好听的声音就像滤镜,特别是在直播中,声音已经是提升直播间人气的关键要素,清晰、动听的声音可以迅速吸引观众,拉满好感。
想要打造一个拥有“好声音”的直播间,除了主播通过调整音调、语调、语速等提升对声音的把控度,也需要应用本身在底层能力上提供为声音加分、提升用户听觉体验的技术支持。而随着直播场景的越来越丰富和复杂,不同的直播场景,也有相应的针对性技术要求。
在不断繁荣的直播业务中,连麦功能在用户留存、直播间活跃度、内容品质提升等方面的作用得到了有力验证,成为各种业务场景的必备能力。
融云直播 SDK,以融云强大的 IM + RTC +X 全通信能力为基础,完整封装业务场景,提供 7 种合流布局模式,覆盖直播连麦全场景。
在直播连麦中,必不可少的技术能力就是声学回声消除(Acoustic Echo Cancellation, AEC)。
本文从基础概念、经典算法、主要挑战,以及人工智能回声消除技术探索等方面,分享融云在 AEC 技术方面的实践及效果。
基础概念介绍
什么是回声 ?
在直播连麦场景中,回声主要指的是声学回声(包括线性回声信号和非线性回声信号)。即:远端讲话者(主播 A 或听众 A)的声音信号在传输给近端(听众 B 或主播 B)后,在近端设备的扬声器播放出来,经过一系列声学反射,被近端设备的麦克风拾取,又传输给远端(主播 A 或听众 A)的现象。
这将导致远端讲话者在很短时间内,又听到了自己刚才的讲话声音。声学回声的产生过程如图 1 所示。
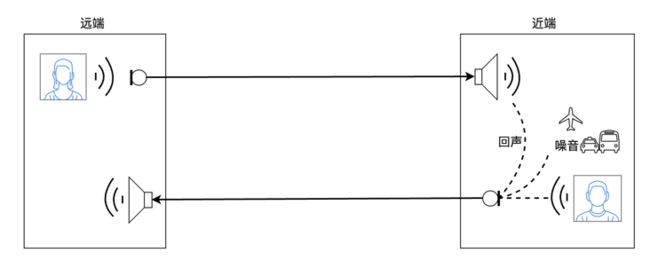
(图 1 声学回声产生过程)
如何避免这一现象 ?
答案就是使用 AEC(声学回声消除)技术,消除近端设备麦克风采集信号中包含的回声 → 保证远端讲话者收听到的声音中不存在回声信号 → 提升用户的连麦直播体验及直播间品质。
使用 AEC 技术后,两端声音传输过程改变为如图 2 所示,进而从底层保证连麦直播场景下声音的干净度。
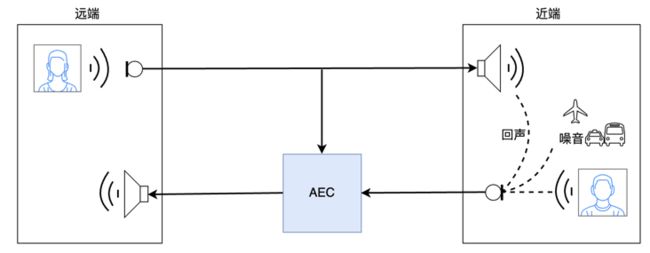
(图 2 AEC 技术使用场景)
常用经典算法
目前,常用的完整声学回声消除算法,由以下三个主要模块组成:时延估计(Time Delay Estimation,TDE)模块、线性回声消除(Linear Echo Cancellation,LEC)模块和残余回声抑制(Residual Echo Suppression,RES)模块,其原理框图如图 3 所示。
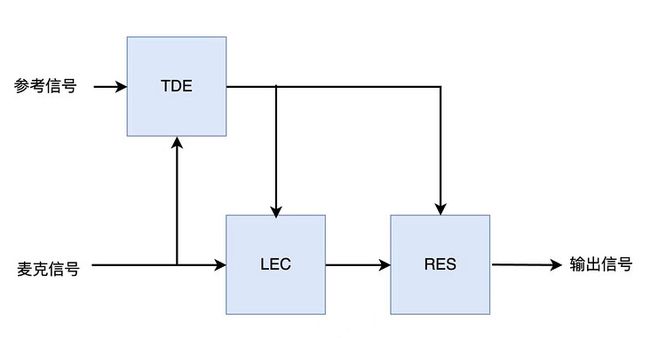
(图 3 回声消除常用算法)
时延估计模块
回声信号相对于参考信号是存在时延的,导致时延的主要原因包括:
① 参考信号获取到扬声器播放出来所经过的时间;
② 扬声器播放出来后到达麦克风经过的时间;
③ 麦克风拾取到回声信号并送到 AEC 算法模块所经过的时间。
由于以上时间均不是固定不变的,而且会出现时延抖动。过大的时延或过大的时延抖动均会严重恶化 AEC 的性能。因此,需要引入时延估计(TDE)模块估计麦克信号与参考信号之间的时延,并进行对齐,从而使得线性回声消除(LEC)模块和残余回声抑制(RES)模块的处理有效。
经典的 TDE 算法是基于互相关原理实现的,这里以 WebRTC 中的 TDE 算法为例说明,其主要是将参考信号与麦克信号分别变换到频域,并将其做 1/0 处理表示有无语音信号,通过不断将两路信号按帧相对移动来寻找最相关时的时间差,来作为时延的估计值。
线性回声消除模块
经典的线性回声消除(LEC)模块主要利用自适应滤波器(Adaptive Filter,AF)来设计,如 LMS、NLMS、AP、RLS、Kalman 等,AF 设计需要考虑如下指标:
① 收敛速率:越快越好,即 AF 由非收敛状态(如初始状态或回声路径变化导致的非收敛状态)到收敛状态的速度;
② 稳定性:主要为 AF 收敛后能够稳定有效地工作使得残余回声量的输出稳定且小;
③ 算法复杂度:要使得滤波效果良好的情况下,计算复杂度尽量低。
通常设计线性回声消除(LEC)模块还需要引入双讲检测(Double Talk Detection,DTD)模块,“双讲”是指近端和远端同时讲话,“单讲”是指只有远端讲话。
双讲检测(DTD)使得自适应滤波器(AF) 在“双讲”时不进行更新,保持自适应滤波器(AF)稳定不发散;而在“单讲”时更新,来跟踪回声路径变化。
残余回声抑制模块
自适应滤波器(AF)通常把回声链路作为一个线性系统进行拟合,而实际系统并非严格意义上的线性系统;且自适应滤波器(AF)长度有限,很难将环境较强混响准确拟合。
因此,在线性回声消除(LEC)处理后,依然会存在残余回声,需要引入残余回声抑制(RES)模块进一步抑制残余回声。
残余回声抑制(RES)模块通常是利用残差信号与麦克信号、参考信号及线性回声估计值之间的相关性来估计残余回声,然后估算后验 / 先验信号回声比,再通过维纳滤波等估计最终的增益,从而得到输出。
需要注意的是,在实际设计残余回声抑制(RES)模块时,还需要分别平衡残余回声抑制量与近端语音失真度,及算法效果与计算复杂度。
经典算法主要挑战
虽然经典算法在实际场景中被广泛使用,但它们也始终面临一些难解的问题,具体如下:
① 在具有强非线性回声的场景下,很难在近端语音不损伤或损伤可接受的情况下,取得不错的回声抑制效果。
② 在强非线性回声或非稳态噪音场景下,传统双讲检测算法也很难得到准确检测结果。
③ 在强混响的场景下,由于自适应滤波器(AF)的长度限制,很难取得不错的回声抑制效果。
在连麦直播场景,AEC 的实际使用场景更加复杂,也面临着更多挑战:
① 用户终端设备种类多、差异大,产生回声的非线性情况大不相同,这对于 AEC 算法提出很大挑战。
② 设备使用环境复杂多样,有安静环境、室内嘈杂环境、室外嘈杂环境、室内强混响环境等,同样考验着 AEC 实现效果。
③ 直播平台的火热可能带来大量用户的涌入,接入人数众多的情况下,“双讲”出现的概率陡增,也提升了 AEC 的难度。
因此,在融云直播 SDK 支持的多种连麦布局直播场景中,传统 AEC 算法面临多重挑战。
人工智能回声消除技术探索
近年来,深度学习在语音信号处理领域的应用越来越多,其与 AEC 算法的结合也取得了一定进展。
深度学习的本质就是构建深度模型来拟合输入与输出之间的映射关系,并且通过所构建模型的不断自我调整来使得模型输出与目标的误差越来越小,直至收敛稳定。对于 AEC 算法来讲,深度网络的输入包括参考和麦克两路信号,输出是一路。
深度学习与 AEC 结合
在当前深度学习与 AEC 结合的研究思路中,主要包括以下两种:
① 传统 LEC + 深度学习 RES
利用深度模型来拟合非线性残余回声,并保留经典线性回声消除(LEC)算法。
② 深度学习 AEC
随着深度网络表达能力的增强,直接利用深度网络模型来拟合全部回声(线性回声+非线性回声)的方法也越来越多。
总的来说,基于深度学习的 AEC 算法研究越来越多,且逐步用到了实际系统中。
融云的探索与应用
连麦是直播业务的重要功能之一,而 AEC 又是连麦直播的必要算法之一,AEC 性能的好坏直接影响着连麦直播的体验。因此,融云对 AEC 的探索从未间断,包括对近年来 NLP 领域最热门的 Transformer 与 AEC 算法融合的探索。
Transformer 由 Google 团队于 2017 年 6 月提出,抛弃了传统 CNN 和 RNN,整个网络结构由 Attention 机制组成。
它带给业界的重大突破在于:解决了 RNN 依赖历史结果导致模型并行能力被限制的问题与顺序计算信息丢失的问题。
现在,Transformer 不仅已经成为了自然语言处理领域的主流模型,还向其他领域跨界,包括图像合成、多目标追踪、音乐生成、时序预测、视觉 - 语言建模等。
语音信号是时序信号,也将是 Transformer 可以大展拳脚的领域。
探索 Transformer 与 AEC 算法的融合,融云构建了一套基于 Dual-path transformer 的 AEC 算法框架,原理框图如图 4 所示,其中 Intra-transformer 与 Inter-transformer 分别用于对局部信息和全局信息建模。
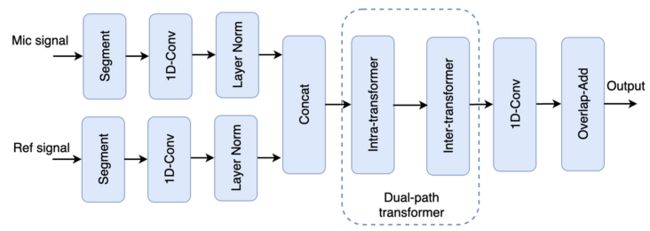
(图 4 融云的人工智能回声消除技术探索)
在深度学习 AEC 的研究趋势下,融云对已有的一些深度学习 AEC 算法进行了实践验证,如基于 LSTM 深度学习模型的 DTLN-AEC 算法。
结果如下对比图所示,结果图中前半部分是“单讲”,后半部分是“双讲”。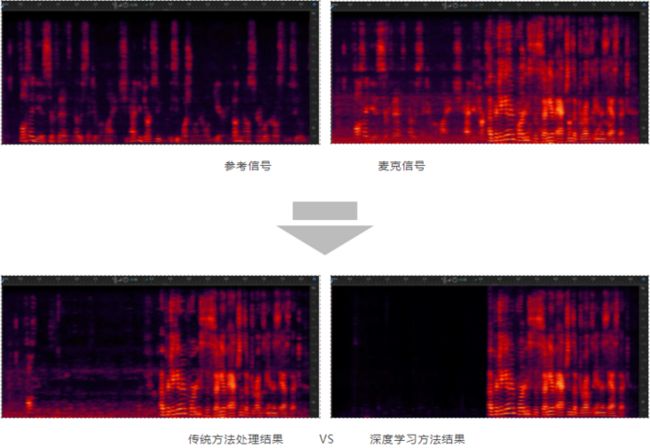
可见,基于 LSTM 的 DTLN-AEC 深度学习方法结果优于传统方法。通过结合深度模型强大的拟合能力与连麦直播场景相关的数据集,为非线性回声、混响、噪音、“双讲”等各种场景的性能带来提升,极大缓解直播连麦场景的挑战。