背景
在我们推送80篇左右的时候,此时,我们想对历史推送的文章做一个聚类分析,指导团队接下来该往哪些方面去攻。
关键字 KMeans聚类算法
数据预处理
提取三行科创后台数据.excel的阅读量和点赞量保存到sanhang.txt文档中,并做初步的数据预处理,调整到我们方便处理的数据格式。
#-*- coding:utf-8 -*-
#读入excel源数据的标签和指标
import xlrd #导入xlrd模块
from numpy import *
import numpy as np
fname="三行科创后台数据.xlsx" #把源excel数据文件赋值给fname
bk=xlrd.open_workbook(fname)#打开excel文件读取数据
shxtrange=range(bk.nsheets) #计算文件中sheet数量
sh=bk.sheet_by_name("Sheet1") #通过名称获取Sheet1
col1=sh.col_values(1) #读取序号列
col2=sh.col_values(5) #读取阅读量列
col3=sh.col_values(16) #读取点赞数列
X=[col2,col3] #把阅读量和点赞数组合
m=np.array(X).T #转置X变成两列
m=m[2:len(col1)] #去掉表头
file=open('sanhangdata.txt','w') #打开待写入的txt文件
file.write(str(m)) #写进阅读量和点赞数
file.close()
with open('sanhangdata.txt','r') as fpr: #重新打开txt文件,整成需要的形式
content=fpr.read()
content=content.replace('[','')
content=content.replace(']','')
content=content.replace("'",'')
#print(content)
with open('sanhangdata.txt','w') as fpw:
fpw.write(content)
建模
读取sanhang.txt数据,利用K-Means算法进行聚类(n_clusters=4),打印聚类结果,并用二维图显示聚类结果
#利用KMeans算法搭建聚类模型
from sklearn.cluster import KMeans
import pandas as pd
#数据初始化
datas=np.loadtxt("sanhangdata.txt") #把数据读取出来,存为numpy数组
data=pd.DataFrame(datas) #数据框化,为后面的columns法则
dataSet=1.0*(data-data.mean())/data.std() #对数据采用0-均值标准化
k=4 #预计聚类类别
iteration=500 #聚类最大循环次数
outputfile='data_type.xls' #保存结果文件
#开始聚类
model=KMeans(n_clusters=k,random_state=0,max_iter=iteration) #建立聚类模型
model.fit(dataSet) #训练模型
#简单打印结果
labels_=model.labels_ #类别标签结果
centers_=model.cluster_centers_ #聚类中心值
#inertia_=model.inertia_ #聚类中心均值
r1=pd.Series(labels_).value_counts() #统计各个类别的数目
r2=pd.DataFrame(centers_) #找出聚类中心
r=pd.concat([r2,r1],axis=1)#横向连接,得到聚类中心对应的类别下的数目
r.columns=list(data.columns) + [u'类别数目'] #重命名表头
print(r)
#输出原始数据及其类别
r=pd.concat([data,pd.Series(model.labels_,index=data.index)],axis=1)#详细输出每个样本对应的类别
r.columns=list(data.columns)+[u'聚类类别'] #重命名表头
r.to_excel(outputfile) #保存结果
#绘制聚类图
import matplotlib.pyplot as plt
plt.figure() #设置画布
for i in range(len(datas)):
if labels_[i]==0:
plt.text(datas[i][0],datas[i][1],str(i),fontsize=7)
plt.scatter(datas[i][0],datas[i][1],marker='.',color='red')
if labels_[i]==1:
plt.text(datas[i][0],datas[i][1],str(i),fontsize=7)
plt.scatter(datas[i][0],datas[i][1],marker='.',color='green')
if labels_[i]==2:
plt.text(datas[i][0],datas[i][1],str(i),fontsize=9)
plt.scatter(datas[i][0],datas[i][1],marker='.',color='blue')
if labels_[i]==3:
plt.text(datas[i][0],datas[i][1],str(i),fontsize=7)
plt.scatter(datas[i][0],datas[i][1],marker='.',color='yellow')
if labels_[i]==4:
plt.text(datas[i][0],datas[i][1],str(i),fontsize=7)
plt.scatter(datas[i][0],datas[i][1],marker='.',color='black')
plt.show()
建模结果
0 1 类别数目
0 1.673184 0.850424 15
1 -1.101573 -1.173252 20
2 -0.162235 -0.308797 28
3 0.082015 1.075277 18
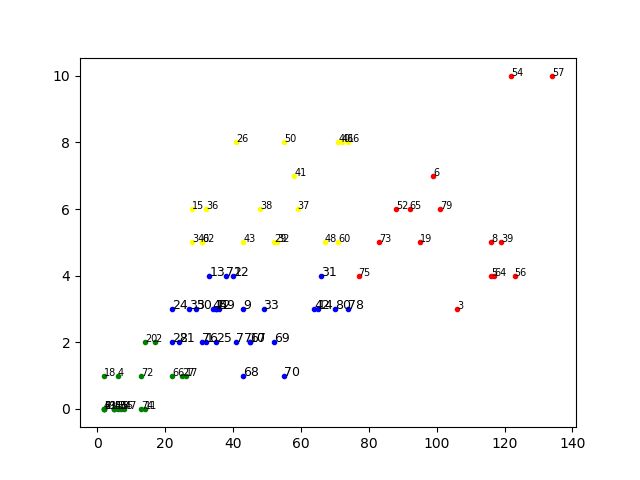
我们仔细阅读对比了聚类图,发现聚类效果还算不错的,但是并不非常满意,比如图1中还是有一些横纵坐标相似度高但是分在不同类的,于是,我们试着能不能修改聚类数目,取k=5,聚类散点图
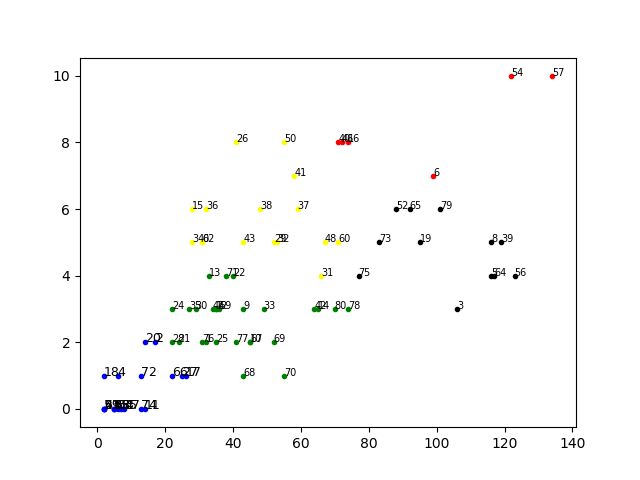
结果分析
对比图1,图2有明显进步,各类界限明显多了,组内更加聚集,组间更加离散,但是还不够满意,比如最明显的是有红色的样本点处于两个极端,我们想用阅读量这种绝对值不太合理,因为不同时期,我们送达总人数是不同的,下次应该用阅读率以及点赞率两组相对指标。以及采用分群的密度函数图来刻画。