引言
上篇文章我们熟悉了Buffer、ByteString、Segment等核心类,了解了Buffer的结构和工作流程,这篇继续从源码分析它的超时机制。
超时机制
OkHttp的所有IO操作都是基于Okio的,包括磁盘读写、Socket流读写等等,而流的读写经常阻塞在某个错误上(如网络环境不佳),Okio引入超时机制就是为了防止流读写阻塞,为了支持网络超时处理,Okio也对Socket做了超时机制实现。
基础超时机制
以Sink为例,Okio包装OutputStream构造Sink的方法如下:
private static Sink sink(final OutputStream out, final Timeout timeout) {
if (out == null) throw new IllegalArgumentException("out == null");
if (timeout == null) throw new IllegalArgumentException("timeout == null");
return new Sink() {
@Override public void write(Buffer source, long byteCount) throws IOException {
checkOffsetAndCount(source.size, 0, byteCount);
while (byteCount > 0) {
//同步超时检测
timeout.throwIfReached();
Segment head = source.head;
int toCopy = (int) Math.min(byteCount, head.limit - head.pos);
out.write(head.data, head.pos, toCopy);
head.pos += toCopy;
byteCount -= toCopy;
source.size -= toCopy;
if (head.pos == head.limit) {
source.head = head.pop();
SegmentPool.recycle(head);
}
}
}
@Override public void flush() throws IOException {
out.flush();
}
@Override public void close() throws IOException {
out.close();
}
@Override public Timeout timeout() {
return timeout;
}
@Override public String toString() {
return "sink(" + out + ")";
}
};
}
输出流写入数据过程中同步检测是否超时 timeout.throwIfReached(),如果超时会抛出IOException。
/**
* Throws an {@link InterruptedIOException} if the deadline has been reached or if the current
* thread has been interrupted. This method doesn't detect timeouts; that should be implemented to
* asynchronously abort an in-progress operation.
*/
public void throwIfReached() throws IOException {
if (Thread.interrupted()) {
throw new InterruptedIOException("thread interrupted");
}
//超时判断
if (hasDeadline && deadlineNanoTime - System.nanoTime() <= 0) {
throw new InterruptedIOException("deadline reached");
}
}
如果超时条件成立,简单粗暴地抛出InterruptedIOException,可以看出这个方法是不会做超时处理的,应该是是一个异步进度操作单元来实现这个类,进行检查超时。但是看到它对Socket的包装时:
/**
* Returns a sink that writes to {@code socket}. Prefer this over {@link
* #sink(OutputStream)} because this method honors timeouts. When the socket
* write times out, the socket is asynchronously closed by a watchdog thread.
*/
public static Sink sink(Socket socket) throws IOException {
if (socket == null) throw new IllegalArgumentException("socket == null");
if (socket.getOutputStream() == null) throw new IOException("socket's output stream == null");
//构建异步超时检测单元
AsyncTimeout timeout = timeout(socket);
//第一层包装:包装socket流
Sink sink = sink(socket.getOutputStream(), timeout);
//第二层包装:支持超时检测的sink
return timeout.sink(sink);
}
我们发现AsyncTimeout类又对sink做了一层封装,为sink添加超时检测功能。
AsyncTimeout
从上面对Socket的封装代码,可以看出它对socket做了两层包装,第一次包装socket输出流,第二次通过AsyncTimeout包装,加入超时机制,我们看看异步超时检测单元AsyncTimeout:
public class AsyncTimeout extends Timeout {
/**
* Don't write more than 64 KiB of data at a time, give or take a segment. Otherwise slow
* connections may suffer timeouts even when they're making (slow) progress. Without this, writing
* a single 1 MiB buffer may never succeed on a sufficiently slow connection.
*/
//不要一次写超过64k的数据否则可能会在慢连接中导致超时
private static final int TIMEOUT_WRITE_SIZE = 64 * 1024;
/** Duration for the watchdog thread to be idle before it shuts itself down. */
//超时检测单元链表为空时,看门狗空闲休眠时间
private static final long IDLE_TIMEOUT_MILLIS = TimeUnit.SECONDS.toMillis(60);
private static final long IDLE_TIMEOUT_NANOS = TimeUnit.MILLISECONDS.toNanos(IDLE_TIMEOUT_MILLIS);
/**
* The watchdog thread processes a linked list of pending timeouts, sorted in the order to be
* triggered. This class synchronizes on AsyncTimeout.class. This lock guards the queue.
*
* Head's 'next' points to the first element of the linked list. The first element is the next
* node to time out, or null if the queue is empty. The head is null until the watchdog thread is
* started and also after being idle for {@link #IDLE_TIMEOUT_MILLIS}.
*/
//当在sink/source读写操作和flush\close操作时都会调用enter()方法构建新的超时检测单元,按超时时间大小排序,加入链表
static @Nullable AsyncTimeout head;//链表头
/** True if this node is currently in the queue. */
//timeout入队标记,出队则设置为false
private boolean inQueue;
/** The next node in the linked list. */
private @Nullable AsyncTimeout next;//后继节点
/** If scheduled, this is the time that the watchdog should time this out. */
private long timeoutAt;//本节点的超时时间
.......
}
首先就是一个最大的写值,定义为64K,刚好和一个Buffer大小一样。注释解释是如果连续读写超过这个数字的字节,那么及其容易导致超时,所以为了限制这个操作,直接给出了一个能写的最大数。
下面两个参数head和next,很明显表明这是一个单链表,timeoutAt则是超时时间。使用者在操作之前首先要调用enter()方法,这样相当于注册了这个超时监听,然后配对的实现exit()方法。这样exit()有一个返回值会表明超时是否出发,注意:这个timeout是异步的,可能会在exit()后才调用。
下面我们看Okio是如何包装超时机制的,看AsyncTimeout的sink方法:
/**
* Returns a new sink that delegates to {@code sink}, using this to implement timeouts. This works
* best if {@link #timedOut} is overridden to interrupt {@code sink}'s current operation.
*/
public final Sink sink(final Sink sink) {
return new Sink() {
@Override public void write(Buffer source, long byteCount) throws IOException {
checkOffsetAndCount(source.size, 0, byteCount);
while (byteCount > 0L) {
// Count how many bytes to write. This loop guarantees we split on a segment boundary.
long toWrite = 0L;
//获得应该读写的大小:toWrite<= byteCount&& toWrite< TIMEOUT_WRITE_SIZE
for (Segment s = source.head; toWrite < TIMEOUT_WRITE_SIZE; s = s.next) {
int segmentSize = s.limit - s.pos;
toWrite += segmentSize;
if (toWrite >= byteCount) {
toWrite = byteCount;
break;
}
}
// Emit one write. Only this section is subject to the timeout.
boolean throwOnTimeout = false;
//超时机制入口
enter();
try {
sink.write(source, toWrite);
byteCount -= toWrite;
throwOnTimeout = true;
} catch (IOException e) {
//超时机制出口
throw exit(e);
} finally {
exit(throwOnTimeout);
}
}
}
@Override public void flush() throws IOException {
boolean throwOnTimeout = false;
//超时机制入口
enter();
try {
sink.flush();
throwOnTimeout = true;
} catch (IOException e) {
throw exit(e);
} finally {
exit(throwOnTimeout);
}
}
@Override public void close() throws IOException {
boolean throwOnTimeout = false;
//超时机制入口
enter();
try {
sink.close();
throwOnTimeout = true;
} catch (IOException e) {
throw exit(e);
} finally {
exit(throwOnTimeout);
}
}
@Override public Timeout timeout() {
return AsyncTimeout.this;
}
@Override public String toString() {
return "AsyncTimeout.sink(" + sink + ")";
}
};
}
从上面代码我们可以得知:
1.enter()和exit()方法成对出现, exit()方法无论是否抛出异常都会和enter配对出现;
2.在读写过程、flush和close方法中都有超时检测机制.
下面我们先看超时机制的如何启动的,exit方法后面再讲。
enter()方法
public final void enter() {
//enter/exit没配对,抛出异常
if (inQueue) throw new IllegalStateException("Unbalanced enter/exit");
//获取超时时间
long timeoutNanos = timeoutNanos();
boolean hasDeadline = hasDeadline();
//不需要超时检测
if (timeoutNanos == 0 && !hasDeadline) {
return; // No timeout and no deadline? Don't bother with the queue.
}
//入队标记
inQueue = true;
scheduleTimeout(this, timeoutNanos, hasDeadline);
}
这里仅仅是对超时条件进行检测,不需要超时检测直接返回,需要则执行scheduleTimeout,它也是超时机制的核心之一
//超时检测单元调度
//1.如果是第一次执行,开启看门狗
//2.根据当前时间和timeoutNanos设置本节点的超时时间
//3.根据当前时间计算超时剩余时间remainingNanos,然后按剩余时间从小到大排序,插入新节点,当
private static synchronized void scheduleTimeout(
AsyncTimeout node, long timeoutNanos, boolean hasDeadline) {
// Start the watchdog thread and create the head node when the first timeout is scheduled.
if (head == null) {
head = new AsyncTimeout();
new Watchdog().start();
}
long now = System.nanoTime();
if (timeoutNanos != 0 && hasDeadline) {
// Compute the earliest event; either timeout or deadline. Because nanoTime can wrap around,
// Math.min() is undefined for absolute values, but meaningful for relative ones.
//一系列判断设置节点的超时时间
node.timeoutAt = now + Math.min(timeoutNanos, node.deadlineNanoTime() - now);
} else if (timeoutNanos != 0) {
node.timeoutAt = now + timeoutNanos;
} else if (hasDeadline) {
node.timeoutAt = node.deadlineNanoTime();
} else {
throw new AssertionError();
}
// Insert the node in sorted order.
// 拿到剩余时间,从小到大排序,添加新节点
long remainingNanos = node.remainingNanos(now);
for (AsyncTimeout prev = head; true; prev = prev.next) {
//尾部节点或者剩余时间更小,插入prev位置
if (prev.next == null || remainingNanos < prev.next.remainingNanos(now)) {
node.next = prev.next;
prev.next = node;
//新节点的剩余时间最小,插入表头,唤醒看门狗,重新设置睡眠时间
if (prev == head) {
AsyncTimeout.class.notify(); // Wake up the watchdog when inserting at the front.
}
break;
}
}
}
scheduleTimeout的主要功能是开启看门狗,设置节点超时时间并按剩余时间排序插入链表,如果新节点的剩余时间最小,则插入表头,此时由于最小剩余时间发生变化,需要唤醒看门狗重新设置挂起。总之这个方法就是干了两件事:1开启看门狗;2.把新的超时节点按剩余时间顺序插入链表。
看门狗
看门狗的功能就是轮询判断头节点是否超时,如果超时则删除它,它和超时单元链表的关系如下图:
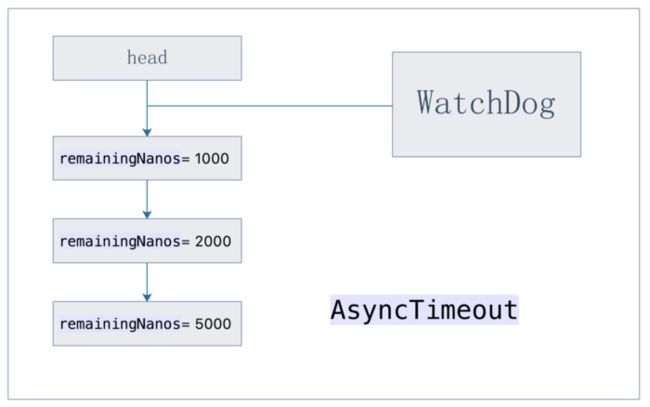
下面我们在研究超时机制第二个核心看门狗:
//异步看门狗轮询线程
private static final class Watchdog extends Thread {
Watchdog() {
super("Okio Watchdog");
setDaemon(true);
}
public void run() {
while (true) {//无限轮询
try {
AsyncTimeout timedOut;
//每一次循环为同步操作
synchronized (AsyncTimeout.class) {
//取头结点,判断是否超时,如果超时则返回这个节点,并从链表中移除
timedOut = awaitTimeout();
// Didn't find a node to interrupt. Try again.
if (timedOut == null) continue;//为空表示此时还没有超时节点
// The queue is completely empty. Let this thread exit and let another watchdog thread
// get created on the next call to scheduleTimeout().
//如果赶回head,表示链表即时在等待一段时间后仍然为空,则返回,等待下一个enter()-> scheduleTimeout()->starWatchDog
if (timedOut == head) {
head = null;//reset
return;
}
}
// Close the timed out node.
//timedOut为已超时的节点,子类实现,超时时处理
timedOut.timedOut();
} catch (InterruptedException ignored) {
}
}
}
}
/**
* Removes and returns the node at the head of the list, waiting for it to time out if necessary.
* This returns {@link #head} if there was no node at the head of the list when starting, and
* there continues to be no node after waiting {@code IDLE_TIMEOUT_NANOS}. It returns null if a
* new node was inserted while waiting. Otherwise this returns the node being waited on that has
* been removed.
*/
static @Nullable AsyncTimeout awaitTimeout() throws InterruptedException {
// Get the next eligible node.
//1.取第一个结点head.next,
AsyncTimeout node = head.next;
// The queue is empty. Wait until either something is enqueued or the idle timeout elapses.
//2.如果链表为空,则线程释放锁,挂起固定时间,挂起时间内,有可能有新节点加入
if (node == null) {//链表为空
long startNanos = System.nanoTime();
AsyncTimeout.class.wait(IDLE_TIMEOUT_MILLIS);
//挂起时间过去,head.next仍然为空,则返回head节点,此时表明链表彻底空闲,看门狗线程退出
//看门狗线程由新加进来的节点唤醒(具体分析看scheduleTimeout),此时俩条件均不满足,返回null,然后看门狗走下面的代码 if (timedOut == null) continue;继续轮询
return head.next == null && (System.nanoTime() - startNanos) >= IDLE_TIMEOUT_NANOS
? head // The idle timeout elapsed.
: null; // The situation has changed.
}
//链表不为空,此node的剩余时间最小,计算它是否超时
long waitNanos = node.remainingNanos(System.nanoTime());
// The head of the queue hasn't timed out yet. Await that.
//如果未超时,则挂起,挂起时长为node的剩余时间,此时间段内节点一直在链表中
if (waitNanos > 0) {
// Waiting is made complicated by the fact that we work in nanoseconds,
// but the API wants (millis, nanos) in two arguments.
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
AsyncTimeout.class.wait(waitMillis, (int) waitNanos);
return null;//返回空,继续轮询
}
// The head of the queue has timed out. Remove it.
//node已经超时,删除节点,返回node
head.next = node.next;
node.next = null;
return node;
}
/**
* Returns the amount of time left until the time out. This will be negative if the timeout has
* elapsed and the timeout should occur immediately.
* 计算剩余时间
*/
private long remainingNanos(long now) {
return timeoutAt - now;
}
阅读看门狗代码,一定要注意锁AsyncTimeout.class的wait()的方法随时都可能被scheduleTimeout中下面的代码唤醒:
// Insert the node in sorted order.
long remainingNanos = node.remainingNanos(now);
for (AsyncTimeout prev = head; true; prev = prev.next) {
if (prev.next == null || remainingNanos < prev.next.remainingNanos(now)) {
node.next = prev.next;
prev.next = node;
if (prev == head) {
//新节点的剩余时间最小,插入表头,释放锁,唤醒看门狗,重新设置根据表头节点设置挂起等待时间
AsyncTimeout.class.notify(); // Wake up the watchdog when inserting at the front.
}
break;
}
}
下面着重分析看门狗核心方法 awaitTimeout
功能:尝试获取已经超时的节点,如果存在则从链表中移除返回它,如果不存在,则挂起,挂起时间为第一个节点的剩余时间。
下面是挂起时间内不被唤醒时的正常流程:
1.如果链表为空,则睡眠固定时间,注意睡眠时间内,有可能有新节点加入。睡眠时间过去,head.next仍然为空,则返回head节点,此时表明链表彻底空闲,看门狗线程退出;看门狗线程由新加进来的节点唤醒(具体分析看scheduleTimeout()),返回null,然后看门狗走下面的代码 if (timedOut == null) continue;继续轮询;
2,链表不为空,则此node的剩余时间最小,计算它是否超时,如果超时,从链表删除返回该节点,否则挂起,时间为它的剩余时间。
新节点的剩余时间更短时,挂起过程被scheduleTimeout方法唤醒(前面分析过),awaitTimeout()立即返回空,继续轮询,下个循环就会处理这个“更加紧急”的节点。
小结:分析完超时机制俩大核心,我个人觉得这是典型的生产者-消费者模型,scheduleTimeout()方法是生产者,看门狗是消费者,生产者在更加紧急的节点进入的条件下才唤醒消费者,消费者根据时间流逝按紧急程度处理他们,移除超时节点。
exit()方法
前面说到enter()方法和exit()方法成对出现,enter方法开启看门狗和新建节点加入链表,猜测exit方法必然是检测是否超时并移除节点。
/**
* Returns either {@code cause} or an IOException that's caused by {@code cause} if a timeout
* occurred. See {@link #newTimeoutException(java.io.IOException)} for the type of exception
* returned.
*/
final IOException exit(IOException cause) throws IOException {
if (!exit()) return cause;
//返回超时异常
return newTimeoutException(cause);
}
/** Returns true if the timeout occurred. */
public final boolean exit() {
if (!inQueue) return false;
inQueue = false;
return cancelScheduledTimeout(this);
}
exit()会调用cancelScheduledTimeout方法取消并检测是否超时:
/** Returns true if the timeout occurred. */
private static synchronized boolean cancelScheduledTimeout(AsyncTimeout node) {
// Remove the node from the linked list.
//尝试从链表中移除,如果找到,表示未超时,否则表示超时
for (AsyncTimeout prev = head; prev != null; prev = prev.next) {
if (prev.next == node) {
prev.next = node.next;
node.next = null;
return false;
}
}
// The node wasn't found in the linked list: it must have timed out!
return true;
}
由于看门狗会根据时间流逝移除已经超时的节点,所以链表中存放的都是未超时节点。当exit执行时,从链表中尝试删除本节点,如果节点在链表中则删除它,返回false,否则返回true.
总结
今天我们重点分析了Okio异步超时机制,学习了同步锁及生产者-消费者模型在这里的应用,截止目前我们仍然没有从顶之下梳理一下它的流程。由于OkHttp的超时机制底层是有Okio实现,而且实现机制很巧妙,所以这里做了个插曲,还望见谅。下一篇我们从Okio的调用层面来梳理它整个工作流程。