早上打开微博一看,WC,微博推给我的第一条就是一篇瓜文。
于是熟练的找到了瓜文出处,基本情况就是力宏前妻忍无可忍,于是发文手撕力宏 ... 博文如下:

开始,我还有些疑惑,前两天力宏是承认了离婚并发了博文:
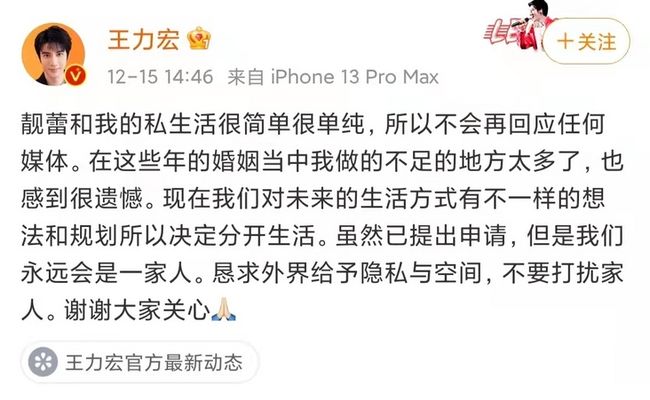
博文中透漏的完全是一副好聚好散,岁月静好的气氛,好像用词有点不当了,不过也不纠结这些了。
本人虽不追星,对各种大小明星也基本无感,但也是很多年前就在娃哈哈的矿泉水瓶上知道力宏这号人物了...

记不清是什么时间了,娃哈哈换掉了代言人力宏,当时网络上还是一片声讨,现在看来 ...
于是我带着吃瓜群众的好奇心读了李靓蕾的微博撕文,WC,真是欠力宏一座奥斯卡 ...

如此瓜文,怎么能放过评论区呢 ... 于是我准备用 Python 爬取评论区数据,主要代码实现如下:
# 爬取一页评论内容
def get_one_page(url):
headers = {
'User-agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3880.4 Safari/537.36',
'Host' : 'weibo.cn',
'Accept' : 'application/json, text/plain, */*',
'Accept-Language' : 'zh-CN,zh;q=0.9',
'Accept-Encoding' : 'gzip, deflate, br',
'Cookie' : '自己的Cookie',
'DNT' : '1',
'Connection' : 'keep-alive'
}
# 获取网页 html
response = requests.get(url, headers = headers, verify=False)
# 爬取成功
if response.status_code == 200:
# 返回值为 html 文档,传入到解析函数当中
return response.text
return None
# 解析保存评论信息
def save_one_page(html):
comments = re.findall('(.*?)', html)
for comment in comments[1:]:
result = re.sub('<.*?>', '', comment)
if '回复@' not in result:
with open('comments.txt', 'a+', encoding='utf-8') as fp:
fp.write(result)爬取分析过程这里就不说了,不清楚的可以看一下:微博评论区爬取,数据有了,现在我们再用 Python 来看一下 TOP10 词汇有哪些,主要代码实现如下:
stop_words = []
with open('stop_words.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
content = open('comments.txt', 'rb').read()
# jieba 分词
word_list = jieba.cut(content)
words = []
for word in word_list:
if word not in stop_words:
words.append(word)
wordcount = {}
for word in words:
if word != ' ':
wordcount[word] = wordcount.get(word, 0)+1
wordtop = sorted(wordcount.items(), key=lambda x: x[1], reverse=True)[:10]
wx = []
wy = []
for w in wordtop:
wx.append(w[0])
wy.append(w[1])
(
Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
.add_xaxis(wx)
.add_yaxis('数量', wy)
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title='评论词 TOP10'),
yaxis_opts=opts.AxisOpts(name='词语'),
xaxis_opts=opts.AxisOpts(name='数量'),
)
.set_series_opts(label_opts=opts.LabelOpts(position='right'))
).render_notebook()看一下效果:
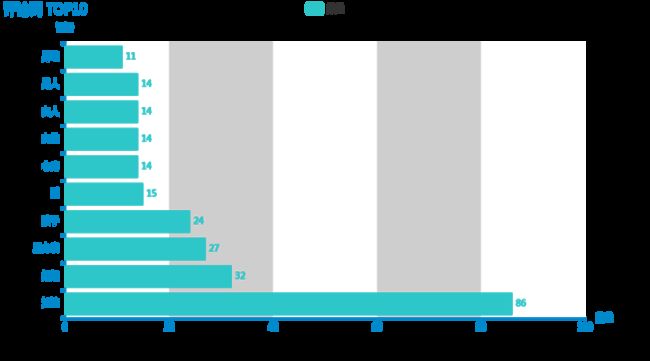
这里我们不做评论了,接着再生成词云看看评论区,主要代码实现如下:
def jieba_():
stop_words = []
with open('stop_words.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
content = open('comments.txt', 'rb').read()
# jieba 分词
word_list = jieba.cut(content)
words = []
for word in word_list:
if word not in stop_words:
words.append(word)
global word_cloud
# 用逗号隔开词语
word_cloud = ','.join(words)
def cloud():
# 打开词云背景图
cloud_mask = np.array(Image.open('bg.png'))
# 定义词云的一些属性
wc = WordCloud(
# 背景图分割颜色为白色
background_color='white',
# 背景图样
mask=cloud_mask,
# 显示最大词数
max_words=200,
# 显示中文
font_path='./fonts/simhei.ttf',
# 最大尺寸
max_font_size=100
)
global word_cloud
# 词云函数
x = wc.generate(word_cloud)
# 生成词云图片
image = x.to_image()
# 展示词云图片
image.show()
# 保存词云图片
wc.to_file('melon.png')看一下效果:

源码已经整理好了,有需要的可以在公众号Python小二后台回复wlh获取。