大家好,我是查理~
昨晚,刚刚王力宏终于回应了。
今天干脆手把手教大家如何数据处理+可视化他的微博评论,下载完整代码/数据见文末。
12月15日,王力宏在微博突然宣布离婚,表示“靓蕾和我的私生活很简单很单纯,所以不会再回应任何媒体”,结束了8年的婚姻。
12月17日深夜,王力宏前妻李靓蕾突然发文,表示长期被王力宏及其家人羞辱和冷暴力,同时还曝出王力宏婚内出轨、私生活混乱等不为人知的事件,使得王力宏多年来的“优质男星”形象岌岌可危。
文章一经发出,引发热议,王力宏长期以来的“优质偶像”形象备受质疑,不少网友在李靓蕾的微博下留言表示,“好难过,太失望了”“王力宏在我心中的形象坍塌了”。
今天就带大家用数据——吃吃瓜。
我使用Python编程,爬取王力宏宣布离婚的微博下的评论。

下载的csv文件中包括用户名、用户id、评论创建时间、评论id、评论内容等。

如上图所示,原始数据中的内容非常混乱,微博评论中夹杂大量表情包、话题以及“转发微博”等等,需要进行数据清洗。
首先根据评论的唯一ID进行去重
df_1 = df_1.drop_duplicates(['idstr']).iloc[:,1:]接着,对所有的微博评论按照小时计数
df_1['created_date'] = pd.to_datetime(df_1['created_date'])df_1_date = df_1.groupby([pd.Grouper(key='created_date',freq='H')]).size().reset_index(name='count')
得到分时数据后,就可以使用Matplotlib绘制折线图。
columns = df_date.columnsfig = plt.figure(figsize=(10, 5), dpi=100)plt.fill_between(df_date['created_date'].values, y1=df_date['count_x'].values, y2=0, label='王力宏微博新增评论数/小时', alpha=0.75, facecolor="#43a9cb", linewidth=1, edgecolor='k')plt.xlabel("Date")plt.ylabel("Value")plt.legend(loc='upper right')plt.show()fig.savefig('王力宏.png')输出结果如下所示
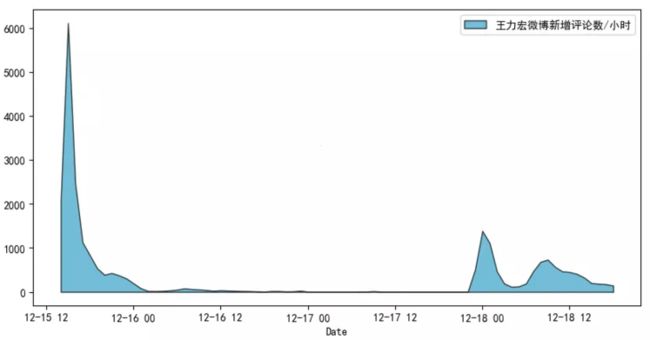
15日时刚刚发布微博,瞬间引爆评论,火速上热搜。
16、17日便没有什么评论了。
直到昨晚23点,前妻李靓蕾深夜发文后,群众们赶紧冲过来开团。
PS:除了吃瓜群众,速度最快的应该是英菲尼迪。
12月16日14时,豪华汽车品牌英菲尼迪才刚刚官宣王力宏成为品牌代言人。18日凌晨1点22分,微博名为@英菲尼迪中国 便发布声明英菲尼迪决定即日起终止与王力宏先生的合作关系。英菲尼迪从和他签约到解约,仅有35小时。
如果我们将王力宏和李靓蕾的微博评论数量,放在一张图会是什么样子呢?
正好我也爬了李靓蕾的微博评论,同样进行数据处理后
columns = df_date.columnsfig = plt.figure(figsize=(10, 8), dpi=100)plt.fill_between(df_date['created_date'].values, y1=df_date['count_x'].values, y2=0, label='王力宏微博新增评论数/小时', alpha=0.75, facecolor="#43a9cb", linewidth=1, edgecolor='k')plt.fill_between(df_date['created_date'].values, y1=df_date['count_y'].values, y2=0, label='李靓蕾微博新增评论数/小时', alpha=0.75, facecolor="#b7ba6b", linewidth=1, edgecolor='k')plt.xlabel("Date")plt.ylabel("Value")plt.legend(loc='upper left')plt.show()输出结果如下所示:
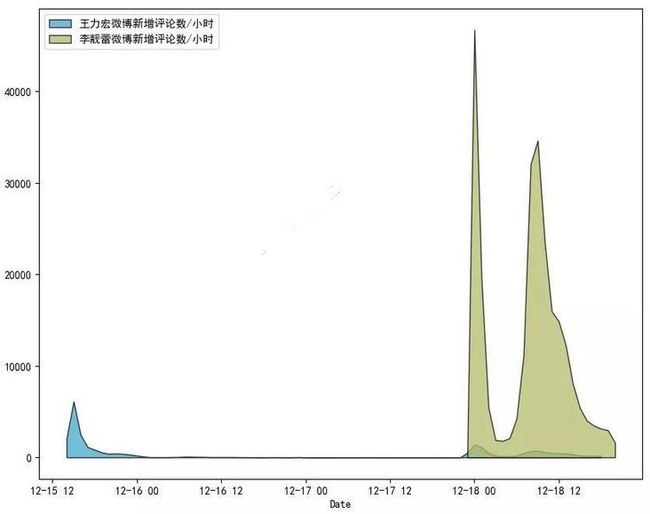
相比之下,王力宏这边的评论就根本不是一个量级,显得是“弟中之弟”了。
吃瓜群众原来全部涌向了李靓蕾的微博。
这次我们还是想盘点一下:群众们开团后,都发了些什么?
与之前文章传统的词云图不一样,我打算玩点新东西。在前文中制作的折线面积图中,将不同时间段的词云填充其中。
很多小伙伴比较好奇怎么做的,其实就是ps将前文的折线图和生成的词云图层叠加。如果你要问Python能不呢做到图层覆盖,我的回答是可以但没必要。
做词云图前,需要将所有王力宏的微博评论分成两部分(即前妻开锤前后),注意下方代码中以2021-12-17 23:08:00"为界。
def get_cut_words(content_series): # 读入停用词表 import jieba stop_words = [] with open("stop_words.txt", 'r', encoding='utf-8') as f: lines = f.readlines() for line in lines: stop_words.append(line.strip()) # 添加关键词 my_words = ['分分合合', '拉黑'] for i in my_words: jieba.add_word(i) # 自定义停用词 my_stop_words = ['快转','转发','微博'] stop_words.extend(my_stop_words) # 分词 word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False) # 条件筛选 word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2] return word_num_selectedtext1 = get_cut_words(content_series=df_1[df_1["created_date"] < "2021-12-17 23:08:00"]['text1'])
接着准备两个蒙版(取自前面得到的折线图)

词云图的代码详细大家都很熟悉了,这里只需注意一点。
background_color='white'# 改为background_color=None,mode='RGBA',这样就可以将词云图的背景色设置为透明,从而方便图层叠加。

这样我们就可以制作如下所示的图了

在前妻李靓蕾曝光前,王力宏的微博评论下基本都是这样的:“结婚是为了幸福,离婚也是”、“情人总分分合合”、“尊重二哥的选择”。
曝光后,王力宏的微博评论下变成了这样:“重新定义简单单纯”、“渣男”、“下头”、“私生活简单?你侮辱了简单这个词”、“人设崩塌”。

PS:愤怒的吃瓜群众还输出了很多“脏话”,我在词云图里做了排除。
我们再换个方向,娱乐一下。
我决定用数据探究一下:吃瓜的猹们最爱发哪些表情呢?
我提取了10万条评论中的emoji表情,先提取微博评论可以使用的emoji的所有名称(此处仅展示一部分)。
emoji_list = ["[小红花]","[微笑]","[可爱]","[太开心]","[鼓掌]","[嘻嘻]","[哈哈]","[笑cry]","[挤眼]","[馋嘴]","[黑线]","[汗]","[挖鼻]","[哼]","[怒]","[委屈]","[可怜]","[失望]","[悲伤]","[泪]","[允悲]"]使用in判断是否包含某个emoji
def emoji_lis(string): entities = [] for i in emoji_list: if i in string: entities.append(i) return entitiesemoji_s = []for index, row in df_1.iterrows(): text = str(row['text']) emoji_s.extend(emoji_lis(text)) c = collections.Counter(emoji_s)print(c)即可得到各emoji出现的次数:

同样还是使用使用Matplotlib绘制极坐标图

输出结果如下所示:
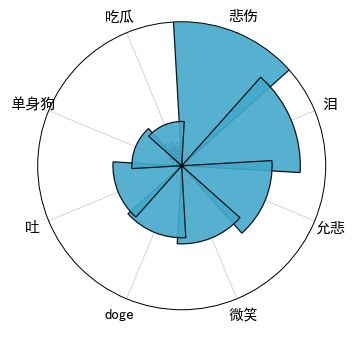
匹配采集到评论中的表情后,按照出现次数选取前8名,并将其制作成极坐标图。
发现前8名的表情是:悲伤、泪、允悲、微笑、doge、吐、单身狗、吃瓜。
王力宏自出道便顶着“优质偶像”的名头,家境良好、才华横溢、长相端正,出道多年更是鲜有负面出现。如今看来,优质的表皮只是假面,他千挑万选找了一个最好拿捏的妻子,却又在她多年的忍让中得寸进尺,变本加厉。
如同李靓蕾长文所说“如果你的演艺事业有受影响,是你自己做出的种种选择造成的,不是我。”