

前言
从2020年10月,基于 Amazon Graviton2 的数据库逐步推出,您可以在使用 Amazon RDS for MySQL、Amazon RDS for PostgreSQL 、Amazon RDS for MariaDB 以及兼容 PostgreSQL 和 MySQL 的 Amazon Aurora时启动这些数据库实例。
Amazon Graviton2 处理器由 Amazon Web Services 使用 64 位 Arm Neoverse 内核定制,对第一代 Amazon Graviton 处理器进行了多种性能优化。这包括 7 倍的性能、4 倍的计算核心数量、每个内核 2 倍的私有内存、5 倍的内存速度和每个核心 2 倍的浮点性能。此外,Amazon Graviton2 处理器还具有全天候运行的全加密 DDR4 内存功能,并且每核加密性能提高 50%。这些性能提升使 Graviton2 R6g 数据库实例成为数据库工作负载的上佳之选。
本文将向您展示Graviton2 R6g 数据库实例对R5数据库实例的性能增强以及从自建或者托管数据库上迁移到Graviton2 R6g 数据库实例的方法流程。通过测试我们可以清楚地看到,无论是何种工作负载和并发条件,R6g实例比之同等资源配置的R5实例性能均有显著的提升,而每小时单价却有下降,因而R6g实例对客户来说,有更好的性价比。
环境准备
1.环境信息

注意:Aurora的参数基本选用默认参数。因为sysbench1.0.18会有大量prepared statement,所以要设置max_prepared_stmt_count为最大值1048576保证测试顺利进行,否则初始化时可能遇到错误FATAL: MySQL error: 1461 “Can’t create more than max_prepared_stmt_count statements (current value: 16382)”
2.安装和配置sysbench
在测试客户端安装sysbench1.0.18
从git中下载sysbench
sudo yum install gcc gcc-c++ autoconf automake make libtool bzr mysql-devel git mysql
git clone https://github.com/akopytov/sysbench.git打开sysbench目录
cd sysbench
切换到sysbench 1.0.18版本,运行autogen.sh
git checkout 1.0.18
sudo ./autogen.sh编译
sudo ./configure --prefix=/usr --mandir=/usr/share/man
sudo make
sudo make install3.打开客户端资源限制
无论安装哪一种sysbench软件,都需要在Sysbench客户端执行 以下配置,告诉Linux kernel可以用所有的CPU cores 去处理 packets(默认只可以用两个),且减少cores 之间的context switching. 这两个设置是为了用更少的Sysbench 客户端达成吞吐目标.( ffffffff表示使用32个核。请根据实际配置修改,例如实际只有8核,则输入ff)
sudo sh -c 'for x in /sys/class/net/eth0/queues/rx-*; do echo ffffffff> $x/rps_cpus; done'
sudo sh -c "echo 32768 > /proc/sys/net/core/rps_sock_flow_entries"
sudo sh -c "echo 4096 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt"
sudo sh -c "echo 4096 > /sys/class/net/eth0/queues/rx-1/rps_flow_cnt"
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536测试
1.只读负载测试
测试数据注入
首先通过sysbench客户端在测试数据库上生成测试表,这里生成250个表,每个表有行数25000条,您也可以根据您的目标,调整表的数目和大小,请替换<>之中的各种连接信息,再执行命令,如果您直接从blog拷贝命令请注意格式。后续命令的注意事项相同,将不再赘述

sysbench --db-driver=mysql --mysql-host=--mysql-port=--mysql-user=--mysql-password=--mysql-db=--table_size=25000 --tables=250 --events=0 --time=600 oltp_read_only prepare测试
在sysbench client执行命令模拟负载,每次持续20分钟,同时从console查看数据库CPU,IO,网络等metrics。在这里我们将通过修改num_threads参数连续测试32, 64, 128, 256多种并发连接的场景。
sysbench --db-driver=mysql --mysql-host= --mysql-user= --mysql-password= --mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=32 --percentile=95 --range_selects=0 --skip-trx=1 --report-interval=20 oltp_read_only run >> _read.log
sysbench --db-driver=mysql --mysql-host= --mysql-user= --mysql-password= --mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=64 --percentile=95 --range_selects=0 --skip-trx=1 --report-interval=20 oltp_read_only run >> _read.log
sysbench --db-driver=mysql --mysql-host= --mysql-user= --mysql-password= --mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=128 --percentile=95 --range_selects=0 --skip-trx=1 --report-interval=20 oltp_read_only run >> _read.log
sysbench --db-driver=mysql --mysql-host= --mysql-user= --mysql-password= --mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=256 --percentile=95 --range_selects=0 --skip-trx=1 --report-interval=20 oltp_read_only run >> _read.log 清除测试数据
测试后清除数据命令如下:
sysbench --db-driver=mysql --mysql-host=--mysql-port=--mysql-user=--mysql-password=--mysql-db=--table_size=25000 --tables=250 --events=0 --time=600 oltp_read_only cleanup2.只写负载测试
数据注入
sysbench --db-driver=mysql --mysql-host=--mysql-port=--mysql-user=--mysql-password=--mysql-db=--table_size=25000 --tables=250 --events=0 --time=600 oltp_write_only prepare测试
同样地,在sysbench client执行命令模拟只写负载,每次持续20分钟,同时从console查看数据库CPU,IO,网络等metrics。在这里我们将通过修改num_threads参数连续测试8,16,32和64多种并发连接的场景。
sysbench --db-driver=mysql --mysql-host= --mysql-user=--mysql-password=--mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=8 --percentile=95 --report-interval=20 oltp_write_only run >>_write.log
sysbench --db-driver=mysql --mysql-host= --mysql-user=--mysql-password=--mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=16 --percentile=95 --report-interval=20 oltp_write_only run >>_write.log
sysbench --db-driver=mysql --mysql-host= --mysql-user=--mysql-password=--mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=32 --percentile=95 --report-interval=20 oltp_write_only run >>_write.log
sysbench --db-driver=mysql --mysql-host= --mysql-user=--mysql-password=--mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=64 --percentile=95 --report-interval=20 oltp_write_only run >>_write.log清除测试数据
sysbench --db-driver=mysql --mysql-host=--mysql-port=--mysql-user=--mysql-password=--mysql-db=--table_size=25000 --tables=250 --events=0 --time=600 oltp_write_only cleanup3.读/写混合压力测试
测试数据注入
sysbench --db-driver=mysql --mysql-host=--mysql-port=--mysql-user=--mysql-password=--mysql-db=--table_size=25000 --tables=250 --events=0 --time=600 oltp_read_write prepare测试
同样地,在sysbench client执行命令模拟读写混合负载,每次持续20分钟,同时从console查看数据库CPU,IO,网络等metrics。在这里我们将通过修改num_threads参数连续测试32、64、128和256多种并发连接的场景。
sysbench --db-driver=mysql --mysql-host= --mysql-user=--mysql-password=--mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=32 --percentile=95 --report-interval=20 oltp_read_write run >>_read_write.log
sysbench --db-driver=mysql --mysql-host= --mysql-user=--mysql-password=--mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=64 --percentile=95 --report-interval=20 oltp_read_write run >>_read_write.log
sysbench --db-driver=mysql --mysql-host= --mysql-user=--mysql-password=--mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=128--percentile=95 --report-interval=20 oltp_read_write run >>_read_write.log
sysbench --db-driver=mysql --mysql-host= --mysql-user=--mysql-password=--mysql-port= --mysql-db= --table_size=25000 --tables=250 --events=0 --max-time=1200 --threads=256 --percentile=95 --report-interval=20 oltp_read_write run >>_read_write.log清除测试数据
sysbench --db-driver=mysql --mysql-host=--mysql-port=--mysql-user=--mysql-password=--mysql-db=--table_size=25000 --tables=250 --events=0 --time=600 oltp_read_write cleanup结果分析
1.结果解读
数据库性能测试输出结果中的指标包括:
每秒执行事务数TPS(Transactions Per Second) 数据库每秒执行的事务数,以COMMIT成功次数为准。
SysBench标准OLTP读写混合场景中一个事务包含18个读写SQL。
SysBench标准OLTP只读场景中一个事务包含14个读SQL(10条主键查询、4条范围查询)。
SysBench标准OLTP只写场景中一个事务包含4个写SQL(2条UPDATE、1条DETELE、1条INSERT)。
每秒执行请求数QPS(Queries Per Second) 数据库每秒执行的SQL数。
2.结果统计
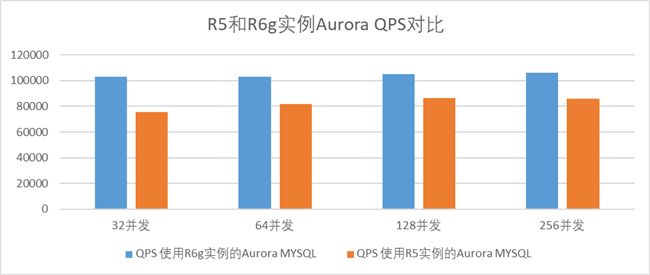
在不同并发连接数下,使用相同资源配置的R6g和R5实例的Aurora MySQL5.7只读负载测试数据如下:

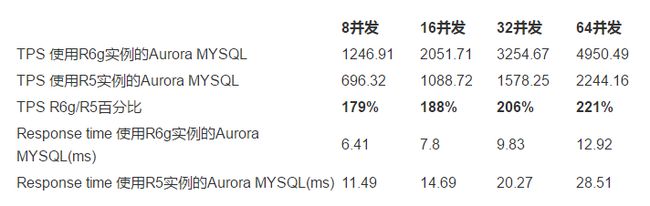
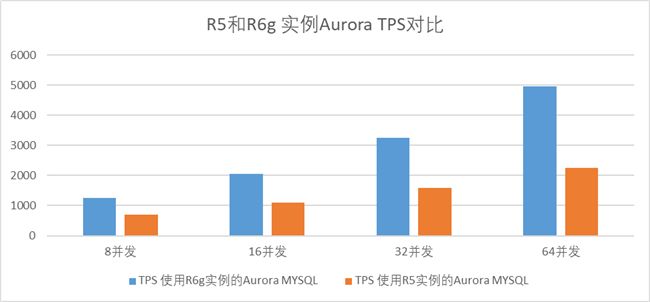
在不同并发连接数下,使用相同资源配置的R6g和R5实例的Aurora MySQL5.7只写负载测试数据如下:
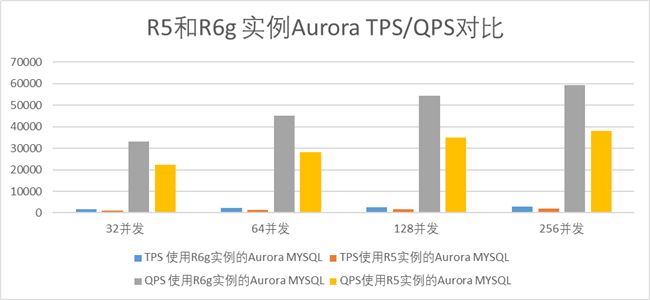
在不同并发连接数下,使用相同资源配置的R6g和R5实例的Aurora MySQL5.7读/写混合负载测试数据如下:

3.结论
通过以上测试数据,我们可以发现:
在只读负载测试中,R6g实例比之同等资源配置的R5实例,QPS提升了21%-37%。
在只写负载测试中,R6g实例比之同等资源配置的R5实例,QPS提升了79%-121%。
在读写混合负载测试中,R6g实例比之同等资源配置的R5实例,QPS提升了48%-60%。
在测试中无论是何种工作负载和并发条件,R6g实例比之同等资源配置的R5实例性能均有显著的提升。
在价格方面,我们可以参考Aurora价格页面,以我们测试的r5.2xlarge和db.r6g.2xlarge为例,db.r6g.2xlarge每小时单价为db.r5.2xlarge每小时单价的89.4%,结合之前性能测试结果,无疑R6g实例比之R5实例有更好的性价比。
注意:不同region不同实例类型的报价不同,下图为2021-04-21时截图,最新价格请见上面价格页面。

迁移MySQL到R6g实例Aurora
1.迁移到R6g实例Aurora的理由
相对于在EC2上自建的MySQL,使用Aurora MySQL可以带来很多益处,限于篇幅,现从四个方面简述如下:
高可用性
Aurora 将数据跨3个可用区同步复制到与集群卷关联的 6 个存储节点,提供AZ(可用区)+1的容错机制,即1个AZ崩溃依旧可以写,一个AZ+一个数据副本无法访问依然可读。
更快的failover时间,配合RDS Proxy,通常Aurora平均failover时间为3秒左右。
集群终端节点为数据库集群的读取/写入连接提供故障转移支持。如果数据库集群的当前主数据库实例失败,Aurora 将自动故障转移到新的主数据库实例。在故障转移期间,数据库集群将继续为从新的主数据库实例到集群终端节点的请求提供服务,对服务造成的中断最少。
Amazon Aurora 全球数据库允许单个 Amazon Aurora 数据库跨越多个 Amazon 地区(region)。它在不影响数据库性能的情况下复制您的数据,在发生地区(region)级的中断时提供灾难恢复能力。
可扩展性
Aurora 最多可以创建 15 个只读 Aurora 副本对读取能力进行横向扩展,Aurora 数据库集群的读取器终端节点为数据库集群的只读连接提供负载均衡支持。
只读Aurora 副本与主实例共享相同的底层存储,与MySQL的基于binlog复制不同,Aurora集群上的副本通常比主实例滞后 10 毫秒。
Amazon Aurora 全球数据库针对全球分布式应用程序而设计,在每个 地区(region)中实现低延迟的快速本地读取,使用基于存储的复制,典型延迟小于 1 秒。
性能
Amazon Aurora 通过将数据库引擎与为数据库工作负载构建的基于 SSD 的虚拟化存储层紧密集成,减少存储系统的写入操作,最大程度降低锁竞争并消除数据库进程线程所产生的延迟,使性能大幅超过 MySQL。
Parallel Query 非常适合需要新数据和良好查询性能的分析工作负载,可将分析查询的运行速度提高多达 2 个数量级。而且不需要更改查询语法。查询优化器可以自动确定是否使用 PQ 来运行特定查询。
可管理性
Aurora作为托管数据库服务,可以处理耗时型任务,如预置、修补、备份、恢复、故障检测和修复,大大减轻您的运维压力。
Aurora Serverless 数据库集群会根据您应用程序的需求自动启动、关闭以及扩展或缩减容量。Aurora Serverless 是简单且更具成本效益的选择,适用于不频发的、间歇性的或不可预测的工作负载。
Aurora 克隆使用写入时复制协议。使用此机制,克隆在首次创建时只需要很少的额外空间。开始时,Aurora 维护数据的单个副本(由原始数据库集群和新数据库集群使用)。Aurora 仅在源集群或克隆集群上的数据发生更改时分配新的存储空间。借助克隆,我们可以快速经济地创建一个新的集群用于测试、审计等场景。
利用回溯功能您可以将数据库集群回溯到特定时间,而无需从备份还原数据。尤其当您需要不断重置测试环境消除变更数据时,回溯功能比传统的时间点恢复要高效得多。
可以通过机器学习 (ML) 功能与 Amazon Aurora的 结合使用,简化开发使用 Amazon SageMaker 和 Amazon Comprehend 服务执行预测的数据库应用程序的过程。此功能适用于多种快速预测。包括低延迟的实时用例,例如欺诈检测、广告定位和产品推荐。查询将客户资料、购物历史记录和产品目录数据传递给 SageMaker 模型。然后,您的应用程序将获得作为查询结果返回的产品推荐。
2.从EC2自建MySQL迁移到迁移到R6g实例Aurora的方法
如果您在EC2上自建MySQL5.6或5.7,您可以用以下四种办法迁移到R6g实例的Aurora MySQL:
通过mysqldump迁移
因为 Amazon Aurora MySQL 是与 MySQL 兼容的数据库,所以您可以使用mysqldump 实用程序从 MySQL 或 MariaDB 数据库中将数据复制到现有 Aurora MySQL 数据库集群。
有关如何为大型 MySQL 数据库执行该操作的讨论,请参阅将数据导入到 MySQL 或 MariaDB 数据库实例中,同时减少停机时间:
https://docs.aws.amazon.com/A...
对于具有较少量数据的 MySQL 数据库,请参阅将数据从 MySQL 或 MariaDB 数据库导入到 MySQL 或 MariaDB 数据库实例:
https://docs.aws.amazon.com/A...
通过xtrbackup迁移
您可以将完整备份文件和增量备份文件从源 MySQL 5.5、6 或 5.7 版数据库复制到 Amazon S3 存储桶,然后从这些文件还原 Amazon Aurora MySQL 数据库集群。具体步骤请见:将数据从外部 MySQL 数据库迁移到 Amazon Aurora MySQL 数据库集群:
https://docs.aws.amazon.com/z...
该选项可能比使用mysqldump 迁移数据要快得多,因为使用 mysqldump 需要重放所有命令,以便在新的 Aurora MySQL 数据库集群中从源数据库重新创建架构和数据。通过复制源 MySQL 数据文件,Aurora MySQL 可以立即将这些文件作为 Aurora MySQL 数据库集群的数据。
通过原生主从方式迁移
创建用于复制的专用用户并授予权限
历史数据可以通过xtrbackup或mysqldump导入,在导出数据时通过添加参数在备份文件中记录日志点的位置信息
设置网络和安全组保证源MySQL和目标Aurora可以互连
通过运行rds_set_external_master 存储过程,配置二进制日志复制。
通过运行rds_start_replication 存储过程,启动二进制日志复制。
具体步骤请见将数据从外部 MySQL 数据库迁移到 Amazon Aurora MySQL 数据库集群:
https://docs.aws.amazon.com/z...
通过DMS任务迁移
Amazon Database Migration Service(DMS)服务可以帮助客户在最小停机时间的情况下, 采用在源库上捕获变化数据,并在目标库上应用变化数据的形式,进行数据库的整体迁移。DMS不仅可以进行相同数据库引擎的迁移,同时还支持不同数据库引擎之间的迁移。有关DMS的详细信息可以参考:https://aws.amazon.com/dms/。大致步骤如下:
创建复制实例保证可以连接到源和目标数据库,在源和目标数据库上创建复制数据专用用户并赋予相应权限
创建源MySQL和目标Aurora的endpoint并通过复制实例测试连接
创建Full load and CDC任务,指定要复制的对象,可以是schema或者表的组合。
开启任务,Full load任务负责迁移历史数据。
Full load完成后,CDC任务会从binlog中捕获变化并同步到Aurora
在业务低谷的时间段,停止向源数据库写入,等待CDC任务复制延迟为0后,确认数据一致切换应用程序向Aurora写入完成迁移。
3. 从RDS迁移到迁移到R6g实例Aurora的方法
如果您已经使用了MySQL5.6或5.7的RDS,您可以用以下三种办法迁移到R6g实例的Aurora MYSQL:
通过只读副本迁移
您可以为源 MySQL 数据库实例创建一个特殊类型的数据库集群,称为 Aurora 只读副本,这种方法可以将RDS数据迁移到Amazon Aurora并要求最小停机时间,通常我们建议选择此种迁移方式。具体步骤可见:通过Aurora只读副本迁移:
https://docs.aws.amazon.com/z...
在创建 MySQL 数据库实例的 Aurora 只读副本时,Amazon RDS 为源 MySQL 数据库实例创建数据库快照(Amazon RDS 私有,不产生费用)。
然后,Amazon RDS 将数据从数据库快照迁移到 Aurora 只读副本。
在将数据从数据库快照迁移到新的 Aurora MySQL 数据库集群后,Amazon RDS 开始在 MySQL 数据库实例和 Aurora MySQL 数据库集群之间进行复制。
如果 MySQL 数据库实例中包含的表使用 InnoDB 之外的存储引擎,或者使用压缩行格式,您可以在创建 Aurora 只读副本之前修改这些表以使用 InnoDB 存储引擎和动态行格式,从而加快 Aurora 只读副本的创建过程。
通过RDS快照迁移
您可以迁移 RDS for MySQL 数据库实例的数据库快照来创建 Aurora MySQL 数据库集群。将使用原始 RDS for MySQL 数据库实例中的数据填充新的 Aurora MySQL 数据库集群。这种方法无法持续复制变更数据,如果希望填充到Aurora的数据与RDS中一致,需要保持RDS只读,通常用于有足够的停机时间窗口的迁移。具体步骤可见:将 RDS for MySQL 快照迁移到 Aurora:
https://docs.aws.amazon.com/z...
如果 MySQL 数据库实例和 Aurora 数据库集群运行相同版本的 MySQL,您可以将 MySQL 快照直接还原到 Aurora 数据库集群。
如果您要将 MySQL 5.6 版本快照迁移到 Aurora MySQL 5.7 版本,可以使用以下一种方法执行迁移:
将 MySQL 5.6 版快照迁移到 Aurora MySQL 5.6 版,拍摄 Aurora MySQL 5.6 版数据库集群快照,然后将 Aurora MySQL 5.6 版快照还原到 Aurora MySQL 5.7 版。
将 MySQL 版本6 快照升级到 MySQL 版本 5.7,拍摄 MySQL 版本 5.7 数据库实例的快照,然后将 MySQL 版本 5.7 快照还原到 Aurora MySQL 版本 5.7。
通过DMS任务迁移
此方法在2节已叙述,故不再赘述。
总结
本文将向您展示Graviton2 R6g 数据库实例对R5数据库实例的性能增强以及从自建或者托管数据库上迁移到Graviton2 R6g 数据库实例的方法流程。通过测试我们可以清楚地看到,无论是何种工作负载和并发条件,R6g实例比之同等资源配置的R5实例性能均有显著的提升,而每小时单价却有下降,因而R6g实例对客户来说,有更好的性价比。
当您按本文步骤进行测试的时候,随着资源配置、数据集、测试负载的不同,需要对命令参数进行微调,测试结果也会相应变化,但测试的思路以及测试结果变化的客观规律却是共通的。除了sysbench,我们还有其他的性能测试工具,譬如mysqlslap或tpcc-mysql,本篇限于篇幅,没有介绍,在以后的blog中,我们再做介绍。
参考资料
Amazon Aurora用户指南:
https://docs.aws.amazon.com/z...
sysbench in github:
https://github.com/akopytov/s...
Amazon Graviton2:
https://aws.amazon.com/cn/ec2...
Amazon RDS for MySQL:
https://aws.amazon.com/cn/rds...
Amazon RDS for PostgreSQL:
https://aws.amazon.com/cn/rds...
Amazon RDS for MariaDB:
https://aws.amazon.com/cn/rds...
本篇作者

吕琳
亚马逊云科技数据库专家架构师
主要负责亚马逊云科技(中国)合作伙伴的技术支持工作,同时负责基于亚马逊云科技的云计算方案的咨询与架构设计,同时致力于数据库和大数据方面的研究和推广。在加入亚马逊云科技之前曾在Oracle担任高级讲师并在Amazon担任高级DBA,在数据库设计运维调优、DR解决方案、大数据以及企业应用等方面有丰富的经验。