备注:
Hive 版本 2.1.1
如果使用Hive作为大数据仓库,强烈建议主要使用ORC文件格式作为表的存储格式
一.ORC文件格式概述
ORC (Optimized Row Columnar)文件格式为Hive数据提供了一种高效的存储方式。它的设计是为了克服其他Hive文件格式的限制。使用ORC文件可以提高Hive读写和处理数据时的性能。
例如,与RCFile格式相比,ORC文件格式有很多优点,如:
- 单个文件作为每个任务的输出,这减少了NameNode的负载
- Hive类型支持包括datetime、decimal和复杂类型(struct、list、map和union)
- 存储在文件中的轻量级索引:
1) 跳过没有通过谓词筛选的行组
2) 查找给定的行 - 基于数据类型的块模式压缩
1)整数列的运行长度编码
2)字符串列的字典编码 - 使用单独的记录器并发读取同一文件
- 能够分裂文件,而不扫描标记
- 限制读写所需的内存量
- 使用协议缓冲区存储的元数据,允许添加和删除字段
文件结构
ORC文件包含一组称为条带的行数据,以及文件页脚中的辅助信息。在文件的末尾,postscript保存压缩参数和压缩页脚的大小。
默认的条带大小为250mb。大条带大小可以使读取HDFS的数据量更大、更高效。
文件页脚包含文件中的条带列表、每个条带的行数和每个列的数据类型。它还包含列级聚合count、min、max和sum。
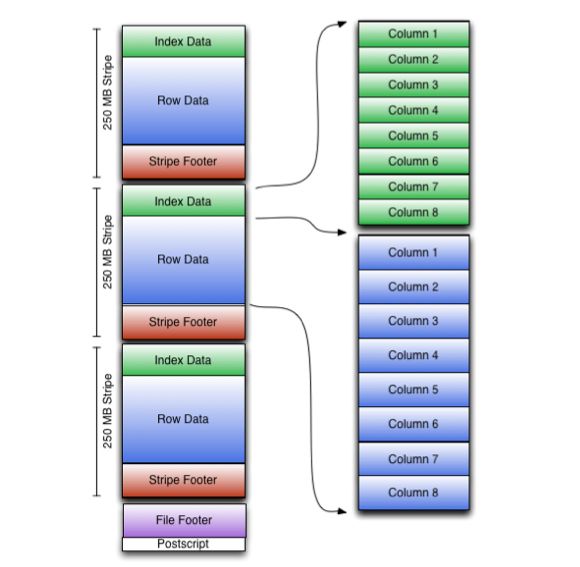
条纹结构
如图所示,ORC文件中的每个条带保存索引数据、行数据和条带页脚。
条带页脚包含一个流位置目录。行数据在表扫描中使用。
索引数据包括每个列的最小值和最大值以及每个列中的行位置。(也可以包含位域或bloom filter。)行索引项提供了能够在解压缩块中查找右侧压缩块和字节的偏移量。注意,ORC索引仅用于选择条带和行组,而不是用于回答查询。
拥有相对频繁的行索引项可以支持在条带内跳过行以快速读取,尽管条带大小很大。默认情况下,可以跳过每10,000行。
有了基于筛选器谓词跳过大量行集的能力,您可以根据表的辅助键对表进行排序,从而大大减少执行时间。例如,如果主分区是事务日期,则可以按状态、邮政编码和姓氏对表进行排序。然后,查找一个州的记录将跳过所有其他州的记录。
ORC规范中给出了该格式的完整规范。
ORC的压缩比

二.测试ORC性能
我本地有一张ods_fact_sale,text文件给事,数据量7亿+,数据拷贝一份到 ods_fact_sale_orc这个文件格式的表。
2.1 查看两个表存储空间的大小
代码:
hadoop fs -ls /user/hive/warehouse/test.db/ods_fact_sale |awk -F ' ' '{print $5}'|awk '{a+=$1}END{print a}'
hadoop fs -ls /user/hive/warehouse/test.db/ods_fact_sale_orc |awk -F ' ' '{print $5}'|awk '{a+=$1}END{print a}'
测试记录:
[root@hp1 ~]# hadoop fs -ls /user/hive/warehouse/test.db/ods_fact_sale |awk -F ' ' '{print $5}'|awk '{a+=$1}END{print a}'
31421093662
[root@hp1 ~]# hadoop fs -ls /user/hive/warehouse/test.db/ods_fact_sale_orc |awk -F ' ' '{print $5}'|awk '{a+=$1}END{print a}'
2151733397
[root@hp1 ~]#
从测试记录可以看到,30G左右的text文件格式表,数据压缩到20G左右,减少了接近三分之一的存储空间。
2.2 测试查询性能
代码:
select count(*) from ods_fact_sale;
select count(*) from ods_fact_sale_orc;
测试记录:
hive>
>
> select count(*) from ods_fact_sale;
Query ID = root_20210106135435_67cdd9d3-9cc2-4e5a-8b03-9e3442c9ffa0
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
21/01/06 13:54:35 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm69
Starting Job = job_1609141291605_0034, Tracking URL = http://hp3:8088/proxy/application_1609141291605_0034/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1609141291605_0034
Hadoop job information for Stage-1: number of mappers: 117; number of reducers: 1
2021-01-06 13:54:42,786 Stage-1 map = 0%, reduce = 0%
2021-01-06 13:54:51,124 Stage-1 map = 2%, reduce = 0%, Cumulative CPU 12.45 sec
2021-01-06 13:54:58,309 Stage-1 map = 3%, reduce = 0%, Cumulative CPU 24.67 sec
2021-01-06 13:55:04,470 Stage-1 map = 5%, reduce = 0%, Cumulative CPU 36.73 sec
2021-01-06 13:55:10,634 Stage-1 map = 6%, reduce = 0%, Cumulative CPU 42.69 sec
2021-01-06 13:55:11,658 Stage-1 map = 7%, reduce = 0%, Cumulative CPU 48.67 sec
2021-01-06 13:55:16,784 Stage-1 map = 8%, reduce = 0%, Cumulative CPU 54.63 sec
2021-01-06 13:55:17,804 Stage-1 map = 9%, reduce = 0%, Cumulative CPU 60.63 sec
2021-01-06 13:55:24,987 Stage-1 map = 10%, reduce = 0%, Cumulative CPU 72.63 sec
2021-01-06 13:55:29,090 Stage-1 map = 11%, reduce = 0%, Cumulative CPU 78.63 sec
2021-01-06 13:55:32,164 Stage-1 map = 12%, reduce = 0%, Cumulative CPU 84.63 sec
2021-01-06 13:55:35,236 Stage-1 map = 13%, reduce = 0%, Cumulative CPU 90.51 sec
2021-01-06 13:55:38,306 Stage-1 map = 14%, reduce = 0%, Cumulative CPU 96.45 sec
2021-01-06 13:55:40,349 Stage-1 map = 15%, reduce = 0%, Cumulative CPU 102.4 sec
2021-01-06 13:55:46,482 Stage-1 map = 16%, reduce = 0%, Cumulative CPU 114.2 sec
2021-01-06 13:55:49,550 Stage-1 map = 17%, reduce = 0%, Cumulative CPU 119.98 sec
2021-01-06 13:55:52,620 Stage-1 map = 18%, reduce = 0%, Cumulative CPU 125.88 sec
2021-01-06 13:55:55,690 Stage-1 map = 19%, reduce = 0%, Cumulative CPU 131.74 sec
2021-01-06 13:55:58,768 Stage-1 map = 20%, reduce = 0%, Cumulative CPU 137.63 sec
2021-01-06 13:56:01,829 Stage-1 map = 21%, reduce = 0%, Cumulative CPU 143.65 sec
2021-01-06 13:56:08,998 Stage-1 map = 22%, reduce = 0%, Cumulative CPU 154.84 sec
2021-01-06 13:56:11,041 Stage-1 map = 23%, reduce = 0%, Cumulative CPU 160.85 sec
2021-01-06 13:56:15,127 Stage-1 map = 24%, reduce = 0%, Cumulative CPU 166.9 sec
2021-01-06 13:56:17,175 Stage-1 map = 25%, reduce = 0%, Cumulative CPU 172.86 sec
2021-01-06 13:56:21,286 Stage-1 map = 26%, reduce = 0%, Cumulative CPU 178.89 sec
2021-01-06 13:56:28,439 Stage-1 map = 27%, reduce = 0%, Cumulative CPU 190.93 sec
2021-01-06 13:56:29,465 Stage-1 map = 28%, reduce = 0%, Cumulative CPU 196.77 sec
2021-01-06 13:56:34,595 Stage-1 map = 29%, reduce = 0%, Cumulative CPU 202.67 sec
2021-01-06 13:56:35,620 Stage-1 map = 30%, reduce = 0%, Cumulative CPU 208.57 sec
2021-01-06 13:56:40,738 Stage-1 map = 31%, reduce = 0%, Cumulative CPU 214.47 sec
2021-01-06 13:56:41,754 Stage-1 map = 32%, reduce = 0%, Cumulative CPU 219.68 sec
2021-01-06 13:56:47,882 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 231.03 sec
2021-01-06 13:56:53,000 Stage-1 map = 34%, reduce = 0%, Cumulative CPU 236.99 sec
2021-01-06 13:56:54,022 Stage-1 map = 35%, reduce = 0%, Cumulative CPU 242.86 sec
2021-01-06 13:57:00,150 Stage-1 map = 37%, reduce = 0%, Cumulative CPU 254.82 sec
2021-01-06 13:57:06,298 Stage-1 map = 38%, reduce = 0%, Cumulative CPU 260.76 sec
2021-01-06 13:57:12,422 Stage-1 map = 39%, reduce = 0%, Cumulative CPU 271.95 sec
2021-01-06 13:57:13,447 Stage-1 map = 40%, reduce = 0%, Cumulative CPU 277.76 sec
2021-01-06 13:57:18,553 Stage-1 map = 42%, reduce = 0%, Cumulative CPU 289.28 sec
2021-01-06 13:57:24,685 Stage-1 map = 44%, reduce = 0%, Cumulative CPU 301.22 sec
2021-01-06 13:57:31,854 Stage-1 map = 45%, reduce = 0%, Cumulative CPU 313.16 sec
2021-01-06 13:57:36,964 Stage-1 map = 46%, reduce = 0%, Cumulative CPU 319.18 sec
2021-01-06 13:57:37,988 Stage-1 map = 47%, reduce = 0%, Cumulative CPU 325.05 sec
2021-01-06 13:57:43,101 Stage-1 map = 48%, reduce = 0%, Cumulative CPU 330.89 sec
2021-01-06 13:57:44,125 Stage-1 map = 49%, reduce = 0%, Cumulative CPU 335.99 sec
2021-01-06 13:57:49,238 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 347.26 sec
2021-01-06 13:57:55,362 Stage-1 map = 51%, reduce = 0%, Cumulative CPU 353.99 sec
2021-01-06 13:57:56,384 Stage-1 map = 52%, reduce = 0%, Cumulative CPU 360.45 sec
2021-01-06 13:58:02,515 Stage-1 map = 53%, reduce = 0%, Cumulative CPU 366.76 sec
2021-01-06 13:58:03,537 Stage-1 map = 54%, reduce = 0%, Cumulative CPU 372.75 sec
2021-01-06 13:58:08,645 Stage-1 map = 55%, reduce = 0%, Cumulative CPU 378.81 sec
2021-01-06 13:58:09,665 Stage-1 map = 56%, reduce = 0%, Cumulative CPU 385.07 sec
2021-01-06 13:58:15,806 Stage-1 map = 57%, reduce = 0%, Cumulative CPU 395.39 sec
2021-01-06 13:58:20,923 Stage-1 map = 58%, reduce = 0%, Cumulative CPU 401.39 sec
2021-01-06 13:58:21,948 Stage-1 map = 59%, reduce = 0%, Cumulative CPU 407.49 sec
2021-01-06 13:58:27,060 Stage-1 map = 60%, reduce = 0%, Cumulative CPU 413.46 sec
2021-01-06 13:58:29,107 Stage-1 map = 61%, reduce = 0%, Cumulative CPU 419.43 sec
2021-01-06 13:58:33,198 Stage-1 map = 62%, reduce = 0%, Cumulative CPU 425.31 sec
2021-01-06 13:58:39,343 Stage-1 map = 63%, reduce = 0%, Cumulative CPU 437.34 sec
2021-01-06 13:58:42,415 Stage-1 map = 64%, reduce = 0%, Cumulative CPU 443.25 sec
2021-01-06 13:58:45,483 Stage-1 map = 65%, reduce = 0%, Cumulative CPU 448.35 sec
2021-01-06 13:58:48,538 Stage-1 map = 66%, reduce = 0%, Cumulative CPU 454.25 sec
2021-01-06 13:58:51,600 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 460.2 sec
2021-01-06 13:58:54,663 Stage-1 map = 68%, reduce = 0%, Cumulative CPU 466.39 sec
2021-01-06 13:59:00,787 Stage-1 map = 69%, reduce = 0%, Cumulative CPU 478.17 sec
2021-01-06 13:59:02,836 Stage-1 map = 70%, reduce = 0%, Cumulative CPU 484.06 sec
2021-01-06 13:59:05,909 Stage-1 map = 71%, reduce = 0%, Cumulative CPU 489.99 sec
2021-01-06 13:59:08,979 Stage-1 map = 72%, reduce = 0%, Cumulative CPU 495.93 sec
2021-01-06 13:59:13,081 Stage-1 map = 73%, reduce = 0%, Cumulative CPU 501.96 sec
2021-01-06 13:59:15,127 Stage-1 map = 74%, reduce = 0%, Cumulative CPU 507.89 sec
2021-01-06 13:59:22,287 Stage-1 map = 75%, reduce = 0%, Cumulative CPU 518.91 sec
2021-01-06 13:59:26,366 Stage-1 map = 76%, reduce = 0%, Cumulative CPU 524.95 sec
2021-01-06 13:59:28,413 Stage-1 map = 77%, reduce = 0%, Cumulative CPU 530.73 sec
2021-01-06 13:59:33,517 Stage-1 map = 78%, reduce = 0%, Cumulative CPU 536.64 sec
2021-01-06 13:59:34,542 Stage-1 map = 79%, reduce = 0%, Cumulative CPU 542.5 sec
2021-01-06 13:59:40,676 Stage-1 map = 80%, reduce = 0%, Cumulative CPU 553.52 sec
2021-01-06 13:59:45,794 Stage-1 map = 81%, reduce = 0%, Cumulative CPU 559.6 sec
2021-01-06 13:59:46,819 Stage-1 map = 82%, reduce = 0%, Cumulative CPU 565.48 sec
2021-01-06 13:59:52,953 Stage-1 map = 83%, reduce = 0%, Cumulative CPU 571.44 sec
2021-01-06 13:59:59,093 Stage-1 map = 84%, reduce = 0%, Cumulative CPU 577.28 sec
2021-01-06 14:00:01,141 Stage-1 map = 84%, reduce = 28%, Cumulative CPU 578.09 sec
2021-01-06 14:00:05,234 Stage-1 map = 85%, reduce = 28%, Cumulative CPU 583.91 sec
2021-01-06 14:00:17,515 Stage-1 map = 86%, reduce = 28%, Cumulative CPU 595.9 sec
2021-01-06 14:00:18,547 Stage-1 map = 86%, reduce = 29%, Cumulative CPU 595.98 sec
2021-01-06 14:00:23,669 Stage-1 map = 87%, reduce = 29%, Cumulative CPU 602.01 sec
2021-01-06 14:00:30,845 Stage-1 map = 88%, reduce = 29%, Cumulative CPU 608.23 sec
2021-01-06 14:00:35,962 Stage-1 map = 89%, reduce = 29%, Cumulative CPU 614.1 sec
2021-01-06 14:00:36,979 Stage-1 map = 89%, reduce = 30%, Cumulative CPU 614.16 sec
2021-01-06 14:00:42,094 Stage-1 map = 90%, reduce = 30%, Cumulative CPU 620.04 sec
2021-01-06 14:00:48,220 Stage-1 map = 91%, reduce = 30%, Cumulative CPU 626.09 sec
2021-01-06 14:01:00,468 Stage-1 map = 92%, reduce = 30%, Cumulative CPU 638.02 sec
2021-01-06 14:01:01,492 Stage-1 map = 92%, reduce = 31%, Cumulative CPU 638.15 sec
2021-01-06 14:01:06,609 Stage-1 map = 93%, reduce = 31%, Cumulative CPU 644.05 sec
2021-01-06 14:01:12,752 Stage-1 map = 94%, reduce = 31%, Cumulative CPU 650.05 sec
2021-01-06 14:01:18,892 Stage-1 map = 95%, reduce = 32%, Cumulative CPU 656.12 sec
2021-01-06 14:01:25,031 Stage-1 map = 96%, reduce = 32%, Cumulative CPU 662.01 sec
2021-01-06 14:01:30,145 Stage-1 map = 97%, reduce = 32%, Cumulative CPU 667.94 sec
2021-01-06 14:01:43,452 Stage-1 map = 98%, reduce = 32%, Cumulative CPU 679.79 sec
2021-01-06 14:01:49,620 Stage-1 map = 99%, reduce = 33%, Cumulative CPU 685.73 sec
2021-01-06 14:01:55,757 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 691.67 sec
2021-01-06 14:01:56,781 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 693.64 sec
MapReduce Total cumulative CPU time: 11 minutes 33 seconds 640 msec
Ended Job = job_1609141291605_0034
MapReduce Jobs Launched:
Stage-Stage-1: Map: 117 Reduce: 1 Cumulative CPU: 693.64 sec HDFS Read: 31436910990 HDFS Write: 109 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 11 minutes 33 seconds 640 msec
OK
767830000
Time taken: 443.177 seconds, Fetched: 1 row(s)
hive>
> select count(*) from ods_fact_sale_orc;
Query ID = root_20210106140512_c7d2993a-f42b-4f3d-b582-71b4c53de3aa
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
21/01/06 14:05:12 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm69
Starting Job = job_1609141291605_0035, Tracking URL = http://hp3:8088/proxy/application_1609141291605_0035/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1609141291605_0035
Hadoop job information for Stage-1: number of mappers: 9; number of reducers: 1
2021-01-06 14:05:19,846 Stage-1 map = 0%, reduce = 0%
2021-01-06 14:05:28,056 Stage-1 map = 22%, reduce = 0%, Cumulative CPU 11.06 sec
2021-01-06 14:05:33,197 Stage-1 map = 44%, reduce = 0%, Cumulative CPU 20.6 sec
2021-01-06 14:05:38,313 Stage-1 map = 56%, reduce = 0%, Cumulative CPU 26.09 sec
2021-01-06 14:05:39,333 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 31.39 sec
2021-01-06 14:05:44,461 Stage-1 map = 78%, reduce = 0%, Cumulative CPU 36.67 sec
2021-01-06 14:05:45,490 Stage-1 map = 89%, reduce = 0%, Cumulative CPU 42.19 sec
2021-01-06 14:05:51,630 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 48.39 sec
2021-01-06 14:05:52,650 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 51.18 sec
MapReduce Total cumulative CPU time: 51 seconds 180 msec
Ended Job = job_1609141291605_0035
MapReduce Jobs Launched:
Stage-Stage-1: Map: 9 Reduce: 1 Cumulative CPU: 51.18 sec HDFS Read: 1991740 HDFS Write: 109 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 51 seconds 180 msec
OK
767830000
Time taken: 42.069 seconds, Fetched: 1 row(s)
hive>
上面测试结果可以看出,textfile文件格式8分钟左右,orc文件格式只需要42秒
三.ORC相关参数
介绍一下ORC相关参数
hive.exec.orc.memory.pool
默认值:0.5
ORC文件写入器可以使用的堆的最大部分。hive.exec.orc.write.format
默认值: 空
定义要写入的文件的版本。可能的值是0.11和0.12。如果没有定义这个参数,ORC将使用Hive 0.12中引入的run length encoding (RLE)hive.exec.orc.base.delta.ratio
默认值:8
根据STRIPE_SIZE和BUFFER_SIZE定义基本写入器和增量写入器的比率。hive.exec.orc.default.stripe.size
默认值:25610241024 (268,435,456) in 0.13.0; 6410241024 (67,108,864) in 0.14.0
定义默认的ORC条带大小,以字节为单位hive.exec.orc.default.block.size
默认值: 25610241024 (268,435,456)
为ORC文件定义默认的文件系统块大小。hive.exec.orc.dictionary.key.size.threshold
默认值: 0.8
如果字典中的键数大于非空行总数的这个分数,则关闭字典编码。使用1表示始终使用字典编码。hive.exec.orc.default.row.index.stride
默认值: 10000
以行数为单位定义默认的ORC索引步长。(Stride是索引项表示的行数。)hive.exec.orc.default.buffer.size
默认值: 256*1024 (262,144)
以字节为单位定义默认的ORC缓冲区大小。hive.exec.orc.default.block.padding
默认值: true
定义默认的块填充。块填充在Hive 0.12.0中被添加hive.exec.orc.block.padding.tolerance
默认值: 0.05
将块填充的容错定义为条带大小的十进制分数(例如,默认值0.05是条带大小的5%)。对于默认的64Mb的ORC stripe和256Mb的HDFS块,使用默认的hive.exec.orc.block.padding.tolerance来保留最大3.2Mb的填充。在这种情况下,如果块中的可用大小超过3.2Mb,将插入一个新的较小的条带以适应该空间。这将确保写入的分条不会跨越块边界,并导致在节点本地任务中进行远程读取。hive.exec.orc.default.compress
默认值: ZLIB
为ORC文件定义默认的压缩编解码器。hive.exec.orc.encoding.strategy
默认值: SPEED
定义写入数据时使用的编码策略。更改此值只会影响整数的轻权重编码。这个标志不会改变更高级别压缩编解码器的压缩级别(如ZLIB)。可能的选项是速度和压缩。hive.orc.splits.include.file.footer
默认值: false
如果打开,ORC生成的分割将包括文件中关于条带的元数据。该数据是远程读取(从客户机或HiveServer2机器)并发送到所有任务的。hive.orc.cache.stripe.details.size
默认值: 10000
保存关于ORC的元信息的缓存大小缓存在客户端。hive.orc.cache.use.soft.references
默认值: false
默认情况下,ORC输入格式用于存储ORC文件页脚的缓存对缓存的对象使用硬引用。将此设置为true可以帮助避免内存压力下(在某些情况下)的内存不足问题,但代价是总体查询性能有一些不可预测性。hive.io.sarg.cache.max.weight.mb
默认值: 10
搜索参数缓存允许的最大权重,以兆字节为单位。默认情况下,缓存允许10MB的最大权重,超过这个值条目将被清除。设置为0,将完全禁用搜索参数缓存。hive.orc.compute.splits.num.threads
默认值: 10
ORC应该使用多少线程来并行地创建分割。hive.exec.orc.split.strategy
默认值: HYBRID
ORC应该使用什么策略来创建执行分割。可用的选项有“BI”、“ETL”和“HYBRID”。
混合模式读取所有文件的页脚,如果文件少于预期的mapper计数,如果平均文件大小小于默认的HDFS块大小,切换到每个文件生成1个split。ETL策略总是在生成分割前读取ORC页脚,而BI策略则是快速生成每个文件的分割,而不需要从HDFS读取任何数据。hive.exec.orc.skip.corrupt.data
默认值: false
如果ORC reader遇到损坏的数据,该值将用于确定是跳过损坏的数据还是抛出异常。默认行为是抛出异常hive.exec.orc.zerocopy
默认值: false
使用ORC读取零拷贝。(这需要Hadoop 2.3或更高版本。)hive.merge.orcfile.stripe.level
默认值: true
当用ORC文件格式写表时,Configuration Properties#hive.merge.mapfiles, Configuration Properties#hive.merge.mapredfiles or Configuration Properties#hive.merge.tezfiles 被设置为enable,
启用此配置属性将实现小ORC文件的条带级快速合并。请注意,启用此配置属性将不支持填充容错配置hive.orc.row.index.stride.dictionary.check
默认值: true
如果启用,字典检查将在第一行索引步长(默认为10000行)之后进行,否则字典检查将在写入第一个分条之前进行。在这两种情况下,使用或不使用dictionary的决定将在以后保留。hive.exec.orc.compression.strategy
默认值: SPEED
定义写入数据时使用的压缩策略。这改变了更高级别压缩编解码器(如ZLIB)的压缩级别。
可选项 SPEED or COMPRESSION.
参考
1.https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
2.http://lxw1234.com/archives/2016/04/630.htm