《本人也在学习中,如果有哪里不对欢迎指出》
介绍
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎
目前被广泛应用于互联网多种领域中,尤其是以下三个领域特别突出。
搜索领域,相对于solr,真正的后起之秀,成为很多搜索系统的不二之选。
Json文档数据库,相对于MongoDB,读写性能更佳,而且支持更丰富的地理位置查询以及数字、文本的混合查询等。
时序数据分析处理,目前是日志处理、监控数据的存储、分析和可视化方面做得非常好,可以说是该领域的引领者了。
定义

节点(node):物理概念,一个运行的Elasticearch实例,一般是一台机器上的一个进程。
索引(index):逻辑概念,包括配置信息mapping和倒排正排数据文件,一个索引的数据文件可能会分布于一台机器,也有可能分布于多台机器。索引的另外一层意思是倒排索引文件。
分片(shard):为了支持更大量的数据,索引一般会按某个维度分成多个部分,每个部分就是一个分片,分片被节点(Node)管理。一个节点(Node)一般会管理多个分片,这些分片可能是属于同一份索引,也有可能属于不同索引,但是为了可靠性和可用性,同一个索引的分片尽量会分布在不同节点(Node)上。分片有两种,主分片和副本分片。每个分片都是一个独立的Lucene索引,会消耗相应的文件句柄, 内存和CPU资源
副本(replica):es默认为一个索引创建5个主分片(分别有一个副本分片,copy),对于分布式搜索引擎,分片及副本是高可用及快速搜索响应的设计核心。当主分片丢失时,副本分片会自动选主
主分片和副本均可以处理查询请求,唯一区别在于只有主分片才能处理索引(增删改查?)请求
再上图中,使用es默认分片配置。自动把5个分片分配到2个节点上,而且各自分片的副本都在其他节点上。
额外的副本可以带来更大的容量,更高的吞吐能力及更强的容灾能力,也更耗资源。
集群运行中你无法调整分片设置。如果需要调整分片数量,只能新建创建并对数据进行重新索引(reindex,非常耗时)
基本概念
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
用Mysql这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
mapping相当于数据库表的定义
es集群架构

部署方式

混合部署(左
分层部署(右
es数据层架构
Elasticsearch的Index和meta,目前支持存储在本地文件系统中,同时支持niofs,mmap,simplefs,smb等不同加载方式,性能最好的是直接将索引LOCK进内存的MMap方式。默认,Elasticsearch会自动选择加载方式,另外可以自己在配置文件中配置。
集群构成
es集群由节点构成,节点有不同的类型。通过如下配置的true/false两两组合成4种类型
conf/elasticsearch.yml:
node.master: true/false
node.data: true/false
node.master为true的节点是master候选节点,可以参与选举。
node.data为true的节点是数据节点,会存储分配在该节点上的分片数据,并负责这些分片的写入/查询等
master和data都为false时,该节点类似与proxy节点,接受命令进行转发,结果聚合等
节点发现
es通过内部的ZenDiscovery模块实现节点发现以及选主等功能。
启动一个es节点时,通过单播方式,在给定的ip:port中,寻找具有相同集群名字并且可见的主节点。如果找到则加入集群,如果没找到就新建集群
master选举
原则
ES针对当前集群中所有的Master Eligible Node进行选举得到master节点,为了避免出现脑裂现象,ES选择了分布式系统常见的quorum(多数派)思想,也就是只有获得了超过半数选票的节点才能成为master。在ES中使用 discovery.zen.minimum_master_nodes 属性设置quorum,这个属性一般设置为 eligibleNodesNum / 2 + 1。
如何触发选举
当满足如下条件是,集群内就会发生一次master选举
当前master eligible节点当前状态不是master
该master-eligible节点通过ZenDiscovery模块的ping操作询问其已知的集群其他节点,没有任何节点连接到master。
集群中无法连接到master的master eligible节点数量已达到 discovery.zen.minimum_master_nodes 所设定的值
一句话总结,当包括自己在内的大多数master_eligible节点认为集群中没有master,则可以开始选举
如何选举
当某个节点决定要进行一次选举是,它会实现如下操作
寻找clusterStateVersion比自己高的master eligible的节点,向其发送选票
如果clusterStatrVersion一样,则计算自己能找到的master eligible节点(包括自己)中节点id最小的一个节点,向该节点发送选举投票。
这样做有利有弊
利:选举结果稳定,不会出现选不出来的情况
弊:极端情况下,master选举出来后负载过高,导致假死,重新选举后,原master恢复后,又被选成master,然后反复假死。
如果一个节点收到足够多的投票(即 minimum_master_nodes 的设置),并且它也向自己投票了,那么该节点成为master开始发布集群状态
其他选举方法
1.Zookeeper
事实上ES可以使用Zookeeper来进行master选举,方法如下
所有master eligible尝试在zk上创建指定路径
只有第一个节点能创建成功,该节点成为master,其余节点watch此路径
一旦zk失去master的连接,该路径被删除,其余master eligible继续尝试创建路径,同样只能有一个节点成功创建并成为master
重复以上步骤
Zookeeper来实现选主可以使得ES内部的选举算法变得非常的简单,至于为什么ES要自己发明一套轮子就不是很清楚了。
2.raft
有两个timeout :election timeout和heartbeat timeout
精髓在于随机时间election timeout(150ms-300ms),到期从follower变成candidate,时间到期之后开始新一轮(term)的选举并投了一票给自己。
candidate发送Request Vote message给其他节点
如果接受消息的节点还没有投票,就投票给该candidate,并刷新自己的election timeout(重新倒计时,倒计时结束没收到下一条心跳,则开始新的选举)。candidate收到大多数票后成为leader,发送Append Entries messages给followers,followers响应该消息,同时刷新自己的election timeout。直到follower停止接受心跳并成为candidate
3.raft与es比较
相同
与raft同为多数派原则;
选出的leader一定拥有最新的已提交数据
不同
raft是论证过正确性的;而es选举没有经过论证,只能在实践中做bug fix
raft有选举周期(term),可以保证每轮选举参与人仅投一票;而es不能
raft选举没有倾向性,只要节点拥有最新已提交数据,则有机会成为master;es按NodeId排序,NodeId小的优先级高。
小结
错误检测
两类
master定期检测集群内其他的节点;master发现节点失联,则会执行removeNode,然后同步集群状态。然后选择新的主分片或者副本,执行数据复制等操作。
集群内其他节点定期检测master;会清空pending在内存中还未commit的新的集群状态,然后发起rejoin,重新加入集群(如果达到选举条件则触发新master选举)
都是通过ping
集群缩扩容(水平)
这里只说DataNode,
扩容
配置好
conf/elasticsearch.yml:
node.master: false
node.data: true
cluster.name: es-cluster
node.name: node_Z
discovery.zen.ping.unicast.hosts: ["x.x.x.x", "x.x.x.y", "x.x.x.z"]
然后启动节点,节点会自动加入相同名字的集群,集群自动进行rebalance。也可以通过ewroute api 手动操作
缩容
设置分配规则,禁止分片分配到要缩容的机器,然后执行rebalance。执行完毕该节点即可安全下线。
索引
Elasticsearch索引的精髓:
一切设计都是为了提高搜索的性能
另一层意思:为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新,否则其他数据库不用混了。前面看到往Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields,比如上面例子中的name, sex, age, about, interests,那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默1的为这些字段建立索引--倒排索引,因为Elasticsearch最核心功能是搜索。
什么是B-Tree索引?
上大学读书时老师教过我们,二叉树查找效率是logN,同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读),传统关系型数据库采用了B-Tree/B+Tree这样的数据结构:
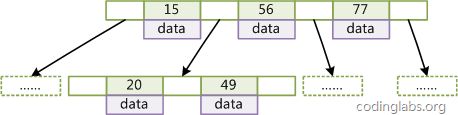
为了提高查询的效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一次寻道读取多个数据,同时也降低树的高度。
什么是倒排索引?

继续上面的例子,假设有这么几条数据(为了简单,去掉about, interests这两个field):
| ID | Name | Age | Sex |
| -- |:------------:| -----:| -----:|
| 1 | Kate | 24 | Female
| 2 | John | 24 | Male
| 3 | Bill | 29 | Male
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
| -- |:----:|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age:
| Term | Posting List |
| -- |:----:|
| 24 | [1,2] |
| 29 | 3 |
Sex:
| Term | Posting List |
| -- |:----:|
| Female | 1 |
| Male | [2,3] |
Posting List
ElasticSearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
看到这里,不要认为就结束了,精彩的部分才刚开始...
通过posting list这种索引方式似乎可以很快进行查找,比如要找age=24的同学,爱回答问题的小明马上就举手回答:我知道,id是1,2的同学。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:

这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
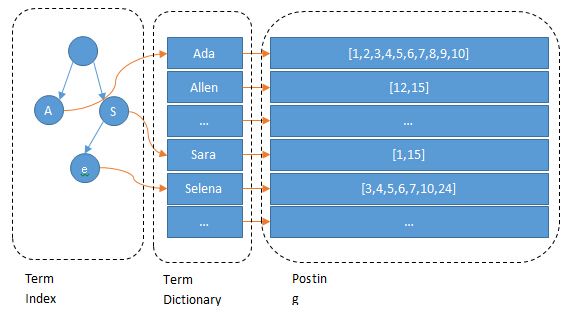
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
假设我们现在要将mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block位置)。最简单的做法就是定义个Map

⭕️表示一种状态
-->表示状态的变化过程,上面的字母/数字表示状态变化和权重
将单词分成单个字母通过⭕️和-->表示出来,0权重不显示。如果⭕️后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
FST以字节的方式存储所有的term,这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
压缩技巧
Elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧。
小明喝完咖啡又举手了:"posting list不是已经只存储文档id了吗?还需要压缩?"
嗯,我们再看回最开始的例子,如果Elasticsearch需要对同学的性别进行索引(这时传统关系型数据库已经哭晕在厕所……),会怎样?如果有上千万个同学,而世界上只有男/女这样两个性别,每个posting list都会有至少百万个文档id。 Elasticsearch是如何有效的对这些文档id压缩的呢?
Frame Of Reference
增量编码压缩,将大数变小数,按字节存储
首先,Elasticsearch要求posting list是有序的(为了提高搜索的性能,再任性的要求也得满足),这样做的一个好处是方便压缩,看下面这个图例:

如果数学不是体育老师教的话,还是比较容易看出来这种压缩技巧的。
原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是大大咧咧的尽管是2也是用int(4个字节)来存储。
Roaring bitmaps
说到Roaring bitmaps,就必须先从bitmap说起。Bitmap是一种数据结构,假设有某个posting list:
[1,3,4,7,10]
对应的bitmap就是:
[1,0,1,1,0,0,1,0,0,1]
非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性:
将posting list按照65535为界限分块,比如第一块所包含的文档id范围在0~65535之间,第二块的id范围是65536~131071,以此类推。再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。

细心的小明这时候又举手了:"为什么是以65535为界限?"
程序员的世界里除了1024外,65535也是一个经典值,因为它=2^16-1,正好是用2个字节能表示的最大数,一个short的存储单位,注意到上图里的最后一行“If a block has more than 4096 values, encode as a bit set, and otherwise as a simple array using 2 bytes per value”,如果是大块,用节省点用bitset存,小块就豪爽点,2个字节我也不计较了,用一个short[]存着方便。
那为什么用4096来区分大块还是小块呢?
个人理解:都说程序员的世界是二进制的,4096*2bytes = 8192bytes < 1KB, 磁盘一次寻道可以顺序把一个小块的内容都读出来,再大一位就超过1KB了,需要两次读。
联合索引
上面说了半天都是单field索引,如果多个field索引的联合查询,倒排索引如何满足快速查询的要求呢?
利用跳表(Skip list)的数据结构快速做“与”运算,或者
利用上面提到的bitset按位“与”
先看看跳表的数据结构:

将一个有序链表level0,挑出其中几个元素到level1及level2,每个level越往上,选出来的指针元素越少,查找时依次从高level往低查找,比如55,先找到level2的31,再找到level1的47,最后找到55,一共3次查找,查找效率和2叉树的效率相当,但也是用了一定的空间冗余来换取的。
假设有下面三个posting list需要联合索引:

如果使用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。
如果使用bitset,就很直观了,直接按位与,得到的结果就是最后的交集。
分片
分片的额外成本
分片不是越多越好,每个分片都是有额外的成本:
每个分片本质上就是一个Lucene索引,因此会消耗相应的文件句柄,内存和cpu资源
每个搜索请求会调度到索引的每个分片中,如果当分片分到同一个节点,竞争相同的硬件资源时,性能会下降
ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差
分片原则:
es推荐的最大JVM堆空间是30-32G,所以把分片最大容量限制为30GB,然后根据数据量计算分片数。例如,一个数据预计能达到200G的索引,推荐分8个左右分片。
不过, 你最好还是能描述出每个节点上只放一个索引分片的必要性. 在开始阶段, 一个好的方案是根据你的节点数量按照1.5~3倍的原则来创建分片. 例如,如果你有3个节点, 则推荐你创建的分片数最多不超过9(3x3)个.
随着数据量的增加,如果你通过集群状态API发现了问题,或者遭遇了性能退化,则只需要增加额外的节点即可. ES会自动帮你完成分片在不同节点上的分布平衡.
再强调一次, 虽然这里我们暂未涉及副本节点的介绍, 但上面的指导原则依然使用: 是否有必要在每个节点上只分配一个索引的分片. 另外, 如果给每个分片分配1个副本, 你所需的节点数将加倍. 如果需要为每个分片分配2个副本, 则需要3倍的节点数. 更多详情可以参考基于副本的集群.
总结和思考
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:
不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询
关于最后一点,个人认为有多个因素:
其中一个(也许不是最重要的)因素: 上面看到的压缩算法,都是对Posting list里的大量ID进行压缩的,那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高;
另外一个因素: 可能是最影响查询性能的,应该是最后通过Posting list里的ID到磁盘中查找Document信息的那步,因为Elasticsearch是分Segment存储的,根据ID这个大范围的Term定位到Segment的效率直接影响了最后查询的性能,如果ID是有规律的,可以快速跳过不包含该ID的Segment,从而减少不必要的磁盘读次数,具体可以参考这篇如何选择一个高效的全局ID方案(评论也很精彩)
type keyword(not_analyzed) vs text(使用分词)
https://blog.csdn.net/wwd0501/article/details/78091720
删除文档的时候只是标记成已删除,es会在之后添加更多索引的时候在后台自动删除
通过文档的version版本控制 进行 乐观并发控制
bulk请求不是原子操作——它们不能实现事务。每个请求操作时分开的,所以每个请求的成功与否不干扰其它操作。
索引分片的作用
默认索引5个分片及1个副本(每个分片都有一个副本,共10个Lucene索引在集群中)
分片的优点:
修改记录时:
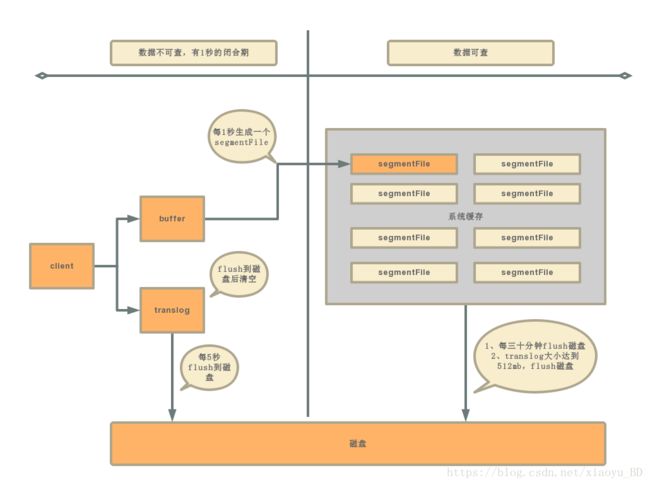
ranslog是保证es数据安全的关键所在,增加flush的频率可以减少数据丢失的风险,但是所带来的是非常大的性能开销,所以生产上要根据具体的业务需求来进行配置的优化。对实时要求不高的长久,可以考虑增加refresh的时间间隔,这会很有效的提升性能。
Lucene中存储的索引主要分为三种类型:
Invert Index,即倒排索引。通过term可以快速查找到包含该term的doc_id。如果Field配置分词,则分词后的每个term都会进入倒排索引,如果Field不指定分词,那该Field的value值则会作为一个term进入倒排。(这里需要注意的是term的长度是有限制的,如果对一个Field不采取分词,那么不建议该Field存储过长的值。关于term超长处理)
DocValues,即正排索引。采用的是类似数据库的列式存储。对于一些特殊需求的字段可以选择这种索引方式。
Store,即原文。存储整个完整Document的原始信息。
写入
Elasticsearch采用多Shard方式,通过配置routing规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能。当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引。这样就能实现分布式了。

每个Index由多个Shard组成,每个Shard有一个主节点和多个副本节点,副本个数可配。但每次写入的时候,写入请求会先根据_routing规则选择发给哪个Shard,Index Request中可以设置使用哪个Filed的值作为路由参数,如果没有设置,则使用Mapping中的配置,如果mapping中也没有配置,则使用_id作为路由参数,然后通过_routing的Hash值选择出Shard,最后从集群的Meta中找出出该Shard的Primary节点。
请求接着会发送给Primary Shard,在Primary Shard上执行成功后,再从Primary Shard上将请求同时发送给多个Replica Shard,请求在多个Replica Shard上执行成功并返回给Primary Shard后,写入请求执行成功,返回结果给客户端。
优点:可靠性高
缺点:时延高
采用多个副本后,避免了单机或磁盘故障发生时,对已经持久化后的数据造成损害,但是Elasticsearch里为了减少磁盘IO保证读写性能,一般是每隔一段时间(比如5分钟)才会把Lucene的Segment写入磁盘持久化,对于写入内存,但还未Flush到磁盘的Lucene数据,如果发生机器宕机或者掉电,那么内存中的数据也会丢失,这时候如何保证?
对于这种问题,Elasticsearch学习了数据库中的处理方式:增加CommitLog模块,Elasticsearch中叫TransLog。


update

Lucene中不支持部分字段的Update,所以需要在Elasticsearch中实现该功能,具体流程如下:
收到Update请求后,从Segment或者TransLog中读取同id的完整Doc,记录版本号为V1。
将版本V1的全量Doc和请求中的部分字段Doc合并为一个完整的Doc,同时更新内存中的VersionMap。获取到完整Doc后,Update请求就变成了Index请求。
加锁。
再次从versionMap中读取该id的最大版本号V2,如果versionMap中没有,则从Segment或者TransLog中读取,这里基本都会从versionMap中获取到。
检查版本是否冲突(V1==V2),如果冲突,则回退到开始的“Update doc”阶段,重新执行。如果不冲突,则执行最新的Add请求。
在Index Doc阶段,首先将Version + 1得到V3,再将Doc加入到Lucene中去,Lucene中会先删同id下的已存在doc id,然后再增加新Doc。写入Lucene成功后,将当前V3更新到versionMap中。
释放锁,部分更新的流程就结束了。
delete
执行delete时,不会真正的删除,而是标记为删除,查询后会过滤掉,等到segment merge的时候才真正的删除。
es存储模块
可以允许用户控制索引的存储方式(存储在磁盘)
简单文件系统存储
index.store.type = simplefs
这是一个随机访问文件的文件存储系统,并发性能较差,多线程下存在性能瓶颈问题。如果我们想对ESSearch索引做持久化,推荐使用niofs。
新I/O文件系统存储
index.store.type = niofs
通过NIO将分片索引文件写到文件系统上,允许多线程同时读取文件。
MMap文件系统存储(非windows系统默认)
index.store.type = mmapfs
将索引分片存储到文件系统上,再通过映射,将索引文件映射到内存中。map即为映射的意思。不过我们需要注意:索引文件映射到内存过程中,我们需要划分出与被映射文件大小一样的虚拟内存空间。
MMap FS / NIO FS
index.store.type = default_fs
它会为每个类型的文件选择最好的文件系统。
查询
es两种使用场景,搜索和NoSQL
工作原理
搜索场景近实时二阶段查(query then fetch)返回最满足条件的TopN要求最终一致性
NoSQL场景实时一阶段直接返回返回满足条件的所有结果要求强一致性
搜索场景:近实时的,需要分散(scatter phase)查询到多个节点中,得到结果,合并(gather phase)它们,按分值排序,返回给客户。
NoSQL场景:实时的,通过DocID直接查translog,查到具体值即返回。

1.搜索场景
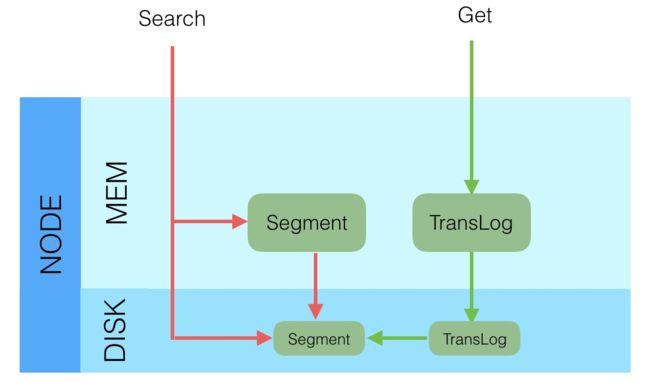
2.NoSQL场景(右)
两类查询
Search
一起查内存和磁盘上的segment,将结果合并返回,因为内存中的index需要一段时间refresh到新的segment,所以是近实时的
Get
先查TransLog,查到即返回,没查到接着查磁盘中的TransLog,还没查到就查磁盘中的Segment。实时的
我们可以在一定程度上控制查询
搜索类型:
根据关注点,注重性能或是注重相关性结果,选择不同的搜索类型
QUERY_THEN_FETCH (默认)
第一次查询匹配到的DocID,第二次查询DocID对应的完整文档。查一次shard,返回数据量准确,score不准,速度一般
QUERY_AND_FEATCH
查一次,score和内容一起返回,速度块,数据量过多,score不准
DFS_QUERY_THEN_FEATCH
对比第一种多了dfs操作,也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作。都准,但是性能差。
DFS_QUERY_AND_FEATCH
搜索执行偏好:
除了可以控制查询方法,还可以控制在哪些分片上执行查询
随机查询数据(es默认方式)
_local:优先本地节点上的分片查询数据,然后再去其他节点上的分片查询。本地节点查没有IO问题但可能会负载不均。
_primary:只在主分片中查询
_primary_first:优先主分片
_only_node:指定节点id中的分片查询,数据可能不完整
_perfer_node:优先在指定节点中查询
_shards:指定分片中查询,数据可能不完整
es查询存在两个问题:
(1)返回数据量问题
(2)返回数据排名问题
解决思路:
(1)返回数据数量问题
第一步:先从每个分片汇总查询的数据id,进行排名,取前10条数据
第二步:根据这10条数据id,到不同分片获取数据
(2)返回数据排名问题
将各个分片打分标准统一
ps:
es5.*以后就没有string类型,引入text,keyword字段。
text:存储数据时候,不会分词建立索引
keyword:存储数据时候,会自动分词,并生成索引
FAQ
全文搜索(使用es)的优势?适合什么样的场景?
特点(优势):
可以作为一个大型分布式集群,处理pb级数据。
近实时更新
3分钟部署,开箱即用,非常简单
适合场景:
维基百科;stack overflow问题和答案的全文检索;github 千亿行代码搜索;电商网站 搜索商品;ELK 数据分析
怎么查询的?查询原理是什么?
数据是怎么存储的?索引是怎么存储的?
分布式相关的,怎么扩展?怎么处理故障?
选举怎么保证不脑裂(选出多个)?
多数派策略,设置minimum_master_nodes为eligibleNodesNum / 2 + 1即可
其实像百度google这样的搜索引擎,最核心的都是建立倒排索引,只不过更复杂一点,包括网页抓去,停顿词过滤等等。
搜索引擎三大内容
爬取内容
进行分词
建立反向索引
es集群中也有master和slave节点的区分
建立索引(mapping的时候也一样)的时候就是先通知master,然后master再将集群状态同步给slaves