前言
Pandas是python的一个数据分析包,是基于NumPy的一种工具提供了大量数据结构和函数,可以很方便的处理结构化数据,常见数据结构有:
Series:一维数组,与Numpy中的一维array类似。
DataFrame:二维的表格型数据结构,可以将DataFrame理解为Series的容器
Time- Series:以时间为索引的Series
Panel :三维的数组,可以理解为DataFrame的容器
1.导入txt文件
本文所使用到的test.txt的内容如下:
![]()
使用read_table()方法导入txt文件
import pandas as pd df = pd.read_table(r'C:\Users\admin\Desktop\test.txt') print(df)
result:
我是李华。 今天本来留下班里十几个人做大扫除结果他们都跑了,只留下了我一个人干完了所有活。 回家的路上真不巧又下了雨,
0 雨太大把我自行车前轮胎上的辐条都冲走了,我非常生气。 为了报复今天发生的一切,我骑着钢圈回到...
1 并把教室里的椅子都扔了出去。
该方法是将利用分隔符分开的文件导入DataFrame的通用函数。不仅可以导入.txt文件,也可以导入.csv文件。
df = pd.read_table(r'C:\Users\admin\Desktop\中文\数据分析测试表.csv') print(df)
result:
区域,省份,城市
0 东北,辽宁,大连
1 西北,陕西,西安
2 华南,广东,深圳
3 华北,北京,北京
4 华中,湖北,武汉
read_table()方法的其他参数用法和read_csv()方法基本一致,再此不再赘述。
2.导入sql文件
2.1 安装依赖库pymysql
python连接MySQL要用到pymysql,需要手动进行安装。
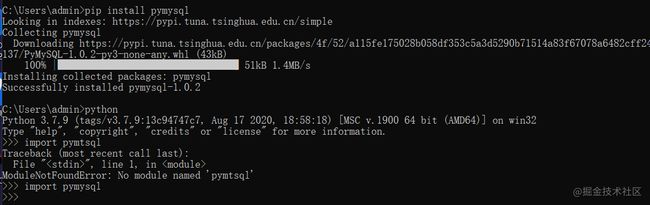
import pandas as pd
import pymysql
con = pymysql.connect(host='127.0.0.1', # 数据库地址,本机为127.0.0.1或localhost
user='root', # 用户名
password='123456', # 密码
db='test', # 数据库名
charset='utf-8') # 数据库编码,一般为utf-8
sql = "select * from employees"
df = pd.read_sql(sql, con)
print(df)
此时报错
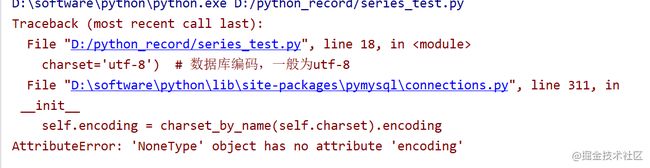
修改charset='utf8'后错误解决:
con = pymysql.connect(host='127.0.0.1', # 数据库地址,本机为127.0.0.1或localhost
user='root', # 用户名
password='123456', # 密码
db='test', # 数据库名
charset='utf8') # 数据库编码,一般为utf-8
sql = "select * from employees"
df = pd.read_sql(sql, con)
print(df)
result:
eID NAME sex birth jobs firJob hiredate
0 1 张三 男 1990-06-21 教师 2005-06-20 2009-08-26
1 2 鲁怀德 男 2004-06-29 工人 2018-08-01 2021-01-06
2 3 赵燕妮 女 1994-07-06 售货员 2004-09-21 2019-05-23
这里提供数据库查询结果作为比对:
注:python使用pymysql与MySQL交互时,编码方式只能写成utf8,不要习惯性地写成utf-8
3.小结
导入数据主要用到pandas里的read_x()方法,x表示待导入文件的格式
除了之前介绍的导入.xlsx文件的read_excel(),导入.csv文件的read_csv(),导入txt的read_table(),导入sql文件的read_sql()之外,
还有一些其他方法在此列出。这些使用到的不多,在此不做深入说明,。后面如有使用到再进行更新。
pd.read_xml() pd.read_html() pd.read_json() pd.read_clipboard() pd.read_feather() pd.read_fwf() pd.read_gbq() pd.read_orc()
总结
到此这篇关于pandas学习之txt与sql文件基本操作的文章就介绍到这了,更多相关pandas之txt与sql文件操作内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!