大家好,我是melo,一名大二后台练习生,大年初三,我又来充当反内卷第一人了!!!
专栏引言
MySQL,一个熟悉又陌生的名词,早在学习Javaweb的时候,我们就用到了MySQL数据库,在那个阶段,MySQL对我们来说似乎只是一个存储数据的好东西,存储时一股脑往里边塞,查询时也是盲目的全表查询(不带一点点优化)。
我们总是自欺欺人的觉得,我们通过其他方面来优化就好了阿,迟迟不愿面对MySQL高级,转而学习一些看似更为"高级"的东西,学Redis,来分担MySQL的压力,学MyCat等中间件,实现主从复制,读写分离,分库分表等等。(说的就是melo没错了)
到了准备面试的时候,发现面试题里边的MySQL一问三不知~

而自己学到的前沿中间件,问的几乎很少!!自己也只是会用,写简历时只能弱弱写上"了解"xxx中间件……
当然了,学习MySQL高级篇,不单单只是为了面试,实际的项目中,这一块的优化是十分重要的,体验过服务器宕机后,只能默默........
从现在开始吧,此时上岸还来得及!!!趁着大二上的寒假,补充补充MySQL高级篇的知识点,从如下几方面开启MySQL高级篇之旅
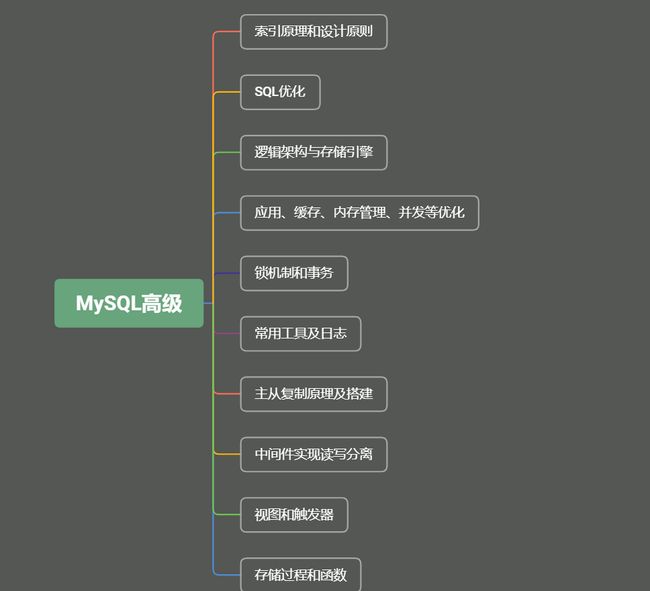
本篇速览
早在MySQL基础篇,我们就听说了索引这么个东西,听起来是个很高级的东西,但当时只停留在了,索引能够加快查找的效率这一阶段的认知。这篇将从如下几点,来带你逐一攻破ta:
- 索引到底是什么
- 索引底层的实现
- 聚簇索引是什么?二级索引呢?
- 最左前缀原则
- 如何设计索引,遵循的原则
- 索引相关语法
本篇篇幅较长,全文近6000字,可以收藏下来慢慢啃,没事就掏出来翻阅翻阅,觉得对您有帮助的话,melo还会持续更进完善本篇文章和MySQL专栏
- 不过就怕等到我更新时,那会您不方便找到我了hhh(高情商求关注)
索引定义
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。如下面的示意图所示 :
其实简单来说,索引就是一个排好序的数据结构
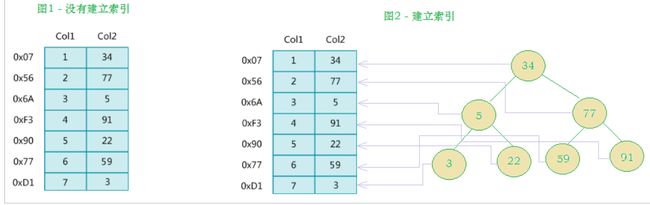
左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应数据。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。索引是数据库中用来提高性能的最常用的工具。
索引优势
- 加快查找和排序的速率,降低数据库的IO成本以及CPU的消耗
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
索引劣势
- 索引实际上也是一张表,保存了主键和索引字段,并指向实体类的记录,本身需要占用空间
- 虽然增加了查询效率,但对于增删改,每次改动表,还需要更新一下索引
- 新增:自然需要在索引树中新增节点
- 删除:索引树中指向的记录可能会失效,意味着这棵索引树很多节点,都是失效的
- 改动:索引树中节点的指向可能需要改变
索引结构
索引是在MySQL的存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引都不一定完全相同,而且也不是所有的引擎都支持所有的索引类型。
- BTREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
- HASH 索引:只有Memory引擎支持 , 使用场景简单 。
- R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍。
- Full-text (全文索引) :全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从Mysql5.6版本开始支持全文索引。
MyISAM、InnoDB、Memory三种存储引擎对各种索引类型的支持
| 索引 | INNODB引擎 | MYISAM引擎 | MEMORY引擎 |
|---|---|---|---|
| BTREE索引 | 支持 | 支持 | 支持 |
| HASH 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引、复合索引、前缀索引、唯一索引默认都是使用 B+tree 索引,统称为 索引。
BTREE
多路平衡搜索树,一棵m阶(m叉)BTREE满足:
- 每个节点最多m个孩子
- 孩子个数:ceil(m/2) 到 m
- 关键字个数:ceil(m/2)-1 到 m-1
ceil表示向上取整,ceil(2.3)=3
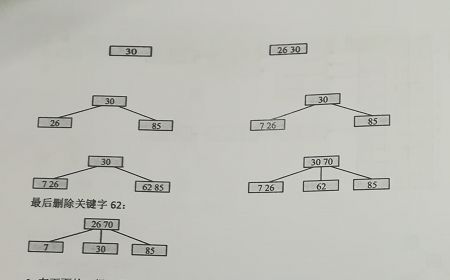
插入关键字案例

保证不破坏m阶B树的性质
由于3阶,最多只能2个节点,所以一开始26和30在一起,之后再来个85就要开始分裂了,30作为中间上位,26保持,85去到右边
即:中间位置上位,然后左边留在旧节点,右边去到新结点
如图中的70再插入的时候,70刚好是中间位置上位,然后62保持,85又去分一个新节点出来
上位后又需要分裂
继续向上分裂即可,同理的
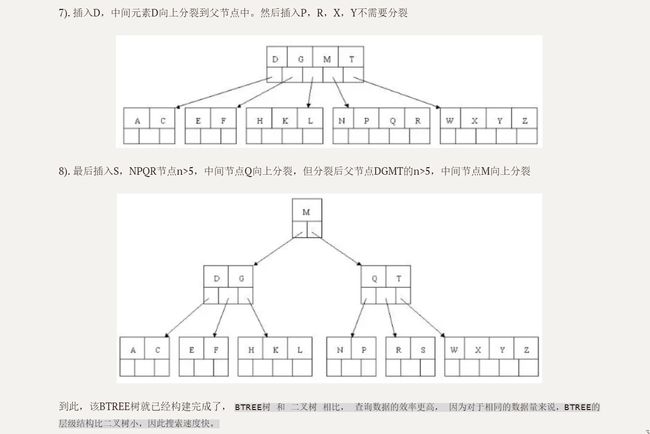
相比优势
相比二叉搜索树,高度/深度更低,自然查询效率更高。
B+TREE
- B+树有两种类型的节点:内部结点(也称索引结点)和叶子结点。内部节点就是非叶子节点,内部节点不存储数据,只存储索引,数据都存储在叶子节点。
- 内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
- 每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
- 父节点存有右孩子的第一个元素的索引。
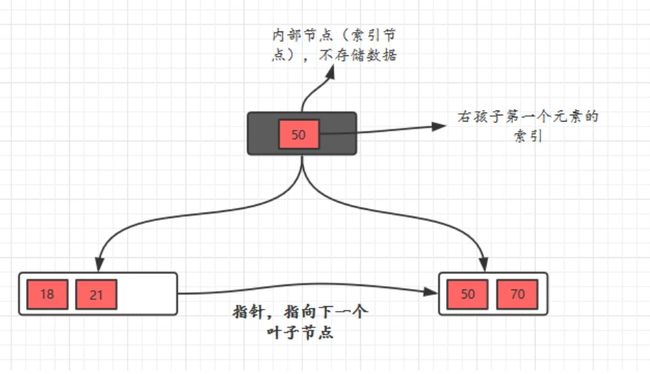
相比优势
- B+Tree的查询效率更加稳定。由于B+Tree只有叶子节点保存key信息,查询任何key都要从root走到叶子,所以更稳定。
- 只需遍历叶子节点,就可以实现整棵树的遍历。
MySQL中的B+Tree
MySql索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针(整体类似一个双向链表的结构),就形成了带有顺序指针的B+Tree,提高区间访问的性能。
MySQL中的 B+Tree 索引结构示意图: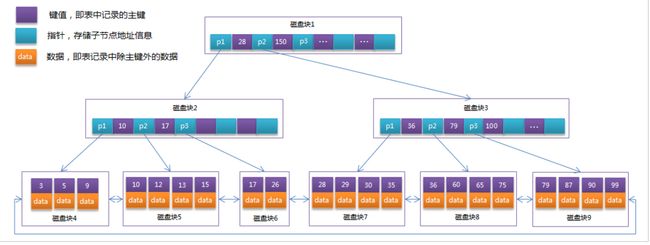
索引原理
BTree索引:
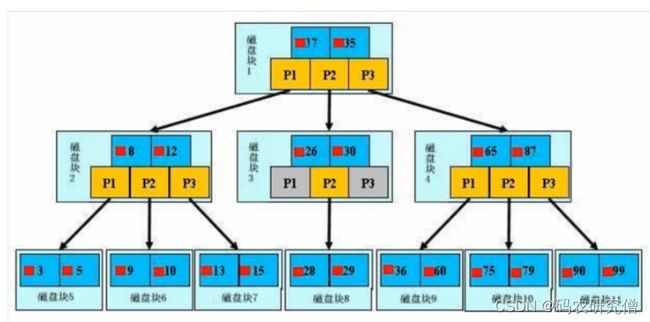
初始化介绍
浅蓝色的称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示)
如磁盘块1包含数据项17和35,包含指针P1、P2、P3,
P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。
- 真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。`
- 非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。`
查找过程
如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO。在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中通过二分查找搜索到29,结束查询,总计三次IO。
真实的情况是,3层的B+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
索引分类
在InnoDB中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。又因为前面我们提到的,InnoDB使用了B+树索引模型,所以数据都是存储在B+树中的。
每一个索引在InnoDB里面对应一棵B+树。
假设,我们有一个主键列为ID的表,表中有字段k,并且在k上有索引。
这个表的建表语句是:
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
表中R1~R5的(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6),两棵树的示例示意图如下: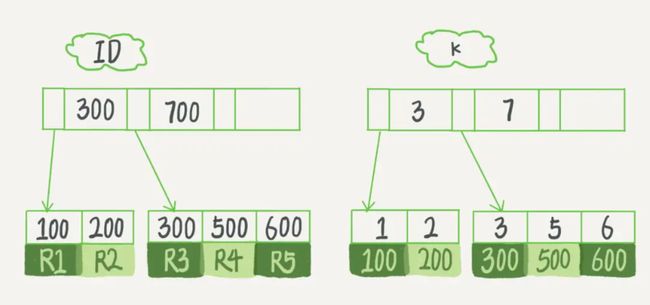
从图中不难看出,根据叶子节点的内容,索引类型分为主键索引和非主键索引。
主键索引
数据表的主键列使用的就是主键索引,且会默认创建,这也是为什么,我们还没学索引的时候,老师经常跟我们说根据主键查会快一点,原来主键本身就建好了索引。
主键索引的叶子节点存的是整行数据。在InnoDB里,主键索引也被称为聚簇索引(clustered index)。
辅助索引
辅助索引的叶子节点内容是主键的值。在InnoDB里,辅助索引也被称为二级索引(secondary index)。
如下图:
- 主键索引存放了整行数据
- 辅助索引只存放了自己本身,以及id主键用于回表查询
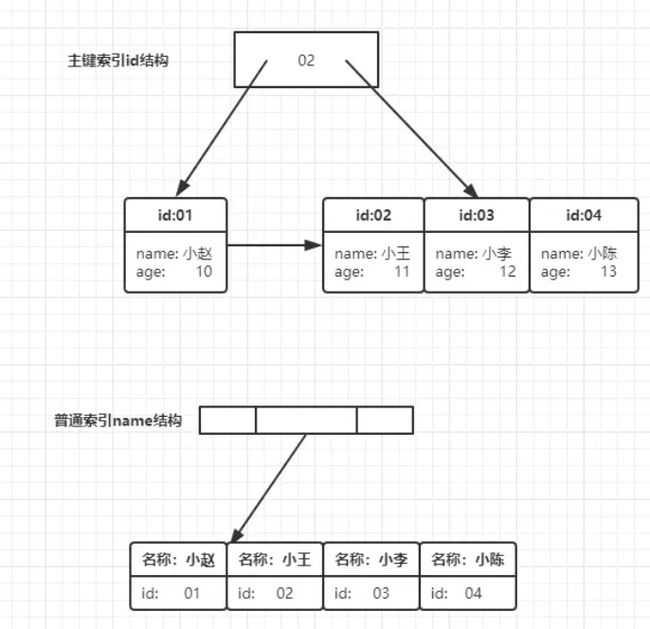
根据上面的索引结构,我们来讨论一个问题:基于主键索引和辅助索引的查询有什么区别?
- 如果语句是select * from T where ID=500,即主键查询方式,则只需要搜索ID这棵B+树;
- 如果语句是select * from T where k=5,即普通索引查询方式,则需要先搜索k索引树,得到ID的值为500,再到ID索引树搜索一次。这个过程称为回表。
也就是说,基于辅助索引的查询需要多扫描一棵索引树。因此,我们在应用中应当尽量使用主键查询。
除非说,我们所要查询的数据,刚好就是我们索引树上存在的,此时我们称之为覆盖索引--即索引列中包含了我们要查询的所有数据。
同时,二级索引又分为了如下几种(先简单略过即可,后续我们再慢慢了解):
- 唯一索引(Unique Key) :唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
- 普通索引(Index) :普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小, 因为只取前几个字符。
- 全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引
最左前缀原则
所谓最左前缀,可以想象成一个爬楼梯的过程,假设我们有一个复合索引:name,status,address,那这个楼梯由低到高依次顺序是:name,status,address,最左前缀,要求我们不能出现跳跃楼梯的情况,否则会导致我们的索引失效:
- 按楼梯从低到高,无出现跳跃的情况--此时符合最左前缀原则,索引不会失效

- 出现跳跃的情况
- 直接第一层name都不走,当然都失效
- 走了第一层,但是后续直接第三层,只有出现跳跃情况前的不会失效(此处就只有name成功)

- 同时,这个顺序并不是由我们where中的排列顺序决定,比如:
- where name='小米科技' and status='1' and address='北京市'
- where status='1' and name='小米科技' and address='北京市'
这两个尽管where中字段的顺序不一样,第二个看起来越级了,但实际上效果是一样的
其实是因为我们MySQL有一个Optimizer(查询优化器),查询优化器会将SQL进行优化,选择最优的查询计划来执行。
- 关于这个查询优化器,后续文章我们也会谈谈MySQL的逻辑架构与存储引擎
索引设计原则
针对表
- 查询频次高,且数据量多的表
针对字段
- 最好从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合。
其他原则
-
最好用唯一索引,区分度越高,使用索引的效率越高
-
不是越多越好,维护也需要时间和空间代价,建议单张表索引不超过 5 个
因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
比如:
我们创建了三个单列索引,name,status,address
当我们where中根据status和address两个字段来查询时,数据库只会选择最优的一个索引,不会所有单列索引都使用。
最优的索引:具体是指所查询表中,辨识度最高(所占比例最少)的索引列,比如此处address中有一个辨识度很高的 '西安市'数据;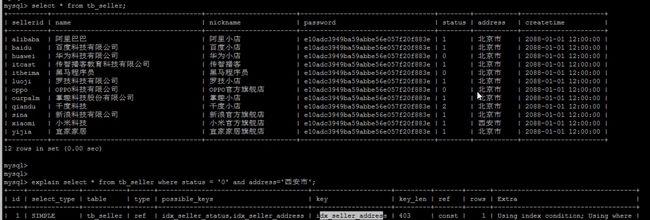
-
使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升MySQL访问索引的I/O效率。
-
利用最左前缀,比如有N个字段,我们不一定需要创建N个索引,可以用复合索引
也就是说,我们尽量创建复合索引,而不是单列索引
创建复合索引:
CREATE INDEX idx_name_email_status ON tb_seller(name,email,status);
就相当于
对name 创建索引 ;
对name , email 创建了索引 ;
对name , email, status 创建了索引 ;
⏰举个栗子
假设我们有这么一个表,id为主键,没有创建索引:
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB
如果要在此处建立复合索引,我们要遵循什么原则呢?
通过调整顺序,可以少维护一个索引
- 比如我们的业务需求里边,有如下两种查询方式:
- 根据name查询
- 根据name和age查询
如果我们建立索引(age,name),由于最左前缀原则,我们这个索引能实现的是根据age,根据age和name查询,并不能单纯根据name查询(因为跳跃了),为了实现我们的需求,我们还得再建立一个name索引;
而如果我们通过调整顺序,改成(name,age),就能实现我们的需求了,无需再维护一个name索引,这就是通过调整顺序,可以少维护一个索引。
考虑空间(短索引)
- 比如我们的业务需求里边,有以下两种查询方式:
- 根据name查询
- 根据age查询
- 根据name和age查询
我们有两种方案:
- 建立联合索引(name,age),建立单列索引:age索引。
- 建立联合索引(age,name),建立单列索引:name索引。
这两种方案都能实现我们的需求,这个时候我们就要考虑空间了,name字段是比age字段大的,显然方案1所耗费的空间是更小的,所以我们更倾向于方案1。
何时建立索引
- where中的查询字段
- 查询中与其他表关联的字段,比如外键
- 排序的字段
- 统计或分组的字段
何时达咩索引
- 表中数据量很少
- 经常改动的表
- 频繁更新的字段
- 数据重复且分布均匀的表字段(比如包含了很多重复数据,那此时多叉树的二分查找,其实用处不大,可以理解为O(logn)退化了)
索引相关语法
创建索引
默认会为主键创建索引--primary
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
查找索引
结尾加上\G,可以变成竖屏显示
select index from tbl_name\G;
删除索引
drop INDEX index_name on tbl_name ;
变更索引
1). alter table tb_name add primary key(column_list);
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
2). alter table tb_name add unique index_name(column_list);
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
3). alter table tb_name add index index_name(column_list);
添加普通索引, 索引值可以出现多次。
4). alter table tb_name add fulltext index_name(column_list);
该语句指定了索引为FULLTEXT, 用于全文索引
查看索引使用情况
show status like 'Handler_read%'; -- 查看当前会话索引使用情况
show global status like 'Handler_read%'; -- 查看全局索引使用情况
Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低越好)。
Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经常使用(这个值越高越好)。
Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。
Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY ... DESC。
Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应该建立索引来补救。
Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
下篇预告
这篇我们主要讲的都是索引的理论知识,还简单介绍了索引的语法,可以看得出索引用起来其实是不难的,关键在于如何设计和优化。
因为在很多情况下,索引其实很容易失效,我们要如何避免,以及如何正确使用索引来进行SQL优化,敬请期待下篇。
参考文献
- 掘金:https://juejin.cn/post/6844903967365791752
- 思否:https://segmentfault.com/a/1190000020416577
- MySQL45讲
- 黑马MySQL高级篇

收藏=白嫖,点赞+关注才是真爱!!!本篇文章如有不对之处,还请在评论区指出,欢迎添加我的微信一起交流:Melo__Jun
友链
-
我的一年后台练习生涯
-
聊聊Java
-
分布式开发实战
-
Redis入门与实战
-
数据结构与算法