NoSql入门和概述
入门概述
1. 互联网时代背景下大机遇,为什么用nosql
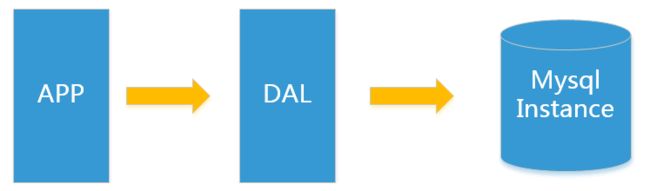
1.1 单机MySQL的美好年代
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。在那个时候,更多的都是静态网页,动态交互类型的网站不多。
上述架构下,我们来看看数据存储的瓶颈是什么?
- 数据量的总大小 一个机器放不下时
- 数据的索引(B+ Tree)一个机器的内存放不下时
- 访问量(读写混合)一个实例不能承受
1.2 Memcached(缓存)+MySQL+垂直拆分
后来,随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带了了比较高的IO压力。在这个时候,Memcached就自然的成为一个非常时尚的技术产品。
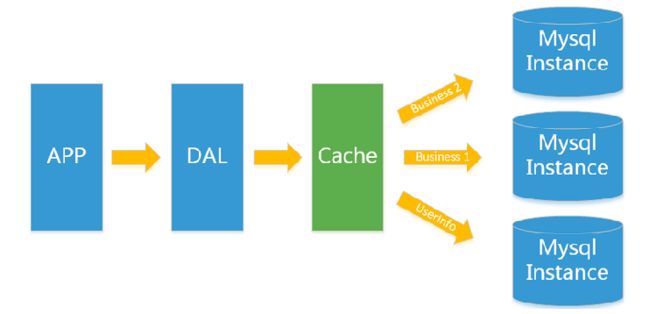
Memcached作为一个独立的分布式的缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务,在Memcached服务器上,又发展了根据hash算法来进行多台Memcached缓存服务的扩展,然后又出现了一致性hash来解决增加或减少缓存服务器导致重新hash带来的大量缓存失效的弊端
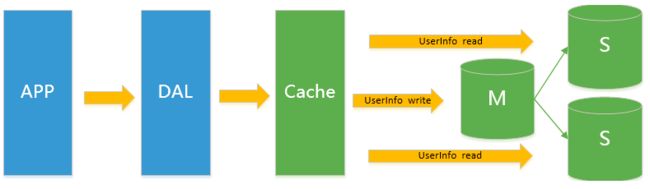
1.3 Mysql主从读写分离
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为这个时候的网站标配了。
1.4 分表分库+水平拆分+mysql集群
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。
同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术,是面试的热门问题也是业界讨论的热门技术问题。也就在这个时候,MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。
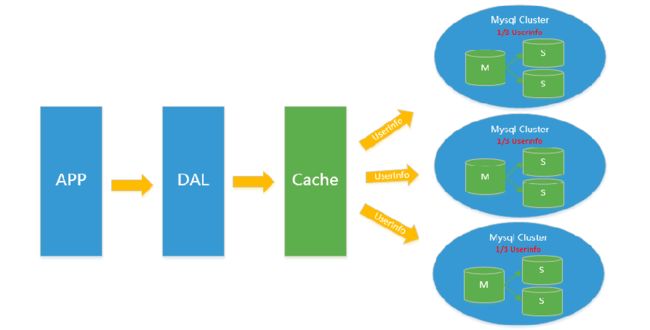
1.5 MySQL的扩展性瓶颈
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySQL的开发人员面临的问题。
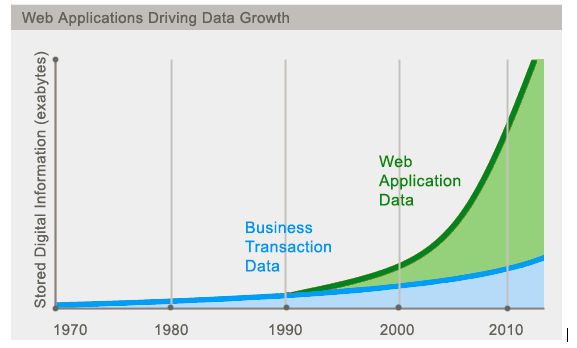
1.6 今天是什么样子??

1.7 为什么用NoSQL
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据
2. 是什么
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,
泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
3 能干嘛
3.1 易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。
数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
3.2 大数据量高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。
这得益于它的无关系性,数据库的结构简单。
一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,
在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,
是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了
3.3 多样灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,
增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦
3.4 传统RDBMS VS NOSQL
RDBMS vs NoSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
3V+3高
1. 大数据时代的3V
- 海量Volume
- 多样Variety
- 实时Velocity
2. 互联网需求的3高
- 高并发
- 高可扩
- 高性能
NoSql的分类
1. 键值(Key-Value)存储数据库
- 相关产品: TokyoCabinet/Tyrant、Redis、Voldemort、Berkeley DB
- 典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
- 数据模型: 一系列键值对
- 优势: 快速查询
- 劣势: 存储的数据缺少结构化
2. 列存储数据库
- 相关产品:Cassandra, HBase,Riak
- 典型应用:分布式的文件系统
- 数据模型:以列簇式存储,将同一列数据存在一起
- 优势:查找速度快,可扩展性强,更容易进行分布式扩展
- 劣势:功能相对局限
3. 文档型数据库
- 相关产品:CouchDB、MongoDB
- 典型应用:Web应用(与Key-Value类似,Value是结构化的)
- 数据模型: 一系列键值对
- 优势:数据结构要求不严格
- 劣势:查询性能不高,而且缺乏统一的查询语法
4. 图形(Graph)数据库
- 相关数据库:Neo4J、InfoGrid、Infinite Graph
- 典型应用:社交网络
- 数据模型:图结构
- 优势:利用图结构相关算法。
- 劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。
当下的NoSQL经典应用
1. 当下的应用是sql和nosql一起使用
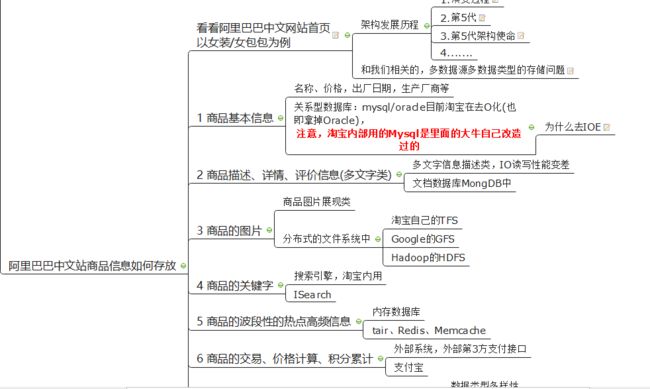
2. 阿里巴巴中文站商品信息如何存放