云时代的来临导致很多同学不在那么关心基础硬件的选型上面了,很庆幸的玩过了各种磁盘介质,1w 转企业级 STAT * 8 Raid 10 「BBU、内置闪存」到 SSD 到 Pcie SSD,也算见证了在不优化任何代码的前提下,我们用磁盘抗住了一波波的进攻。「云时代对应的是啥,升配啊。。。」
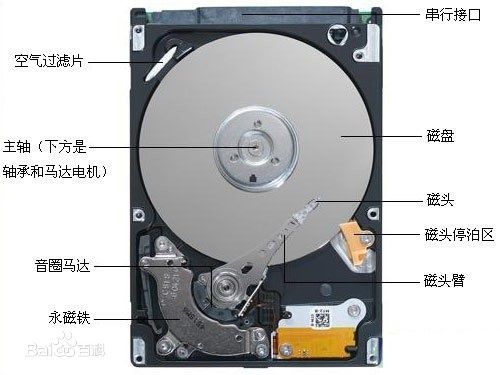
机械硬盘
看图就能看出这个就是一个完全拼转速,拼多碟的冬冬,可以提高的空间也能想象要么盘更多,要么提高单次磁头旋转的效率 「传统优化数据库所有很多系统批量操作,随机转顺序很大程度上面是存储介质的限制了太多的想象。」,为了提高存储的可用性,自然而然的出现了 Raid 卡这样一个东西,raid卡通过多盘绑定 raid0、raid10、raid6 等实现了性能与安全性的平衡,raid 并非上了就高枕无忧了,需要考虑 BBU 充放电的情况,此时基本上就无法利用raid卡本身的cache 「这个也是可以监控的」,所以后来出现了直接在 raid 卡上面放一个小闪存的东西。「多年前在测试 MySQL 的时候还发现了当STAT * 8 Raid 10,基本上就已经到达Raid卡的瓶颈了,而且之后在高性能 MySQL 一书中作者也提高了这个情况」
SSD
第一次接触这个东西,也是在公司 DB 到达瓶颈,又不想拆的情况下,我们直接上了一批 SSD 接着么什么 Slow Query 不存在的。
SSD 全称 Solid State Disk,就是大家平时提到的固态硬盘,是一种完全由电子元器件组成的持久化存储设备,这是和传统机械硬盘(Hard Disk Drive,简称 HDD)的重要区别。SSD 和机械硬盘相比,有着更高的 IOPS,更高的带宽,更低的访问 latency,还兼容目前主流的 HDD 接口,比如 SATA SAS 等。现在市场上的 SSD 主要都是基于 NAND Flash 的。
SSD 主要组件
1. 控制器芯片
2. NAND 芯片
3. 电容,掉电保护,保证数据安全性
4. DRAM,缓存元数据
5. 对外接口,图中是 SATA 接口
6. NOR Flash,引导 SSD

NAND 芯片
NAND 是存储最终数据的介质,NAND 实际上是一种 EEPOM(加电可擦除可编程 ROM),最基本的组成单位称作 cell,而 cell是一种类似 MOSFET(金属-氧化层 半导体场效晶体管)的电子元件。主要的部分是 ControlGate(控制闸,简称 CG)和 Floating Gate(浮动闸,简称 FG)。CG 的作用就是通过加不同电压来对 FG 进行充放电,改变 cell 存储的 bit FG是一个与周围绝缘的氧化物层,电子可以在 FG 里长久保存而不会轻易泄露,这也是 NAND存储数据非易失的原因。
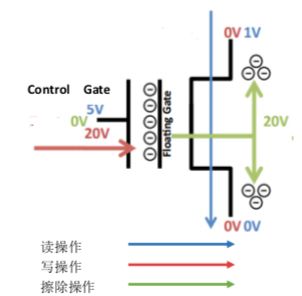
上图也介绍了针对 cell 的三种操作,分别是读操作 写操作和擦除操作,先假设每个 cell 只 存储一个 bit
读操作,在 CG 上加 5V 的电压,然后根据读到电压值去判断这个 cell 存储的 是 0 还是 1
写操作,在 CG 上加 20V 电压,电子被 FG 捕获,相当于一个充电过程。一般 写之后还会进行读校验,判断写入是否成功,正常写入完应该是 0
擦除操作,加电压的方向和写操作正好是相反的,作用也是相反的,相当于对 FG 的一个放电过程,擦除完成 cell 代表的是 1

Cell 组成 Page,Page 组成 Block,Block 组成 Plane,Plane 组成 Die,多个 Die 最终封装成我 们之前看到的 NAND 芯片。从上面组成中我们重点分析一下 Page 和 Block。Page 主要由两部分组成,Main 和 OOB 两部分,Main 主要是存储实际写的数据,而 OOB 主要存储一些元数据信息和 ECC 信息,Page 在出厂时一般是 0xFF,也就是全部擦出过一遍。 Block 是由一组 Page 来组成。并且还有很重要的一点就是,Page 是 SSD 最小的读写单位,而 Block 是最小的擦除单位,这 就造成了所谓的写入放大问题(Write Amplification)。SSD 按照 Block 去擦除,这样做的原因一 方面是由于底层电路设计限制,另一方面原因是为了 SSD 本身寿命和响应时间考虑。
Garbage collection
垃圾回收指的是回收已经失效的数据页,当然最终回收的时候还是以 block 为单位的。为什么 SSD 需要垃圾回收,而传统硬盘不需要呢。主要有两点原因构成:不支持 In Place Update 和擦除单位最小是 block。我们先引入一个概念 Write amplification 「写入放大」
上面的公式右边被称为写入放大因子,公式是放大因子计算方法。写入放大的原因也是我们之前提到的 SSD 不支持数据覆盖写。从 SSD 写入原理来看,写入放大因子一般是大于 1 的,目前企业级 SSD 的写入放大因子一般都在 1.1 左右。

1.首先在数据块 X 的四个可 用页里写入 A-D 现在垃圾回收一般都是在后台去执行,垃圾回收对 读写影响还是会比较大的,所以要控制好这个速度,既要保证当前可用空闲块比 例,也要保证尽可能不要影响 写入能力。 提到垃圾回收,还涉及到另外 两个概念:
1) Trim
Trim 是一个 ATA 指令。由操作系统发送给 SSD 主控制器,告诉它哪些数据占的地址是“无效”的,避免不必要的垃圾回收迁移数据。
2) Over-provisioning
OP 简单来说就是预留空间,SSD 出厂时候一般都有预留,出厂 OP 空间比例在 10%左右,用户也可以自己预留 OP。OP 可以用于磨损调度和垃圾回收,OP 空 间越大,性能越好越稳定,寿命越久,写入放大比例越低。上面的 Trim 和 OP 都是对垃圾回收效率和提高寿命有好处的。「如果需要较高性能、建议越大越好 个人建议 20%」
2.在数据块 X 写入 E-H,然后 对 A-D 进行更新,然后把新 数据写入到 A’-D’,A-D 标记 为无效
3.为了使 A-D 数据页可用, 就只能把 E-H 和 A‘-D’复制到 数据块 Y,然后擦除数据块 X
Bad Block Management(坏块管理)和 ECC
关于坏块管理,同样可以监控也必须要监控,先说一下坏块的来源,第一是出厂时候有一定的坏块比例,这个比例 MLC 一般控制在 5%,SLC 一般控制在 2%。第二是随着读写次数增加,导致 cell电子泄漏,无法修复就变成坏块。控制器会维护一张坏块表,记录哪些数据块是不可用的。ECC 算法是保证 SSD 数据可靠性和寿命的一个非常重要的特性。尤其在 NAND 制程越来越低的情况下,cell 之间的距离越来越小,读写都有可能造成对邻近 cell 的状态变化。
个人总结
目前企业级 SSD 主要是两种类型,分别是 SATA SSD 和 Pcie SSD,建议在核心实例上面「前提自建IDC」直接考虑Pcie SSD「自带Raid 5」,在高吞吐量的分布式数据库中,自带缓存层或者冷热数据分离功能的数据库,直接将类似数据丢到 SSD 中去,提高瞬时抗压能力,提高稳定性。「其实 STAT SSD 和 Pcie SSD 最最底层的闪存颗粒是一样的,只是在接口、与内置调度器算法上面有巨大的差异」。很多数据库厂商与硬件厂商已经在各种尝试软硬结合的解决方案了,在计算存储分离的趋势下,其实可以将大量的计算操作下沉到最最底层的硬件服务器上面去执行,来帮助计算节点提高效率,同样在云上面的大量架构都是类似的逻辑,没有绝对的计算存储分离都是相对的、是互助的。重复利用基础软件设计 & 底层硬件的优势发挥最大的效能「是不是也是一种提高效率的表现」。
感谢 微博 zolker 的分享 「漫谈SSD原理与应用实践」,借鉴学习了很多。