本地广播和全局广播的区别
BroadcastReceiver 是跨应用广播,利用Binder机制实现,支持动态和静态两种方式注册方式。
LocalBroadcastReceiver 是应用内广播,利用Handler实现,利用了IntentFilter的match功能,提供消息的发布与接收功能,实现应用内通信,效率和安全性比较高,仅支持动态注册。
广播细分为三种:
普通广播
有序广播
本地广播
普通广播是什么?
调用sendBroadcast()发送
有序广播是什么?
调用sendOrderedBroadcast()发送
广播接收者会按照priority优先级从大到小进行排序
优先级相同的广播,动态注册的广播优先处理
广播接收者还能对广播进行截断和修改
本地广播的优点?
效率更高。
发送的广播不会离开我们的应用,不会泄露关键数据。
其他程序无法将广播发送到我们程序内部,不会有安全漏洞。
SharedPreference相关
请不要滥用SharedPreference
1.注意点
不要存放大的key和value!我就不重复三遍了,会引起界面卡、频繁GC、占用内存等等,好自为之!
毫不相关的配置项就不要丢在一起了!文件越大读取越慢,不知不觉就被猪队友给坑了;蓝后,放进defalut的那个简直就是愚蠢行为!
读取频繁的key和不易变动的key尽量不要放在一起,影响速度。(如果整个文件很小,那么忽略吧,为了这点性能添加维护成本得不偿失)
不要乱edit和apply,尽量批量修改一次提交!
尽量不要存放JSON和HTML,这种场景请直接使用json!
不要指望用这货进行跨进程通信!!!
2.sp较大时的问题
如果你的sp文件比较大,那么会带来几个严重问题:
第一次从sp中获取值的时候,有可能阻塞主线程,使界面卡顿、掉帧。
解析sp的时候会产生大量的临时对象,导致频繁GC,引起界面卡顿。
这些key和value会永远存在于内存之中,占用大量内存。
加载进来的这些大对象,会永远存在于内存之中,不会被释放。我们看看ContextImpl这个类,在getSharedPreference的时候会把所有的sp放到一个静态变量里面缓存起来。
private ArrayMap getSharedPreferencesCacheLocked() {
if (sSharedPrefsCache == null) {
sSharedPrefsCache = new ArrayMap<>();
}
final String packageName = getPackageName();
ArrayMap packagePrefs = sSharedPrefsCache.get(packageName);
if (packagePrefs == null) {
packagePrefs = new ArrayMap<>();
sSharedPrefsCache.put(packageName, packagePrefs);
}
return packagePrefs;
}
注意这个static的sSharedPrefsCache,它保存了你所有使用的sp,然后sp里面有一个成员mMap保存了所有的键值对;这样,你程序中使用到的那些个sp永远就呆在内存中.
3.commit和apply区别
SharedPreference 相关修改使用 apply 方法进行提交会先写入内存,然后异步写入磁盘,commit方法是直接写入磁盘。如果频繁操作的话 apply 的性能会优于 commit,apply会将最后修改内容写入磁盘。
但是如果希望立刻获取存储操作的结果,并据此做相应的其他操作,应当使用 commit。
4.【SharedPreferences问题】
容易导致ANR
可能造成ANR的原因有:
①同步提交:commit是同步的,知道磁盘操作成功后才会完成
所以当数据量比较大时,使用commit可能引起ANR。
②异步提交:当写入数量比较大时,使用apply也可能引起ANR。
apply()是将写入任务加入到队列中,而写入任务在一个线程中执行。
当生命周期处于 handleStopService() 、handlePauseActivity() 、handleStopActivity()时会调用QueuedWork.waitToFinish() 会等待写入任务执行完毕。
waitToFinish() :会一直等待写入任务执行完毕,其它什么都不做
当有很多写入任务,会依次执行;当文件很大时,效率很低,则容易造成 ANR
③获取数据getXX()导致的
所有 getXXX() 方法都是同步的,都是操作内存。在主线程调用 get 方法,必须等待 SP 加载完毕,也有可能导致ANR
为什么Dialog的Context不能是ApplicationContext?
Activity 对应的 Window/WMS 都是持有这个 mToken 的。结合之前 Application 创建 Dialog 的报错信息, Application Context 创建 Dialog 的过程中,并没有实例化类似的 token.
Android 不允许 Activity 以外的 Context 来创建和显示普通的 Dialog
Token 是 ActivityRecord 的静态内部类,它持有外部 ActivityRecord 的弱引用。
startService和bindService区别
github解答
android横竖屏切换生命周期
github解答
ContentProvider、ContentResolver、ContentObserver关系
github解答
对 Activity.runOnUiThread 的理解?
一般是用来将一个runnable绑定到主线程,在runOnUiThread源码里面会判断当前runnable是否是主线程,如果是直接run,如果不是,通过一个默认的空构造函数handler将runnable post 到looper里面,创建构造函数handler,会默认绑定一个主线程的looper对象
子线程是否能更新UI
子线程能更新UI,但是不推荐这么做。一般说的子线程不能更新UI,是因为执行更新UI操作的时候会进行checkThread检查,checkThread判断如果当前线程不是UI线程就会抛出异常。更新UI时会调用ViewRootImpl的requestLayout方法,其中会调用checkThread
方法检查是否是当前线程。而checkThread跟ViewRootImpl这个类的对象有关,那么只要ViewRootImpl的对象还未创建,就无法执行checkThread,也就是在子线程更新UI也不会报错。ViewRootImpl的对象是在onResume()之后创建的,因此在onCreate()、onStart()、onResume()中可以做子线程更新UI
【Window和DecoreView关系】
github解答
Window 是 WindowManager 最顶层的视图,它负责背景(窗口背景)、Title之类的标准的UI元素,Window 是一个抽象类,整个Android系统中, PhoneWindow是 Window 的唯一实现类。至于 DecorView,它是一个顶级 View,内部会包含一个竖直方向的LinearLayout,这个 LinearLayout 有上下两部分,分为 titlebar 和 contentParent 两个子元素,contentParent 的 id 是 content,而我们自定义的 Activity 的布局就是 contentParent 里面的一个子元素。View 层的所有事件都要先经过 DecorView 后才传递给我们的 View。 DecorView 是 Window 的一个变量,即 DecorView 作为一切视图的根布局,被 Window 所持有,我们自定义的 View 会被添加到 DecorView ,而DecorView 又会被添加到 Window 中加载和渲染显示。此处放一张它们的简单内部层次结构图:

Windows 的创建是在 Activity 的 attach 方法中创建的,直接 new 了个 PhoneWindows 对象,而 WindowsManager 的创建是在 Activity 的 attach 方法中,创建完 Windows 后,通过 Windows 的 setWindowManager 方法创建的 WindowsManager,我觉得 WindowsManager 的创建是通过 Windows 去创建的。
具体的 Windows 是怎么创建的 WindowsManager ? 它是在 ContextImpl 中通过 SystemServiceRegistry.getSystemService(this, name); 中通过服务名称获取的 WindowsManager,WindowsManager 是放在一个 HashMap 当中的,是在 SystemServiceRegistry 初始化的时候已经创建好了 WindowManagerImpl
自定义View的流程
github解答
【针对RecyclerView的优化】
github解答,超nice、
RecyclerView的几种刷新方式
刷新全部可见的item,notifyDataSetChanged()
刷新指定item,notifyItemChanged(int)
从指定位置开始刷新指定个item,notifyItemRangeChanged(int,int)
插入、移动一个并自动刷新,notifyItemInserted(int)、notifyItemMoved(int)、notifyItemRemoved(int)
局部刷新,notifyItemChanged(int, Object)
差量跟新DiffUtil原理是指定位置刷新
RemoteViews
github解答
View.post()为什么可以获取到宽高信息?
github解答
下面来分析一下:
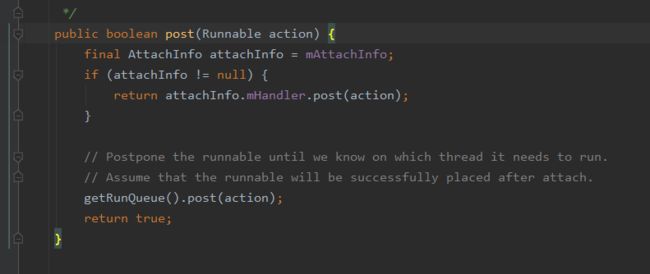

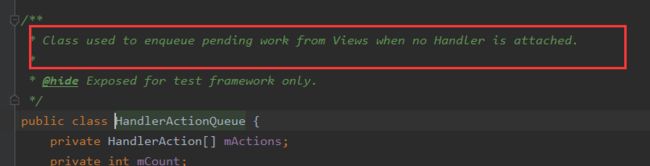
在View还没有绘制时,确切的说View的Handler还没有绑定时,会将runnable缓存到HandlerActionQueue中。在ViewRootImpl初始化时,创建了一个View.AttachInfo对象并绑定ViewRootImpl的Handler,该Handler用于发送View绘制相关的msg。
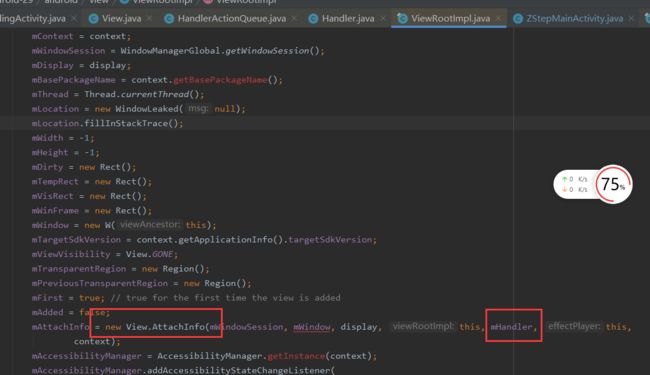
等到ViewRootImpl执行performTraversals方法时(此时Activity已经回调了onResume),会配置View的AttachInfo对象,并且通过View的dispatchAttachedToWindow方法传入到View里面绑定,在该方法中会取出View缓存的Runnable并用View.AttachInfo的Handler来进行post方法,这样此Runnable会加入到MessageQueue里排队。因为UI刷新中的内存屏障(SyncBarriar)的存在,会优先执行Vsync异步消息,等到这些缓存的Runnable执行时,主线程里的View绘制流程也就结束了,这时候Looper取出这些缓存的Runnable执行时就可以拿到View的宽高。
那什么时候View.post不会执行呢?如果Activity因为某些原因没有执行到onResume,无法顺利调用ViewRootImp的performTraversals的话,View.post方法就不会执行。
属性动画的估值器和差值器
1、插值器,根据时间(动画时常)流逝的百分比来计算属性变化的百分比。系统默认的有匀速,加减速,减速插值器。
2、估值器,根据插值器得到的百分比计算出具体变化的值。系统默认的有整型,浮点型,颜色估值器
3、自定义只需要重写他们的evaluate方法就可以了。
getDimension、getDimensionPixelOffset 和 getDimensionPixelSize 三者的区别?
getDimension()返回的float绝对尺寸,getDimensionPixelOffset返回取整绝对尺寸 int类型,getDimensionPixelSize四舍五入返回int类型
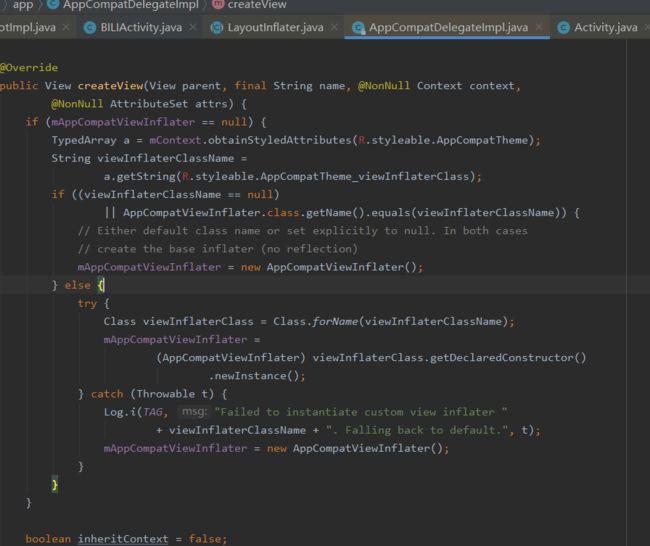
LayoutInflater是如何通过inflate方法获取到具体View的?
github解答
系统通过LayoutInflater.from创建出布局构造器。inflate方法中,会调用createViewFromTag方法,其内部调用的tryCreateView方法会优先调用factory2的onCreateView方法

走到AppCompatDelegateImpl#createView方法中通过反射创建View。
【Fragment懒加载-TODO实际使用】
参考博客
参考博客2
实现Fragment懒加载的策略是:判断Fragment是否可见,可见的时候才加载数据。
涉及到Fragment的两个方法:
setUserVisibileHint(boolean isVisibleToUser)和onHiddenChanged(boolean hidden).
setUserVisibleHint
setUserVisibleHint()方法只有在使用ViewPager管理Fragment时才会调用,有一个参数isVisibleToUser,也就是是否对于用户可见。
每个Fragment的setUserVisibleHint()方法都会至少执行两次,一次是在Fragment的生命周期方法执行之前,此时isVisibleToUser的值为false;一次是在Fragment变为可见时,此时isVisibleToUser的值为true。
onHiddenChanged
onHiddenChanged()方法只有在利用FragmentManager管理Fragment,并且使用hide()和show()方法切换Fragment时才会被调用,该方法同样有一个参数hidden,表示Fragment是否隐藏.
加载思路
要在Fragment可见时加载数据,并且只加载一次。
由于ViewPager的预加载机制,因此要利用setUserVisibleHint()方法,根据参数isVisibleToUser来判断Fragment是否可见。
setUserVisibleHint()方法不止会在Fragment切换时调用,在onCreateView()之前也会被调用,此时isVisibleToUser的值为false,这时是获取不到视图和控件的,因此不能只根据isVisibleToUser来判断是否需要加载数据,需要引入一个变量标识视图是否已经加载完成。
由于加载数据后继续切换ViewPager仍然会执行setUserVisibleHint()方法,因此还需要引入一个变量标识是否已经加载过数据,防止数据的重复加载。
只有当同时满足以下三个条件时才加载数据:
视图已加载完成
数据未加载
Fragment可见
【RecyclerView缓存机制】
经典博客
RecyclerView主要有三级缓存:
①AttachedScrap & ChangedScrap
②CachedViews
③RecyclerViewPool
我们逐个分析(摘录参考博客里的关键点)
(1)AttachedScrap & ChangedScrap
分别对应两个ViewHolder的ArrayList:
ArrayList
ArrayList
在插入或者删除itemView时,先把屏幕内的ViewHolder保存至AttachedScrap中,把需要从ViewGroup中移除的子View的父View置为null。
而新插入的View从CachedView/RecyclerViewPool中查找,没找到则createViewHolder。
而ChangedScrap主要用于刷新屏幕上的itemView数据,不需要重新layout、notifyItemChanged或者notifyRangeChanged.
(2)CachedViews
也对应一个ViewHolder列表:
ArrayList
保存最近移出屏幕的ViewHolder,包含数据和position信息,复用时必须是相同位置的ViewHolder才能复用,来回滑动时,能直接复用ViewHolder数据,不需要重新bindView。
(3)RecyclerViewPool
缓存池,当CachedView满了之后,将CachedView中移除的ViewHolder放到Pool中,放之前会把ViewHolder的数据清除掉,所以复用时需要重新bindView,按viewType来保存ViewHolder,每种类型最大缓存个数默认为5.
缓存过程
在滑动过程中,会先将滑动走的itemView(ViewHolder)保存到CachedViews中,CachedViews大小默认是2,如果超过了最大容量,按照FIFO将头部的itemView出队,保存至缓存池RecyclerViewPool中,缓存池是按itemView的类型viewType来保存的,每种itemType默认缓存个数是5,如果超过,则直接由GC回收。
获取缓存过程
先在缓存CachedViews中查找,找到则直接复用;
如果在缓存池RecyclerViewPool中找到,则需要bindView;
如果没有找到可用的ViewHolder,则需要create新建一个ViewHolder,走onCreateViewHolder,并bindView走onBindViewHolder。
【RecyclerView优化】
同样是上面的参考博客
1.recyclerView.setHasFixedSize(true)
当item的高度是固定时,可以设置此属性,当插入或者删除时性能提升很明显。
RecyclerView在条目改变,会重新measure/layout各个item。当设置了此属性时,不会整个布局都重绘。
2.getExtraLayoutSpace为LayoutManager设置更多预留空间
场景:当RecyclerView元素较高,一屏只能显示一个元素时,第一次滑动到第二个元素会卡顿。
在屏幕可见范围内,如果只有一张卡片可见,当滚动时,RecyclerView找不到可重用的view(第一个卡片还无法复用,只是保存到内存中,如果复用了,第一个卡片滑下来一点就会回收掉,就会很奇怪),就会创建一个新的,因此滑动到第二个卡片是会有一定延迟,但第二个卡片之后滚动是流畅的,因为这时RecyclerView中已经有能重用的view了。
3.RecyclerView数据获取
参考
4.避免创建过多对象
在onCreateViewHolder和onBindViewHolder中要尽量避免繁琐的操作和循环创建对象。例如onClickListener,可以在ViewHolder中创建一个全局的onClickListener。
5.局部刷新
使用notifyItemChanged、notifyItemInserted等方法,以及DiffUtil来替代notifyDataSetChanged,来达到局部刷新的目的。
6.重写onScroll事件
滑动暂停后再加载图片。
7.RecyclerView缓存
①setItemViewCacheSize
设置所需要的ViewHolder缓存数量,默认大小是2,实际上就是CachedViews大小。超过2会放进RecyclerViewPool中,就会重新bindView,以空间换时间,可以减少bindView的实践。
②复用RecylerViewPool
在TabLayout+ViewPager+RecyclerView的场景中,当多个RecyclerView有相同的item布局结构时,多个RecyclerView共用一个RecycledViewPool可以避免创建ViewHolder的开销,避免GC。
mRecyclerView2.setRecycledViewPool(mPool);
View.inflate和LayoutInflater.inflate区别
github解答
- 实际上没有区别,View.inflate实际上是对LayoutInflater.inflate做了一层包装,在功能上,LayoutInflate功能更加强大。
- View.inflate实际上最终调用的还是LayoutInflater.inflate(@LayoutRes int resource, @nullable ViewGroup root)三个参数的方法,这里如果传入的root如果不为空,那么解析出来的View会被添加到这个ViewGroup当中去。
- 而LayoutInflater.inflate方法则可以指定当前View是否需要添加到ViewGroup中去。
invalidate()和postInvidate()方法的区别:
前者主线程,后者主线程和子线程。postInvalidate()方法内部通过Handler发送了一个消息将线程切回到UI线程通知重新绘制。
【SurfaceView和TextureView】
解析的很清楚
TODO分析源码
Kotlin扩展函数原理
源生扩展函数let/run/apply等
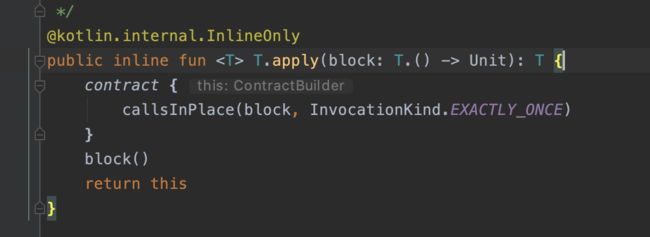

这里我们以let为例:
可以看到let函数的本质就是一个参数为lambda表达式的内联扩展函数。
这个lambda表达式也就是block的参数类型为T,也就是扩展函数的载体,因为参数为载体自身,所以我们可以用it指代使用let函数的对象。
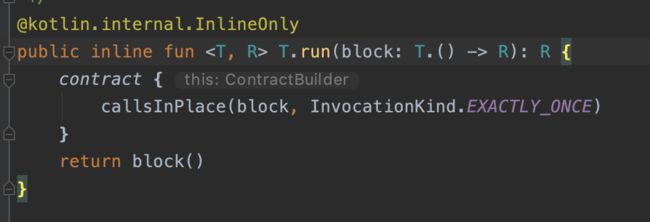
而run函数的参数虽然也是一个lambda式,但是此lambda的参数为T.()->R,也就是对象本身的扩展函数。这样在run闭包中,自然就不需要it来指代自身了。
自定义扩展函数


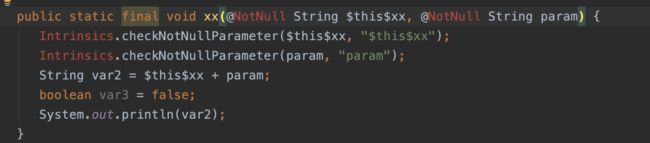
可以看到Kotlin的扩展函数其实并没有修改原有的类,而是在类中生成了一个静态方法,当我们在Kotlin中调用扩展方法时,会把当前的对象作为第一个参数传进这个静态方法。
Surface和Canvas区别
参考
Canvas是Java层构建的数据结构,是给View用的画布。ViewGroup会把自己的Canvas拆分给子View。View会在onDraw方法里将图形数据绘制在它获得的Canvas上。
而Surface是Native层构建的数据结构,是给SurfaceFlinger用的画布。它是直接被用来绘制到屏幕上的数据结构。 开发者一般所用的View都是在Canvas进行绘制,然后最顶层的View(通常是DecorView)的Canvas的数据信息会转换到一个Surface上。SurfaceFlinger会将各个应用窗口的Surface进行合成,然后绘制到屏幕上(实际上是一个Buffer,但一般开发者不用考虑这些,所以省略一些概念)。那为什么会有一个SurfaceView呢?这是因为View的测量(Measure),布局(Layout)以及绘制(Draw)的计算量比较大。计算完以后再从Canvas转换成Surface中数据,然后再绘制屏幕,这个流程比较耗时。对于常规的UI绘制不会有什么问题,但是像Camera的预览以及视频的播放这样的应用场景来说就不可接受了。SurfaceView就是为了解决这个问题。SurfaceView内容不再是绘制在Canvas上,而是直接绘制在其持有的一个Surface上。由于省去了很多步骤,其绘制性能大大提高。而SurfaceView本身只是用来控制这个Surface的大小和位置而已。
Window和WindowManager
解析的很明白的博客
这里做一些简单总结:
WindowManagerService 就是位于 Framework 层的窗口管理服务,它的职责就是管理系统中的所有窗口。窗口的本质是什么呢?其实就是一块显示区域,在 Android 中就是绘制的画布:Surface,当一块 Surface 显示在屏幕上时,就是用户所看到的窗口了。WindowManagerService 添加一个窗口的过程,其实就是 WindowManagerService 为其分配一块 Surface 的过程,一块块的 Surface 在 WindowManagerService 的管理下有序的排列(SurfaceFlinger)在屏幕上,Android 才得以呈现出多姿多彩的界面。

们操作的是 UI 框架层,对 Window 的操作通过 WindowManager 即可完成,而 WindowManagerService 作为系统级服务运行在一个单独的进程,所以 WindowManager 和 WindowManagerService 的交互是一个 IPC 过程。(《进阶之光》有解析)
WindowInsets
WindowInsets是应用于窗口的系统视图(例如状态栏,导航栏)的插页(或大小)。
可以获取导航栏、状态栏、键盘的高度和状态。
参考博客1
参考博客2
View常见的位移方式
setTranslationX/Y
scrollBy/scrollTo
offsetTopAndBottom/offsetLeftAndRight
动画
margin
layoutParams
Fragment的生命周期(不要觉得问题简单就忽略了细节)
github解答
同步屏障
停止同步消息的处理,只处理异步消息,一般异步消息为系统的某些事件。
Android UI刷新里会用到同步屏障,保证刷新的异步消息优先执行。
handler.getLooper().getQueue().postSyncBarrier()加入同步屏障后,Message.obtain()获取一个target为null的msg,并根据当前时间将该msg插入到链表中。
在Looper.loop()循环取消息中 Message msg = queue.next(); target为空时,取链表中的异步消息。
通过setAsynchronous(true)来指定为异步消息
应用场景:ViewRootImpl scheduleTraversals中加入同步屏障 并在view的绘制流程中post异步消息,保证view的绘制消息优先执行
ViewDragHelper(好久没做过手机端了...)
鸿洋博客
SparseArray原理解析
SparseArray简要分析
SparseArray并没有像ArrayMap一样实现Map接口,仅仅实现了Cloneable接口。
默认容量是10.
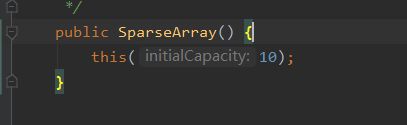
里面有两个重要的数组:int类型的mKeys和Object类型的mValues,分别存储键值。
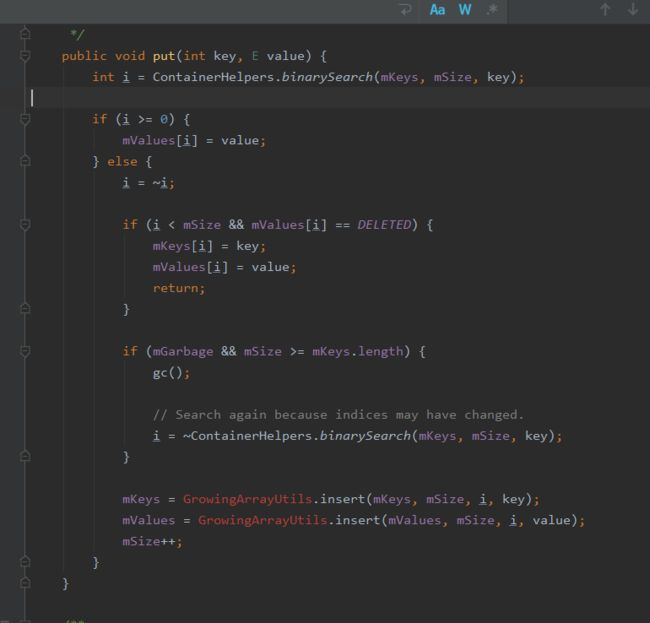
put方法首先使用二分查找在mKeys中查找key,如果找到,则直接更新对应下标的value。如果未找到,binarySearch方法返回待插入的下标的取反(为负数)。故i = ~i之后为原来的下标。如果待插入的位置的元素已经被标记为DELETED,则直接更新并返回。如果需要执行gc函数,且需要扩大数组的容量(mSize >= mKeys.lengt),则先执行gc函数。由于执行gc函数之后元素会发生移动,故重新计算待插入位置,最后执行元素的插入。插入函数分为插入key和插入value。GrowingArrayUtils.insert的。
里面的#gc()
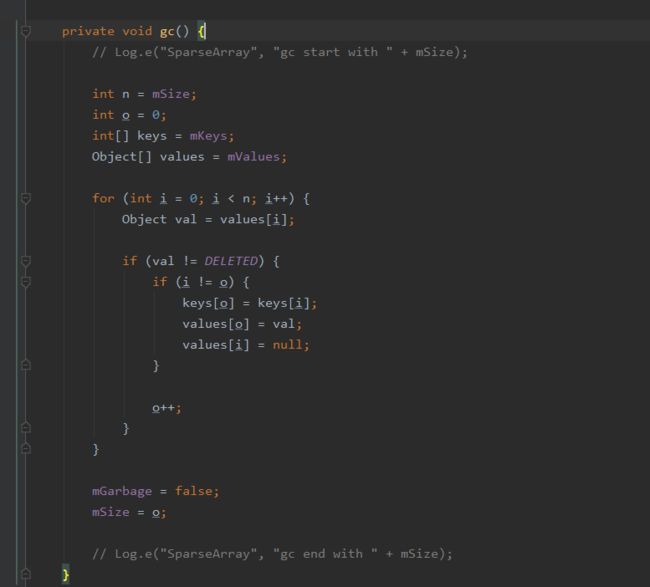
gc函数实际上就是将mValues数组中还未标记为DELETED的元素以及对应下标的mKeys数组中的元素移动到数组的前面,保证数组在0到mSize之间的元素都是未被标记为DELETED,经过gc之后,数据的位置可能会发生移动。
SparseArray主要是为了优化int值到Object映射的存储,提高内存的使用效率。相较于HashMap,在存储上的优化如下:
使用int和Object类型的数组分别存储key和value,相较于HashMap使用Node,SparseArray在存储单个key-value时更节省内存
SparseArray使用int数组存储int类型的key,避免了int到Integer的自动装箱机制
虽然在存储int到Object映射时的内存使用效率更高,由于使用数组存储数组,在添加或者删除元素时需要进行二分查找,元素较多(超过1000)时效率较低,谷歌给出的建议是数据量不要超过1000,这种情况下,相较于HashMap,效率降低不会超过50%。
【Native Crash(需要实践)】
(Android Native Crash)[https://blog.csdn.net/w1070216393/article/details/84830217]
启动流程优化
常规操作暂不多说,主要有个新的方案redex工具优化dex,虽然接入成本很高,但其优化的一些功能点实现很具有参考价值。
redex简介
WebView的优化
github解答
①单/多进程化:webView在独立的进程里面,那么WebView的进程崩溃不会影响到主进程运行;同时WebView的安 全漏洞也很难影响到主进程;如果是多进程的话,可以使用WebView的容器池,有二次秒开的作用;不过缺点就是需要你做好和WebView的跨进程通讯了
②网络优化:我们可以让WebView的host和客户端的host保持一致,和项目api所有域名一致,节省域名解析的解析的时间,那么就达到复用DNS缓存的效果;如果客户端有针对网络请求进行了优化,那么可以让WebView的全部网络请求托管给客户端
③H5离线包:这个是手Q的H5方案之一,让客户端提前去下载离线的H5数据包,WebView只需要加载本地H5数据包即可,这么做不仅可以避免一些http的劫持,而且跳过了WebView的建立TCP连接和H5、CCS等数据下载的过程,直接开始UI渲染,大大提高了WebView的效率
大图加载策略
1、首先确定大图的用途,精度需求:
a)完整显示,对精度要求不高,图片本身就很大
b)对精度需求比较高,不需要完整显示
2、解决方案
a)针对第一种的处理图片本身,按需加载(根据显示设备本身大小进行缩放),降低精度加载(改变图片模式,如将ARGB8888改成RGB565,ARGB4444),修改图片格式(png改成webp,jpg)
b)第二种的一般采用局部加载,主要要用到的是BitmapRegionDecoder这个类decodeRegion的方法,读取图片指定大小的数据,然后通过移动来动态改变显示区域的图片
BitmapRegionDecode详解
BitmapRegionDecode.newInstance(...)获取一个对象,然后通过这个对象去调用decodeRegion(...)得到bitmap,最后就可以显示在屏幕上了。考虑到用户可以触摸移动图像,我们用手势控制器GestureDetector来控制图片显示的区域。
【网络请求优化】
1、尽量避免使用多个不同的域名:域名需要通过DNS服务解析成IP,域名过多会浪费时间(当然了DNS会有缓存)
2、减少不必要数据的数据传输:后台返回数据的时候,如果数据没有用到可以不传递给客户端,避免造成浪费
3、使用GZip压缩数据:可以把传递的数据通过压缩变小
4、使用keep-alive: 网络请求之后,不断开链接,下次再次发起网络请求的时候,不用再次走三次握手
5、根据不同的网络环境,定制不同的策略:比如WiFi环境下,可以下载高清大图、下载热更资源等;移动网络状态下,不要进行太费流量的操作;
【SharedPreference是线程安全的吗?commit和apply区别?】
github解答
1.SharePreferences是线程安全的 其实现类SharedPreferenceImpl里面的方法有大量的synchronized来保障。

2.SharePreferences不是进程安全的 即使你用了MODE_MULTI_PROCESS 。
3.第一次getSharePreference会读取磁盘文件,异步读取,写入到内存中,后续的getSharePreference都是从内存中拿了。
4.第一次读取完毕之前 所有的get/set请求都会被卡住 等待读取完毕后再执行,所以第一次读取会有ANR风险。
5.所有的get都是从内存中读取。
6.提交都是 写入到内存和磁盘中 。apply跟commit的区别在于
apply 是内存同步 然后磁盘异步写入任务放到一个单线程队列中 等待调用。方法无返回 即void
commit 内存同步 只不过要等待磁盘写入结束才返回 直接返回写入成功状态 true or false
7.从 Android N 开始, 不再支持 MODE_WORLD_READABLE & MODE_WORLD_WRITEABLE. 一旦指定, 会抛异常 。也不要用MODE_MULTI_PROCESS 迟早被放弃。
8.**每次commit/apply都会把全部数据一次性写入到磁盘,即没有增量写入的概念 。 **所以单个文件千万不要太大 否则会严重影响性能。
建议用微信的第三方MMKV来替代SharePreference
MMKV框架
基于 mmap 内存映射的 key-value 存储组件
通过 mmap 内存映射文件,提供了一段可供随时写入的内存块,App 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失;
增量更新,避免每次进行相对增量来说大数据量的全量写入。
底层序列化/反序列化使用 protobuf 实现,以最少的数据量能表示最多的信息
Seializable 和Parcelable区别
两者最大的区别在于 存储媒介的不同,Serializable 使用 I/O 读写存储在硬盘上(碎片化严重),而 Parcelable 是直接 在内存中读写。很明显,内存的读写速度通常大于 IO 读写,所以在 Android 中传递数据优先选择 Parcelable。
【Andriod版本相关】
1.Android 7.0新特性
①JIT/AOT编译 (主要是为了提高app的性能,android4.4开发者选项里第一次加入了AOT,目的是为了在安装时进行一次编译,优化应用的使用,从而避免了每次使用都要编译与转义。而android7.0开始,新增了 JIT编译器,目的是为了对AOT代码进行分析,从而不断提高app的性能)
②画中画功能
③应用分屏
④添加对VR的支持
⑤电量功能改进
2.Android 8.0新特性
Android 8.0新特性
①后台位置限制:降低了后台应用接收位置更新的频率
②提醒窗口:可以在其他应用或者系统窗口上方显示窗口(需要SYSTEM_ALERT_WINDOW权限)
③网络连接和HTTPS联系:做了一些改动,比如URI中不能包含空白标签
3.Android 9.0新特性
①利用Wi-Fi RTT进行室内定位
②渠道设置、广播和请勿打扰:可以屏蔽一个渠道组的通知
③多摄像头支持和摄像头更新:可以通过两个或更多物理摄像头来同时访问多个视频流
④引入可绘制对象和位图的ImageLoader: 使用该类取代 [BitmapFactory] 和 [BitmapFactory.Options] API, ImageDecoder 还可以为圆角或圆形遮罩之类的图像添加复杂的定制效果
⑤新增动画:Android 9 引入了 AnimatedImageDrawable 类,用于绘制和显示 GIF 和 WebP 动画图像
4.Android 10.0新特性
10.0新特性
①支持5G网络
②暗黑主体
③ART优化
④智能回复
⑤手势导航
5.Andriod 11.0新特性
11.0新特性
①消息通知页面:可以在锁屏页面回复消息
②控制敏感权限:面向用户的权限对话框将包含 “仅限这一次” 选项。如果用户在对话框中选择此选项,系统会向应用授予单次授权。
③强制应用调用内置相机:Android 11取消了应用调用第三方相机应用的功能,系统会自动选择预装的相机应用,这么做的原因是考虑到隐私和安全。
④优化折叠设备支持
ArrayMap和HashMap的区别
github解答
1.查找效率
HashMap因为其根据hashcode的值直接算出index,所以其查找效率是随着数组长度增大而增加的。
ArrayMap使用的是二分法查找,所以当数组长度每增加一倍时,就需要多进行一次判断,效率下降
2.扩容数量
HashMap初始值16个长度,每次扩容的时候,直接申请双倍的数组空间。
ArrayMap每次扩容的时候,如果size长度大于8时申请size*1.5个长度,大于4小于8时申请8个,小于4时申请4个。这样比较ArrayMap其实是申请了更少的内存空间,但是扩容的频率会更高。因此,如果数据量比较大的时候,还是使用HashMap更合适,因为其扩容的次数要比ArrayMap少很多。
3.扩容效率
HashMap每次扩容的时候重新计算每个数组成员的位置,然后放到新的位置。
ArrayMap则是直接使用System.arraycopy,所以效率上肯定是ArrayMap更占优势。
4.内存消耗
以ArrayMap采用了一种独特的方式,能够重复的利用因为数据扩容而遗留下来的数组空间,方便下一个ArrayMap的使用。而HashMap没有这种设计。 由于ArrayMap之缓存了长度是4和8的时候,所以如果频繁的使用到Map,而且数据量都比较小的时候,ArrayMap无疑是相当的是节省内存的。
5.总结
综上所述,数据量比较小,并且需要频繁的使用Map存储数据的时候,推荐使用ArrayMap。 而数据量比较大的时候,则推荐使用HashMap。
LRUCache
github解答
LruCache 是最近最少使用算法的一种实现,主要用于内存缓存。
LruCache 内部使用 LinkedHashMap 来实现最近最少使用的核心逻辑。通过构造函数初始化最大的cache 大小,其单位要和 sizeOf 大小一致。还会初始化一个有序的 LinkedHashMap,这个 LinkedHashMap 是个有序的双向链表,根据进入顺序进行排序,新进入或最新使用的放在链表尾部,这样表头就是最少使用的。当超过给定的大小时就会移除表头的数据,知道大小小于给定大小为止。
注意:LruCache 是强引用,LruCache 本身并没有释放内存存,它只是把 LinkedHashMap 中的数据移除,如果数据还在其他地方引用,还是无法释放内存,可以手动释放;
SparseArray 相比HashMap优势
int作为键,减少自动装箱操作;
value使用纯粹的数组,结构相比hashmap简单,
二分查找,小数据量下更高效
延时回收,remove只是修改值引用,不删数据,不会时不会频繁压缩数组,在gc()函数后真正删除
说说HttpClient与HttpUrlConnection的区别?并谈谈为何前者会被替代
1,android2.3之前,HttpUrlConnection具有一些bug,例如关闭输入流时可能导致连接池关闭。
2,android2.3之后,HttpUrlConnection才相对成熟。特点是,轻量、api少
3,HttpClient一直很强大,支持get、post、delete等其他协议。
具体可参考表格:
https://www.cnblogs.com/spec-dog/p/3792616.html
被替代原因:
太重了,api太多;针对Android系统,不便于向后维护
Android签名机制
V2
1、更加安全(不可修改),一旦修改则无法安装
2、安装更快(不解压,验证时间缩短)
3、7.0以后的签名方式
建议v1和v2一起使用,7.0以下的手机安装时会使用v1验证,7.0以上的手机使用v2验证
【Android构建流程】
Github解答
①使用aapt处理资源文件,如编译AndroidManifest.xml,编译生成resources.arsc,生成R.java等
②使用javac等工具编译java文件,生成class格式文件
③使用dx等工具将.class和项目依赖的jar编译成.dex
④将生成的这些文件压缩进一个zip中
⑤签名(jarsigner)
这只是最简单的过程,实际还会涉及到multidex,使用如proguard的工具处理生成的字节码,需要依赖aar文件,需要编译kotlin,使用jack,使用jni,使用d8/r8等情况~
D8和R8简述
【Android安装流程】
Android应用安装有以下四种方式:
①系统应用安装――开机时完成,没有安装界面
②网络下载应用安装――通过market应用完成,没有安装界面
③ADB工具安装――没有安装界面。
④第三方应用安装――通过SD卡里的APK文件安装,有安装界面,由packageinstaller.apk应用处理安装及卸载过程的界面。
具体流程可参照:
Apk安装流程
Java与Js互调
①Java调用js:主要通过WebView中loadUrl()方法进行调用。
②js调用java代码:通过addJavascriptInterface方法,给java方法添加@JavascriptInterface 添加js调用注解
ViewModel的出现时为了解决什么问题?(原理在点三有分析)
1.对于activity/fragment的销毁重建,它们内部的数据也会销毁,通常可以用onSaveInstanceState()防法保存,通过onCreate的bundle中重新获取,但是大量的数据不合适,而vm会再页面销毁时自动保存并在页面加载时恢复。
2.对于异步获取数据,大多时候会在页面destroyed时回收资源,随着数据和资源的复杂,会造成页面中的回收操作越来越多,页面处理ui的同时还要处理资源和数据的管理。而引入vm后可以把资源和数据的处理统一放在vm里,页面回收时系统也会回收vm。加上databinding的支持后,会大幅度分担ui层的负担。
RxJava背压原理
在异步的情况下,当上游事件发送的速度大于下游处理事件的速度时,称之为背压,此时会生成一个无限大的缓冲池去缓存事件。在RxJava中,Flowable是支持背压策略的。
总共分为4种策略
1.BackpressureStrategy.ERROR:若上游发送事件速度超出下游处理事件能力,且事件缓存池已满,则抛出异常
//阻塞时队列
2.BackpressureStrategy.BUFFER:若上游发送事件速度超出下游处理能力,则把事件存储起来等待下游处理
3.BackpressureStrategy.DROP:若上游发送事件速度超出下游处理能力,事件缓存池满了后将之后发送的事件丢弃
4.BackpressureStrategy.LATEST:若上有发送时间速度超出下游处理能力,则只存储最新的128个事件
对于MVC和MVP的理解
github解答
MVC 是常用的软件开发架构,但是android中对activity的定位不明确,mvc写法常常会将业务逻辑和视图逻辑都混合在一个activity类中,造成代码逻辑混乱,随着项目增大,维护成本会几何倍增加。
MVP 主要思想就是将业务逻辑从activity中割裂出来,保证职责的明确,依赖关系可以简单的这样表示 M==>P<===>V ,M只负责获取数据,p只从m拿数据而不关心数据获取的流程,p 会有v的引用,从而发送消息给v ,v需要数据时只需要调用p而不需要知道p对数据的操作。
mvp的之间的依赖不是一定的,每个人对一个事物都会有自己的见解,但是万变不离‘职责明确’这四个字
mvc使用: 项目小 开发进度需求快,直接莽,用mvc没关系,技术是为了完成业务的 。
mvp使用:中大型项目,最好配合模块化,将粒度分的更细更清晰,写起来需要多人配合,不然会稍慢
MVP如何处理Presenter层以防止内存泄漏
最简单的方式就是换成MVC,哈哈哈哈哈哈!!
在 Activity 执行 onDestroy() 方法之前,调用 Presenter 自定义一个 onDestroy() 方法,因为 Presenter 持有 Activity View 的应用,所以在 Presenter 的 onDestroy() 方法里面把 View = null,在 Presenter 执行 网络请求或者其他的耗时操作,结果返回都必须执行 if(view != null )操作判断。
多渠道打包
gradle自带的productFlavor方式
一张图片所占的内存空间的大小
图片占用内存大小=图片宽度图片高度图片位深
图片位深: ARGB_8888 32位、ARGB_4444 16位、ARGB_565 16位
例如: 10801920 ,位深为ARGB_8888的图片的内存占用=1080192032位/8=10801920*4字节= 7.9M
【64k问题】
如果您的 minSdkVersion 设为 21 或更高版本,系统会默认启用 MultiDex,并且您不需要 MultiDex 库。
突破65535 限制 实现三步走
1.导入依赖
‘com.android.support:multidex:2.0.0’
2.defaultConfig 增加设置
multiDexEnabled true
3.自定义Application 继承 MultiDexApplication
或者修改清单文件中application的name:
...
如何优化Gradle构建速度
github解答
好的硬件是第一位
其次在gradle.properties中配置:
android.enableBuildCache=true
org.gradle.jvmargs=-Xmx2048m -XX:MaxPermSize=512m -XX:+HeapDumpOnOutOfMemoryError -Dfile.encoding=UTF-8
等
如何获取Android唯一设备ID
①序列号
android.os.Build.SERIAL 获得序列号
26以后被弃用 ,getSerial ()替代,需要动态申请READ_PHONE_STATE权限
②android id(目前最靠谱的)
设备首次启动产生的,不需要获取权限
8.0中,只要程序包名称和签名密钥相同,ANDROID_ID值就不会在程序包卸载/重新安装时更改
获取方法:
String androidId = Settings.Secure.getString(context.getContentResolver(), Settings.Secure.ANDROID_ID);
缺点:
设备恢复出厂设置会被重置
部分手机返回为空或固定值9774d56d682e549c
考虑到动态申请权限成本较高,可接受恢复出厂重置androidId
什么是AOP,在Android中有哪些应用
AOP,面向切面编程,Android里面大多是使用动态代理技术来实现
在日志统计,登录信息check,网络是否连接等场景有应用,主要是用来避免每次做check时都写重复的逻辑代码。
MVVM
个人理解(欢迎指正 感谢!)
MVVM = Model View ViewModel
主要分离View 和Model的 让View层不做逻辑 model层不做界面刷新
View:只负责接收新的数据 和刷新界面 通知ViewModel去计算/获取数据
ViewModel : 负责接收View的获取数据请求 计算获取新的数据
Model:模型类
配合databinding 更配噢!
数据埋点
手动在需要的地方添加埋点代码
asm+android gradle api编译期注入
【断点下载】
OKHttp断点下载
之前有实现过HttpURLConnection版本的,后面会贴上来。
OKHttp断点上传
webp和svg图片
github解答
svg格式
svg是矢量图,这意味着svg图片由直线和曲线以及绘制它们的方法组成。当你放大一个svg图片的时候,你看到的还是线和曲线,而不会出现像素点。svg图片在放大时,不会失真,所以它非常适合用来绘制企业Logo、Icon
SVG格式特点:
1、SVG 指可伸缩矢量图形 (Scalable Vector Graphics)
2、SVG 用来定义用于网络的基于矢量的图形
3、SVG 使用 XML 格式定义图形
4、SVG 图像在放大或改变尺寸的情况下其图形质量不会有所损失
5、SVG 是万维网联盟的标准
6、SVG 与诸如 DOM和 XSL 之类的W3C标准是一个整体
webp格式
webp是谷歌开发的一种新图片格式,是同时支持有损和无损压缩的、使用直接色的、点阵图。
如何绕过Android9.0针对反射的限制?
双重反射,即利用反射调用反射API,这个时候系统进行栈回溯,发现直接调用者是反射API,反射API也是系统API,就直接通过了
为什么要将项目迁移到AndroidX?
现在Android官方支持的最低系统版本已经是4.0.1,对应的API版本号是15。support-v4、appcompat-v7库也不再支持那么久远的系统了,但是它们的名字却一直保留了下来,虽然它们现在的实际作用已经对不上当初命名的原因了。
那么很明显,Android团队也意识到这种命名已经非常不合适了,于是对这些API的架构进行了一次重新的划分,推出了AndroidX。因此,AndroidX本质上其实就是对Android Support Library进行的一次升级,升级内容主要在于以下两个方面。
第一,包名。之前Android Support Library中的API,它们的包名都是在android.support.下面的,而AndroidX库中所有API的包名都变成了在androidx.下面。这是一个很大的变化,意味着以后凡是android.包下面的API都是随着Android操作系统发布的,而androidx.包下面的API都是随着扩展库发布的,这些API基本不会依赖于操作系统的具体版本。
第二,命名规则。吸取了之前命名规则的弊端,AndroidX所有库的命名规则里都不会再包含具体操作系统API的版本号了。比如,像appcompat-v7库,在AndroidX中就变成了appcompat库。
Kotlin相关
@JvmOverloads作用
在Kotlin中@JvmOverloads注解的作用就是:在有默认参数值的方法中使用@JvmOverloads注解,则Kotlin就会暴露多个重载方法。
List和MutableList的区别
MutableList:可读写,实际上就是个ArrayList
List:可读 如同Java List一样只是个接口
List 返回的是EmptyList,MutableList 返回的是一个 ArrayList,查看EmptyList的源码就知道了,根本就没有提供 add 方法。
什么是委托属性,使用场景及原理
属性委托
有些常见的属性操作,我们可以通过委托方式,让它实现,例如:
lazy 延迟属性: 值只在第一次访问的时候计算
observable 可观察属性:属性发生改变时通知
map 集合: 将属性存在一个map集合里面
类委托
可以通过类委托来减少 extend
类委托的时,编译器回优使用自身重新函数,而不是委托对象的函数
interface Base{
fun print()
}
case BaseImpl(var x: Int):Base{
override fun print(){
print(x)
}
}
// Derived 的 print 实现会通过构造函数的b对象来完成
class Derived(b: base): Base by b
kotlin的Unit和Java Void区别
Unit : Kotlin 中Any的子类, 方法的返回类型为Unit时,可以省略;
Void:Java中的方法无法回类型时使用,但是不能省略;
Nothing:任何类型的子类,编译器对其有优化,有一定的推导能力,另外其常常和抛出异常一起使用;
Kotlin中infix关键字的原理和使用场景
infix可以自定义操作符,比如1 to 2 这种的, 1 add 2,让程序更加语义化
是扩展方法的一种特殊情况,如下是 to 的定义:
public infix fun
Kotlin中的可见性修饰符有哪些?相比于Java有什么区别?
kotlin存在四种可见性修饰符,默认是public。 private、protected、internal、public
1.private、protected、public是和java中的一样的。
2.不同的是java中默认是default修饰符(包可见),而kotlin存在internal修饰符(模块内部可见)。
3.kotlin可以直接在文件顶级声明方法、变量等。其中protected不能用来修饰在文件顶级声明的类、方法、变量等。
构造方法默认是public修饰,可以使用可见性修饰符修饰constructor关键字来改变构造方法的可见性。
【kotlin解构】
给一个包含N个组件函数(component)的对象分解为替换等于N个变量的功能,而实现这样功能只需要一个表达式就可以了。
例如
有时把一个对象 解构 成很多变量会很方便,例如:
val (name, age) = person
这种语法称为 解构声明 。一个解构声明同时创建多个变量。 我们已经声明了两个新变量: name 和 age,并且可以独立使用它们:
println(name)
println(age)
一个解构声明会被编译成以下代码:
val name = person.component1()
val age = person.component2()
【内联函数】
kotlin 中的Any与Java中的Object有何异同?
都是顶级父类
异:
成员方法不同
Any只声明了toString()、hashCode()和equals()作为成员方法。
kotlin中的数据类型有隐式转换吗,为什么?
kotlin中没有所谓的'基本类型',本质上不存在拆装箱过程,所有的基本类型都可以想象成Java中的包装类型,所以也不存在隐式转换,对应的都是强类型,一旦声明之后,所有转换都是显示转换。
【EventBus粘性事件】
参考文章
【HashMap原理】
参考文章