前言
在上一篇语法分析中,我们知道了Go编译器是如何按照Go的文法,解析go文本文件中的各种声明类型(import、var、const、func等)。语法分析阶段将整个源文件解析到一个File的结构体中,源文件中各种声明类型解析到File.DeclList中。最终生成以File结构体为根节点,importDecl、constDecl、typeDecl、varDecl、FuncDecl等为子节点的语法树
首先我们需要明确的就是,抽象语法树的作用其实就是为了后边进行类型检查、代码风格检查等等。总之,有了抽象语法树,编译器就可以精准的定位到代码的任何地方,对其进行一些列的操作及验证等
本文为抽象语法树的构建,我们知道,在编译器前端必须将源程序构建成一种中间表示形式,以便在编译器的后端进行使用,抽象语法树就是一种常见的树状的中间表示形式。所以本文主要是介绍Go编译器将语法树构建成抽象语法树都做了哪些事情?
抽象语法树构建概览
以下先从整体上认识抽象语法树构建过程,可能跨度比较大,具体实现细节在下一部分介绍
在上一篇的语法解析阶段我们知道,Go编译器会起多个协程,将每一个源文件都解析成一棵语法树。具体代码的位置是:src/cmd/compile/internal/gc/noder.go → parseFiles
func parseFiles(filenames []string) uint {
noders := make([]*noder, 0, len(filenames))
// Limit the number of simultaneously open files.
sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10)
for _, filename := range filenames {
p := &noder{
basemap: make(map[*syntax.PosBase]*src.PosBase),
err: make(chan syntax.Error),
}
noders = append(noders, p)
//起多个协程对源文件进行语法解析
go func(filename string) {
sem <- struct{}{}
defer func() { <-sem }()
defer close(p.err)
base := syntax.NewFileBase(filename)
f, err := os.Open(filename)
if err != nil {
p.error(syntax.Error{Msg: err.Error()})
return
}
defer f.Close()
p.file, _ = syntax.Parse(base, f, p.error, p.pragma, syntax.CheckBranches) // errors are tracked via p.error
}(filename)
}
//开始将每一棵语法树构建成抽象语法树
var lines uint
for _, p := range noders {
for e := range p.err {
p.yyerrorpos(e.Pos, "%s", e.Msg)
}
p.node() //构建抽象语法树的核心实现
lines += p.file.Lines
p.file = nil // release memory
......
}
localpkg.Height = myheight
return lines
}在将源文件解析成一棵语法树之后,Go编译器会将每一棵语法树(源文件)构建成抽象语法树。其核心代码就在p.node()这个方法中:
func (p *noder) node() {
......
xtop = append(xtop, p.decls(p.file.DeclList)...)
......
clearImports()
}p.node()这个方法的核心部分是p.decls(p.file.DeclList)方法,该方法实现了将源文件中的各种声明类型转换成一个一个的抽象语法树,即import、var、type、const、func声明都会成为一个根节点,根节点下边包含当前声明的子节点
p.decls(p.file.DeclList)的实现如下:
func (p *noder) decls(decls []syntax.Decl) (l []*Node) {
var cs constState
for _, decl := range decls {
p.setlineno(decl)
switch decl := decl.(type) {
case *syntax.ImportDecl:
p.importDecl(decl)
case *syntax.VarDecl:
l = append(l, p.varDecl(decl)...)
case *syntax.ConstDecl:
l = append(l, p.constDecl(decl, &cs)...)
case *syntax.TypeDecl:
l = append(l, p.typeDecl(decl))
case *syntax.FuncDecl:
l = append(l, p.funcDecl(decl))
default:
panic("unhandled Decl")
}
}
return
}从整体上来看,该方法其实就是将语法树中的各种声明类型,都转换成了以各种声明为根节点的抽象语法树(Node结构),最终语法树就变成了一个节点数组(Node)
下边可以看一下这个Node结构体长什么样
type Node struct {
// Tree structure.
// Generic recursive walks should follow these fields.
//通用的递归遍历,应该遵循这些字段
Left *Node //左子节点
Right *Node //右子节点
Ninit Nodes
Nbody Nodes
List Nodes //左子树
Rlist Nodes //右子树
// most nodes
Type *types.Type //节点类型
Orig *Node // original form, for printing, and tracking copies of ONAMEs
// func
Func *Func //方法
// ONAME, OTYPE, OPACK, OLABEL, some OLITERAL
Name *Name //变量名、类型明、包名等等
Sym *types.Sym // various
E interface{} // Opt or Val, see methods below
// Various. Usually an offset into a struct. For example:
// - ONAME nodes that refer to local variables use it to identify their stack frame position.
// - ODOT, ODOTPTR, and ORESULT use it to indicate offset relative to their base address.
// - OSTRUCTKEY uses it to store the named field's offset.
// - Named OLITERALs use it to store their ambient iota value.
// - OINLMARK stores an index into the inlTree data structure.
// - OCLOSURE uses it to store ambient iota value, if any.
// Possibly still more uses. If you find any, document them.
Xoffset int64
Pos src.XPos
flags bitset32
Esc uint16 // EscXXX
Op Op //当前结点的属性
aux uint8
}知道上边注释中的几个字段的含义,基本就够用了。核心是Op这个字段,它标识了每个结点的属性。你可以在:src/cmd/compile/internal/gc/syntax.go中看到所有Op的定义,它都是以O开头的,也都是整数,每个Op都有自己的语义
const (
OXXX Op = iota
// names
ONAME // var or func name 遍历名或方法名
// Unnamed arg or return value: f(int, string) (int, error) { etc }
// Also used for a qualified package identifier that hasn't been resolved yet.
ONONAME
OTYPE // type name 变量类型
OPACK // import
OLITERAL // literal 标识符
// expressions
OADD // Left + Right 加法
OSUB // Left - Right 减法
OOR // Left | Right 或运算
OXOR // Left ^ Right
OADDSTR // +{List} (string addition, list elements are strings)
OADDR // &Left
......
// Left = Right or (if Colas=true) Left := Right
// If Colas, then Ninit includes a DCL node for Left.
OAS
// List = Rlist (x, y, z = a, b, c) or (if Colas=true) List := Rlist
// If Colas, then Ninit includes DCL nodes for List
OAS2
OAS2DOTTYPE // List = Right (x, ok = I.(int))
OAS2FUNC // List = Right (x, y = f())
......
)比如当某一个节点的Op为OAS,该节点代表的语义就是Left := Right。当节点的Op为OAS2时,代表的语义就是x, y, z = a, b, c
假设有这样一个声明语句:a := b + c(6),构建成抽象语法树就长下边这样

最终每种声明语句都会被构建成这样的抽象语法树。上边是对抽象语法树有个大致的认识,下边就具体的看各种声明语句是如何一步一步的被构建成抽象语法树的
语法分析阶段解析各种声明
为了更直观的看到抽象语法树是如何解析各种声明的,我们可以直接利用go提供的标准库中的方法来进行调试。因为在前边并没有直观的看到一个声明被语法解析出来之后长什么样子,所以下边通过标准库中的方法来展示一下
提示:在前边的Go词法分析这篇文章中提到,Go提供的标准库中的词法解析、语法解析、抽象语法树构建等的实现跟Go编译器中的实现或设计不一样,但是整体的思路是一样的
基础面值解析
基础面值有整数、浮点数、复数、字符、字符串、标识符。从上一篇Go的语法解析中知道,Go编译器中基础面值的结构体为
BasicLit struct {
Value string //值
Kind LitKind //那种类型的基础面值,范围(IntLit、FloatLit、ImagLit、RuneLit、StringLit)
Bad bool // true means the literal Value has syntax errors
expr
}而在标准库中,基础面值的结构体长下边这样
BasicLit struct {
ValuePos token.Pos // literal position
Kind token.Token // token.INT, token.FLOAT, token.IMAG, token.CHAR, or token.STRING
Value string // literal string; e.g. 42, 0x7f, 3.14, 1e-9, 2.4i, 'a', '\x7f', "foo" or `\m\n\o`
}其实几乎是一样的,包括我们后边会提到的其它的各种面值的结构体或声明的结构体,在Go编译器中和Go标准库中结构都不一样,但是含义都差不多
知道了基础面值的结构,如果我们想构建一个基础面值,就可以这样
func AstBasicLit() {
var basicLit = &ast.BasicLit{
Kind: token.INT,
Value: "666",
}
ast.Print(nil, basicLit)
}
//打印结果
*ast.BasicLit {
ValuePos: 0
Kind: INT
Value: "666"
}上边就是直接构建了一个基础面值,理论上我们可以按照这种方式构造一个完成的语法树,但是手工的方式毕竟太麻烦。所以标准库中提供了方法来自动的构建语法树。假设我要将整数666构建成基础面值的结构
func AstBasicLitCreat() {
expr, _ := parser.ParseExpr(`666`)
ast.Print(nil, expr)
}
//打印结果
*ast.BasicLit {
ValuePos: 1
Kind: INT
Value: "666"
}再比如标识符面值,它的结构体为:
type Ident struct {
NamePos token.Pos // 位置
Name string // 标识符名字
Obj *Object // 标识符类型或扩展信息
}通过下边方法可以构建一个标识符类型
func AstInent() {
ast.Print(nil, ast.NewIdent(`a`))
}
//打印结果
*ast.Ident {
NamePos: 0
Name: "a"
}如果标识符是出现在一个表达式中,就会通过Obj这个字段存放标识符的额外信息
func AstInent() {
expr, _ := parser.ParseExpr(`a`)
ast.Print(nil, expr)
}
//打印结果
*ast.Ident {
NamePos: 1
Name: "a"
Obj: *ast.Object {
Kind: bad
Name: ""
}
}ast.Object结构中的Kind是描述标识符的类型
const (
Bad ObjKind = iota // for error handling
Pkg // package
Con // constant
Typ // type
Var // variable
Fun // function or method
Lbl // label
)表达式解析
在标准库的go/ast/ast.go中,你会看到各种类型的表达式的结构,我这里粘一部分看一下
// A SelectorExpr node represents an expression followed by a selector.
SelectorExpr struct {
X Expr // expression
Sel *Ident // field selector
}
// An IndexExpr node represents an expression followed by an index.
IndexExpr struct {
X Expr // expression
Lbrack token.Pos // position of "["
Index Expr // index expression
Rbrack token.Pos // position of "]"
}
// A SliceExpr node represents an expression followed by slice indices.
SliceExpr struct {
X Expr // expression
Lbrack token.Pos // position of "["
Low Expr // begin of slice range; or nil
High Expr // end of slice range; or nil
Max Expr // maximum capacity of slice; or nil
Slice3 bool // true if 3-index slice (2 colons present)
Rbrack token.Pos // position of "]"
}在Go的编译器中,你也可以看到类似的表达式结构,位置在:src/cmd/compile/internal/gc/noder.go
// X.Sel
SelectorExpr struct {
X Expr
Sel *Name
expr
}
// X[Index]
IndexExpr struct {
X Expr
Index Expr
expr
}
// X[Index[0] : Index[1] : Index[2]]
SliceExpr struct {
X Expr
Index [3]Expr
// Full indicates whether this is a simple or full slice expression.
// In a valid AST, this is equivalent to Index[2] != nil.
// TODO(mdempsky): This is only needed to report the "3-index
// slice of string" error when Index[2] is missing.
Full bool
expr
}虽然结构体定义的不一样,但是表达的含义是差不多的。在标准库中提供了很多解析各种表达式的方法
type BadExpr struct{ ... }
type BinaryExpr struct{ ... }
type CallExpr struct{ ... }
type Expr interface{ ... }
type ExprStmt struct{ ... }
type IndexExpr struct{ ... }
type KeyValueExpr struct{ ... }
......而在Go编译器中,解析表达式的核心方法是:src/cmd/compile/internal/gc/noder.go→expr()
func (p *noder) expr(expr syntax.Expr) *Node {
p.setlineno(expr)
switch expr := expr.(type) {
case nil, *syntax.BadExpr:
return nil
case *syntax.Name:
return p.mkname(expr)
case *syntax.BasicLit:
n := nodlit(p.basicLit(expr))
n.SetDiag(expr.Bad) // avoid follow-on errors if there was a syntax error
return n
case *syntax.CompositeLit:
n := p.nod(expr, OCOMPLIT, nil, nil)
if expr.Type != nil {
n.Right = p.expr(expr.Type)
}
l := p.exprs(expr.ElemList)
for i, e := range l {
l[i] = p.wrapname(expr.ElemList[i], e)
}
n.List.Set(l)
lineno = p.makeXPos(expr.Rbrace)
return n
case *syntax.KeyValueExpr:
// use position of expr.Key rather than of expr (which has position of ':')
return p.nod(expr.Key, OKEY, p.expr(expr.Key), p.wrapname(expr.Value, p.expr(expr.Value)))
case *syntax.FuncLit:
return p.funcLit(expr)
case *syntax.ParenExpr:
return p.nod(expr, OPAREN, p.expr(expr.X), nil)
case *syntax.SelectorExpr:
// parser.new_dotname
obj := p.expr(expr.X)
if obj.Op == OPACK {
obj.Name.SetUsed(true)
return importName(obj.Name.Pkg.Lookup(expr.Sel.Value))
}
n := nodSym(OXDOT, obj, p.name(expr.Sel))
n.Pos = p.pos(expr) // lineno may have been changed by p.expr(expr.X)
return n
case *syntax.IndexExpr:
return p.nod(expr, OINDEX, p.expr(expr.X), p.expr(expr.Index))
......
}
panic("unhandled Expr")
}下边还是用Go标准库中提供的方法来看一个二元表达式解析出来之后长啥样
func AstBasicExpr() {
expr, _ := parser.ParseExpr(`6+7*8`)
ast.Print(nil, expr)
}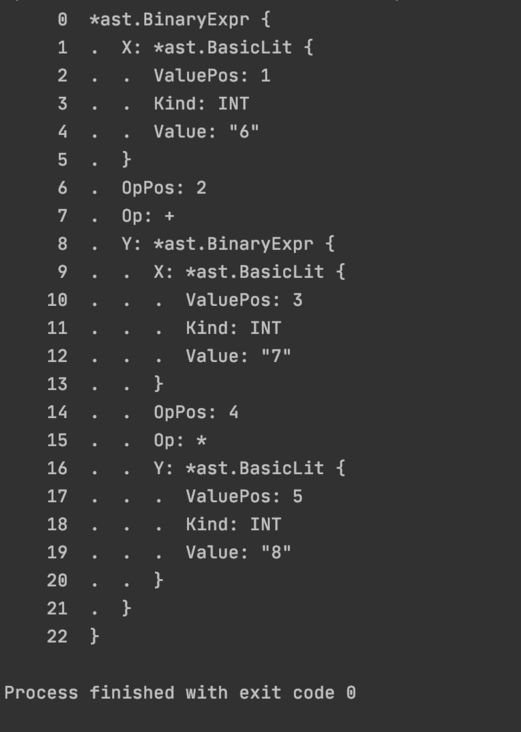
首先二元表达式的结构体是BinaryExpr
// A BinaryExpr node represents a binary expression.
BinaryExpr struct {
X Expr // left operand
OpPos token.Pos // position of Op
Op token.Token // operator
Y Expr // right operand
}当被解析成这样的结构之后,就可以根据Op的类型来创建不同的节点。在前边提到,每一个Op都有自己的语义
表达式求值
假设要对上边的那个二元表达式进行求值
func AstBasicExpr() {
expr, _ := parser.ParseExpr(`6+7*8`)
fmt.Println(Eval(expr))
}
func Eval(exp ast.Expr) float64 {
switch exp := exp.(type) {
case *ast.BinaryExpr: //如果是二元表达式类型,调用EvalBinaryExpr进行解析
return EvalBinaryExpr(exp)
case *ast.BasicLit: //如果是基础面值类型
f, _ := strconv.ParseFloat(exp.Value, 64)
return f
}
return 0
}
func EvalBinaryExpr(exp *ast.BinaryExpr) float64 { //这里仅实现了+和*
switch exp.Op {
case token.ADD:
return Eval(exp.X) + Eval(exp.Y)
case token.MUL:
return Eval(exp.X) * Eval(exp.Y)
}
return 0
}
//打印结果
62
主要的地方加了注释,应该是很容易看明白
Var声明解析
首先需要说明的是,在上一篇Go语法解析中我们知道,对于Var类型的声明,会解析到VarDecl结构体中。但是在Go标准库中,语法解析将Var、const、type、import声明都解析到GenDecl这个结构体中(叫通用声明)
// token.IMPORT *ImportSpec
// token.CONST *ValueSpec
// token.TYPE *TypeSpec
// token.VAR *ValueSpec
//
GenDecl struct {
Doc *CommentGroup // associated documentation; or nil
TokPos token.Pos // position of Tok
Tok token.Token // IMPORT, CONST, TYPE, VAR
Lparen token.Pos // position of '(', if any
Specs []Spec
Rparen token.Pos // position of ')', if any
}可以通过Tok字段来区分是哪种类型的声明
下边通过一个示例展示Var声明被语法解析之后的样子
const srcVar = `package test
var a = 6+7*8
`
func AstVar() {
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, "hello.go", srcVar, parser.AllErrors)
if err != nil {
log.Fatal(err)
}
for _, decl := range f.Decls {
if v, ok := decl.(*ast.GenDecl); ok {
fmt.Printf("Tok: %v\n", v.Tok)
for _, spec := range v.Specs {
ast.Print(nil, spec)
}
}
}
}
首先可以看到它的Tok是Var,表示他是Var类型的声明,然后它的变量名通过ast.ValueSpec结构体存放的,其实就可以理解成Go编译器中的VarDecl结构体
到这里就应该大致了解了基础面值、表达式、var声明,经过语法解析之后是什么样子。前边的概览中提到,抽象语法树阶段会将Go源文件中的各种声明,转换成一个一个的抽象语法树,即import、var、type、const、func声明都会成为一个根节点,根节点下边包含当前声明的子节点。下边就以var声明为例,看一下它是如何进行处理的
抽象语法树构建
每种声明的抽象语法树构建过程的思路差不多,里边的代码比较复杂,就不一行一行的代码去解释它们在做什么了,大家可以自己去看:src/cmd/compile/internal/gc/noder.go →decls()方法的内部实现
我这里仅以Var声明的语句为例,来展示一下在抽象语法树构建阶段是如何处理var声明的
Var声明语句的抽象语法树构建
在前边已经提到,抽象语法树构建的核心逻辑在:src/cmd/compile/internal/gc/noder.go →decls,当声明类型为*syntax.VarDecl时,调用p.varDecl(decl)方法进行处理
func (p *noder) decls(decls []syntax.Decl) (l []*Node) {
var cs constState
for _, decl := range decls {
p.setlineno(decl)
switch decl := decl.(type) {
......
case *syntax.VarDecl:
l = append(l, p.varDecl(decl)...)
......
default:
panic("unhandled Decl")
}
}
return
}下边直接看p.varDecl(decl)的内部实现
func (p *noder) varDecl(decl *syntax.VarDecl) []*Node {
names := p.declNames(decl.NameList) //处理变量名
typ := p.typeExprOrNil(decl.Type) //处理变量类型
var exprs []*Node
if decl.Values != nil {
exprs = p.exprList(decl.Values) //处理值
}
......
return variter(names, typ, exprs)
}我将该方法中调用的几个核心方法展示出来了,方法调用的都比较深,我下边会通过图的方式来展示每个方法里边都做了些什么事情
可以先回顾一下保存var声明的结构体长什么样
// NameList Type
// NameList Type = Values
// NameList = Values
VarDecl struct {
Group *Group // nil means not part of a group
Pragma Pragma
NameList []*Name
Type Expr // nil means no type
Values Expr // nil means no values
decl
}核心字段就是NameList、Type、Values,我们可以发现在上边的处理方法中,分别调用了三个方法来处理这三个字段
- names := p.declNames(decl.NameList),该方法就是将所有的变量名都转换成相应的Node结构,Node结构的字段在前边已经介绍过了,里边核心的字段就是Op,该方法会给每个Name的Op赋值为ONAME。所以该方法最终返回的是一个Node数组,里边是var声明的所有变量名
- p.typeExprOrNil(decl.Type),该方法是将一个具体的类型转换成相应的Node结构(比如int、string、slice等,var a int )。该方法主要是调用
expr(expr syntax.Expr)方法来实现的,它的核心作用就是将指定类型转换成相应的Node结构(里边就是一堆switch case) - p.exprList(decl.Values),该方法就是将值部分转换成相应的Node结构,核心也是根据值的类型去匹配相应的方法进行解析
- variter(names, typ, exprs),它其实就是将var声明的变量名部分、类型部分、值或表达式部分的Node或Node数组拼接成一颗树
前三个方法,就是将var声明的每部分转换成相应的Node节点,其实就是设置这个节点的Op属性,每一个Op就代表一个语义。然后第四个方法就是,根据语义将这些节点拼接成一棵树,使它能合法的表达var声明
下边通过一个示例来展示一下var声明的抽象语法树构建
示例展示var声明的抽象语法树
假设有下边这样一个var声明的表达式,我先通过标准库中提供的语法解析方法,展示它解析后的样子,然后再展示将该结果构建成抽象语法树之后的样子
const srcVar = `package test
var a = 666+6
`
func AstVar() {
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, "hello.go", srcVar, parser.AllErrors)
if err != nil {
log.Fatal(err)
}
for _, decl := range f.Decls {
if v, ok := decl.(*ast.GenDecl); ok {
fmt.Printf("Tok: %v\n", v.Tok)
for _, spec := range v.Specs {
ast.Print(nil, spec)
}
}
}
}
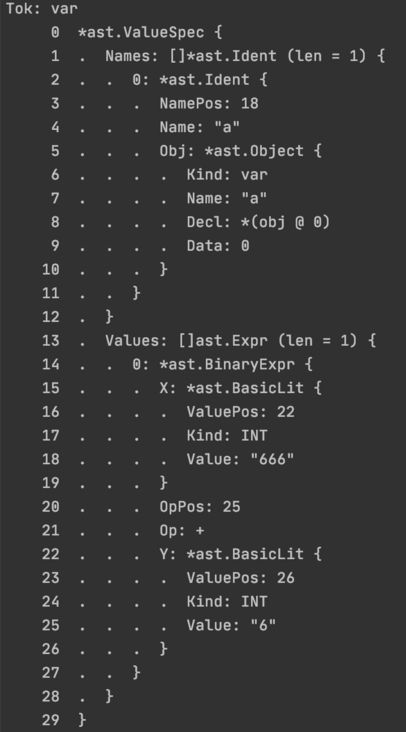
上边是语法分析之后的结果,然后是调用上边提到的那三个方法,将Names、Type、Values转换成Node结构如下:
Names:
ONAME(a)
Values:
OLITERAL(666)
OADD(+)
OLITERAL(6)
再通过variter(names, typ, exprs)方法将这些Node构建成一棵树如下:
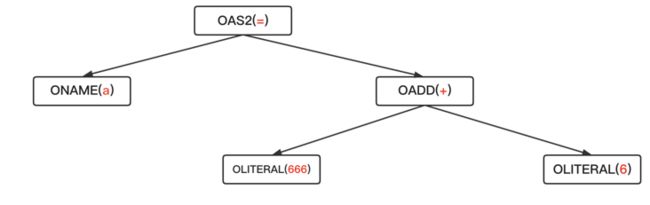
你可以通过下边方式去查看任何代码的语法解析结果:
const src = `你的代码`
func Parser() {
fset := token.NewFileSet() // positions are relative to fset
f, err := parser.ParseFile(fset, "", src, 0)
if err != nil {
panic(err)
}
// Print the AST.
ast.Print(fset, f)
}总结
本文先是从整体上认识了一下抽象语法树做了什么?以及它的作用是什么?源文件中的声明被构建成抽象语法树之后长什么样子?
然后通过标准库中提供的语法解析的方法,展示了基础面值、表达式、Var声明语句被解析之后的样子,然后以Var声明类型为例,展示了抽象语法树构建阶段是如何处理Var声明语句的
不管是在词法分析、语法分析、抽象语法树构建阶段还是后边要分享的类型检查等等,他们的实现必然有很多的细节,这些细节没法在这里一一呈现,本系列文章可以帮助小伙伴提供一个清晰的轮廓,大家可以按照这个轮廓去看细节。比如哪些var声明的使用是合理的、import有哪些写法,你都可以在Go编译的底层实现中看到
参考
- 《编译原理》
- 《Go语言底层原理剖析》
- go-ast-book