

在Amazon Redshift的协助下,客户得以顺利完成一系列业务目标,例如从加速现有数据库环境,到提取网络日志以进行大数据分析等等。Amazon Redshift是一套全托管PB级大规模并行数据仓库,拥有极低的上手难度与出色的性能表现。Amazon Redshift还提供开放的标准JDBC/ODBC驱动程序接口,供您直接对接现有商业智能(BI)工具并复用现有分析查询方法。
- Amazon Redshift
https://aws.amazon.com/cn/red...
Amazon Redshift能够运行任意类型的数据模型,涵盖生产事务处理系统第三范式模型、星型与雪花型模型、数据仓库以及各类简单的平面表等。
本文将向大家介绍如何在应用Amazon Redshift过程中实现性能优化,并针对各类优化方式做出深入剖析及操作指导。

想要了解更多亚马逊云科技最新技术发布和实践创新,敬请关注2021亚马逊云科技中国峰会!点击图片报名吧~
内容更新
本文更新了2019年初发布的同名文章,旨在纳入一年多以来亚马逊云科技的各项最新进展,并将着重对其中要点做出阐述。
查询吞吐量比查询并发性更为重要
配置并发性(如内存管理)可以通过Automatic WLM与Query Priorities队列优先级机制将并发能力引入Amazon Redshift的内部机器学习模型。在大规模生产集群当中,我们看到自动化流程会为某些工作负载分配更多的活动语句,并对其他类型的用例分配较少活动语句。这种作法是为了最大程度提高吞吐量,保证Amazon Redshift集群能够在特定时段之内完成特定工作总量,例如实现每分钟300条查询,或者每小时处理1500条SQL语句等。本文建议大家充分利用并发机制提高吞吐量,因为吞吐量正是对集群用户具有直接影响的一类核心性能指标。
除了通过优化Automatic WLM设置实现吞吐量最大化之外,Amazon Redshift中的并发扩展功能还可以将集群的吞吐量扩展至原始集群固有吞吐量的10倍。目前Amazon Redshift将10倍设定为吞吐量的软限制,大家可以根据需求与你的客户团队联系以调整此上限。
关注Amazon Redshift驱动程序
Amazon Web Services建议大家使用Amazon Redshift JDBC或ODBC驱动程序,借此提高性能表现。每种驱动程序都对应多种可选配置,您可以进一步调整以控制语句使用量以及结果集中的具体行数。
对各类常见数据库管理任务进行自动化,借此降低使用门槛
2018年,我们曾在文章中通过排序键、编码、表维护、分发以及工作负载管理等角度探讨了性能优化方面的几大关键注意事项。自那时以来,Amazon Redshift先后添加多项自动化功能,为SET DW提供100%信息支持、将表维护纳入Amazon Web Services服务职责(不再由用户方承担),并通过智能化程度更高的默认设置增强了开箱即用性能。即使表任务随时间推移而有所变化,Amazon Redshift Advisor仍会持续监控集群以寻找各类优化机会。Amazon Web Services还发布了用于量化Amazon Redshift性能的基准方案,帮助大家轻松重现性能测试结果。
- Amazon Redshift Advisor
https://docs.aws.amazon.com/r... - 基准方案
https://github.com/awslabs/am...
使用RA3节点与Amazon Redshift Spectrum实现计算与存储资源的独立扩展
除了原本提供的Dense Compute与Dense Storage节点等便捷集群构建块之外,现在大家还可以使用其他工具进一步对计算与存储资源进行独立扩展。Amazon Redshift Managed Storage(即RA3节点家族)将帮助大家专注于调整计算资源量,而不必分神于存储容量问题。此外,并发扩展则允许我们根据实际需求,对整个集群内的其他计算资源进行调整。Amazon Redshift Spectrum使用由Amazon Simple Storage Service(Amazon S3)提供的、近乎无限的存储容量以支持按需计算层,其容量可高达主集群容量的10倍,且现已提供配套的物化视图支持选项。
- Amazon Redshift Spectrum
https://docs.aws.amazon.com/r... - Amazon Simple Storage Service
https://aws.amazon.com/cn/s3/
利用暂停与还原功能优化使用成本
现在,所有Amazon Redshift集群皆可使用暂停与还原功能。对于按需创建的集群,集群暂停操作将停止按秒计算的服务计费。预留实例集群则可通过暂停与还原功能,定义特定访问时间或在特定时间点上冻结数据集。
技巧一:使用Amazon Redshift物化视图获取预计算结果
物化视图能够极大改善高重复度、可预测型分析工作负载的查询性能,包括仪表板、商业智能工具中的查询,以及提取、加载与转换(ELT)等数据处理操作。数据工程师能够轻松轻松创建并维护一套包含物化视图的高效数据处理管道,同时将性能优势无缝扩展至各类数据分析与商业智能工具当中。
物化视图适用于需要重复执行、且结果具备一定可预测性的查询操作。应用程序可以查询物化视图中保留的预先计算数据,而不必对大型表反复执行资源密集型查询。
当基表中的数据发生变更时,您可以发出Amazon Redshift SQL语句“refresh materialized view”以刷新物化视图。在发出刷新语句之后,您的物化视图将包含与常规视图相同的数据内容。刷新可以采取增量刷新与完全刷新(重新计算)两种具体形式。Amazon Redshift还会在完成上一次物化视图刷新之后,尽可能通过增量方式刷新基表中的已变更数据。
为了演示其工作原理,我们可以创建一套示例schema以存储销售信息,包括每一项销售交易以及销售活动所在商店的详细信息。
要查看各城市的销售总额,我们使用create materialized view SQL语句(city_sales)将来自两份表中的记录join起来,借此建立起物化视图,进而汇总各个城市(group by city)的具体销售额(sum(sales.amount)):
CREATE MATERIALIZED VIEW city_sales AS
(
SELECT st.city, SUM(sa.amount) as total_sales
FROM sales sa, store st
WHERE sa.store_id = st.id
GROUP BY st.city
);现在,我们可以像查询常规视图或表那样查询这套物化视图,并发出“SELECT city, total_sales FROM city_sales”这类语句以得出以下结果。两份表单的join与聚合(sum与group by)已经预计算完成,从而大大减少了需要扫描的实际数据量。
当底层基表中的数据发生变更时,物化视图无法自动反映这些更改。您可以根据需求使用refresh materialized view SQL命令,将基表中的更改体现在物化视图中的数据处。具体参见以下代码:
!-- let's add a row in the sales base table
INSERT INTO sales (id, item, store_id, customer_id, amount)
VALUES(8, 'Gaming PC Super ProXXL', 1, 1, 3000);
SELECT city, total_sales FROM city_sales WHERE city = 'Paris'
|city |total_sales|
|-----|-----------|
|Paris| 690|
!-- the new sale is not taken into account !!
-- let's refresh the materialized view
REFRESH MATERIALIZED VIEW city_sales;
SELECT city, total_sales FROM city_sales WHERE city = 'Paris'
|city |total_sales|
|-----|-----------|
|Paris| 3690|
!-- now the view has the latest sales data关于此用例的完整代码,请参阅GitHub。
- GitHub
https://github.com
您也可以将物化视图的优势扩展到Amazon S3数据湖以及其他联合数据源中的外部数据当中。使用物化视图,我们可以轻松存储并管理由SELECT语句引用自外部表及Amazon Redshift表的预计算结果。以此为基础,一切引用物化视图的后续查询都将获得更快的运行速度,因为其使用的是存储在Amazon Redshift中的预计算结果,而不必实际访问各外部表。您也可以借此减少重复访问外部数据源带来的运营成本,保证仅在明确需要刷新物化视图时才执行此类高成本访问。
技巧二:通过并发扩展与弹性调整处理突发工作负载
传统的本地模型要求我们对系统未来三到四年之内的资源需求作出预估,借此保证在设备采购时预留充足的容量。相比之下,Amazon Web Services允许您直接调整集群大小,从而随心所欲地控制总体资源规模。具体到Amazon Redshift,我们可以通过弹性调整与并发扩展实现这一突出优势。
弹性调整的本质,在于快速增加或减少计算节点的数量(最大可将原始集群的节点数量增加一倍或者减少一半),甚至可以灵活调整节点类型。您可以扩展集群规模以获取额外的处理能力,借此适应突然增长的工作负载,例如每年大型购物季、或者支持企业内部组织的网络业务挑战赛。如果某项配置无法适配弹性调整,您还可以选择经典调整方案。经典调整的执行速度较慢,但允许您更改节点类型和节点的实际规模伸缩范围将超出弹性调整的加倍或减半限制。
弹性调整操作只需要几分钟即可完成,且无需重启集群。对于按可预测时间表出现的预期内工作负载峰值,您可以使用Amazon Redshift控制台、Amazon Web Services命令行界面(Amazon CLI)或者API中的弹性调整调度功能,实现规模调整的自动执行。
并发扩展则允许您为Amazon Redshift集群动态添加容量,借此响应当前集群中的实际工作负载水平。
在默认情况下,并发扩展选项处于禁用状态。您可以针对任意工作负载管理(WLM)队列启用并发扩展,将并发查询数量扩展至近乎无穷的水平,且保持高度一致的快速查询性能。通过将“max_concurrency_scaling_clusters”参数值从1(默认)设定为10(系统设定的软上限,您可联系支持团队以调整这一上限),大家能够快速操控集群的最大并发扩展数量。更重要的,Amazon Web Services提供的免费并发扩展配额已经足以满足大多数客户的需求,使用此项功能的用户一般不需要为此额外承担费用。关于并发扩展计费模型的更多详细信息,请参阅并发扩展费率标准。
- 并发扩展费率标准
https://aws.amazon.com/cn/red...
大家可以创建每日、每周或每月资源使用上限,借此监视并控制并发扩展功能的使用情况与使用成本,并要求Amazon Redshift在使用量达到上限时自动采取措施(例如记录日志、发布警报或禁止后续操作等)。关于更多详细信息,请参阅在Amazon Redshift中管理使用量限制。
- 在Amazon Redshift中管理使用量限制
https://docs.aws.amazon.com/r...
通过这些选项,亚马逊云科技为您带来一种对平台进行灵活调整以随时适应实际需求的全新方法。在使用这些选项之前,您需要预先确定WLM队列乃至整个Amazon Redshift集群的大小,并以此为基础为可能出现的需求峰值做好准备。
技巧三:使用Amazon Redshift Advisor降低管理负担
Amazon Redshift Advisor负责为您的Amazon Redshift集群提供优化建议,借此改善集群性能表现并降低运营成本。
Advisor提出的优化建议,以性能统计信息或对运营数据的观察结果为基础。Advisor会在集群上运行测试,借此确定观察值是否处于合理范围之内,进而整理出观察结果。一旦测试结果超出合理范围,Advisor将为当前集群生成一项观察值。此外,Advisor还将针对如何将观察值引导至合理范围内提供相应建议。Advisor只提供可能对性能及运营成本产生重大影响的建议。在确定相关建议已被采纳、问题得到解决之后,Advisor会将其从建议列表中删除。在本节中,我们将分享几个Advisor建议示例:
分配键相关建议
Advisor会分析您的集群工作负载,为各表确定最合适的分配键方式,借此提升性能表现。Advisor提供ALTER TABLE语句,根据分析结果更改表的DISTSTYLE与DISTKEY。要显著提升现有性能,请保证在建议组内使用全部SQL语句。
- ALTER TABLE
https://docs.aws.amazon.com/r...
以下截屏所示,为关于分配键的建议示例。

如果您没有收到建议,也并不代表当前分配方式已经达到最优效果。这可能意味着分析数据不足或重新分配的预期收益过低,因此Advisor决定暂不提供相关建议。
排序键相关建议
通过使用适当的排序键对表进行排序,我们可以减少需要从磁盘处读取的表数据块,借此提高查询性能。这种方法特别适用于特定范围之内的查询操作。
Advisor会分析过去几天内集群的工作负载情况,据此为表选定合适的排序键,详见以下截屏。

如果您没有收到建议,也并不代表当前配置方式已经达到最优效果。这可能意味着分析数据不足或重新排序的预期收益过低,因此Advisor决定暂不提供相关建议。
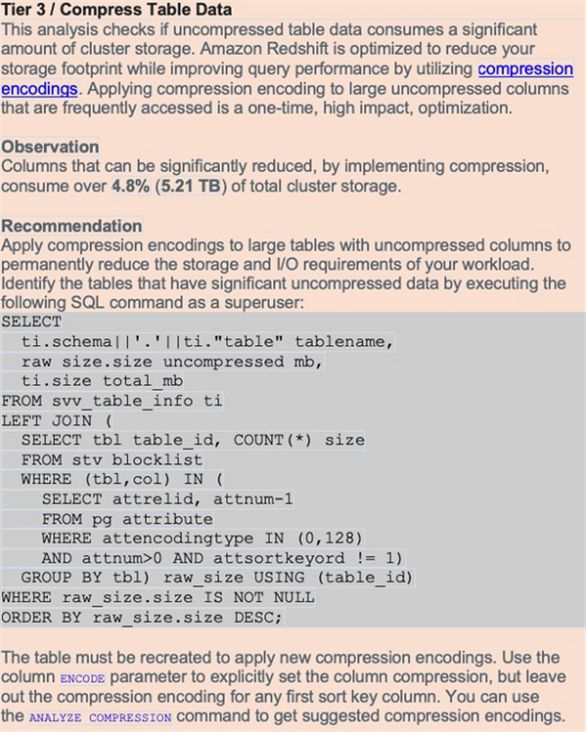
表压缩相关建议
Amazon Redshift经过优化,可通过压缩编码减少存储空间占用,同时提高查询性能。如果不使用压缩,数据将占用更多空间,且产生额外的磁盘I/O需求。对大规模未经压缩的列执行压缩处理,可能对您的集群产生显著影响。
Advisor中的压缩分析能够跟踪被分配给不可变用户表的未压缩数据,并对不属于排序键列的大型未压缩列进行元数据分配审查。
以下截屏所示,为表压缩的建议示例。
表统计相关建议
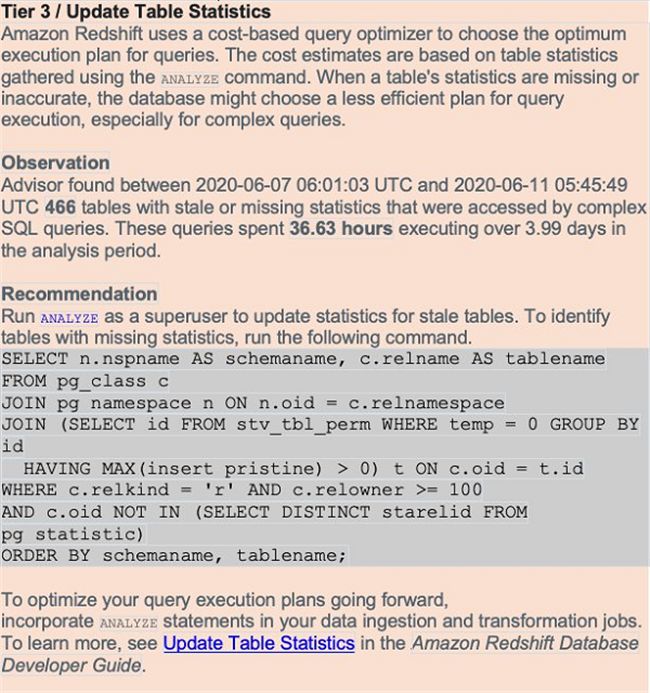
保留当前统计信息,往往有助于后续复杂查询获得更快的执行速度。Advisor分析会跟踪表中已过期或者存在缺失的统计信息,同时检查与复杂查询相关联的表访问元数据。一旦发现访问频率较高、且访问模式较为复杂的表缺少统计信息,Amazon Redshift Advisor就会创建一项重要建议以运行ANALYZE。如果此类表上的统计信息已经过期,则Advisor同样会创建对应建议以运行ANALYZE。
以下截屏所示,为表统计的示例建议。
技巧四:使用Auto WLM配合优先级机制提升吞吐量
Auto WLM使用机器学习技术对内存及并发机制进行动态管理,保证集群资源的使用方式得到充分优化,并借此简化工作负载管理流程并提升查询吞吐量。
- 工作负载管理流程
https://docs.aws.amazon.com/r...
Amazon Redshift使用队列系统(WLM)运行查询,您可以最多定义八个队列、借此将不同工作负载彼此区分开来。
Amazon Redshift Advisor能够自动分析当前WLM使用情况,并提出建议以指导您通过当前集群获取更高的吞吐量。定期查看Advisor建议,将帮助您实现集群最佳性能。
查询优先级是Auto WLM中的一项功能,可帮助您为不同用户组或查询组分配对应优先级,保证即使是在繁忙时段,高优先级工作负载仍能获得更多处理资源,借此实现统一的查询性能。本文强烈建议大家设置查询监控规则(QMR),借此监控并管理资源密集型查询或者与预期运行状态不符的失控查询。在QMR的帮助下,您还可以根据查询的运行时性能与您所定义的指标性规则,动态调整各项查询操作的优先级水平。
关于将手动WLM查询优先级转换为自动模式的更多详细信息,请参阅修改WLM配置。
这里建议大家使用Amazon Redshift提供的短查询加速(SQA)功能。SQA使用机器学习技术在自有队列中运行生命周期较短的作业,借此保证小型作业得以快速完成,而不必在队列中等待运行耗时更长的其他SQL语句。在默认情况下,默认的参数组与全部新参数组均已启用SQA。您可以通过Amazon Redshift控制台上的复选框或使用Amazon Redshift CLI,对SQA进行启用或禁用。
如果您启用了并发扩展机制,那么在工作负载开始备份时,Amazon Redshift能够自动快速配置附加集群。在确定集群的具体WLM配置方面,我们建议大家认真考虑这项因素。
一种常见的模式是对WLM配置进行优化,在无需添加内存的前提下运行更多SQL语句,借此为短查询作业保留额外的处理能力。当然,合理范围内的队列也完全可以接受,因为一旦您的需求突然增加,系统会随之添加更多附加集群。要在WLM队列上启用并发规模伸缩,请将并发扩展模式的值设定为AUTO。关于具体架构设计决策,建议您参阅并发扩展费率标准。大家也可以使用Amazon Redshift中的限制功能,监视并控制并发扩展功能的使用情况与使用成本。
- 并发扩展费率标准
https://aws.amazon.com/cn/red... - Amazon Redshift中的限制功能
https://docs.aws.amazon.com/r...
在某些情况下,对于未启用并发扩展功能的集群,其中的用户或查询分配队列可能长时间处于忙碌状态,必须等待队列中腾出新的空位。在此期间,系统将无法运行任何新的查询。一旦经常出现此类状况,大家可能必须上调并发水平。
首先,使用queuing_queries.sql管理员脚本以确定当前是否存在查询队列。使用wlm_apex.sql以查看集群以往所需要的最大并发性,或者使用wlm_apex_hourly.sql进行每小时运行记录分析。请注意,虽然上调并发行能够增加同时运行的查询总量,但每项查询所获得的内存配额也将对应减少。在实际使用中,您可能发现在上调并发性之后,某些查询必须借助临时磁盘存储才能完成,而这同样不符合性能最优化原则。
- queuing_queries.sql
https://github.com/awslabs/am... - wlm_apex.sql
https://github.com/awslabs/am... - wlm_apex_hourly.sql
https://github.com/awslabs/am...
技巧五:充分发挥Amazon Redshift数据湖的集成优势
Amazon Redshift能够与Amazon S3等其他Amazon Web Services原生服务紧密集成,帮助用户以多种方式实现Amazon Redshift集群与数据湖间的交互。
Amazon Redshift Spectrum能够通过可独立进行弹性调整的计算层,从Amazon S3中的文件处直接查询数据。单独使用这些模式,或者将多种模式组合使用,能够将工作负载转移至Amazon Redshift Spectrum计算层,借此实现数据集的快速创建、转换或聚合,同时消除传统ETL流程中的繁琐操作步骤。
- 使用Amazon Redshift Spectrum计算层分担主集群上的部分工作负载,并为特定SQL语句提供更多处理能力。Amazon Redshift Spectrum能够自动分配算力,最高可达主集群处理能力的10倍,借此帮助用户显著提升大型转换或聚合作业的执行效率。
- 跳过ETL流程中的负载,直接面向Amazon S3上的数据执行转换。您可以使用INSERT…SELECT语句对Amazon S3上的分区、列式数据支持转换逻辑。这种处理方式明显要比暂存当前数据集,将其join至其他表而后再行转换的流程简单得多。
- 使用Amazon Redshift Spectrum对Amazon S3中的数据运行查询,借此跳过向主集群加载数据的步骤,真正实现实时分析。
- 以分区、列式格式将分段或转换集群的输出结果引入Amazon S3。主集群或报告集群能够直接从该Amazon S3数据集内查询结果,并通过INSERT…SELECT语句进行快速加载。
在Amazon Redshift当中,我们可以使用UNLOAD命令或写入外部表的方式,将数据导出至数据湖内。这两种方式都能够以并发形式将SQL语句的输出结果导入Amazon S3。具体操作步骤如下:
- 使用您所熟悉的CREATE EXTERNAL TABLE AS SELECT与INSERT INTO SQL语句在Amazon S3上创建并填充外部表,以供Amazon Redshift或者甚至加入数据湖的服务后续使用,这种方式能够消除对分区的手动维护操作。物化视图亦可覆盖外部表,由此进一步增强对数据湖的访问及利用能力。
- 使用UNLOAD命令,Amazon Redshift能够以大规模并发方式将SQL语句的输出结果导出至Amazon S3。这项技术极大提高了导出性能,同时也减轻了经由主节点进行数据传输造成的性能影响。我们可以在导出数据传出Amazon Redshift集群的过程中对其进行压缩。输出数据的体积越小,这项导出功能的优势也就越明显。在将列式数据写入至数据湖的过程中,UNLOAD还能够同时写入分区感知型Parquet数据。
- CREATE EXTERNAL TABLE AS SELECT
https://docs.aws.amazon.com/r... - INSERT INTO
https://docs.aws.amazon.com/r...
技巧六:提高临时表的效率
Amazon Redshift还提供临时表功能,其作用与普通表类似,但生命周期与单一SQL会话相关联。正确使用临时表能够显著提升某些ETL操作的性能表现。与常规的永久表不同,指向临时表的数据更改不会触发Amazon S3中的自动增量备份——换言之,无需同步数据块镜像,我们即可将数据的冗余副本存储在其他计算节点之上。在此基础之上,临时表上的数据提取成本更低,执行速度也更快。也正因为如此,临时表成为承载临时存储(例如分段表)的理想选项。
大家可以使用CREATE TEMPORARY TABLE语法,或者发出SELECT … INTO #TEMP_TABLE查询以创建临时表。CREATE TABLE语句允许用户全面控制临时表的定义。SELECT … INTO and C(T)TAS命令则使用输入数据以确定列名称、大小与数据类型,并使用默认存储属性。这里要提醒大家认真考虑是否应使用默认存储属性,以防引起意外影响。在默认情况下,Amazon Redshift会在临时表内以非列编码(例如RAW压缩)的方式全面执行EVEN表分配,而这一数据结构实际并不适合很多常见的查询类型。
- CREATE TEMPORARY TABLE
https://docs.aws.amazon.com/r... - SELECT … INTO #TEMP_TABLE查询
https://docs.aws.amazon.com/r...
如果您使用SELECT…INTO语法,则无法设置列编码、列分配或者排序键。相反,您只能使用CREATE TABLE AS(CTAS)语法以指定分配样式与排序键,这时Amazon Redshift会自动在除排序键、布尔值、实数以及双精度数以外的所有内容中应用LZO编码。当然,大家也可以直接使用CREASTE TABLE语法(不包括CTAS)以实现其他控制。
如果需要创建临时表,请注意将所有SELECT…INTO语法转换为CREATE语句,借此保证您的临时表内包含列编码,且不致在工作流中引发分配错误。例如,您可以使用以下语法进行语句转换:
SELECT column_a, column_b INTO #my_temp_table FROM my_table;您需要分析临时表以实现列编码优化:
Master=# analyze compression #my_temp_table;
Table | Column | Encoding
----------------+----------+---------
#my_temp_table | columb_a | lzo
#my_temp_table | columb_b | bytedict
(2 rows)接下来,您可以将SELECT INTO语句转换为以下形式:
BEGIN;
CREATE TEMPORARY TABLE my_temp_table(
column_a varchar(128) encode lzo,
column_b char(4) encode bytedict)
distkey (column_a) -- Assuming you intend to join this table on column_a
sortkey (column_b) -- Assuming you are sorting or grouping by column_b
;
INSERT INTO my_temp_table SELECT column_a, column_b FROM my_table;
COMMIT;如果您使用CREATE TABLE LIKE语句创建一个临时分段表,则该分段表将从父目标表处继承分配键、排序键与列编码。在这种情况下,由于各行被join合并,因此分段与目标表将被join至同一分配键上,执行速度也由此加快。若要验证查询是否使用合并join,请使用EXPLAIN运行查询,并检查所有joins上的DS_DIST_NONE。
大家可能还需要分析临时表上的统计信息,特别是在将临时表作为join表以供后续查询的情况下。详见以下代码:
ANALYZE my_temp_table;
使用此项技巧,您可以保留临时表的功能,同时通过分配键控制数据在集群上的放置位置。此外,您还可以通过列编码发挥Amazon Redshift的列属性优势。
技巧七:使用QMR与Amazon CloudWatch指标以驱动其他性能改进
除了Amazon Redshift Advisor建议之外,大家也可以通过其他渠道获取性能洞见结论。
无论大家是否在集群上制定有规则,Amazon Redshift集群都会持续自动为查询监控规则收集指标。通过这一便捷的设定,您可以轻松查看以下属性:
- 某一SQL语句的CPU时间 (query_cpu_time)
- 某一作业可能“溢出至磁盘”的临时空间占用量(query_temp_blocks_to_disk)
- 读取的最大数据块数量与平均值之比 (io_skew)
这项设定还提供Amazon Redshift Spectrum指标,例如某项查询中涉及的Amazon Redshift Spectrum行数以及MB数(分别为spectrum_scan_row_count和spectrum_scan_size_mb、respectively)。Amazon Redshift系统的SVL_QUERY_METRICS_SUMMARY视图会显示已完成各查询的指标最大值,STL_QUERY_METRICS与STV_QUERY_METRICS视图则以1秒为间隔显示已完成以及正在运行中的查询信息。
- SVL_QUERY_METRICS_SUMMARY
https://docs.aws.amazon.com/r... - STL_QUERY_METRICS
https://docs.aws.amazon.com/r... - STV_QUERY_METRICS
https://docs.aws.amazon.com/r...
Amazon Redshift CloudWatch指标作为Amazon CloudWatch监控功能所使用的数据点。CloudWatch指标可覆盖集群范围,例如运行情况、读取/写入、IOPS、延迟或吞吐量;也可以提供计算节点层级的数据,例如网络发送/接收吞吐量以及读取/写入延迟。在WLM队列这一监控力度下,我们还可查看每秒完成的查询数量、队列长度等。CloudWatch还会通过ConcurrencyScalingSeconds与ConcurrencyScalingActiveClusters等指标协助用户监控并发扩展功能的使用情况。
在投入时间创建新内容前,我们建议大家首先认真核查各项CloudWatch指标(及以这些指标为基础建立的现有通知架构)。同样的,QMR指标也能涵盖大部分指标用例,多数用户可以直接使用,无需单独编写自定义指标。
- Amazon Redshift CloudWatch
https://docs.aws.amazon.com/r...
技巧八:串连OLAP、OLTP与数据湖执行联合查询
Amazon Redshift中新增的联合查询功能,允许您直接针对OLTP源系统数据库与Amazon S3数据湖上的实时数据执行分析操作,整个过程无需执行任何ETL、也不需要将源数据库提取至Amazon Redshift表内。作为一项快捷高效的选项,这项功能能够在运营报告上提供实时数据可见性,从而替代将少量ETL批处理实时数据导入数据仓库的传统方法。通过将数据仓库中的历史趋势数据,与源系统中的实时使用趋势相结合,我们可以整理出有价值洞见,据此驱动实时业务决策。
例如,我们假定销售数据分别存储在三套不同的数据存储体系当中:
实时销售数据存储在Amazon RDS for PostgreSQL数据库上(在以下外部schema中表示为“ext_postgres”)。
历史销售数据存储在本地Amazon Redshift数据库上(表示为“local_dwh”)。
5年以上的已归档“冷”销售数据存储在Amazon S3上(表示为“ext_spectrum”)。
- Amazon RDS for PostgreSQL
https://aws.amazon.com/rds/po...
我们可以在Amazon Redshift上创建后期绑定视图,借此合并及查询来自所有三个来源处的数据。具体参见以下代码:
CREATE VIEW store_sales_integrated AS
SELECT * FROM ext_postgres.store_sales_live
UNION ALL
SELECT * FROM local_dwh.store_sales_current
UNION ALL
SELECT ss_sold_date_sk, ss_sold_time_sk, ss_item_sk, ss_customer_sk, ss_cdemo_sk,
ss_hdemo_sk, ss_addr_sk, ss_store_sk, ss_promo_sk, ss_ticket_number, ss_quantity,
ss_wholesale_cost, ss_list_price, ss_sales_price, ss_ext_discount_amt,
ss_ext_sales_price, ss_ext_wholesale_cost, ss_ext_list_price, ss_ext_tax,
ss_coupon_amt, ss_net_paid, ss_net_paid_inc_tax, ss_net_profit
FROM ext_spectrum.store_sales_historical
WITH NO SCHEMA BINDING目前,对于存储在Amazon Aurora PostgreSQL与Amazon RDS for PostgreSQL数据库内的数据,我们可以直接进行联合查询。后续Amazon Web Services还将推出面向其他主要RDS引擎的支持功能。大家还可以使用联合查询功能,简化ETL与数据输入过程。联合查询将帮助您在CTAS/INSERT SQL联合查询当中通过一步操作,将数据直接摄取至Amazon Redshift表当中,而不再需要将数据暂存在Amazon S3上再执行COPY操作。
- Amazon Aurora PostgreSQL
https://aws.amazon.com/cn/rds...
例如,以下代码所示为一项upsert/merge操作,其中将由Amazon S3到Amazon Redshift的COPY操作直接替换为以PostgreSQL为源的联合查询:
BEGIN;
CREATE TEMP TABLE staging (LIKE ods.store_sales);
-- replace the following COPY from S3:
/*COPY staging FROM 's3://yourETLbucket/daily_store_sales/'
IAM_ROLE 'arn:aws:iam:::role/'
DELIMITER '|' COMPUPDATE OFF; */
-- with this federated query to load staging data directly from PostgreSQL source
INSERT INTO staging SELECT * FROM pg.store_sales p
WHERE p.last_updated_date > (SELECT MAX(last_updated_date) FROM ods.store_sales);
DELETE FROM ods.store_sales USING staging s WHERE ods.store_sales.id = s.id;
INSERT INTO ods.store_sales SELECT * FROM staging;
DROP TABLE staging;
COMMIT; 关于设置以上联合查询的更多详细信息,请参阅使用Amazon Redshift联合查询简化ETL与实时数据查询解决方案。关于联合查询的其他技巧与最佳实践,请参阅Amazon Redshift联合查询最佳实践。
- 使用Amazon Redshift联合查询简化ETL与实时数据查询解决方案
https://aws.amazon.com/cn/blo... - Amazon Redshift联合查询最佳实践
https://aws.amazon.com/cn/blo...
技巧九:保持高效的数据加载
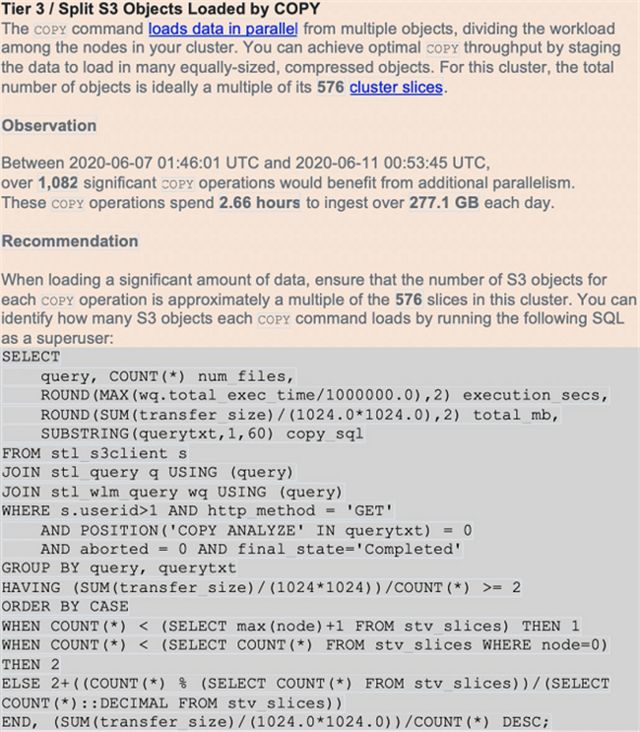
Amazon Redshift最佳实践建议大家使用COPY命令执行基于文件的数据加载。但单行INSERT属于反模式用例。COPY操作能够使用集群中的所有计算节点,从Amazon S3、Amazon DyanmoDB、Amazon EMR HDFS文件系统或者任意SSH连接等来源实现数据的并行加载。
在执行数据加载时,请尽可能对数据文件进行压缩。对于面向行(CSV)的数据,Amazon Redshift支持GZIP与LZO压缩。加载大量小文件的执行效率,要高于加载单一大型文件,因此最理想的文件数量应是集群总分片数量的整数倍。此外,Amazon Redshift还支持Pqrquet及ORC等列式数据。当压缩文件的大小在1 MB到1 GB之间时,即可实现最佳加载性能。
每个节点的分片数量,取决于集群中的实际节点大小(以及可能的弹性调整历史记录)。通过保证各个分片上的文件数量相等,即可引导COPY命令平均使用集群资源并尽快完成加载操作。您可以使用SELECT COUNT(*)AS number_of_slices FROM stv_slices;查询集群的当前分片数量。
由amazon-redshift-utils GitHub repo提供的另一个脚本,CopyPerformance,能够计算每项加载操作的统计信息。Amazon Redshift Advisor还会根据实际分片数量,就压缩缺失或文件数量过低问题发出警报(详见以下截屏):
- amazon-redshift-utils
https://github.com/awslabs/am... - CopyPerformance
https://github.com/awslabs/am...
执行COPY操作能够有效减少下游用户获取结果的等待时长,并最大程度减少用于执行加载操作的集群资源。
技巧十:使用亚马逊云科技提供的最新Amazon Redshift驱动程序
由于Amazon Redshift以PostgreSQL为基础设计而来,因此我们之前建议大家使用JDBC4 PostgreSQL驱动程序8.4.703版本以及psql ODBC 9.x版本驱动程序。但如果您目前仍在使用这些驱动程序,我们建议您升级至Amazon Redshift的新型专用驱动程序。关于驱动程序与连接配置的更多详细信息,请参阅《Amazon Redshift集群管理指南》中的用于Amazon Redshift的JDBC与ODBC驱动程序部分。
- Amazon Redshift集群管理指南
https://docs.aws.amazon.com/r... - JDBC
https://docs.aws.amazon.com/r... - ODBC
https://docs.aws.amazon.com/r...
尽管几率很低,但大家偶尔可能需要对Amazon Redshift驱动程序中的某些参数做出调整。下游第三方应用程序通常也制定有自己的驱动程序优化最佳实践,能够进一步提升系统的整体性能。
对于JDBC,请参考以下最佳实践:
1.为了避免在使用JDBC检索大型数据集时,出现客户端内在不足的错误,我们可以设置JDBC fetch size参数或BlockingRowsMode的方式,让客户端批量获取数据。
2.Amazon Redshift无法识别JDBC maxRows参数。相反,请指定LIMIT子句以限制结果集。大家还可以使用OFFSET子句跳转至结果集中的特定起点。
- 设置JDBC fetch size参数
https://docs.aws.amazon.com/r... - LIMIT
https://docs.aws.amazon.com/r... - OFFSET
https://docs.aws.amazon.com/r...
对于ODBC,请参考以下最佳实践:
1.在启用useDelareFetch时,会在集群的主节点上启用一个指针。该指针将提取fetchsize/cursorsize,并在应用程序请求更多行时协助执行提取操作。
2.CURSOR命令是一条用于操纵主节点上指针行为的显式指令。与JDBC驱动程序不同,ODBC驱动程序不提供BlockingRowsMode机制。
除非您有明确需求,否则请不要调整驱动程序。Amazon Web Services Support将为您提供与此相关的更多帮助信息。
总结
Amazon Redshift是一套功能强大的全托管数据仓库,能够在云端提供更好的性能表现与更低的运营成本。随着Amazon Redshift在全球数以万计活跃客户的使用与反馈下不断发展壮大,其易用性、扩展性以及性价比也得到持续增强。通过这些改进,您能够从这项核心亚马逊云科技服务当中获得更多价值,并不断降低时间与精力投入。
希望本文能够为大家在充分发挥Amazon Redshift各项优势的尝试中,带来一点指引与启发。
如果您有任何疑问或建议,请在评论区中与我们交流。
本篇作者

Matt Scaer
亚马逊云科技首席数据仓库
专业解决方案架构师
他在亚马逊云科技与Amazon.com拥有超过11年的从业经验。

Manish Vaziran
亚马逊云科技分析
专业解决方案架构师

Tarun Chaudhary
亚马逊云科技分析
专业解决方案架构师