Intro
近期在整理数据分析流程,找到了之前写的一篇代码,分享给大家。这是我上学时候做的一个项目,当时由于经验不足产生了一些问题,这些问题会在之后一点一点给大家讨论,避免各位踩坑。本篇分享会带一些讲解,可能有些地方不够清楚,欢迎留言讨论。
本次除了分享之外也是对自己之前项目的一个复盘。还是使用R语言(毕竟是我钟爱的语言)。Python的如果有需求之后会放别的项目。
本篇中包含了数据导入,清洗,可视化,特征工程,建模的代码,大家可以选择需要的去参考。
项目背景
数据来自Online Shopper’s Intention 包含12,330 条数据, 10个计数型特征和8个类别型特征。 使用‘Revenue’ 作为标签进行建模。最终目的就是根据拿到的这些数据去建立一个可以预测Revenue的模型。
前期准备
首先你要下载一个R语言以及它的舒适版本R studio。怎么下载呢,把我之前文章上的话直接粘过来哈哈
安装R以及Rstudio
如果之前有用过R的朋友请忽略这一段。
安装R非常简单,直接官网下载
之后下载Rstudio,这个相当于R语言的开挂版,界面相比于R来说非常友好,辅助功能也很多,下载地址
#注意Rstudio是基于R语言的,需要下载安装R语言后才可以安装使用。
安装好了后运行以下代码来导入package们。
setwd("~/Desktop/STAT5003/Ass") #选择项目存放的位置,同样这也是你数据csv存放的位置
# install.packages("xxx") 如果之前没有装过以下的包,先用这句话来装包,然后再去load
# the following packages are for the EDA part
library(GGally)
library(ggcorrplot)
library(psych)
library(ggstatsplot)
library(ggplot2)
library(grid)
# the following packages are for the Model part
library(MASS)
library(Boruta) # Feature selection with the Boruta algorithm
library(caret)
library(MLmetrics)
library(class)
library(neuralnet)
library(e1071)
library(randomForest)
library(keras)
导入的包有些多,keras那个的安装可以参考我之前的文章 (R语言基于Keras的MLP神经网络详解
https://www.jb51.net/article/234031.htm )
数据描述
首先啊把这个数据下载到你的电脑上,然后用以下代码导入R就可以了。
dataset <- read.csv("online_shoppers_intention.csv")
str(dataset)
str()这个function可以看到你这个数据的属性,输出如下:
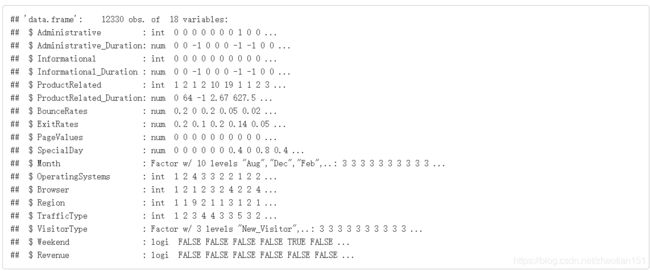
此时发现数据格式有int,number,factor等等。为了之后建分析和建模方便,我们先统一数据格式。
dataset$OperatingSystems <- as.factor(dataset$OperatingSystems) dataset$Browser <- as.factor(dataset$Browser) dataset$Region <- as.factor(dataset$Region) dataset$TrafficType <- as.factor(dataset$TrafficType) dataset$Weekend <- as.factor(dataset$Weekend) dataset$Revenue <- as.factor(dataset$Revenue) dataset$Administrative <- as.numeric(dataset$Administrative) dataset$Informational <- as.numeric(dataset$Informational) dataset$ProductRelated <- as.numeric(dataset$ProductRelated) summary(dataset)
现在数据格式基本统一啦,分为factor和numeric,这方便我们之后的操作。因为R里面的一些package(尤其是建模的package)对数据的输入格式有要求,所以提前处理好非常重要。这可以帮助你更好的整理数据以及敲出简洁舒爽的代码。
记住整理好数据格式之后summary()一下,你可以从这里发现一些数据的小问题。比如下面的这个‘Administrative_Duration ’。

你看这min=-1就离谱,(当然这也是一个小坑)我们知道duration不可能是<0的。但这是我们的主观思维,由于不知道这个数据在采集入数据库的时候是怎么定义的,所以这个-1是为啥我们不会知道原因。这也是为什么我推荐做数据分析的时候要从头开始跟项目,这样你对数据了如指掌,而不是像现在这样只凭主观思想去判断数据对错(虽然大部分时候你的主观思想没啥问题)
以下给一些数据解释,就不翻译了,看或不看都可(但你自己做项目的时候一定一定一定要仔细看)
Variables are described as follows:
Administrative : Administrative Value
Administrative_Duration : Duration in Administrative Page
Informational : Informational Value
Informational_Duration : Duration in Informational Page
ProductRelated : Product Related Value
ProductRelated_Duration : Duration in Product Related Page
BounceRates : Bounce Rates of a web page
ExitRates : Exit rate of a web page
PageValues : Page values of each web page
SpecialDay : Special days like valentine etc
Month : Month of the year
OperatingSystems : Operating system used
Browser : Browser used
Region : Region of the user
TrafficType : Traffic Type
VisitorType : Types of Visitor
Weekend : Weekend or not
Revenue : Revenue will be generated or not
数据清洗
我们在上一部分的summary已经发现了duration有小于0的,因此所有小于0的duration相关的,我们把它变成NA,然后算一下NA率,来判断这些数是给它填补上还是直接删。个人认为如果missing rate很小删了就成。但如果你的数据集本身就不大,那建议你使用填值法填进去。因为数据太少的话就没啥分析的必要。具体多少算少,见仁见智吧,感兴趣的话之后可以写一篇做讨论。
dataset$Administrative_Duration[dataset$Administrative_Duration < 0] = NA
dataset$Informational_Duration[dataset$Informational_Duration < 0] = NA
dataset$ProductRelated_Duration[dataset$ProductRelated_Duration < 0] = NA
missing.rate <- 1 - nrow(na.omit(dataset))/nrow(dataset)
paste("missing rate =", missing.rate * 100, "%")
"missing rate = 0.381184103811838 %"还挺小的,所以直接删掉有问题的数据。
dataset <- na.omit(dataset)
然后记得用summary再查一次哦,看看是否删干净了。
预分析及预处理
数值型数据
下面三种分别是箱形图,ggpairs以及相关性矩阵。 箱形图可以用来观察数据整体的分布情况。ggpairs绘制的相关关系图可以查看数据分布和相关性。相关性矩阵专注于看相关系数以及是否相关性是否significant。这几个各有其注重点,根据需要去做就可以。
par(mfrow = c(2, 5)) #让图片以2行5列的形式排列在一张图上 boxplot(dataset$Administrative, main = "Administrative") boxplot(dataset$Administrative_Duration, main = "Administrative_Duration") boxplot(dataset$Informational, main = "Informational") boxplot(dataset$Informational_Duration, main = "Informational_Duration") boxplot(dataset$ProductRelated, main = "ProductRelated") boxplot(dataset$ProductRelated_Duration, main = "ProductRelated_Duration") boxplot(dataset$BounceRates, main = "BounceRates") boxplot(dataset$ExitRates, main = "ExitRates") boxplot(dataset$PageValues, main = "PageValues") boxplot(dataset$SpecialDay, main = "SpecialDay")

ggpairs(dataset[, c(1:10)])
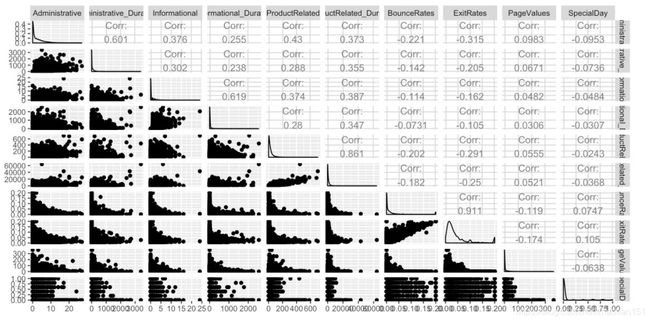
corr = cor(dataset[, c(1:10)])
p.mat <- cor_pmat(dataset[, c(1:10)], use = "complete", method = "pearson")
ggcorrplot(corr, hc.order = TRUE, type = "lower", lab = TRUE, p.mat = p.mat,
insig = "blank")

类别型数据
针对类别型数据我们主要是看他的分布,因此直接画bar plot就成。下面的代码用到了ggplot,是个非常好用的可视化包。grid.newpage()这里主要是为了让这些图片都显示在一张图上,这样把图片导出或是直接在markdown上显示的时候所有图都会显示在一个页面上面,看起来比较美观和舒适。
p1 <- ggplot(dataset, aes(x = SpecialDay)) + geom_bar(fill = "#CF6A1A", colour = "black") +
theme_bw()
p2 <- ggplot(dataset, aes(x = Month)) + geom_bar(fill = "#CF6A1A", colour = "black") +
theme_bw()
p3 <- ggplot(dataset, aes(x = OperatingSystems)) + geom_bar(fill = "#CF6A1A",
colour = "black") + theme_bw()
p4 <- ggplot(dataset, aes(x = Browser)) + geom_bar(fill = "#CF6A1A", colour = "black") +
theme_bw()
p5 <- ggplot(dataset, aes(x = Region)) + geom_bar(fill = "#CF6A1A", colour = "black") +
theme_bw()
p6 <- ggplot(dataset, aes(x = TrafficType)) + geom_bar(fill = "#CF6A1A", colour = "black") +
theme_bw()
p7 <- ggplot(dataset, aes(x = VisitorType)) + geom_bar(fill = "#CF6A1A", colour = "black") +
theme_bw()
p8 <- ggplot(dataset, aes(x = Weekend)) + geom_bar(fill = "#CF6A1A", colour = "black") +
theme_bw()
p9 <- ggplot(dataset, aes(x = Revenue)) + geom_bar(fill = "#CF6A1A", colour = "black") +
theme_bw()
grid.newpage()
pushViewport(viewport(layout = grid.layout(4, 3, heights = unit(c(1, 3, 3, 3),
"null"))))
grid.text("Bar Plot of All Categorical Feature", vp = viewport(layout.pos.row = 1,
layout.pos.col = 1:3))
vplayout = function(x, y) viewport(layout.pos.row = x, layout.pos.col = y)
print(p1, vp = vplayout(2, 1))
print(p2, vp = vplayout(2, 2))
print(p3, vp = vplayout(2, 3))
print(p4, vp = vplayout(3, 1))
print(p5, vp = vplayout(3, 2))
print(p6, vp = vplayout(3, 3))
print(p7, vp = vplayout(4, 1))
print(p8, vp = vplayout(4, 2))
print(p9, vp = vplayout(4, 3))
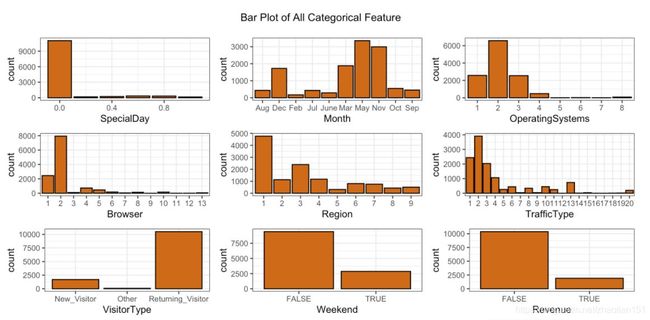
我们可以看到,数据还是比较偏。我们想要预测的revenue也是非常imbalance(标签中的false与true占比不均衡)。因此在处理数据或是选择模型的时候要注意这一点。这里不作详细讨论。针对imbalance data应该是有很多可以说的东西。之后有空的话可以细聊~
其实到目前为止,作为一个普通的项目来说,预分析可以结束了,我们查看了所有数据的分布,并且对现有的数据有了一些直观的印象。但我们不能满足于此,因此对每一个类别型变量再做一次更细致的分析。
首先看一下这个 Special Day 。原数据里给的这个special day给的是0,0.2,0.4这种数值,代表的是距离节日当天的日子,比如1就是节日当天,0.2是节日的前几天(我记得大概是这样)但这种就比较迷惑,我不知道这个具体是咋划分的(这也是为啥希望大家对你所研究的项目有非常深入的了解,你如果对此很了解,那么很多分析的步骤是可以省略的),所以只能让数据告诉我,special day应该如何存在于我们之后的模型中。
special_day_check <- dataset[, c(10, 18)]
special_day_check$Revenue <- ifelse(special_day_check$Revenue == "FALSE", 0,
1)
special_day_check$SpecialDay[special_day_check$SpecialDay == 0] = NA
special_day_check <- na.omit(special_day_check)
special_day_glm <- glm(Revenue ~ SpecialDay, data = special_day_check, family = binomial(link = "logit"))
summary(special_day_glm)
##
## Call:
## glm(formula = Revenue ~ SpecialDay, family = binomial(link = "logit"),
## data = special_day_check)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -0.3961 -0.3756 -0.3560 -0.3374 2.4491
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.3954 0.2986 -8.021 1.05e-15 ***
## SpecialDay -0.5524 0.4764 -1.159 0.246
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 578.11 on 1247 degrees of freedom
## Residual deviance: 576.77 on 1246 degrees of freedom
## AIC: 580.77
##
## Number of Fisher Scoring iterations: 5
首先,我们要检查的是special day 是否应该是一个数值变量。因此,建立一个glm模型(revenue = a+b*special_day),发现special day的p值=0.246(>0.05),因此可以数值型的认为“SpecialDay”不对revenue有显著的影响,因此specialday可以被当作类别型变量。
现在我们把它当作类别型变量分析一下。用ggbarstats这个function。ggstatsplot是ggplot2包的扩展,主要用于创建美观的图片同时自动输出统计学分析结果,其统计学分析结果包含统计分析的详细信息,该包对于经常需要做统计分析的科研工作者来说非常有用。
ggbarstats(data = dataset, main = Revenue, condition = SpecialDay, sampling.plan = "jointMulti",
title = "Revenue by Special Days", xlab = "Special Days", perc.k = 0.5,
x.axis.orientation = "slant", ggstatsplot.layer = FALSE, messages = FALSE)

用此函数可以绘制出呈现分类变量的柱状图,图中的上半部分( x P e a r s o n 2 x^2_{Pearson} xPearson2, p p p , V C r a m e r V_{Cramer} VCramer 等)代表传统的统计学方法(Frequentist)的一些统计值,下面的部分( l o g e ( B F 01 ) log_e(BF_{01}) loge(BF01)等)代表贝叶斯(Bayesian)的一些统计值。
在本项目中,我们主要关注p-value,我们发现,p<0.001并且在柱状图上方所有都是***,这代表了非常显著。因此我们可以确定special day就这样作为类别型变量使用。
之后把每一个类别型变量都这样做一下。过程不赘述了,挑一个有代表性的给大家看一下。
我们看一下operating systems的ggbarstats()。
ggbarstats(data = dataset, main = Revenue, condition = OperatingSystems, sampling.plan = "jointMulti",
title = "Revenue by Different Operating Systems", xlab = "Operating Systems",
perc.k = 0.5, x.axis.orientation = "slant", ggstatsplot.layer = FALSE, messages = FALSE)

我们发现整体的p<0.001但是,因为在子类别的样本少,所以柱状图上面出现了ns。我们知道,如果数据很少,那么该数据便不具有统计价值,因此我们把这些少样本的子类别合并在一起,再看一次。
dataset$OperatingSystems <- as.integer(dataset$OperatingSystems)
dataset$OperatingSystems[dataset$OperatingSystems == "5"] <- "other"
dataset$OperatingSystems[dataset$OperatingSystems == "6"] <- "other"
dataset$OperatingSystems[dataset$OperatingSystems == "7"] <- "other"
dataset$OperatingSystems <- as.factor(dataset$OperatingSystems)
ggbarstats(data = dataset, main = Revenue, condition = OperatingSystems, sampling.plan = "jointMulti",
title = "Revenue by Different Operating Systems", xlab = "Operating Systems",
perc.k = 0.5, x.axis.orientation = "slant", ggstatsplot.layer = FALSE, messages = FALSE)
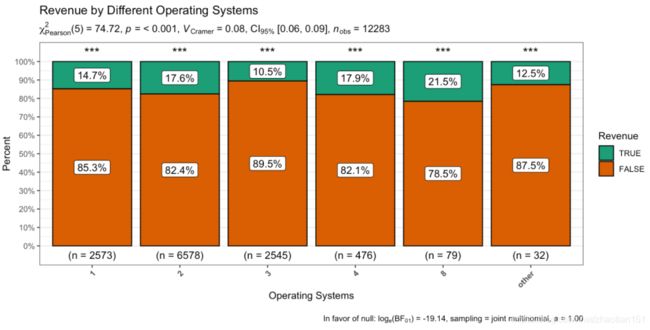
现在看起来就比较舒适了,都很显著。
预处理和预分析到此结束。
特征
我们进行特征工程的最终目的就是提升模型的性能,比如你的数据特征很少的话我们需要建立一些二阶、三阶特征来丰富我们的数据。或是特征太多的时候我们需要进行降维处理。这里我没有做太多的特征工程,只是把特征进行了一下基本的筛选,把没有用的特征删掉。这里的逻辑是先用pca看一下可以保留多少特征,再用Boruta算法和stepAIC去选一下。
# PCA Since pca can only use on numeric data, so we use the os[,c(1:9)] pcdata <- os[, c(1:9)] pclable <- ifelse(os$Revenue == "TRUE", "red", "blue") pc <- princomp(os[, c(1:9)], cor = TRUE, scores = TRUE) summary(pc) ## Importance of components: ## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 ## Standard deviation 1.8387377 1.2923744 1.0134790 1.0020214 0.9697619 ## Proportion of Variance 0.3756618 0.1855813 0.1141266 0.1115608 0.1044931 ## Cumulative Proportion 0.3756618 0.5612431 0.6753697 0.7869305 0.8914236 ## Comp.6 Comp.7 Comp.8 Comp.9 ## Standard deviation 0.65008195 0.59319914 0.3510795 0.281849096 ## Proportion of Variance 0.04695628 0.03909836 0.0136952 0.008826546 ## Cumulative Proportion 0.93837989 0.97747825 0.9911735 1.000000000 plot(pc, type = "lines")

从pca里面我们可以发现,保留7个numeric变量就可以有95%以上的方差。因此之后我们可以按着至少7个numeric variable这个标准去保留。
Boruta算法
set.seed(123) boruta.train <- Boruta(Revenue ~ ., data = os, doTrace = 2, maxRuns = 15) print(boruta.train) # Boruta performed 14 iterations in 3.920271 mins. 13 attributes confirmed # important: Administrative, Administrative_Duration, BounceRates, Browser, # ExitRates and 8 more; 1 attributes confirmed unimportant: SpecialDay; 2 # tentative attributes left: OperatingSystems, Weekend; so SpecialDay can be # delete when we fit the model. OperatingSystems and Weekend need to check # by other ways.
StepAIC
full.model <- glm(Revenue ~ . - SpecialDay, data = os, family = binomial(link = "logit")) # Backward Stepwise AIC stepback <- stepAIC(full.model, direction = "backward", steps = 3) summary(stepback) # OperatingSystems, Weekend are all above the, combine the previous # result by Boruta algorithm, it can be delete when we fit model. Browser # has the minimum AIC, it can be delete when we fit model. PCA shows we # should keep 7 numeric variables in the dataset when fit the model, so two # numeric variables should be remove. Informational_Duration and # Administrative has the minimum AIC in numeric variables, so remove these # two variables.
综合上面三个特征选择的方法 SpecialDay, OperatingSystems, Weekend, Browser, Informational_Duration 和 Administrative 应当在建模的时候被移除。有兴趣的可以跑一下上面的代码,由于运行时间有点长,结果就直接码在代码框里了。
建模
现在把用来建模数据整理好,准备建模。
os_modeldata <- os[, -c(1, 4, 10, 11, 12, 16)] # summary(os_modeldata) write.csv(os_modeldata, "os_modeldata.csv")
首先划分训练集和测试集(train 和 test)
set.seed(123)
os_modeldata <- read.csv("os_modeldata.csv")
os_modeldata <- os_modeldata[, -1]
os_modeldata$Revenue <- as.factor(os_modeldata$Revenue)
inTrain <- createDataPartition(os_modeldata$Revenue, p = 0.9)[[1]]
Train <- os_modeldata[inTrain, ]
Test <- os_modeldata[-inTrain, ]
然后把训练集拆成train和val。这里加了个10-cv。有些模型的function可以自己加cv,但由于要用到不同的建模package,为了避免不同package之间划分cv的差异,咱自己建~
add_cv_cohorts <- function(dat, cv_K) {
if (nrow(dat)%%cv_K == 0) {
# if perfectly divisible
dat$cv_cohort <- sample(rep(1:cv_K, each = (nrow(dat)%/%cv_K)))
} else {
# if not perfectly divisible
dat$cv_cohort <- sample(c(rep(1:(nrow(dat)%%cv_K), each = (nrow(dat)%/%cv_K +
1)), rep((nrow(dat)%%cv_K + 1):cv_K, each = (nrow(dat)%/%cv_K))))
}
return(dat)
}
# add 10-fold CV labels to real estate data
train_cv <- add_cv_cohorts(Train, 10)
# str(train_cv)
首先建一个基准模型,Logistic regression classifer(benchmark model)
train_cv_glm <- train_cv
glm.acc <- glm.f1 <- c()
train_cv_glm$Revenue <- ifelse(train_cv_glm$Revenue == "TRUE", 1, 0)
# str(train_cv_glm)
for (i in 1:10) {
# Segement my data by fold using the which() function
indexes <- which(train_cv_glm$cv_cohort == i)
train <- train_cv_glm[-indexes, ]
val <- train_cv_glm[indexes, ]
# Model
glm.model <- glm(Revenue ~ . - cv_cohort, data = train, family = binomial(link = "logit"))
# predict
glm.pred <- predict(glm.model, newdata = val, type = "response")
glm.pred <- ifelse(glm.pred > 0.5, 1, 0)
# evaluate
glm.f1[i] <- F1_Score(val$Revenue, glm.pred, positive = "1")
glm.acc[i] <- sum(glm.pred == val$Revenue)/nrow(val)
}
# F1 and ACC
glm.acc.train <- round(mean(glm.acc), 5) * 100
glm.f1.train <- round(mean(glm.f1), 5) * 100
# print(glm.cm <- table(glm.pred, val$Revenue))
paste("The accuracy by Logistic regression classifier by 10-fold CV in train data is",
glm.acc.train, "%")
paste("The F1-score by Logistic regression classifier by 10-fold CV in train data is",
glm.f1.train, "%")
# f1 = 0.50331
然后建立我们用来对比的机器学习模型。这里使用网格搜索法调参。
KNN
# since knn() function can't use factor as indenpent variable So re-coding
# data, factor to dummy variable)
train_cv_knn <- as.data.frame(model.matrix(~., train_cv[, -11]))
train_cv_knn$Revenue <- train_cv$Revenue
train_cv_knn <- train_cv_knn[, -1]
# head(train_cv_knn)
knn.grid <- expand.grid(k = c(1:30))
knn.grid$acc <- knn.grid$f1 <- NA
knn.f1 <- knn.acc <- c()
for (k in 1:nrow(knn.grid)) {
for (i in 1:10) {
# Segement my data by fold using the which() function
indexes <- which(train_cv_knn$cv_cohort == i)
train <- train_cv_knn[-indexes, ]
val <- train_cv_knn[indexes, ]
# model and predict
knn.pred <- knn(train[, -c(34, 35)], val[, -c(34, 35)], train$Revenue,
k = k)
# evaluate
knn.f1[i] <- F1_Score(val$Revenue, knn.pred, positive = "TRUE")
knn.acc[i] <- sum(knn.pred == val$Revenue)/nrow(val)
}
knn.grid$f1[k] <- mean(knn.f1)
knn.grid$acc[k] <- mean(knn.acc)
print(paste("finished with =", k))
}
print(knn.cm <- table(knn.pred, val$Revenue))
knn.grid[which.max(knn.grid$f1), ]
# k = 7, f1=0.5484112, acc=0.885042
SVM
svm.grid <- expand.grid(cost = c(0.1, 1, 10), gamma = seq(0.2, 1, 0.2))
svm.grid$acc <- svm.grid$f1 <- NA
svm.f1 <- svm.acc <- c()
for (k in 1:nrow(svm.grid)) {
for (i in 1:10) {
# Segement my data by fold using the which() function
indexes <- which(train_cv$cv_cohort == i)
train <- train_cv[-indexes, ]
val <- train_cv[indexes, ]
# model
svm.model <- svm(Revenue ~ ., kernel = "radial", type = "C-classification",
gamma = svm.grid$gamma[k], cost = svm.grid$cost[k], data = train[,
-12])
svm.pred <- predict(svm.model, val[, -12])
# evaluate
svm.f1[i] <- F1_Score(val$Revenue, svm.pred, positive = "TRUE")
svm.acc[i] <- sum(svm.pred == val$Revenue)/nrow(val)
}
svm.grid$f1[k] <- mean(svm.f1)
svm.grid$acc[k] <- mean(svm.acc)
print(paste("finished with:", k))
}
print(svm.cm <- table(svm.pred, val$Revenue))
svm.grid[which.max(svm.grid$f1), ]
# cost=1, gamma=0.2,f1= 0.5900601,acc= 0.8948096
Random Forest
rf.grid <- expand.grid(nt = seq(100, 500, by = 100), mrty = c(1, 3, 5, 7, 10))
rf.grid$acc <- rf.grid$f1 <- NA
rf.f1 <- rf.acc <- c()
for (k in 1:nrow(rf.grid)) {
for (i in 1:10) {
# Segement my data by fold using the which() function
indexes <- which(train_cv$cv_cohort == i)
train <- train_cv[-indexes, ]
val <- train_cv[indexes, ]
# model
rf.model <- randomForest(Revenue ~ ., data = train[, -12], n.trees = rf.grid$nt[k],
mtry = rf.grid$mrty[k])
rf.pred <- predict(rf.model, val[, -12])
# evaluate
rf.f1[i] <- F1_Score(val$Revenue, rf.pred, positive = "TRUE")
rf.acc[i] <- sum(rf.pred == val$Revenue)/nrow(val)
}
rf.grid$f1[k] <- mean(rf.f1)
rf.grid$acc[k] <- mean(rf.acc)
print(paste("finished with:", k))
}
print(rf.cm <- table(rf.pred, val$Revenue))
rf.grid[which.max(rf.grid$f1), ]
# nt=200,mtry=3 ,f1 = 0.6330392, acc=0.8960723
Neural Network
nndata <- Train
nndata$Revenue <- ifelse(nndata$Revenue == "TRUE", 1, 0)
train_x <- model.matrix(~., nndata[, -11])
train_x <- train_x[, -1]
train_y <- to_categorical(as.integer(as.matrix(array(nndata[, 11]))), 2)
model <- keras_model_sequential()
# defining model's layers
model %>% layer_dense(units = 30, input_shape = 33, activation = "relu") %>%
layer_dense(units = 40, activation = "relu") %>% layer_dropout(rate = 0.4) %>%
layer_dense(units = 60, activation = "relu") %>% layer_dropout(rate = 0.4) %>%
layer_dense(units = 30, activation = "relu") %>% layer_dropout(rate = 0.4) %>%
layer_dense(units = 2, activation = "sigmoid")
# defining model's optimizer
model %>% compile(loss = "binary_crossentropy", optimizer = "adam", metrics = c("accuracy"))
# Metrics: The performance evaluation module provides a series of functions
# for model performance evaluation. We use it to determine when the NN
# should stop train. The ultimate measure of performance is F1.
# Check which column in train_y is FALSE
table(train_y[, 1]) # the first column is FALSE
table(train_y[, 1])[[2]]/table(train_y[, 1])[[1]]
# Define a dictionary with your labels and their associated weights
weight = list(5.5, 1) # the proportion of FALSE and TURE is about 5.5:1
# fitting the model on the training dataset
model %>% fit(train_x, train_y, epochs = 50, validation_split = 0.2, batch_size = 512,
class_weight = weight)
# after epoch = 20, val_loss not descrease and val_acc not increase, so NN
# should stop at epoch = 20
模型对比
GLM
glmdata <- Train
glmdata$Revenue <- ifelse(glmdata$Revenue == "TRUE", 1, 0)
testglm <- Test
testglm$Revenue <- ifelse(testglm$Revenue == "TRUE", 1, 0)
glm.model.f <- glm(Revenue ~ ., data = glmdata, family = binomial(link = "logit"))
glm.pred.f <- predict(glm.model.f, newdata = Test, type = "response")
glm.pred.f <- ifelse(glm.pred.f > 0.5, 1, 0)
glm.f1.f <- F1_Score(testglm$Revenue, glm.pred.f, positive = "1")
paste("The F1-score by Logistic regression classifier in test data is", glm.f1.f)
KNN
knndata <- as.data.frame(model.matrix(~., Train[, -11]))
knndata <- knndata[, -1]
knntest <- as.data.frame(model.matrix(~., Test[, -11]))
knntest <- knntest[, -1]
knn.model.f.pred <- knn(knndata, knntest, Train$Revenue, k = 7)
knn.f1.f <- F1_Score(Test$Revenue, knn.model.f.pred, positive = "TRUE")
paste("The F1-score by KNN classifier in test data is", knn.f1.f)
SVM
svm.model.f <- svm(Revenue ~ ., kernel = "radial", type = "C-classification",
gamma = 0.2, cost = 1, data = Train)
svm.pred.f <- predict(svm.model.f, Test)
svm.f1.f <- F1_Score(Test$Revenue, svm.pred.f, positive = "TRUE")
paste("The F1-score by SVM classifier in test data is", svm.f1.f)
Random Forests
rf.model.f <- randomForest(Revenue ~ ., data = Train, n.trees = 200, mtry = 3)
rf.pred.f <- predict(rf.model.f, Test)
rf.f1.f <- F1_Score(Test$Revenue, rf.pred.f, positive = "TRUE")
paste("The F1-score by Random Forests classifier in test data is", rf.f1.f)
NN
nndata <- Train
nndata$Revenue <- ifelse(nndata$Revenue == "TRUE", 1, 0)
train_x <- model.matrix(~., nndata[, -11])
train_x <- train_x[, -1]
train_y <- to_categorical(as.integer(as.matrix(array(nndata[, 11]))), 2)
model <- keras_model_sequential()
# defining model's layers
model %>% layer_dense(units = 30, input_shape = 33, activation = "relu") %>%
layer_dense(units = 40, activation = "relu") %>% layer_dropout(rate = 0.4) %>%
layer_dense(units = 60, activation = "relu") %>% layer_dropout(rate = 0.4) %>%
layer_dense(units = 30, activation = "relu") %>% layer_dropout(rate = 0.4) %>%
layer_dense(units = 2, activation = "sigmoid")
# defining model's optimizer
model %>% compile(loss = "binary_crossentropy", optimizer = "adam", metrics = c("accuracy"))
weight = list(5.5, 1)
model %>% fit(train_x, train_y, epochs = 20, batch_size = 512, class_weight = weight)
# test data
testnn <- Test
testnn$Revenue <- ifelse(testnn$Revenue == "TRUE", 1, 0)
test_x <- model.matrix(~., testnn[, -11])
test_x <- test_x[, -1]
nn.pred <- model %>% predict(test_x)
nn.pred <- as.data.frame(nn.pred)
nn.pred$label <- NA
nn.pred$label <- ifelse(nn.pred$V2 > nn.pred$V1, "TRUE", "FALSE")
nn.pred$label <- as.factor(nn.pred$label)
nn.f1 <- F1_Score(Test$Revenue, nn.pred$label, positive = "TRUE")
paste("The F1-score by Neural network in test data is", nn.f1)

看一下结果对比哈,RF和NN的表现较好。最后做个混淆矩阵看一下。
# RF print(rf.cm.f <- table(rf.pred.f, Test$Revenue)) ## ## rf.pred.f FALSE TRUE ## FALSE 987 74 ## TRUE 50 116 # NN print(nn.cm.f <- table(nn.pred$label, Test$Revenue)) ## ## FALSE TRUE ## FALSE 980 69 ## TRUE 57 121
到此这篇关于R语言数据建模流程分析的文章就介绍到这了,更多相关R语言数据建模内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!