一. Service介绍与定义
http://kubernetes.kansea.com/docs/user-guide/services/
1. 问题
• 在多个Pod情况下,service 如何实现负载均衡的?
答:通过node节点kube-proxy组件完成请求转发
• Pod重启后IP变化,service是如何感知容器重启后的IP?
答:Kubernetes提供了一个简单的Endpoints API,service通过selector标签选择器不断的对Pod进行筛选,并将结果POST到同名的Endpoints对象。
• 如何通过域名访问后端应用?
答:通过集群内部coredns解析到service 的cluser-IP, 然后通过kube-proxy转发请求,同一命名空间的直接请求service-name即可,不同命名空间,则service-name.namespace-name
2. Service介绍
• 防止Pod失联
• 定义一组Pod的访问策略
• 支持ClusterIP,NodePort以及LoadBalancer三种类型
• Service的底层实现主要有Iptables和IPVS二种网络模式
3. Service定义
# cat my-service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: default
spec:
clusterIP: 10.0.0.123
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector: ##标签选择器,service将匹配的标签的一组pod关联起来
app: nginx
# kubectl apply -f my-service.yaml
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 443/TCP 4d23h
my-service ClusterIP 10.0.0.123 80/TCP 5s
nginx-service NodePort 10.0.0.138 80:43431/TCP 17h
# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.40.6.201:6443,10.40.6.209:6443 4d23h
my-service 172.17.31.3:80,172.17.31.4:80,172.17.59.2:80 + 1 more... 11s
nginx-service 172.17.31.3:80,172.17.31.4:80,172.17.59.2:80 + 1 more... 17h
service要动态感知后端IP的变化,得介入一个endpoints控制器,也就是每个service都有对应一个endpoints控制器,endpoints帮它关联后端的pod,service 通过selector标签选择器关联pod, 具体实现动态IP变化由endpoints来实现。
kubectl get endpoints 或 kubectl get ep
# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.40.6.201:6443,10.40.6.209:6443 4d23h
my-service 172.17.31.3:80,172.17.31.4:80,172.17.59.2:80 + 1 more... 4m53s
nginx-service 172.17.31.3:80,172.17.31.4:80,172.17.59.2:80 + 1 more... 17h
# kubectl get pod -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-deployment-5cdc94fdc8-8hjp8 1/1 Running 0 17h
nginx-deployment-5cdc94fdc8-bhgwk 1/1 Running 0 17h
nginx-deployment-5cdc94fdc8-wqb4d 1/1 Running 0 17h
# kubectl describe svc my-service
Name: my-service
Namespace: default
Labels:
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"my-service","namespace":"default"},"spec":{"clusterIP":"10.0.0.12...
Selector: app=nginx
Type: ClusterIP
IP: 10.0.0.123
Port: http 80/TCP
TargetPort: 80/TCP
Endpoints: 172.17.31.3:80,172.17.59.2:80,172.17.59.3:80
Session Affinity: None
Events:
4. Pod 与Service的关系

• 通过label-selector 相关联
• 通过Service实现Pod的负载均衡(TCP/UDP 4层)
# kubectl get deployment/nginx-deployment -o yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "3"
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"labels":{"app":"nginx"},"name":"nginx-deployment","namespace":"default"},"spec":{"replicas":3,"selector":{"matchLabels":{"app":"nginx"}},"template":{"metadata":{"labels":{"app":"nginx"}},"spec":{"containers":[{"image":"nginx:1.15.4","name":"nginx","ports":[{"containerPort":80}]}],"imagePullSecrets":[{"name":"registry-pull-secret"}]}}}}
creationTimestamp: 2019-06-03T09:38:26Z
generation: 3
labels: ###deployment控制器标签
app: nginx
name: nginx-deployment
namespace: default
resourceVersion: "550371"
selfLink: /apis/extensions/v1beta1/namespaces/default/deployments/nginx-deployment
uid: 567ccde6-85e3-11e9-8a6c-005056b66bc1
spec:
progressDeadlineSeconds: 600
replicas: 3
revisionHistoryLimit: 10
selector: ###这个deployment控制器的标签选择器,用于匹配关联pod标签
matchLabels:
app: nginx
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels: ###这是pod的标签,提供给deployment控制器和service的标签选择器配置关联
app: nginx
spec:
containers:
- image: nginx:1.15.4
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: registry-pull-secret
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
availableReplicas: 3
conditions:
- lastTransitionTime: 2019-06-03T09:38:26Z
lastUpdateTime: 2019-06-03T09:45:34Z
message: ReplicaSet "nginx-deployment-5cdc94fdc8" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
- lastTransitionTime: 2019-06-04T02:29:36Z
lastUpdateTime: 2019-06-04T02:29:36Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
observedGeneration: 3
readyReplicas: 3
replicas: 3
updatedReplicas: 3
二. Service三种类型
• ClusterIP:默认,分配一个集群内部可以访问的虚拟IP(VIP)
• NodePort:在每个Node上分配一个端口作为外部访问入口
• LoadBalancer:工作在特定的Cloud Provider上,例如Google Cloud,AWS,OpenStack
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 443/TCP 5d
my-service ClusterIP 10.0.0.123 80/TCP 52m
nginx-service NodePort 10.0.0.138 80:43431/TCP 18h
1. ClusterIP
Service 默认类型,分配一个集群内部可以访问的虚拟IP(VIP),同一个集群内部应用之间相互访问
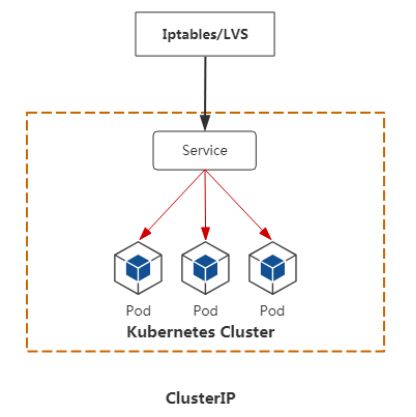
ClusterIP yaml配置文件:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: A
ports:
- protocol: TCP
port: 80
targetPort: 8080
2. NodePort
在每个Node上分配一个端口作为外部访问入口, 让外部用户访问到集群内部pod应用
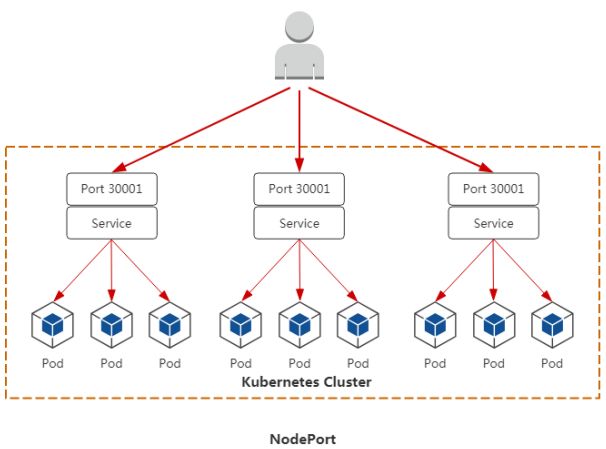
NodePort yaml资源配置文件:
# cat my-NodePort-service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30001 ##可指定也可以不指定,不指定会自动分配端口
type: NodePort
# kubectl create -f my-NodePort-service.yaml
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 443/TCP 5d2h
my-nodeport-service NodePort 10.0.0.105 80:30001/TCP 4m39s
# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.40.6.201:6443,10.40.6.209:6443 5d2h
my-nodeport-service 172.17.31.3:80,172.17.59.2:80,172.17.59.3:80 5m32s
# netstat -ntlp |grep 30001 ##每个node节点上启动了一个kube-proxy进程,并监听30001端口
tcp6 0 0 :::30001 :::* LISTEN 28035/kube-proxy
用浏览器打开nodeIP:30001即可访问到pod应用。在node节点上使用 ipvsadm -ln可以看到很多做端口轮询转发的规则。如果要提供给外用户访问,在前面再加个负载均衡器,比如nginx,haproxy,或公有云的LB,转发到指定的某几台node,域名解析到负载均衡器即可。
3. LoadBalancer
工作在特定的Cloud Provider上,例如Google Cloud,AWS,OpenStack, 不是我们自建的kubernetes集群里,是公有云提供商提供,公有云LB可以自动将我们node 上的service 的IP和端口加入LB中。
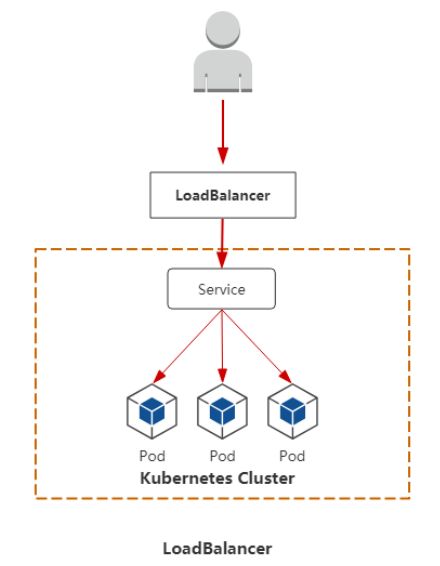
4. Service类型小结
NodePort请求应用流:
用户--->域名 ----> 负载均衡器(后端服务器) ---> NodeIP:Port ---> PodIP:Port
LoadBalancer请求应用流:
用户--->域名 ----> 负载均衡器(LB) ---> NodeIP:Port ---> PodIP:Port
LoadBalancer 提供特定云提供商底层LB接口,例如AWS,Google,Openstack
NodePort类型service IP和端口的限制是在master 节点的kube-apiserver配置文件中的两个参数指定--service-cluster-ip-range和--service-node-port-range
# cat /opt/kubernetes/cfg/kube-apiserver
KUBE_APISERVER_OPTS="--logtostderr=false \
--log-dir=/opt/kubernetes/logs/kube-apiserver \
--v=4 \
--etcd-servers=https://10.40.6.201:2379,https://10.40.6.210:2379,https://10.40.6.213:2379 \
--bind-address=10.40.6.201 \
--secure-port=6443 \
--advertise-address=10.40.6.201 \
--allow-privileged=true \
--service-cluster-ip-range=10.0.0.0/24 \
--service-node-port-range=30000-50000 \
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota,NodeRestriction \
--authorization-mode=RBAC,Node \
--enable-bootstrap-token-auth \
--token-auth-file=/opt/kubernetes/cfg/token.csv \
--tls-cert-file=/opt/kubernetes/ssl/server.pem \
--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \
--client-ca-file=/opt/kubernetes/ssl/ca.pem \
--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \
--etcd-cafile=/opt/etcd/ssl/ca.pem \
--etcd-certfile=/opt/etcd/ssl/server.pem \
--etcd-keyfile=/opt/etcd/ssl/server-key.pem"
三. Service 代理模式
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 组件负责为 Service 实现了一种 VIP(虚拟 IP)的形式,完成流量转发规则的生成。kube-proxy网络底层流量代理转发与负载均衡实现有两种方式:
• Iptables
• IPVS
可以通过kube-proxy配置文件指定--proxy-mode:
# cat /opt/kubernetes/cfg/kube-proxy
KUBE_PROXY_OPTS="--logtostderr=false \
--log-dir=/opt/kubernetes/logs/kube-proxy \
--v=4 \
--hostname-override=10.40.6.210 \
--cluster-cidr=10.0.0.0/24 \
--proxy-mode=ipvs \
--kubeconfig=/opt/kubernetes/cfg/kube-proxy.kubeconfig"
1. Iptables代理模式
代理模式之Iptables工作原理:
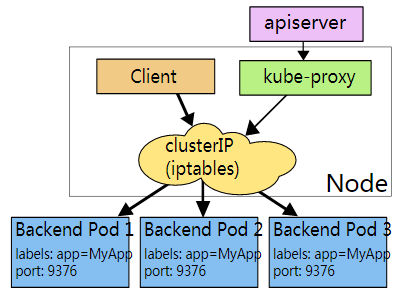
kube-proxy 会监视 Kubernetes master 对Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会生成 iptables 规则,从而捕获到该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend pod中的某个上面。 对于每个 Endpoints 对象,它也会生成 iptables 规则,这个规则会选择一个 backend Pod。默认的策略是,随机选择一个 backend pod。 实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 "ClientIP" (默认值为 "None")。和 userspace 代理类似,网络返回的结果是,任何到达 Service 的 IP:Port 的请求,都会被代理到一个合适的 backend pod,不需要客户端知道关于 Kubernetes、Service、或 Pod 的任何信息。 这应该比 userspace 代理更快、更可靠。然而,不像 userspace 代理,如果初始选择的 Pod 没有响应,iptables 代理不能够自动地重试另一个 Pod,所以它需要依赖readiness probes(Pod检查检查策略,也就是探针)
# cat /opt/kubernetes/cfg/kube-proxy
KUBE_PROXY_OPTS="--logtostderr=false \
--log-dir=/opt/kubernetes/logs/kube-proxy \
--v=4 \
--hostname-override=10.40.6.210 \
--cluster-cidr=10.0.0.0/24 \
--proxy-mode=iptables \
--kubeconfig=/opt/kubernetes/cfg/kube-proxy.kubeconfig"
# systemctl restart kube-proxy
# kubectl get svc ##在master 节点查看clusterIP
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 443/TCP 5d5h
my-service ClusterIP 10.0.0.123 80/TCP 5h28m
# iptables-save |grep 10.0.0.123 ##node节点iptables规则
....
-A KUBE-SERVICES -d 10.0.0.123/32 -p tcp -m comment --comment "default/my-service:http cluster IP" -m tcp --dport 80 -j KUBE-SVC-I37Z43XJW6BD4TLV
# iptables-save |grep KUBE-SVC-I37Z43XJW6BD4TLV
-A KUBE-SVC-I37Z43XJW6BD4TLV -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-H5NGRYAMAKIASDJ5
-A KUBE-SVC-I37Z43XJW6BD4TLV -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-6MGVLH7DQH7EFO3X
-A KUBE-SVC-I37Z43XJW6BD4TLV -j KUBE-SEP-RHHV7QUEQUTYC3QN
# iptables-save |grep KUBE-SEP-H5NGRYAMAKIASDJ5
....
-A KUBE-SEP-H5NGRYAMAKIASDJ5 -p tcp -m tcp -j DNAT --to-destination 172.17.31.3:80
....
2.IPVS代理模式
代理模式之IPVS工作原理:
iptables方式service过多时的弊端:
• 创建很多iptables规则(更新,非增量式)
• iptables规则从上到下逐条匹配(延时大)
• iptables工作在用户态
救世主:IPVS
IPVS工作在内核态,iptables工作在用户态;
LVS 基于IPVS内核调度模块实现的负载均衡;
阿里云SLB,基于LVS实现四层负载均衡。
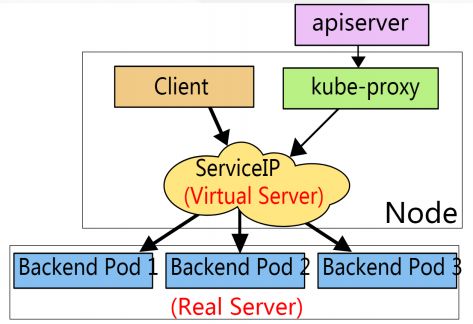
kube-proxy 使用的IPVS模式,启动之后会在node生成一个kube-ipvs0网卡,此网卡的ip就是对应service 的CLUSTER-IP
# ip a
.....
8: kube-ipvs0: mtu 1500 qdisc noop state DOWN group default
link/ether ee:0b:f9:77:95:7c brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/32 brd 10.0.0.1 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.0.0.198/32 brd 10.0.0.198 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.0.0.138/32 brd 10.0.0.138 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.0.0.123/32 brd 10.0.0.123 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.0.0.105/32 brd 10.0.0.105 scope global kube-ipvs0
valid_lft forever preferred_lft forever
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.0.0.1:443 rr
-> 10.40.6.201:6443 Masq 1 0 0
-> 10.40.6.209:6443 Masq 1 0 0
TCP 10.0.0.138:80 rr
-> 172.17.31.3:80 Masq 1 0 0
-> 172.17.59.2:80 Masq 1 0 0
-> 172.17.59.3:80 Masq 1 0 0
TCP 10.0.0.198:443 rr
-> 172.17.31.2:8443 Masq 1 0 0
TCP 10.40.6.213:30001 rr
-> 172.17.31.3:80 Masq 1 0 0
-> 172.17.59.2:80 Masq 1 0 0
-> 172.17.59.3:80 Masq 1 0 0
....
这里的real server正是我们启动的pod。ipvs 转发后端IP正好是pod IP
3. Iptables与IPVS优缺点
Iptables:
• 灵活,功能强大(可以在数据包不同阶段对包进行操作)
• 规则遍历匹配和更新,呈线性时延
IPVS:
• 工作在内核态,有更好的性能
• 调度算法丰富:rr,wrr,lc,wlc,ip hash...
在企业中尽可能使用IPVS模式,调度算法可以在kube-proxy配置文件中配置参数重启即可:--ipvs-scheduler=wrr
四. 集群内部DNS服务(CoreDNS)
1. DNS 存在的目的
service CLUSTER-IP 也不是固定不变的,在应用程序也不可能写CLUSTER-IP,这里建议写域名(service名称),kubernetes集群DNS 将service 名称解析为CLUSTER-IP,DNS服务实时监视Kubernetes API,为每一个Service创建DNS记录用于域名解析。
2. CoreDNS部署
通过yaml配置文件部署
https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/dns/coredns/coredns.yaml.sed
apiVersion: v1
kind: ServiceAccount ##ServiceAccount主要提供pod 访问apiserver提供权限访问验证
metadata:
name: coredns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1 ### rbac是角色的访问权限控制
kind: ClusterRole ##ClusterRole是集群范围对象,所以这里不需要定义"namespace"字段
metadata:
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: Reconcile
name: system:coredns
rules: ##授权规则
- apiGroups:
- "" ## 空字符串""表明使用core API group
resources: ##授权资源对象
- endpoints
- services
- pods
- namespaces
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding ##集群角色的绑定
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: EnsureExists
name: system:coredns
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:coredns
subjects:
- kind: ServiceAccount ##这里指定绑定的ServiceAccount
name: coredns ##ServiceAccount的名称为coredns,对应上边定义的ServiceAccount
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap ##这是coreDNS 的配置文件
metadata:
name: coredns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
data:
Corefile: |
.:53 {
errors
health
ready
kubernetes $DNS_DOMAIN in-addr.arpa ip6.arpa { ##DNS的域,比如A域,B域,替换为kubelet.config配置文件中的clusterDomain
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
---
apiVersion: apps/v1
kind: Deployment ##这是部署coredns服务
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
annotations:
seccomp.security.alpha.kubernetes.io/pod: 'docker/default'
spec:
priorityClassName: system-cluster-critical
serviceAccountName: coredns ##这里指定这个pod携带coredns 这个角色的权限访问apiserver
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
nodeSelector:
beta.kubernetes.io/os: linux
containers: ##容器的定义
- name: coredns
image: k8s.gcr.io/coredns:1.5.0 ##镜像路径改为coredns/coredns:1.5.0
imagePullPolicy: IfNotPresent
resources:
limits:
memory: $DNS_MEMORY_LIMIT ##pod总内存限制,实际得改为,例如170Mi
requests:
cpu: 100m
memory: 70Mi
args: [ "-conf", "/etc/coredns/Corefile" ]
volumeMounts: ##这里引用了刚刚的配置文件
- name: config-volume
mountPath: /etc/coredns
readOnly: true
ports: ##定义ports,这个pod提供哪些端口对外服务
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153 ##暴露监控端口
name: metrics
protocol: TCP
livenessProbe: ##pod健康检查
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /ready
port: 8181
scheme: HTTP
securityContext: ##上下文
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- all
readOnlyRootFilesystem: true
dnsPolicy: Default ##DNS策略
volumes: ##数据卷引用上边定义的
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1 ##coredns pod service
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: $DNS_SERVER_IP ##使用CLUSTER-IP 即可,替换为kubelet.config配置文件中的clusterDNS
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
- name: metrics
port: 9153
protocol: TCP
这里主要修改几个参数:DNS域、DNS地址(IP),coredns pod内存限制和镜像地址
# kubectl apply -f coredns.yaml
serviceaccount/coredns created
clusterrole.rbac.authorization.k8s.io/system:coredns created
clusterrolebinding.rbac.authorization.k8s.io/system:coredns created
configmap/coredns created
deployment.apps/coredns created
service/kube-dns created
# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-56666cdc6b-g5cpw 1/1 Running 0 4m22s
kubernetes-dashboard-774f47666c-97c86 1/1 Running 0 5d1h
创建一个pod进行service名称解析验证
# kubectl run -it --image=busybox:1.28.4 --rm --restart=Never sh
If you don't see a command prompt, try pressing enter.
/ # nslookup my-service ## 解析service 名称my-service
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: my-service
Address 1: 10.0.0.123 my-service.default.svc.cluster.local
3. ClusterIP A记录
ClusterIP A记录格式:
示例:my-service.default.svc.cluster.local
跨命名空间做域名解析:
pod 请求同一个命名空间service时,只写service名称即可;请求不在同一个命名空间service时,得在service名称加上“.命名空间”,比如: my-service.default
# kubectl run -it --image=busybox:1.28.4 --rm --restart=Never sh -n kube-system
/ # nslookup my-service
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
nslookup: can't resolve 'my-service'
/ # nslookup my-service.default
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: my-service.default
Address 1: 10.0.0.123 my-service.default.svc.cluster.local