hadoop大数据平台搭建(一)
@Hadoop大数据平台搭建
前言(这篇文章的背景和目的)
百科是这样解释大数据(Big data)。“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
大数据需要特殊的技术,以有效地处理大量的容忍经过时间内的数据。适用于大数据的技术,包括大规模并行处理(MPP)数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统。
本人是一名大学生,目前也在学习大数据,文中但凡有错误的地方请大家积极指正,希望在这方面以及其他相关领域和大家一起学习交流。话不多说,上干货。
学习前准备工作
1、linux基础的知识,还要有Linux系统结构框架的认知。
2、python基础,这个很是重要!!!Python太强大了,数据预处理,数据分析,数据可视化都可以用到。上手也挺简单的。(后面有时间出一期)
3、java基础知识和范式,mapreduce的编写语言是java语言的,所以要熟悉eclipse开发环境和对应的Java语法。
4、我是用的虚拟机装linux系统(centos6.5),所以吃点电脑配置,我个人建议笔记本练习配置:i7或者i5稍微新的版本,最最好内存是16g或者12g,不然虚拟机很卡,硬盘一般500g的就行。
Hadoop的生态概括
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。可以在不了解分布式底层细节的情况下,开发分布式程序。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。

Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 。
HDFS
HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,但是 HDFS 的架构是基于一组特定的节点构建的。这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode(可以多个),它为 HDFS 提供存储块。存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议 。
Mapreduce
最简单的 MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。main 函数将作业控制和文件输入/输出结合起来。MapReduce 本身就是用于并行处理大数据集的软件框架。MapReduce 的根源是函数性编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和 Reduce)的操作组成。Map 函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键值对列表 。
HBASE
hbase是一个建立在HDFS之上,面向列的针对结构化的数据可伸缩,高可靠,高性能分布式和面向列的动态模式数据库。
Zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
Hive
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
Yarn
Apache Hadoop YARN 是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Spark
Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark看可以说是Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是不需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
装虚拟机
我个人习惯是vmware,其他版本虚拟机都行。下载vmware16版本,打开安装。

点击下一步,我提前下载好了centos6的镜像文件,你们可以去官网或者我这里下载



随意写虚拟机名字,最好是英文。

20G够我们学习用了。

我这里是16G内存,所以我分了虚拟机4g内存,这里说明一下,后面我是直接复制3台虚拟机,所以虚拟机的内存配置是一台4g 一台2g 一台2g。普及一下小知识,笔记本普遍是8g内存,而电脑操作系统会占用2g多一些,实际我们可以使用内存6g不到,再加上其他的聊天软件,实际虚拟机使用内存最多是5g多,16g内存依次类推。如果你们8g电脑内存,个人建议给2g装有NameNode的主机,另外2台分1g内存正好
配置网络

打开网络配置器,找到vm8虚拟网卡,右击属性。

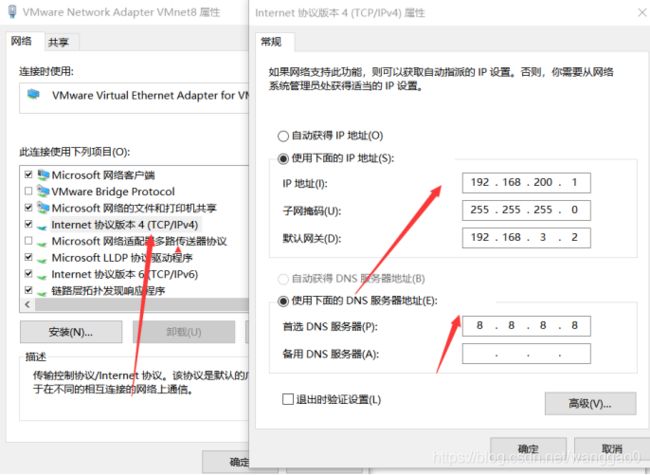
我用的net配置虚拟机网络(可以直接照着我的做),你们还可以用其他方式配置网络。
打开虚拟机,输入账号和密码进行登录。
vi /etc/sysconfig/network-scripts/ifcfg-eth0

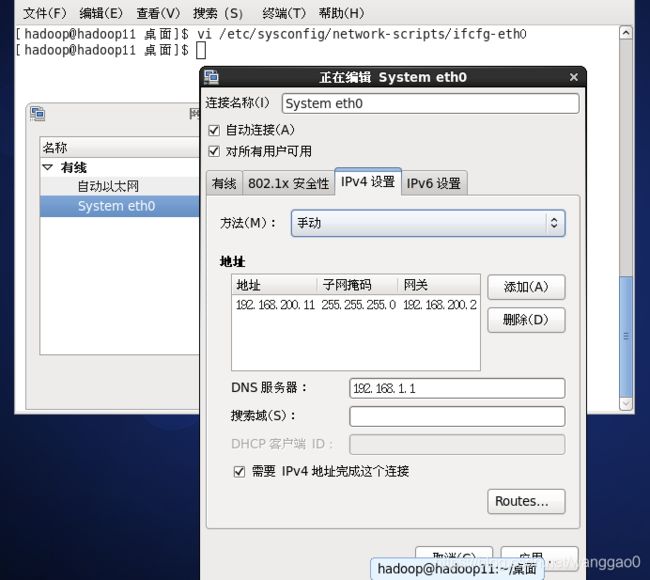
我们需要增加IP地址、网关、和DNS1具体配置如下图所示。
将ONBOOT设置为yes,将BOOTPROTO设置为static(静态)。
修改完之后按下esc,再输入 :wq!,以保存退出或者shift+zz直接保存退出。
关闭防火墙,输入
service ip6 tables stop
之后右边会出现绿色的ok字样,代表关闭成功。
重启网络,在命令行中输入service network restart。
重启网卡成功之后右边会出现绿色的ok字样。
通过ipconfig命令可以查看IP地址是否改过来了,或者可视化操作找到centos6的网络连接 直接配置。
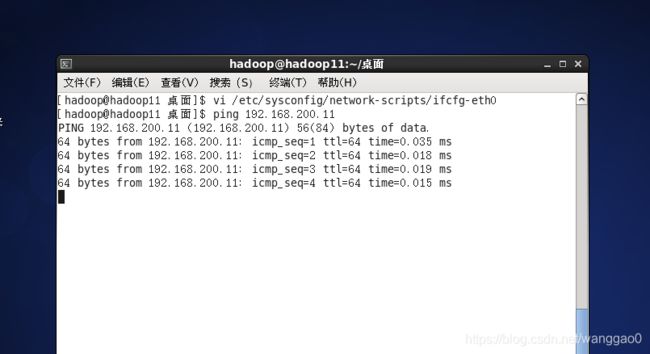
用ping检查一下 如果可以ping通就行了
这是配置网络成功的。ctrl+c 停止它。
更改主机名 建立映射
hostname更改主机名,命令使用方式hostname+主机名,我改的是
hostname hadoop11
这个需要记住,后面用到,进入本地找到虚拟机的安装文件夹。
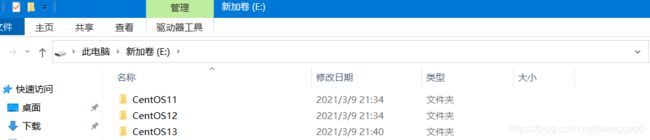
复制出来两个虚拟机文件夹,使用vm16扫描虚拟机,然后进去虚拟机。
改一下主机名,IP地址(最好连续地址好记,我这里创建了三个虚拟主机,分别命名hadoop11、hadoop12、hadoop13,对应地址是192.168.200.11 、192.168.200.12 、192.168.200.13 )。
使用命令
vi /etc/hosts
然后配置三台主机和IP的映射。

三台机子都要配置上面的映射。
ssh 免密码登录
输入命令:ssh-keygen -t rsa 然后点击四个回车键,如下图所示:

关闭防火墙
关闭防火墙:
service iptables stop
永久关闭防火墙:
chkconfig iptables off
运行完成后查看防火墙关闭状态
service iptables status
安装jdk
三个节点安装java并配置java环境变量
解压压缩包
tar zxvf jdk-linux-x64.tar.gz
sudo mv jdk1.8.0_77 /usr/app
在/etc/profile文件里添加jdk路径
vi /etc/profile
export JAVA_HOME=/usr/app/jdk1.8.0_77
export PATH=$JAVA_HOME/bin:$PATH

(后面hadoop hbase hive spark文件也需要这样配置)
执行命令source /etc/profile使配置文件生效,并查看java版本信息
source /etc/profile
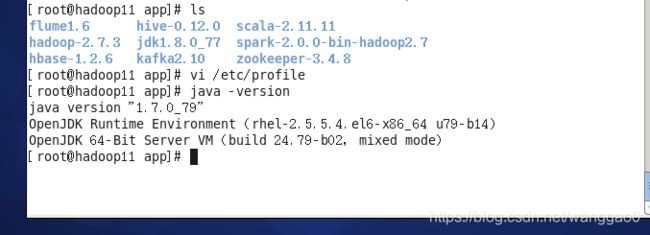
验证jdk安装成功。
安装SecureCRT


输入主机名 ip名然后输入用户密码 连接如上图
SecureCRT是一款支持SSH(SSH1和SSH2)的终端仿真程序,简单地说是Windows下登录UNIX或Linux服务器主机的软件。可以在CRT里面控制虚拟机的主机,简单方便,配置几个界面就行了。
打开 选项 找到对话设置
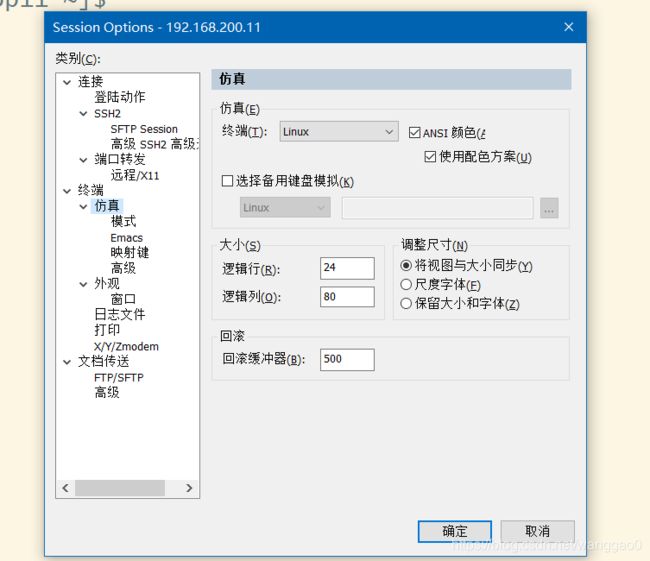
设置仿真模式 linux模式 大小随意

设置外观 utf-8 字体随意

打开 命令窗口 下面出来一栏空白栏,右击选择发送到交互全部命令,这个空白栏可以 一个命令控制多台主机,后面配置都可以在这里弄。
搭建hadoop集群

hadoop集群需要在每一个节点上进行相同的配置,因此先在hadoop11节点上配置,然后再复制到其他节点上
,将hadoop包放在/usr/app/目录下并解压解压hadoop 配置环境变量
tar zxvf hadoop-2.7.3.tar.gz -C
cd hadoop-2.7.3
vi /etc/profile
export HADOOP_HOME=/usr/app/hadoop-2.7.3
export HADOOP_USER_NAME=hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
设置环境生效
source /etc/profile
配置hadoop文件
进入/usr/app/hadoop-2.7.1/etc/hadoop/目录下的文件
hadoop-env.sh yarn-site.xml slaves core-site.xml hdfs-site.xml mapred-site.xml yarn-env.sh
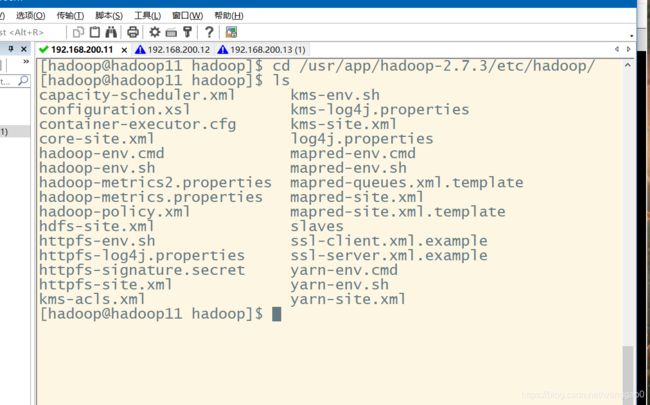
vi hadoop-env.sh

vi yarn-env.sh 
vi slaves

配置vi core-site.xml
fs.defaultFS
hdfs://ns1
hadoop.tmp.dir
/usr/app/hadoop-2.7.3/tmp
ha.zookeeper.quorum
hadoop11:2181,hadoop12:2181,hadoop13:2181
vi hdfs-site.xml
dfs.nameservices
ns1
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
hadoop11:9000
dfs.namenode.http-address.ns1.nn1
hadoop11:50070
dfs.namenode.rpc-address.ns1.nn2
hadoop12:9000
dfs.namenode.http-address.ns1.nn2
hadoop12:50070
dfs.namenode.shared.edits.dir
dfs.journalnode.edits.dir
/usr/app/hadoop-2.7.3/journal/data
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailo
verProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
vi mapred-site.xml
mapreduce.framework.name
yarn
vi yarn-site.xml 文件配置我是全部复制了
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop11
yarn.resourcemanager.hostname.rm2
hadoop12
yarn.resourcemanager.zk-address
hadoop11:2181,hadoop12:2181,hadoop13:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
接下来将配置好的hadoop文件复制到其他节点上
scp -r /usr/app/hadoop-2.7.3/ root@hadoop12:/usr/app/
scp -r /usr/app/hadoop-2.7.3/ root@hadoop13:/usr/app/
运行hadoop
格式化Namenode
cd /usr/app/hadoop-2.7.3
./bin/hdfs namenode -format
hadoop version

安装成功,启动hadoop集群
cd /usr/app/hadoop-2.7.3/sbin/
./start-all.sh
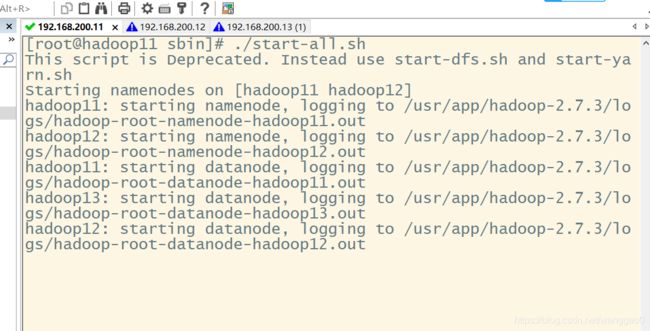
接着打印出日志文件,用jps 测试集群全部跑起来没,全部跑起来了。

web界面访问hadoop hdfs管理界面

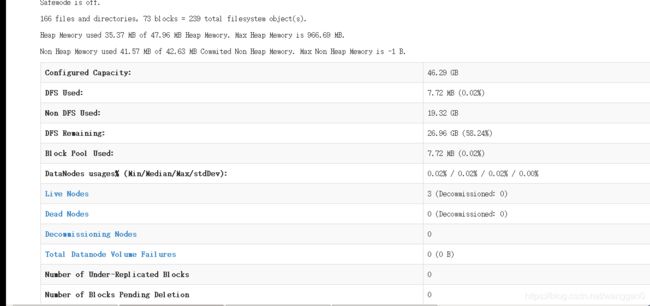
以上是我自己安装的经验,有不懂的可以私信我,所需文件在我主页里。等会更新安装hive hbase spark等。上面有错误的请大家帮忙指正,谢谢。