作者:Taying,牛津大学计算机科学专业博士
图源:Unsplash
卷积神经网络(CNN)一直是计算机视觉和图像处理的主要技术支柱。与传统的多层感知器(MLP)相比,卷积网络在二维邻域感知和平移同变性方面具有显著优势。然而,最近在自然语言处理领域刮起了一阵新趋势,越来越多的人开始用Transformer来取代递归神经网络,而这也让CV从业者对Transformer的潜力感到非常好奇。
不久前的ICLR 2021*刚好就有一篇论文探讨了Transformer在CV领域的应用前景,并率先提出了“视觉Transformer”的概念,与卷积模型的理念大相径庭。
本文将带大家深入探讨Transformer的概念,特别是视觉Transformer及其与卷积的比较。我们还将简单介绍如何在PyTorch上训练Transformer。
*注:国际学习表征会议(ICLR)是世界顶级的深度学习会议。
卷积网络有什么优势?
为什么卷积网络在计算机视觉领域如此受欢迎?答案就在于卷积的固有性质。卷积核能够将图片内临近像素的特征聚集在一起,使模型能够在学习过程中将这些特征统筹起来。此外,当我们在图像中移动卷积核时,核经过任何地方都能将矩阵内的特征用于分类(称为平移同变性,translation equivariance)。因此,卷积网络无需考虑特征在图像中的位置就能提取特征,在过去几年中让图像分类任务出现了重大进展。
但既然卷积网络已经如此强大,我们为什么还需要Transformer呢?
自然语言处理中的Transformer
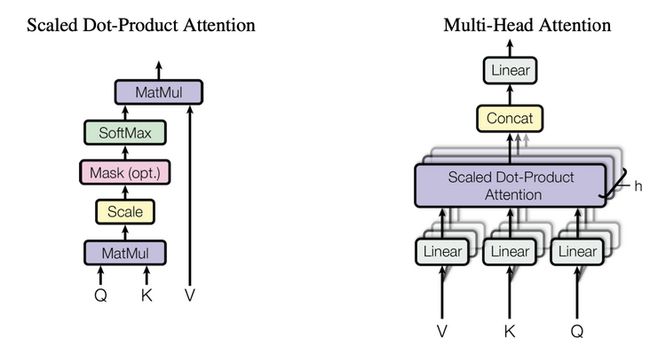
图 1. Transformer中的尺度变换点乘注意力机制和多头注意力机制. 源: https://arxiv.org/abs/1706.03...
Transformer首先在自然语言处理领域提出,论文为“Attention Is All You Need”(《你只是需要有点注意力而已》)。传统的NLP方法(如RNNs和LSTMs)在计算任何预测时都会考虑到短语内附近的词。然而,由于每次出现新的输入时算法都需要考虑到之前已经出现的所有输入,因此模型的预测速度并不算快。
Transformer则利用了“注意力”这一概念。“注意力”某种程度上其实就是矢量词之间的相关性,模型利用这种相关性来计算出最终的预测结果。由于一个词与其他词的相关性独立于其他词之间的相关性,模型得以对所有词进行同时计算。由此,Transformer进一步优化了深度网络的计算逻辑。通过同时考虑所有的词及其相关性,其实际性能明显优于传统的递归方法。
此外,Transformer还加入了“多头注意力”(multi-headed attention)机制,可以多次并行运行注意力机制,并将分离的向量串联成最终的输出结果。
视觉领域的注意力转向
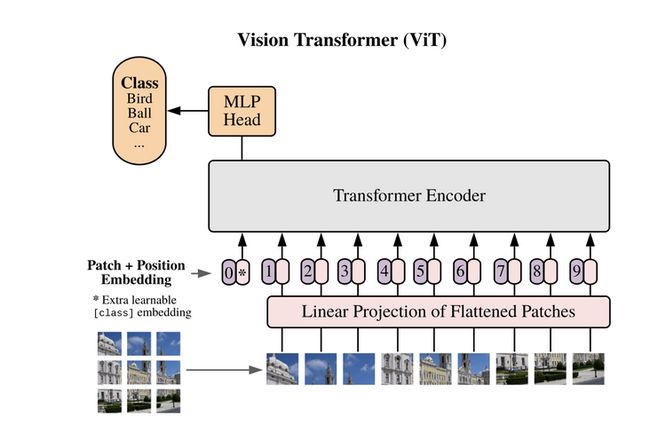
pip install vit-pytorch一定要确保Pytorch和Torchvision的版本已是最新。
"""
Import the necessary libraries
"""
import torch
from vit_pytorch import ViT导入了我们需要的库之后,我们可以用如下代码创建一个ViT:
"""
Create a visual transformer, declaring the number of classes, image size, etc.
Make sure that image_size is divisible by patch_size.
"""
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)如果仅仅需要用ViT来进行推理(inference),使用以下代码即可:
"""
Feed in the image as a standard image model of size (batch, 3, image_size, image_size)
The output will be in the dimension of (batch_size, num_classes)
"""
preds = v(img)如果你真的很想尝试自己去进一步训练ViT,可以参考这篇文章中介绍的方法,通过“蒸馏”(distillation)来进行训练,减少所需的数据量。前述的vit-pytorch仓库里即有提及相关代码。
结果
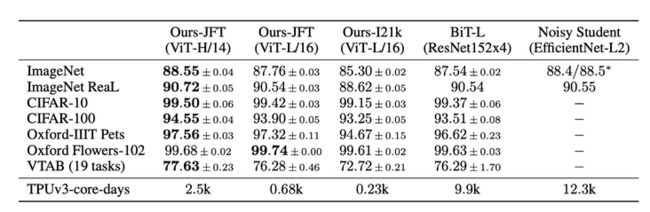
图 2. ViT在多个大型数据集上的结果. 源: https://arxiv.org/abs/2010.11...
ViT的原始论文已经可以让我们看到,ViT的性能可以非常突出,但前提是一定要用非常大型的数据集进行预训练,且预训练所需要的算力之多也是极为惊人。
结语
近年来,计算机视觉领域一直在不断改进Transformer,使其能够更加适应图像处理乃至三维点云任务的需要。最近的ICCV 2021亦出现了如云Transformer和Swin Transformer(会议最佳论文奖得主)这样的优秀文章,表明注意力机制已然成为图像处理的新趋势。
更多信息请访问格物钛官网