用 Kubebuilder,这两者的生成方式差别不大。在上图的“初始化项目”里可以看到仓库的名称,它定义了一个版本的版本号,以及类型 canaryDeployment,即灰度的无服务状态。之后生成对应的资源和控制器。完成后写刚刚讲到的调和函数和 API 定义。全部完成后就可以执行了,非常简单。
灰度更新的设计
在聊了上面的这些知识后,来看一下灰度更新。上图是灰度更新的简易示例图,流程是从左开始到右边结束。
第一步是创建灰度服务,创建后可以更新灰度。比如刚才的 Nginx 的例子,我们创建的版本号是 1.19。但是在灰度过程中发现当前版本有 bug,而在对这个 bug 进行修复后,确认无误就可以将原服务更新到版本号 1.20,然后删除灰度服务。如果发现 1.20 版本依然有 bug,也可以选择删除灰度服务,让你原服务接管所有流量。这就是 CRD 对开发步骤的简化。
灰度更新一共有以下 4 个阶段:
- 创建
- 更新
- 替换
- 删除
创建
因为 Kubernetes 是水平触发的,所有它创建和更新的处理逻辑是相同的,只看最终状态即可。

这张图比较重要,大家可以仔细看一下。图中右上部分是原服务,原服务包含 Kubernetes 无状态服务、Service 内部域名、ApisixRoute、Apisix 路由规则、ApisixUpstrean,以及 Apisix 上游的一些配置。原服务下方是灰度服务,左边的 controller 是之前提到的 CRD 控制器。
原服务创建好后,创建无状态服务,配置对应的 http 转发规则后转到 ApisixRoute 服务站中进行对应路由的配置,之后只有转到容器网关就会自动定位到指定服务。然后大家可以看到,我们自定义的 CRD 类型名是 CanaryDeployment,是灰度的无状态服务。创建这个无状态服务的流程和原服务是相同的。
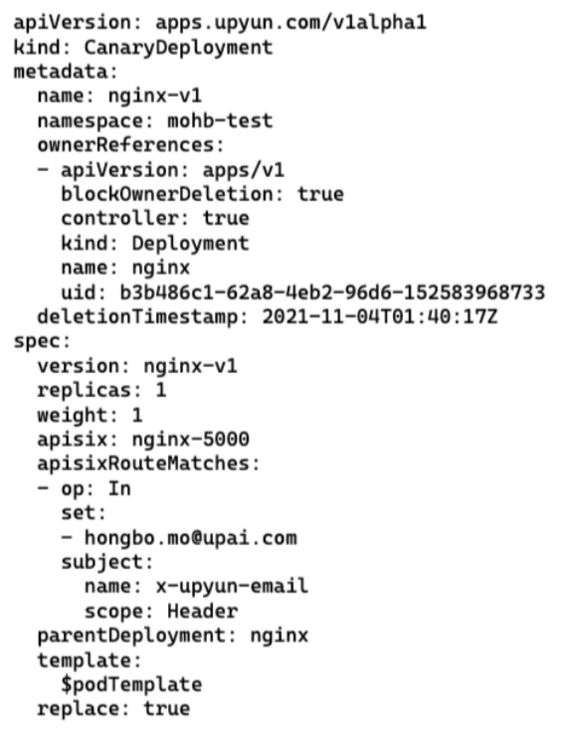
CRD 的定义是如何设计的?下图是一个简单示例:

apiVersion 我们先不讲,具体看一下下面的部分:
- kind:类型,上图类型为 CanaryDeployment(无状态服务)
- name:名称
- namespace:位置,在 mohb-test 这个测试空间下
- version:版本
- replicas:灰度实例个数,这个个数是可配的
- weight:权重,影响了灰度服务接管多少流量
- apisix:服务对应的 hb 转化规则
- apisixRouteMatches:相关功能
- parentDeployment:原无状态服务名称
- template:这里定义了刚刚讲的镜像、其他命令、开放端口等配置
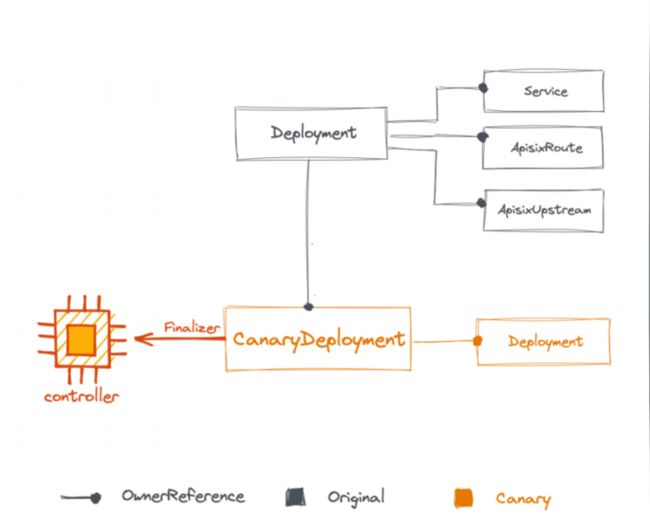
在定义 CRD 的时候可能会遇到几个问题。第一个问题是如果删除了原服务,那灰度服务不会自动删除,会被遗留。出现这个问题是因为没有做 Kubernetes 的回收技术,而解决这个问题需要 Kubernetes 的 ownerReferences。它可以帮助你把灰度服务的 CRD 指到原服务的无状态服务中,也就是灰度服务的 owner 由原服务负责。
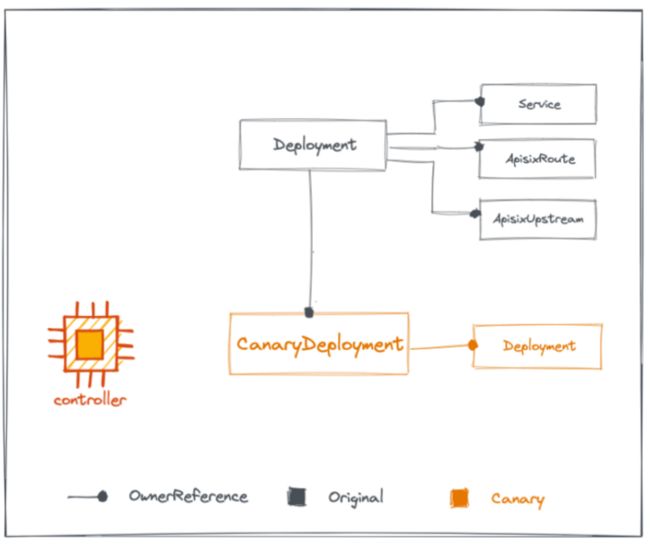
这样当删除原服务的时候,owner 会负责删除灰度服务。而删除 CanaryDeployment的时候,只会删除它右边的 Deployment。
ownerReferences 的具体设置如下图:

我们在定义 CRD 时加入红框部分的字段,这个字段会指定它是谁的 owner,以及它的指向。到这里创建阶段基本就完成了。
替换
接下来看第二阶段——替换。

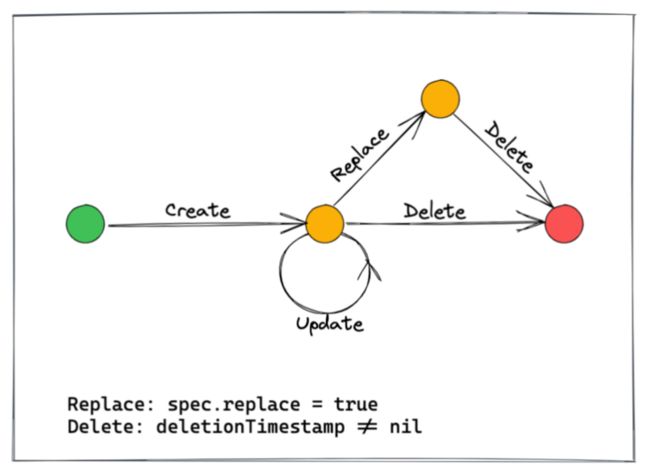
我通过加入字段 replace 进行控制,默认情况下它是 false,如果值是 true 那控制器就会知道要用 deployment 的进行替换。这里有个问题是什么时候进行替换?也就是什么时候把流量切过去。虽然直接切也可以,但是等原服务完全运行起来后再切无疑是更好的。
那具体要怎么做呢?
这就涉及到 informer 的部分逻辑了。这需要控制器能够感知到灰度服务的 parentDeployment 是否发生变更。这部分 operator-sdk 和 Kubebuilder 就很好,它可以把不是 CRD 事件的变动也导入到调和函数内,让控制器可以监听无状态服务。
具体可以看一下代码。首先注册一些 watch 来监听无状态服务,然后写一个函数让无状态服务对应到 CanaryDeployment,比如在 text back 内对无状态服务进行了标记,这样当感知到事件后可以看一下是哪个无状态服务进行了替换,并推算出对应的 CanaryDeployment,然后通过调用调和函数对比和预期是否有差距。
取消
接下来看最后一个阶段——取消阶段。
如果直接把 CanaryDeployment 对应的对象删掉,就会发现它的右边多了一个 deletionTimestamp 的字段,这是 Kubernetes 打的删除时间标记。而对于控制器来讲,就是知道这个已经是删除状态了,需要调整对应内容。
这有个问题,删除是瞬间的操作,可能等不到控制器运行起来,删除就已经完成了。因此 Kubernetes 提供了 Finalizer,Finalizer 决定了最终由谁来做释放。
Finalizer 是自定义的,对应我们自己写的 controller。当 Kubernetes 看到 Finalizer 不为空时,就不会立即删除,而是出于删除中的状态,这就让 controller 有时间去做一些对应处理。
压力测试 wrk
一套东西做完后,验证它是否正确的方法就是进行压力测试。

我用了一个更加通用的工具来做压力测试,可以设置更多的东西。比如可以做一些逻辑上的处理。如上图例子一样,假设有一个服务,请求原服务会返回“ helloword”,而请求灰度版本则会返回“ hello Hongbo”。然后定义回来的包,让每一个请求结束后都会调用函数判断是否等于 200,如果不是,那可能是切的过程中出现了异常,如果等于 200,则可以看一下里面是否有 “Hongbo”。如果有,那证明请求的是灰度版本。这样房门定一个档(summary),对请求到原服务、灰度服务、失败请求的次数进行统计了。
另外还可以进行一下头部设置:
- -c:多少个链接,比如 20
- -d:放低多长时间,比如 3 分钟
- -s:脚本对应的地址

上图是压测的结果,大家可以简单看一下。
总结和规划
接下来和大家谈一下引入 CRD 后的总结。在引⼊ CRD 后,基于 Kubernetes 事件驱动以及⽔平触发的理念,简化了实现的复杂性。而且因为采用了 OperatorSDK 的成熟框架,不再需要关心底层的实现,可以更加聚焦于业务的逻辑实现。减少了开发成本,提高了开发效率。
然后关于未来,有以下的规划:
- apisix 采用 subnet 的方式,减少创建的资源,提高成功率
- 支持按 HTTP 头部、特定 IP 灰度
- 灰度服务流量比较
以上就是今天关于灰度更新实践的分享了,感谢大家的支持。