作者:潘文彪
小 T 导读: 中节能风力发电股份有限公司(股票简称:节能风电,股票代码:601016)是中国节能环保集团有限公司控股的现代股份制公司。公司先后成功中标并示范建设了国家第一个百万千瓦级风电基地启动项目——河北张北单晶河 200 兆瓦风电特许权项目,和第一个千万千瓦级风电基地启动项目——甘肃玉门昌马 200 兆瓦风电特许权项目,是国家首个百万千瓦、千万千瓦风电基地的示范者和引领者,在业内树立了较高的知名度和良好的品牌形象。建成、在建项目装机规模 547.97 万千瓦,已发展成为张北坝上地区、甘肃河西走廊地区最大的风电开发商之一,是我国风电领域一支重要的力量。

一、项目背景
公司作为中节能集团在风电领域的专业化公司和核心上市平台,具备成熟的风电开发和运维经验,但是随着在建风场逐步增多以及各类新型传感器的加装,传统运维方式已经越来越吃力,数字化智能化的需求越来越强烈,因此迫切需要基于海量时序数据的数据平台来支撑繁杂的运维工作。
因此,我们做了大量的时序数据调研工作。但是选型工作也并非一帆风顺,开始我们尝试传统的工控时序数据库,但是随着测点数量的增多,单机版架构已经无力支撑,后期我们也尝试了 InfluxDB 和 OpenTSDB 等分布式架构的时序数据库,但是性能又达不到要求。
机遇巧合,我们注意到一款国产、开源的时序数据库 TDengine,所以也尝试了一下。
二、TDengine 选型测试
针对我们重点关注的查询性能,我们做了如下几个测试。
1. 单测点历史数据聚合查询
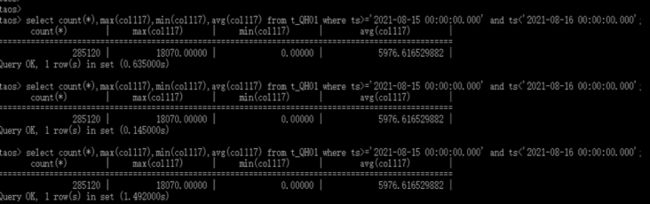
随机选择任一个测点,查询该测点在某个时间段测点采集值的 count,max,min,avg;比如从 2020-01-01 00:00:00.000 到 2020-02-01 00:00:00.000 的 31 天内的共 535680 条数据记录的 count,max,min,avg。
具体的查询语句为:
select count(*),max(col117),min(col117),avg(col117) from t_QH01 where ts>='2021-08-15 00:00:00.000' and ts<'2021-08-16 00:00:00.000'实验截图如下:
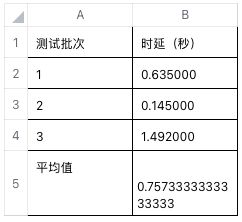
3 次查询测试时延如下:
2. 分组聚合查询
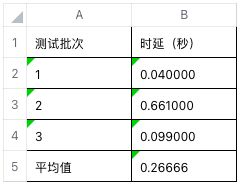
查询某个时间段内测点采集值的 count,max,min,avg,比如查询从 2020-01-01 00:00:00.000 到 2020-02-01 00:00:00.000 的 31 天内的数据记录的 count,max,min,avg。
数据库中对应查询语句为:
select count(*),max(col117),min(col117),avg(col117) from t_QH01 where ts >='2021-08-01 00:00:00.000' and ts<'2021-09-01 00:00:00.000' group by wtcode >>E:/taosTempData/2实验截图如下:

3 次查询测试时延如下:
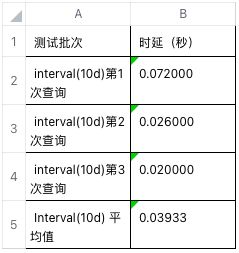
3. 窗口查询操作
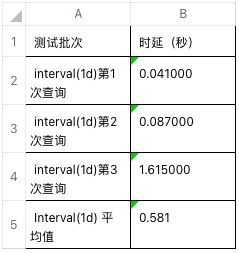
查询某个时间段内,按照 1 小时、1 天、10 天的时间窗口进行分组后的 count,max,min,avg 聚合结果;比如查询从 2020-01-01 00:00:00.000 到 2020-02-01 00:00:00.000 的 31 天内的全部数据记录,按照每 1 小时、1 天、10 天的时间区间划分后的 count,max,min,avg。
数据库中对应查询语句为:
select count(*),max(col117),min(col117),avg(col117) from t_QH01 where ts >='2021-08-01 00:00:00.000' and ts<'2021-09-01 00:00:00.000' and wtcode ='001' interval (1h) >>E:/taosTempData/3;
select count(*),max(col117),min(col117),avg(col117) from t_QH01 where ts >='2021-08-01 00:00:00.000' and ts<'2021-09-01 00:00:00.000' and wtcode ='001' interval (1d) >>E:/taosTempData/4;
select count(*),max(col117),min(col117),avg(col117) from t_QH01 where ts >='2021-08-01 00:00:00.000' and ts<'2021-09-01 00:00:00.000' and wtcode ='001' interval (10d) >>E:/taosTempData/5;实验截图如下:

多个批次查询测试时延如下:

经过反复对比测试以及应用适配,最终我们选定 TDengine 作为我们数据平台的时序数据解决方案。
三、TDengine 落地实践
目前中节能风电的整体时序数据流如下图所示:
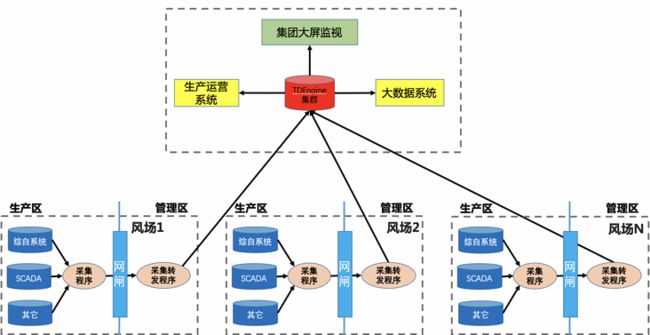
风场的时序数据(主要是风机数据和电气数据)穿透网闸后,经由场站侧的采集程序采集和转发,最终所有数据会汇聚到集团侧的分布式时序数据库,前端的实时监视、指标计算均构建于其上,同时数据还要送到大数据分析平台和生产运维平台。
集团中心侧的 TDengine 集群起到了举足轻重的作用,既要收集所有风场的时序数据,同时还要支撑前端应用以及同步数据到其它系统。
TDengine 的诸多特性中,最吸引我们的是超级表和标签功能。超级表能让同一类风机的建模、管理和计算过程更加方便快捷,而标签特性能增加诸如隶属项目、平台容量等维度特征,便于在聚合操作过程中快速筛选或者分组。基于时间窗口和状态窗口的功能也为应用构建提供了很多方便,比如功率曲线拟合过程中需要的五分钟平均风速和功率计算逻辑,以及基于风机状态的各类统计分析。
在 TDengine 的使用初期遇到了一些问题,主要涉及集群搭建和参数配置方面,经过和涛思数据技术团队的沟通交流,都已得到解决。
后期在数据建模和应用适配方面也走了一些弯路,尤其是数据建模方面。最开始我们使用的是最简单的单列模式,一个测点一张表,在测点数目少的情况下问题并不明显,但是随着测点数目的不断膨胀,这种方式逐渐暴露出在应用适配方面的问题;后来我们采取按照不同机型不同风场建超级表的方式建模,基本能解决我们的应用问题,但是依然有无效开关量数值过多的问题;最终我们采取将风机状态等重点开关量单列建模的方式解决了。
四、整体效果和未来展望
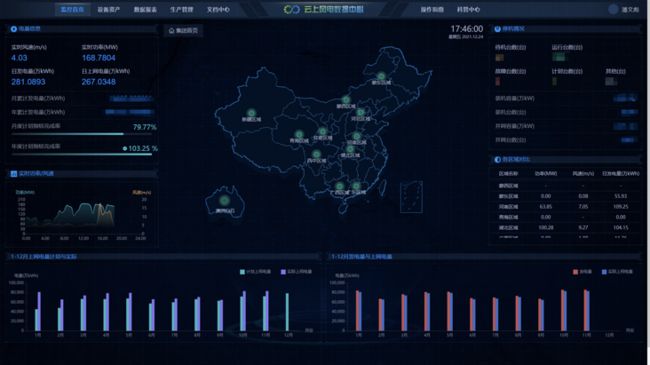
目前基于 TDengine 数据库我们构建了中节能风电运维平台,使用后数据存储优势明显,整体压缩比在 7-8 倍,数据查询也实现秒级响应。整体使用效果如下图所示:
未来我们考虑在每个风电场站的三区部署一个单节点 TDengine,作用不只是采集和转发,还要起到时序数据质量治理以及实时模型预测的功能;而在集团侧我们会考虑基于 TDengine 构建更多更复杂的计算指标和高级模型;同时还要和任务调度引擎以及风电行业标准集成。未来的数据流图如下图所示:

最终将其作为中节能风电公司时序数据的核心技术组件来构建智能运维平台,为中节能风电公司 3060 双碳目标的提供坚实基础。
作者介绍:
潘文彪,中节能风电生产运维部数据分析师,2019 年起从事节能风电的数据分析与数字化平台建设工作。
⬇️点击下方图片查看活动详情,iPhone 13 Pro 等你带回家!