作者
吕亚霖,2019年加入作业帮,作业帮架构研发负责人,在作业帮期间主导了云原生架构演进、推动实施容器化改造、服务治理、GO微服务框架、DevOps的落地实践。
简介
调度系统的本质是为计算服务/任务匹配合适的资源,使其能够稳定高效地运行,以及在此的基础上进一步提高资源使用密度,而影响应用运行的因素非常多,比如 CPU、内存、IO、差异化的资源设备等等一系列因素都会影响应用运行的表现。同时,单独和整体的资源请求、硬件/软件/策略限制、 亲和性要求、数据区域、负载间的干扰等因素以及周期性流量场景、计算密集场景、在离线混合等不同的应用场景的交织也带来了决策上的多变。
调度器的目标则是快速准确地实现这一能力,但快速和准确这两个目标在资源有限的场景下会往往产生产生矛盾,需要在二者间权衡。
调度器原理和设计
K8s 默认调度器的整体工作框架,可以简单用下图概括:

两个控制循环
- 第一个控制循环,称为 Informer Path。它的主要工作,是启动一系列的 Informer,用来监听(Watch)集群中 Pod、Node、Service 等与调度相关的 API 对象的变化。比如,当一个待调度 Pod 被创建出来之后,调度器就会通过 Pod Informer 的 Handler,将这个待调度 Pod 添加进调度队列;同时,调度器还要负责对调度器缓存 Scheduler Cache 进行更新,并以这个 cache 为参考信息,来提高整个调度流程的性能。
- 第二个控制循环,即为对 pod 进行调度的主循环,称为 Scheduling Path。这一循环的工作流程是不断地从调度队列中取出待调度的 pod,运行2个步骤的算法,来选出最优 node。
- 在集群的所有节点中,选出所有“可以”运行该 pod 的节点,这一步被称为 Predicates;
- 在上一步选出的节点中,根据一些列优选算法对节点就行打分,选出“最优”即得分最高的节点,这一步被称为 Priorities。
调度完成之后,调度器就会为 pod 的 spec.NodeName 赋值这个节点,这一步称为 Bind。而为了不在主流程路径中访问 Api Server 影响性能,调度器只会更新 Scheduler Cache 中的相关 pod 和 node 信息:这种基于乐观的假设的 Api 对象更新方式,在 K8s 中称为 Assume。之后才会创建一个 goroutine 来异步地向 Api Server 发起更新 Bind 操作,这一步就算失败了也没有关系,Scheduler Cache 更新后就会一切正常。
大规模集群调度带来的问题和挑战
K8s 默认调度器策略在小规模集群下有着优异的表现,但是随着业务量级的增加以及业务种类的多样性变化,默认调度策略则逐渐显露出了局限性:调度维度较少,无并发,存在性能瓶颈,以及调度器越来越复杂。
迄今为止,我们当前单个集群规模节点量千级,pod 量级则在 10w 以上,整体资源分配率超过60%,其中更是包含了 gpu,在离线混合部署等复杂场景;在这个过程中,我们遇到了不少调度方面的问题。
问题1:高峰期的节点负载不均匀
默认调度器,参考的是 workload 的 request 值,如果我们针对 request 设置的过高,会带来资源的浪费;过低则有可能带来高峰期 CPU 不均衡差异严重的情况;使用亲和策略虽然可以一定程度避免这种,但是需要频繁填充大量的策略,维护成本就会非常大。而且服务的 request 往往不能体现服务真实的负载,带来差异误差。而这种差异误差,会在高峰时体现到节点负载不均上。
实时调度器,在调度的时候获取各节点实时数据来参与节点打分,但是实际上实时调度在很多场景并不适用,尤其是对于具备明显规律性的业务来说;比如我们大部分服务晚高峰流量是平时流量的几十倍,高低峰资源使用差距剧大,而业务发版一般选择低峰发版,采用实时调度器,往往发版的时候比较均衡,到晚高峰就出现节点间巨大差异,很多实时调度器,往往在出现巨大差异的时候会使用再平衡策略来重新调度,高峰时段对服务 POD 进行迁移,服务高可用角度来考虑是不现实的。显然实时调度是远远无法满足业务场景的。
我们的方案:高峰预测时调度
所以针对这种情况,需要预测性调度,根据以往高峰时候 CPU、IO、网络、日志等资源的使用量,通过对服务在节点上进行最优排列组合回归测算,得到各个服务和资源的权重系数,基于资源的权重打分扩展,也就是使用过去高峰数据来预测未来高峰节点服务使用量,从而干预调度节点打分结果。
问题2:调度维度多样化
随着业务越来越多样性,需要加入更多的调度维度,比如日志。由于采集器不可能无限速率采集日志且日志采集是基于节点维度。需要将平衡日志采集速率,不能各个节点差异过大。部分服务 CPU 使用量一般但是日志输出量很大;而日志并不属于默认调度器决策的一环,所以当这些日志量很大的服务多个服务的 pod 在同一个节点上的时候,该机器上的日志上报就有可能出现部分延迟。
我们的方案:补全调度决策因子
该问题显然需要我们对调度决策补全,我们扩展了预测调度打分策略,添加了日志的决策因子,将日志也作为节点的一种资源,并根据历史监控获取到服务对应的日志使用量来计算分数。
问题3:大批量服务扩缩导带来的调度时延
随着业务的复杂度进一步上升,在高峰时段出现,会有大量定时任务和集中大量弹性扩缩,大批量(上千 POD)同时调度导致调度时延的上涨,这两者对调度时间比较敏感,尤其对于定时任务来说,调度延时的上涨会被明显感知到。原因是 K8s 调度 pod 本身是对集群资源的分配,反应在调度流程上则是预选和打分阶段是顺序进行的;如此一来,当集群规模大到一定程度的时候,大批量更新就会出现可感知到的 pod 调度延迟。
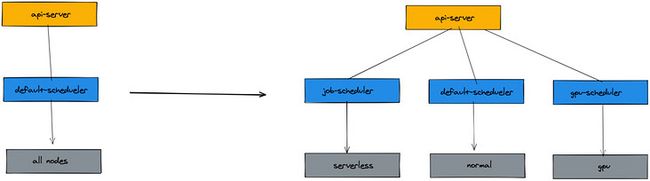
我们的方案:拆分任务调度器,加大并发调度域、批量调度
解决吞吐能力低下的最直接的方法就是串行改并行,对于资源抢占场景,尽量细化资源域,资源域之间并行。给予以上策略,我们拆分出了独立的 job 调度器,同时使用了 serverless 作为 job 运行的底层资源。K8s serverless 为每一个 JOB POD,单独申请了独立的 POD 运行 sanbox,也就是任务调度器,是完整并行。以下对比图:
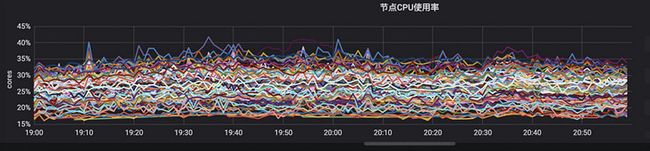
原生调度器在晚高峰下节点 CPU 使用率
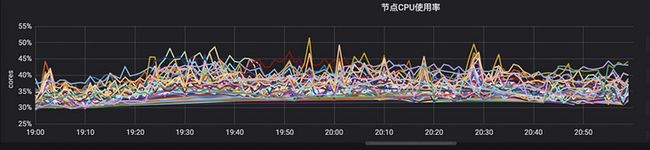
优化后调度器在晚高峰下节点 CPU 使用率
总结
work 节点资源、GPU 资源、serverless 资源这就是我们集群异构资源分属于这三类资源域,这三种资源上运行的服务存在天然的差异性,我们使用 forecast-scheduler、gpu-scheduler、job-schedule 三个调度器来管理这三种资源域上的 pod 的调度情况。
预测调度器管理大部分在线业务,其中扩展了资源维度,添加了预测打分策略。
GPU 调度器管理 GPU 资源机器的分配,运行在线推理和离线训练,两者的比例处于长期波动中,高峰期间离线训练缩容、在线推理扩容;非高峰期间离线训练扩容、在线推理缩容;同时处理一些离线图片处理任务来复用 GPU 机器上比较空闲的 CPU 等资源
Job 调度器负责管理我们定时任务的调度,定时任务量大且创建销毁频繁,资源使用非常碎片化,而且对实效性要求更高;所以我们将任务尽量调度到 Serverless 服务上,压缩集群中为了能容纳大量的任务而冗余的机器资源,提升资源利用率。
未来的演进探讨
更细粒度的资源域划分
将资源域划分至节点级别,节点级别加锁来进行。
资源抢占和重调度
正常场景下,当一个 pod 调度失败的时候,这个 pod 会保持在 pending 的状态,等待 pod 更新或者集群资源发生变化进行重新调度,但是 K8s 调度器依然存在一个抢占功能,可以使得高优先级 pod 在调度失败的时候,挤走某个节点上的部分低优先级 pod 以保证高优 pod 的正常,迄今为止我们并没有使用调度器的抢占能力,即使我们通过以上多种策略来加强调度的准确性,但依然无法避免部分场景下由于业务带来的不均衡情况,这种非正常场景中,重调度的能力就有了用武之地,也许重调度将会成为日后针对异常场景的一种自动修复的方式。
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
