前言:
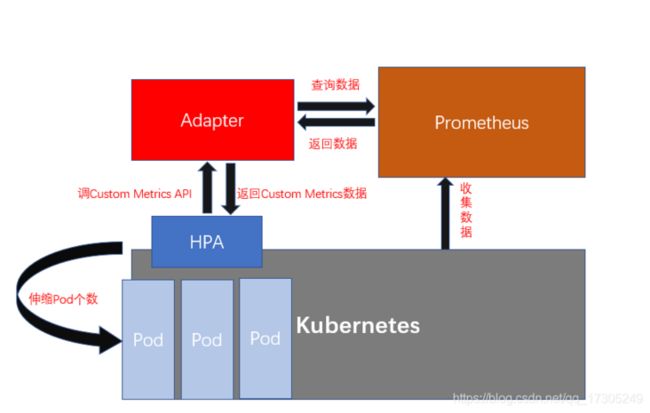
prometheus:prometheus能够收集各种维度的资源指标,比如CPU利用率,网络连接的数量,网络报文的收发速率,包括进程的新建及回收速率等等,能够监控许许多多的指标,而这些指标K8S早期是不支持的,所以需要把prometheus能采集到的各种指标整合进k8s里,能让K8S根据这些指标来判断是否需要根据这些指标来进行pod的伸缩。
kube-prometheus-adapter简介
prometheus既作为监控系统来使用,也作为某些特殊的资源指标的提供者来使用。但是这些指标不是标准的K8S内建指标,称之为自定义指标,但是prometheus要想将监控采集到的数据作为指标来展示,则需要一个插件,这个插件叫kube-prometheus-adapter,这些指标判断pod是否需要伸缩的基本标准,例如根据cpu的利用率、内存使用量去进行伸缩。
HPA简介
HPA(Horizontal Pod Autoscaler)Pod自动弹性伸缩,K8S通过对Pod中运行的容器各项指标(CPU占用、内存占用、网络请求量)的检测,实现对Pod实例个数的动态新增和减少。
其中 v1版本只能基于观测核心指标进行Pod自动弹性伸缩,v2版可以实现自定义指标的自动弹性伸缩,当业务负载上升超过HPA设定值,创建新的Pod保障业务对资源的需求,当负载下载后可以通过销毁Pod是否资源来提高利用率。
HPA 依赖 metrics-server 获取的核心指标。所以我们要先安装 metrics-server 插件
metrics-server
metrics-server 通过kubelet(cAdvisor)获取监控数据,主要作用是为kube-scheduler,HPA等k8s核心组件,以及kubectl top命令和Dashboard等UI组件提供数据来源。
在新一代的K8S指标监控体系当中主要由核心指标流水线和监控指标流水线组成:
核心指标流水线:是指由kubelet、metrics-server以及由API server提供的api组成;CPU的累积使用率、内存实时使用率,Pod资源占用率以及容器磁盘占用率等等。
监控流水线:用于从系统收集各种指标数据并提供给终端用户、存储系统以及HPA,包含核心指标以及其他许多非核心指标。非核心指标本身不能被K8S所解析。所以需要kube-prometheus-adapter` 插件 将prometheus采集到的数据转化为k8s能理解的格式,为k8s所使用。。
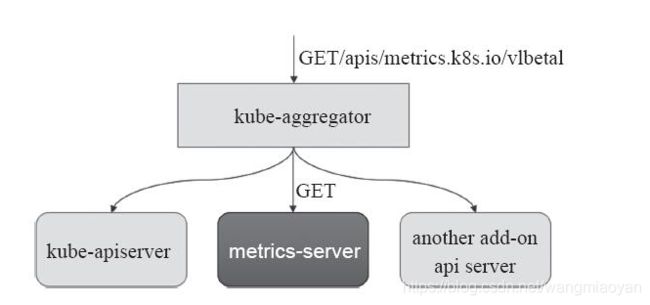
metrics-server通过 Kubernetes 聚合 器 kube-aggregator注册 到 主 API Server 之上, 而后 基于 kubelet 的 Summary API 收集 每个 节 点上 的 指标 数据, 并将 它们 存储 于 内存 中 然后 以 指标 API 格式 提供,如下图:
metrics-server基于 内存 存储, 重 启 后 数据 将 全部 丢失, 而且 它 仅能 留存 最近 收集 到 的 指标 数据, 因此, 如果 用户 期望 访问 历史 数据, 就不 得不 借助于 第三方 的 监控 系统( 如 Prometheus 等)。
- 部署
metrics-server
[下载官方yaml链接
](https://github.com/kubernetes...) kubectl top命令用到的就是metrics-server核心指标 因为还没有部署所以是抓取不到指标
[root@k8s-master prometheus]# kubectl top node error: Metrics API not available [root@k8s-master prometheus]# kubectl top pod error: Metrics API not available [root@k8s-master prometheus]# kubectl top pod -n kube-system error: Metrics API not available [root@k8s-master prometheus]# wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml^C [root@k8s-master prometheus]# kubectl apply -f components.yaml [root@k8s-master prometheus]# kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-5f6cfd688c-89nxp 1/1 Running 20 19d calico-node-6qr5r 1/1 Running 0 19d calico-node-dgxnz 1/1 Running 0 19d calico-node-gdmt7 1/1 Running 0 19d calico-node-jdf7d 1/1 Running 0 19d coredns-f9fd979d6-2fn6w 1/1 Running 0 19d coredns-f9fd979d6-sq44h 1/1 Running 0 19d etcd-k8s-master 1/1 Running 3 19d kube-apiserver-k8s-master 1/1 Running 0 19d kube-controller-manager-k8s-master 1/1 Running 0 19d kube-proxy-bh6k7 1/1 Running 0 19d kube-proxy-qw6lb 1/1 Running 0 19d kube-proxy-t2n7z 1/1 Running 0 19d kube-proxy-v2t9j 1/1 Running 0 19d kube-scheduler-k8s-master 1/1 Running 0 8d metrics-server-9f459d97b-f4ggw 0/1 Running 0 33m [root@k8s-master prometheus]# kubectl describe pod metrics-server-9f459d97b-f4ggw -n kube-system #报错证书认证有问题 E0918 09:50:33.463133 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.4.170:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.4.170 because it doesn't contain any IP SANs" node="k8s-master" E0918 09:50:33.543733 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.4.173:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.4.173 because it doesn't contain any IP SANs" node="k8s-node3" E0918 09:50:33.558163 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.4.171:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.4.171 because it doesn't contain any IP SANs" node="k8s-node1"修改yaml文件 重新部署
[root@k8s-master prometheus]# vim components.yaml apiVersion: apps/v1 kind: Deployment ...... spec: containers: - args: - --cert-dir=/tmp - --secure-port=443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port - --metric-resolution=15s - --kubelet-insecure-tls #不验证证书 [root@k8s-master prometheus]# kubectl delete -f components.yaml s [root@k8s-master prometheus]# kubectl apply -f components.yaml [root@k8s-master prometheus]# kubectl get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-5f6cfd688c-89nxp 1/1 Running 20 19d 192.168.237.2 k8s-mastercalico-node-6qr5r 1/1 Running 0 19d 192.168.4.173 k8s-node3 calico-node-dgxnz 1/1 Running 0 19d 192.168.4.172 k8s-node2 calico-node-gdmt7 1/1 Running 0 19d 192.168.4.171 k8s-node1 calico-node-jdf7d 1/1 Running 0 19d 192.168.4.170 k8s-master coredns-f9fd979d6-2fn6w 1/1 Running 0 19d 192.168.237.1 k8s-master coredns-f9fd979d6-sq44h 1/1 Running 0 19d 192.168.237.3 k8s-master etcd-k8s-master 1/1 Running 3 19d 192.168.4.170 k8s-master kube-apiserver-k8s-master 1/1 Running 0 19d 192.168.4.170 k8s-master kube-controller-manager-k8s-master 1/1 Running 0 19d 192.168.4.170 k8s-master kube-proxy-bh6k7 1/1 Running 0 19d 192.168.4.173 k8s-node3 kube-proxy-qw6lb 1/1 Running 0 19d 192.168.4.172 k8s-node2 kube-proxy-t2n7z 1/1 Running 0 19d 192.168.4.170 k8s-master kube-proxy-v2t9j 1/1 Running 0 19d 192.168.4.171 k8s-node1 kube-scheduler-k8s-master 1/1 Running 0 8d 192.168.4.170 k8s-master metrics-server-766c9b8df-zpt94 1/1 Running 0 61s 192.168.51.88 k8s-node3 top命令已经可以获取到指标
[root@k8s-master ~]# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master.org 228m 11% 2248Mi 58% k8s-node1.org 200m 5% 2837Mi 36% k8s-node2.org 218m 5% 2703Mi 34% k8s-node3.org 280m 7% 4184Mi 53% [root@k8s-master ~]# kubectl top pod -n kube-system NAME CPU(cores) MEMORY(bytes) calico-kube-controllers-74b8fbdb46-qhsn4 5m 69Mi calico-node-8bwfr 25m 126Mi calico-node-cc765 35m 151Mi calico-node-fwdm2 35m 124Mi calico-node-gdtvh 35m 140Mi calico-typha-686cfb8bb6-h9vtf 2m 27Mi coredns-7f6cbbb7b8-f9b8t 2m 35Mi coredns-7f6cbbb7b8-vqmqj 2m 30Mi etcd-k8s-master.org 15m 141Mi kube-apiserver-k8s-master.org 69m 844Mi kube-controller-manager-k8s-master.org 11m 123Mi kube-proxy-9m94r 1m 26Mi kube-proxy-btbxx 5m 37Mi kube-proxy-d2f7r 1m 46Mi kube-proxy-jrvds 6m 27Mi kube-scheduler-k8s-master.org 3m 56Mi metrics-server-5b6dd75459-c8rmt 4m 19Mikube-prometheus-adapter部署
前面提到过
prometheus既作为监控系统来使用,也作为某些特殊的资源指标的提供者来使用。但是这些指标不是标准的K8S内建指标,称之为自定义指标,但是prometheus要想将监控采集到的数据作为指标来展示,则需要一个插件,这个插件叫kube-prometheus-adapter,这些指标判断pod是否需要伸缩的基本标准,例如根据cpu的利用率、内存使用量去进行伸缩。- helm 安装部署
prometheus-adapter
[root@k8s-master ~]# helm search repo prometheus-adapter
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/prometheus-adapter 2.17.0 v0.9.0 A Helm chart for k8s prometheus adapter
stable/prometheus-adapter 2.5.1 v0.7.0 DEPRECATED A Helm chart for k8s prometheus adapter
[root@k8s-master prometheus-adapter]# helm pull prometheus-community/prometheus-adapter #chart下载到本地
[root@k8s-master ~]# helm show values prometheus-community/prometheus-adapter #检查默认配置根据实际情况修改查看
prometheus svc确定连接地址[root@k8s-master ~]# kubectl get svc -n monitor NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus-adapter ClusterIP 10.96.61.209443/TCP 27m prometheus-alertmanager ClusterIP 10.111.88.56 80/TCP 30h prometheus-kube-state-metrics ClusterIP 10.111.190.243 8080/TCP 30h prometheus-node-exporter ClusterIP None 9100/TCP 30h prometheus-pushgateway ClusterIP 10.103.67.173 9091/TCP 30h prometheus-server ClusterIP 10.111.189.44 80/TCP 30h 修改
prometheus-adapter连接的prometheus svc[root@k8s-master prometheus-adapter]# vim values.yaml prometheus: # Value is templated url: http://prometheus-server.monitor.svc.cluster.local port: 80 path: ""安装
prometheus-adapter[root@k8s-master prometheus]# helm install prometheus-adapter prometheus-adapter -n monitor NAME: prometheus-adapter LAST DEPLOYED: Sun Sep 19 22:23:41 2021 NAMESPACE: monitor STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: prometheus-adapter has been deployed. In a few minutes you should be able to list metrics using the following command(s): kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 [root@k8s-master prometheus]# kubectl get pod -n monitor -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES prometheus-adapter-5d4864b5c6-tl6wb 1/1 Running 0 41s 192.168.113.86 k8s-node1prometheus-alertmanager-5775f494fc-n5t9j 2/2 Running 0 15h 192.168.12.89 k8s-node2 prometheus-kube-state-metrics-696cf79768-v2m6f 1/1 Running 0 15h 192.168.51.93 k8s-node3 prometheus-node-exporter-489sz 1/1 Running 2 30h 192.168.4.171 k8s-node1 prometheus-node-exporter-6k67l 1/1 Running 0 30h 192.168.4.173 k8s-node3 prometheus-node-exporter-pmvdb 1/1 Running 0 30h 192.168.4.172 k8s-node2 prometheus-pushgateway-9fd8fbf86-p9thk 1/1 Running 0 15h 192.168.51.94 k8s-node3 prometheus-server-7d54f5bcbc-md928 2/2 Running 0 15h 192.168.12.90 k8s-node2 抓取指标 各种 指标 节点 容器 容器内部应用程序的指标等
[root@k8s-master prometheus]# kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1|jq . { "kind": "APIResourceList", "apiVersion": "v1", "groupVersion": "custom.metrics.k8s.io/v1beta1", "resources": [ { "name": "namespaces/kube_pod_container_status_restarts", "singularName": "", "namespaced": false, "kind": "MetricValueList", "verbs": [ "get" ] }, { "name": "namespaces/memory_mapped_file", "singularName": "", "namespaced": false, "kind": "MetricValueList", "verbs": [ "get" ] }, { "name": "namespaces/kube_deployment_spec_strategy_rollingupdate_max_unavailable", "singularName": "", "namespaced": false, "kind": "MetricValueList", "verbs": [ "get" ] }, ...查看name值 默认只会暴露一些常规指标
[root@k8s-master prometheus]# kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1|jq '.resources[].name' "pods/fs_reads_bytes" "namespaces/spec_cpu_period" "jobs.batch/kube_deployment_status_replicas_available" "namespaces/kube_persistentvolumeclaim_resource_requests_storage_bytes" "namespaces/kube_pod_container_status_running" "namespaces/kube_pod_start_time" "secrets/kube_ingress_tls" "namespaces/kube_pod_completion_time" "jobs.batch/kube_pod_container_status_restarts" "namespaces/kube_deployment_spec_strategy_rollingupdate_max_unavailable" "jobs.batch/kube_daemonset_status_updated_number_scheduled" "jobs.batch/kube_poddisruptionbudget_status_pod_disruptions_allowed" "pods/fs_usage_bytes" "jobs.batch/kube_daemonset_metadata_generation" "jobs.batch/kube_pod_owner" "namespaces/kube_pod_container_status_restarts" "jobs.batch/kube_deployment_metadata_generation" "jobs.batch/kube_ingress_path" "namespaces/kube_job_owner"并没有自己想要的自定义指标
[root@k8s-master prometheus]# kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1|grep "http_requests_per_second" [root@k8s-master prometheus]# kubectl get cm -n monitor NAME DATA AGE prometheus-adapter 1 37h prometheus-alertmanager 1 2d19h prometheus-server 5 2d19h暴露自定义指标需要自己定义rule
[root@k8s-master prometheus]# kubectl edit cm prometheus-adapter -n monitor apiVersion: v1 data: config.yaml: | rules: - seriesQuery: '{__name__=~"^container_.*",container!="POD",namespace!="",pod!=""}' seriesFilters: [] resources: overrides: namespace: resource: namespace pod: resource: pod name: matches: ^container_(.*)_seconds_total$ as: "" metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container!="POD"}[5m])) by (<<.GroupBy>>) - seriesQuery: '{__name__=~"^container_.*",container!="POD",namespace!="",pod!=""}' seriesFilters: - isNot: ^container_.*_seconds_total$ resources: overrides: namespace: resource: namespace pod: resource: pod name: matches: ^container_(.*)_total$ as: "" metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container!="POD"}[5m])) by (<<.GroupBy>>)prometheus-adapter rlue规范
rules: default: true #是否加载默认规则; custom: - seriesQuery: 'http_requests_total{kubernetes_namespace!="", kubernetes_pod_name!=""}' #找出Pod资源 resources: overrides : kubernetes_namespace: {resource: "namespace"} #替换标签 kubernetes_pod_name: {resource: "pod"} #替换标签 name: matches: "^(.*)_total" #匹配时间序列指标 as: "${1}_per_second" #把上面http_requests_total标签前缀保持不变替换后面为_per_second metricsQuery: 'rate(<<.Series>>{<<.LabelMatchers>>}[2m])' #2m钟范围向量求速率 existing: external: []编辑
comfigmap配置添加自定义rule, 记得先备份comfigmap配置[root@k8s-master prometheus]# kubectl get cm prometheus-adapter -n monitor -o yaml > prometheus-adapter-secrect.yaml [root@k8s-master prometheus]# cat prometheus-adapter-secrect.yaml apiVersion: v1 data: config.yaml: | rules: ... - seriesQuery: '{namespace!="",__name__!~"^container_.*"}' seriesFilters: [] resources: template: <<.Resource>> name: matches: ^(.*)_seconds_total$ as: "" metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[5m])) by (<<.GroupBy>>) #添加规则 - seriesQuery: 'http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pod"} name: matches: "^(.*)_total" as: "${1}_per_second" metricsQuery: 'rate(<<.Series>>{<<.LabelMatchers>>}[2m])' kind: ConfigMap metadata: annotations: meta.helm.sh/release-name: prometheus-adapter meta.helm.sh/release-namespace: monitor creationTimestamp: "2021-09-19T14:23:47Z" #删除原信息 labels: app: prometheus-adapter app.kubernetes.io/managed-by: Helm chart: prometheus-adapter-2.17.0 heritage: Helm release: prometheus-adapter managedFields: - apiVersion: v1 fieldsType: FieldsV1 fieldsV1: f:data: .: {} f:config.yaml: {} managedFields: #整个字段删除 - apiVersion: v1 fieldsType: FieldsV1 fieldsV1: f:data: .: {} f:config.yaml: {} f:metadata: f:annotations: .: {} f:meta.helm.sh/release-name: {} f:meta.helm.sh/release-namespace: {} f:labels: .: {} f:app: {} f:app.kubernetes.io/managed-by: {} f:chart: {} f:heritage: {} f:release: {} manager: Go-http-client operation: Update time: "2021-09-19T14:23:47Z" name: prometheus-adapter namespace: monitor resourceVersion: "5118605" #删除原信息 selfLink: /api/v1/namespaces/monitor/configmaps/prometheus-adapter #删除原信息 uid: 033ad427-8f62-427e-bbe7-94a41958ee88 #删除原信息重启Pod
[root@k8s-master prometheus]# kubectl apply -f prometheus-adapter-secrect.yaml Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply configmap/prometheus-adapter configured [root@k8s-master prometheus]# kubectl delete pod prometheus-alertmanager-769488c787-h9s7z -n monitor pod "pod-21566" deleted示例1: HPA v1 autoscale
通过核心指标Pod自动扩缩容
[root@k8s-master hpa] cat demoapp.yaml apiVersion: apps/v1 kind: Deployment metadata: name: demoapp spec: replicas: 2 selector: matchLabels: app: demoapp controller: demoapp template: metadata: labels : app: demoapp controller: demoapp spec: containers: - name: demoapp image: ikubernetes/demoapp:v1.0 ports: - containerPort : 80 name: http resources: requests: memory: "256Mi" cpu: "50m" limits: memory: "256Mi" cpu: "50m" --- apiVersion: v1 kind: Service metadata: name: demoapp spec: selector: app: demoapp controller: demoapp ports: - name: http port: 80 targetPort: 80 [root@k8s-master hpa] kubectl get svc -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR demoapp ClusterIP 10.105.4.6580/TCP 4m57s app=demoapp,controller=demoapp kubernetes ClusterIP 10.96.0.1 443/TCP 5m23s [root@k8s-master hpa] curl 10.105.4.65 iKubernetes demoapp v1.0 !! ClientIP: 192.168.4.170, ServerName: demoapp-557f9776fd-qmltc, ServerIP: 192.168.12.97! [root@k8s-master hpa] curl 10.105.4.65 iKubernetes demoapp v1.0 !! ClientIP: 192.168.4.170, ServerName: demoapp-557f9776fd-wcj4n, ServerIP: 192.168.113.94! [root@k8s-master hpa] curl 10.105.4.65 iKubernetes demoapp v1.0 !! ClientIP: 192.168.4.170, ServerName: demoapp-557f9776fd-qmltc, ServerIP: 192.168.12.97! 创建autoscale 实现自动扩缩容
[root@k8s-master hpa] kubectl autoscale --help Creates an autoscaler that automatically chooses and sets the number of pods that run in a kubernetes cluster. Looks up a Deployment, ReplicaSet, StatefulSet, or ReplicationController by name and creates an autoscaler that uses the given resource as a reference. An autoscaler can automatically increase or decrease number of pods deployed within the system as needed. Examples: # Auto scale a deployment "foo", with the number of pods between 2 and 10, no target CPU utilization specified so a default autoscaling policy will be used: kubectl autoscale deployment foo --min=2 --max=10 # Auto scale a replication controller "foo", with the number of pods between 1 and 5, target CPU utilization at 80%: kubectl autoscale rc foo --max=5 --cpu-percent=80 #CPU使用率到80 扩容 最大数量为5当CPU使用率为60%时Pod进行扩容最大为6个 低于60%时Pod进行缩容最小为2个
[root@k8s-master hpa]# kubectl autoscale deployment/demoapp --min=2 --max=6 --cpu-percent=60 horizontalpodautoscaler.autoscaling/demoapp autoscaled [root@k8s-master hpa]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE demoapp Deployment/demoapp/60% 2 6 0 14s [root@k8s-master hpa]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE demoapp Deployment/demoapp 2%/60% 2 6 2 21s [root@k8s-master hpa]# kubectl get hpa demoapp -o yaml #详细信息 apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler ...... spec: maxReplicas: 6 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: demoapp targetCPUUtilizationPercentage: 60 status: currentCPUUtilizationPercentage: 2 currentReplicas: 2 desiredReplicas: 2 #监控autoscale状态 NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE demoapp Deployment/demoapp 2%/60% 2 6 2 19m - 压测 同时开两个终端或多个终端同时访问 或调整访问间隔时长
#终端1
[root@k8s-master ~]# kubectl run pod-$RANDOM --image="ikubernetes/demoapp:v1.0" --rm -it --command -- /bin/sh
[root@pod-19457 /]# while true; do curl -s http://demoapp.default.svc; done
iKubernetes demoapp v1.0 !! ClientIP: 192.168.12.101, ServerName: demoapp-557f9776fd-jjq9n, ServerIP: 192.168.51.104!
iKubernetes demoapp v1.0 !! ClientIP: 192.168.12.101, ServerName: demoapp-557f9776fd-qmltc, ServerIP: 192.168.12.97!
iKubernetes demoapp v1.0 !! ClientIP: 192.168.12.101, ServerName: demoapp-557f9776fd-wcj4n, ServerIP: 192.168.113.94!
iKubernetes demoapp v1.0 !! ClientIP: 192.168.12.101, ServerName: demoapp-557f9776fd-ftr64, ServerIP: 192.168.51.105!
iKubernetes demoapp v1.0 !! ClientIP: 192.168.12.101, ServerName: demoapp-557f9776fd-bj7dj, ServerIP: 192.168.113.97!
iKubernetes demoapp v1.0 !! ClientIP: 192.168.12.101, ServerName: demoapp-557f9776fd-gkwsz, ServerIP: 192.168.12.100
#终端2
[root@k8s-master authfiles]# kubectl run pod-$RANDOM --image="ikubernetes/demoapp:v1.0" --rm -it --command -- /bin/sh
[root@pod-25921 /]# while true; do curl -s http://demoapp.default.svc; sleep .1; done
iKubernetes demoapp v1.0 !! ClientIP: 192.168.113.96, ServerName: demoapp-557f9776fd-jjq9n, ServerIP: 192.168.51.104!
iKubernetes demoapp v1.0 !! ClientIP: 192.168.113.96, ServerName: demoapp-557f9776fd-wcj4n, ServerIP: 192.168.113.94!
iKubernetes demoapp v1.0 !! ClientIP: 192.168.113.96, ServerName: demoapp-557f9776fd-jjq9n, ServerIP: 192.168.51.104!
iKubernetes demoapp v1.0 !! ClientIP: 192.168.113.96, ServerName: demoapp-557f9776fd-wcj4n, ServerIP: 192.168.113.94!
iKubernetes demoapp v1.0 !! ClientIP: 192.168.113.96, ServerName: demoapp-557f9776fd-jjq9n, ServerIP: 192.168.51.104!
- 查看监控结果
[root@k8s-master hpa]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
demoapp Deployment/demoapp 2%/60% 2 6 2 19m
demoapp Deployment/demoapp 8%/60% 2 6 2 21m
demoapp Deployment/demoapp 14%/60% 2 6 2 22m
demoapp Deployment/demoapp 17%/60% 2 6 2 22m
demoapp Deployment/demoapp 8%/60% 2 6 2 22m
demoapp Deployment/demoapp 68%/60% 2 6 2 23m
demoapp Deployment/demoapp 70%/60% 2 6 3 23m #扩缩容并不会到达阀值后立刻执行,为了防止Pod抖动 会有一定的延时 缩容的延时会更长
demoapp Deployment/demoapp 72%/60% 2 6 3 23m
demoapp Deployment/demoapp 51%/60% 2 6 3 23m
demoapp Deployment/demoapp 46%/60% 2 6 3 24m
demoapp Deployment/demoapp 32%/60% 2 6 3 24m
demoapp Deployment/demoapp 63%/60% 2 6 3 24m
demoapp Deployment/demoapp 83%/60% 2 6 3 25m
demoapp Deployment/demoapp 49%/60% 2 6 5 28m
demoapp Deployment/demoapp 53%/60% 2 6 5 28m
demoapp Deployment/demoapp 51%/60% 2 6 5 29m
demoapp Deployment/demoapp 52%/60% 2 6 5 29m
demoapp Deployment/demoapp 50%/60% 2 6 5 29m
demoapp Deployment/demoapp 44%/60% 2 6 5 29m
demoapp Deployment/demoapp 46%/60% 2 6 5 30m
demoapp Deployment/demoapp 50%/60% 2 6 5 30m
demoapp Deployment/demoapp 67%/60% 2 6 5 30m
demoapp Deployment/demoapp 86%/60% 2 6 6 31m
demoapp Deployment/demoapp 81%/60% 2 6 6 31m
demoapp Deployment/demoapp 78%/60% 2 6 6 31m
demoapp Deployment/demoapp 70%/60% 2 6 6 31m
demoapp Deployment/demoapp 74%/60% 2 6 6 32m
demoapp Deployment/demoapp 76%/60% 2 6 6 32m
demoapp Deployment/demoapp 53%/60% 2 6 6 32m
demoapp Deployment/demoapp 44%/60% 2 6 6 32m
demoapp Deployment/demoapp 40%/60% 2 6 6 33m
demoapp Deployment/demoapp 39%/60% 2 6 6 33m
demoapp Deployment/demoapp 38%/60% 2 6 6 34m
demoapp Deployment/demoapp 40%/60% 2 6 6 34m #扩缩容并不会到达阀值后立刻执行,为了防止Pod抖动 会有一定的延时 缩容的延时会更长
demoapp Deployment/demoapp 39%/60% 2 6 6 34m
demoapp Deployment/demoapp 40%/60% 2 6 6 35m
demoapp Deployment/demoapp 41%/60% 2 6 6 35m
demoapp Deployment/demoapp 40%/60% 2 6 6 35m
demoapp Deployment/demoapp 39%/60% 2 6 6 36m
demoapp Deployment/demoapp 42%/60% 2 6 6 36m
demoapp Deployment/demoapp 20%/60% 2 6 6 36m
demoapp Deployment/demoapp 7%/60% 2 6 6 36m
demoapp Deployment/demoapp 6%/60% 2 6 6 37m
demoapp Deployment/demoapp 6%/60% 2 6 6 37m #压测关掉之前开始缩容
demoapp Deployment/demoapp 6%/60% 2 6 5 37m
demoapp Deployment/demoapp 7%/60% 2 6 5 38m
demoapp Deployment/demoapp 8%/60% 2 6 5 38m
demoapp Deployment/demoapp 7%/60% 2 6 5 39m
demoapp Deployment/demoapp 8%/60% 2 6 5 40m
demoapp Deployment/demoapp 7%/60% 2 6 5 40m
demoapp Deployment/demoapp 8%/60% 2 6 5 40m
demoapp Deployment/demoapp 7%/60% 2 6 5 40m
demoapp Deployment/demoapp 8%/60% 2 6 5 41m
demoapp Deployment/demoapp 8%/60% 2 6 5 41m
demoapp Deployment/demoapp 8%/60% 2 6 2 41m
demoapp Deployment/demoapp 12%/60% 2 6 2 41m
demoapp Deployment/demoapp 17%/60% 2 6 2 42m
demoapp Deployment/demoapp 16%/60% 2 6 2 42m
demoapp Deployment/demoapp 17%/60% 2 6 2 42m
demoapp Deployment/demoapp 16%/60% 2 6 2 43m
demoapp Deployment/demoapp 17%/60% 2 6 2 43m
demoapp Deployment/demoapp 2%/60% 2 6 2 43m
示例2: HPA v2 autoscale
通过自定义指标Pod自动扩缩容 使用前面自定义指标prometheus-adapter http_requests_total
[root@k8s-master hpa]# cat metrics-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-app
spec:
replicas: 2
selector:
matchLabels:
app: metrics-app
controller: metrics-app
template:
metadata:
labels :
app: metrics-app
controller: metrics-app
annotations:
prometheus.io/scrape: "true" #打开指标抓取 以下两个指标
prometheus.io/port: "80"
prometheus.io/path: "/metrics"
spec:
containers:
- image: ikubernetes/metrics-app
name: metrics-app
ports:
- name: web
containerPort: 80
resources:
requests:
memory: "50Mi"
cpu: "100m"
limits:
memory: "100Mi"
cpu: "200m"
---
apiVersion: v1
kind: Service
metadata:
name: metrics-app
spec :
type: NodePort
selector:
app: metrics-app
controller: metrics-app
ports :
- name: http
port: 80
targetPort: 80
[root@k8s-master hpa]# kubectl apply -f metrics-app.yaml
deployment.apps/metrics-app created
service/metrics-app unchanged
[root@k8s-master hpa]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 8h
metrics-app NodePort 10.100.76.148 80:30665/TCP 33m
[root@k8s-master hpa]# curl 10.100.76.148
Hello! My name is metrics-app-6bf7d6779b-8ztnb. The last 10 seconds, the average QPS has been 0.2. Total requests served: 34
[root@k8s-master hpa]# curl 10.100.76.148
Hello! My name is metrics-app-6bf7d6779b-cb5wf. The last 10 seconds, the average QPS has been 0.1. Total requests served: 32
[root@k8s-master ~]# curl 10.100.76.148/metrics
# HELP http_requests_total The amount of requests in total
# TYPE http_requests_total counter
http_requests_total 25
# HELP http_requests_per_second The amount of requests per second the latest ten seconds
# TYPE http_requests_per_second gauge
http_requests_per_second 0.1
prometheus 已经能抓取到指标

创建autoscale 实现自动扩缩容
[root@k8s-master hpa]# cat metrics-app-hpa.yaml
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2beta2
metadata:
name: metrics-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: metrics-app
minReplicas: 2
maxReplicas: 6
metrics:
- type: Pods
pods :
metric:
name: http_requests_per_second #指标名称 之前我们自定义指标
target:
type: AverageValue #平均值
averageValue: 5
behavior:
scaleDown:
stabilizationWindowSeconds: 120
[root@k8s-master hpa]# kubectl apply -f metrics-app-hpa.yaml
horizontalpodautoscaler.autoscaling/metrics-app-hpa created
[root@k8s-master hpa]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
demoapp Deployment/demoapp 2%/60% 2 6 2 13h
metrics-app-hpa Deployment/metrics-app 16m/5 2 6 2 18s
- 压测 同时开两个终端或多个终端同时访问 或调整访问间隔时长
[root@k8s-master hpa]# kubectl run pod-$RANDOM --image="ikubernetes/demoapp:v1.0" --rm -it --command -- /bin/sh
[root@pod-17207 /]# while true; do curl -s http://metrics-app.default.svc ; sleep 0.05 ; done
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 2.6. Total requests served: 2300
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 2.5. Total requests served: 2299
Hello! My name is metrics-app-5b6d848d9-4t4tv. The last 10 seconds, the average QPS has been 2.5. Total requests served: 93
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 2.6. Total requests served: 2301
...
Hello! My name is metrics-app-5b6d848d9-4t4tv. The last 10 seconds, the average QPS has been 2.8. Total requests served: 105
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 2.9. Total requests served: 2313
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 2.8. Total requests served: 2312
...
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 4.4. Total requests served: 4511
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 4.3. Total requests served: 4510
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 4.5. Total requests served: 4512
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 4.4. Total requests served: 4511
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 4.6. Total requests served: 4513
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 4.5. Total requests served: 4512
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 4.7. Total requests served: 4514
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 4.6. Total requests served: 4513
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 4.8. Total requests served: 4515
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 4.7. Total requests served: 4514
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 4.9. Total requests served: 4516
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 4.8. Total requests served: 4515
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 5. Total requests served: 4517
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 4.9. Total requests served: 4516
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 5.1. Total requests served: 4518
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 5. Total requests served: 4517
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 5.2. Total requests served: 4519
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 5.1. Total requests served: 4518
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 5.2. Total requests served: 4520
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 5.2. Total requests served: 4519
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 5.3. Total requests served: 4521
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 5.3. Total requests served: 4520
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 5.4. Total requests served: 4522
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 5.4. Total requests served: 4521
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 5.5. Total requests served: 4523
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 5.5. Total requests served: 4522
Hello! My name is metrics-app-5b6d848d9-g2t6n. The last 10 seconds, the average QPS has been 5.6. Total requests served: 4524 #当平均值超过5时 开始扩容
...
Hello! My name is metrics-app-5b6d848d9-6fjcr. The last 10 seconds, the average QPS has been 7.1. Total requests served: 4461
Hello! My name is metrics-app-5b6d848d9-dk485. The last 10 seconds, the average QPS has been 7.1. Total requests served: 848
Hello! My name is metrics-app-5b6d848d9-g7hbf. The last 10 seconds, the average QPS has been 7.1. Total requests served: 994
Hello! My name is metrics-app-5b6d848d9-4t4tv. The last 10 seconds, the average QPS has been 7.1. Total requests served: 2255-- 测试结果
[root@k8s-master hpa]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
demoapp Deployment/demoapp 2%/60% 2 6 2 13h
metrics-app-hpa Deployment/metrics-app 16m/5 2 6 2 2m52s
metrics-app-hpa Deployment/metrics-app 4266m/5 2 6 2 8m41s
metrics-app-hpa Deployment/metrics-app 4258m/5 2 6 2 8m57s
metrics-app-hpa Deployment/metrics-app 3324m/5 2 6 2 9m43s
metrics-app-hpa Deployment/metrics-app 4733m/5 2 6 2 10m
metrics-app-hpa Deployment/metrics-app 5766m/5 2 6 2 11m
metrics-app-hpa Deployment/metrics-app 5766m/5 2 6 3 11m
metrics-app-hpa Deployment/metrics-app 4883m/5 2 6 3 12m
metrics-app-hpa Deployment/metrics-app 3333m/5 2 6 3 13m
metrics-app-hpa Deployment/metrics-app 3416m/5 2 6 3 14m
metrics-app-hpa Deployment/metrics-app 3609m/5 2 6 3 14m
metrics-app-hpa Deployment/metrics-app 3722m/5 2 6 3 14m
metrics-app-hpa Deployment/metrics-app 7200m/5 2 6 3 14m
metrics-app-hpa Deployment/metrics-app 8412m/5 2 6 5 15m
metrics-app-hpa Deployment/metrics-app 8494m/5 2 6 5 15m
metrics-app-hpa Deployment/metrics-app 8872m/5 2 6 5 15m
metrics-app-hpa Deployment/metrics-app 9088m/5 2 6 5 15m
metrics-app-hpa Deployment/metrics-app 9488m/5 2 6 5 16m
metrics-app-hpa Deployment/metrics-app 9488m/5 2 6 6 16m
metrics-app-hpa Deployment/metrics-app 8394m/5 2 6 6 16m #到达最大值