【Python笔记】pyspark.sql库
文章目录
- 1 pyspark.sql.SQLContext
-
- 1.1 applySchema(rdd, schema)、inferSchema(rdd, samplingRatio=None)
- 1.2 cacheTable(tableName)
- 1.3 clearCache()
- 1.4 createDataFrame(data, schema=None, samplingRatio=None)
- 1.5 createExternalTable(tableName, path=None, source=None, schema=None, **options)
- 1.6 dropTempTable(tableName)
- 1.7 getConf(key, defaultValue)
- 1.8 jsonFile(path, schema=None, samplingRatio=1.0)
- 1.9 jsonRDD(rdd, schema=None, samplingRatio=1.0)
- 1.10 load(path=None, source=None, schema=None, **options)
- 1.11 newSession()
- 1.12 parquetFile(*paths)
- 1.13 range(start, end=None, step=1, numPartitions=None)
- 1.14 read
- 1.15 registerDataFrameAsTable(df, tableName)
- 1.16 registerFunction(name, f, returnType=StringType)
- 1.17 setConf(key, value)
- 1.18 sql(sqlQuery)
- 1.19 table(tableName)
- 1.20 tableNames(dbName=None)
- 1.21 tables(dbName=None)
- 1.22 udf
- 1.23 uncacheTable(tableName)
- 2 pyspark.sql.HiveContext
- 3 pyspark.sql.DataFrame
-
- 3.1 agg(*exprs)
- 3.2 alias(alias)
- 3.3 cache()
- 3.4 coalesce(numPartitions)
- 3.5 collect()
- 3.6 columns
- 3.7 corr(col1, col2, method=None)
- 3.8 count()
- 3.9 cov(col1, col2)
- 3.10 crosstab(col1, col2)
- 3.11 cube(*cols)
- 3.12 describe(*cols)
- 3.13 distinct()
- 3.14 drop(col)
- 3.15 dropDuplicates(subset=None)
- 3.16 drop_duplicates(subset=None)
- 3.17 dropna(how='any', thresh=None, subset=None)
- 3.18 dtypes
- 3.19 explain(extended=False)
- 3.20 fillna(value, subset=None)
- 3.21 filter(condition)
- 3.22 first()
- 3.23 flatMap(f)
- 3.24 foreach(f)
- 3.25 foreachPartition(f)
- 3.26 freqItems(cols, support=None)
- 3.27 groupBy(*cols)
- 3.28 groupby(*cols)
- 3.29 head(n=None)
- 3.30 insertInto(tableName, overwrite=False)
- 3.31 intersect(other)
- 3.32 intersect(other)
- 3.33 join(other, on=None, how=None)
- 3.34 limit(num)
- 3.35 map(f)
- 3.36 mapPartitions(f, preservesPartitioning=False)
- 3.37 na
- 3.38 orderBy(*cols, **kwargs)
- 3.39 persist(storageLevel=StorageLevel(False, True, False, False, 1))
- 3.40 printSchema()
- 3.41 randomSplit(weights, seed=None)
- 3.42 rdd
- 3.43 registerAsTable(name)
- 3.44 registerTempTable(name)
- 3.45 repartition(numPartitions, *cols)
- 3.46 replace(to_replace, value, subset=None)
- 3.47 rollup(*cols)
- 3.48 sample(withReplacement, fraction, seed=None)
- 3.49 sampleBy(col, fractions, seed=None)
- 3.50 save(path=None, source=None, mode='error', **options)
- 3.51 saveAsParquetFile(path)
- 3.52 saveAsTable(tableName, source=None, mode='error', **options)
- 3.53 schema
- 3.54 select(*cols)
- 3.55 selectExpr(*expr)
- 3.56 show(n=20, truncate=True)
- 3.57 sort(*cols, **kwargs)
- 3.58 sortWithinPartitions(*cols, **kwargs)
- 3.59 stat
- 3.60 subtract(other)
- 3.61 take(num)
- 3.62 toDF(*cols)
- 3.63 toJSON(use_unicode=True)
- 3.64 toPandas()
- 3.65 unionAll(other)
- 3.66 unpersist(blocking=True)
- 3.67 where(condition)
- 3.68 withColumn(colName, col)
- 3.69 withColumnRenamed(existing, new)
- 3.70 write
- 4 pyspark.sql.GroupedData
-
- 4.1 agg(*exprs)
- 4.2 avg(*args)
- 4.3 count()
- 4.4 max(*args)
- 4.5 mean(*args)
- 4.6 min(*args)
- 4.7 pivot(pivot_col, values=None)
- 4.8 sum(*args)
- 5 pyspark.sql.Column
-
- 5.1 alias(*alias)
- 5.2 asc()
- 5.3 astype(dataType)
- 5.4 between(lowerBound, upperBound)
- 5.5 bitwiseAND(other)
- 5.6 bitwiseOR(other)
- 5.7 bitwiseXOR(other)
- 5.8 cast(dataType)
- 5.9 desc()
- 5.10 endswith(other)
- 5.11 getField(name)
- 5.12 getItem(key)
- 5.13 inSet(*cols)
- 5.14 isNotNull()
- 5.15 isNull()
- 5.16 isin(*cols)
- 5.17 like(other)
- 5.18 otherwise(value)
- 5.19 over(window)
- 5.20 rlike(other)
- 5.21 startswith(other)
- 5.22 substr(startPos, length)
- 5.23 when(condition, value)
- 6 class pyspark.sql.Row
-
- 6.1 asDict(recursive=False)
- 7 pyspark.sql.DataFrameNaFunctions
-
- 7.1 drop(how='any', thresh=None, subset=None)
- 7.2 fill(value, subset=None)
- 7.3 replace(to_replace, value, subset=None)
- 8 pyspark.sql.DataFrameStatFunctions
-
- 8.1 corr(col1, col2, method=None)
- 8.2 cov(col1, col2)
- 8.3 crosstab(col1, col2)
- 8.4 freqItems(cols, support=None)
- 9 pyspark.sql.Window
-
- 9.1 orderBy(*cols)
- 9.2 partitionBy(*cols)
- 10 pyspark.sql.WindowSpec
-
- 10.1 orderBy(*cols)
- 10.2 partitionBy(*cols)
- 10.3 rangeBetween(start, end)
- 10.4 rowsBetween(start, end)
- 11 pyspark.sql.DataFrameReader
-
- 11.1 format(source)
- 11.2 jdbc
- 11.3 json(path, schema=None)
- 11.4 load(path=None, format=None, schema=None, **options)
- 11.5 option(key, value)
- 11.6 options(**options)
- 11.7 orc(path)
- 11.8 parquet(*paths)
- 11.9 schema(schema)
- 11.10 table(tableName)
- 11.11 text(paths)
- 12 pyspark.sql.DataFrameWriter
-
- 12.1 format(source)
- 12.2 insertInto(tableName, overwrite=False)
- 12.3 jdbc(url, table, mode=None, properties=None)
- 12.4 json(path, mode=None)
- 12.5 mode(saveMode)
- 12.6 option(key, value)
- 12.7 options(**options)
- 12.8 orc(path, mode=None, partitionBy=None)
- 12.9 parquet(path, mode=None, partitionBy=None)
- 12.10 partitionBy(*cols)
- 12.11 save(path=None, format=None, mode=None, partitionBy=None, **options)
- 12.12 saveAsTable(name, format=None, mode=None, partitionBy=None, **options)
- 12.13 text(path)
- 13 pyspark.sql.types
- 14 pyspark.sql.functions
pyspark.sql 模块 —— Context
Spark SQL和DataFrames重要的类有:
- pyspark.sql.SQLContext DataFrame和SQL方法的主入口
- pyspark.sql.HiveContext 访问Hive数据的主入口
- pyspark.sql.DataFrame 将分布式数据集分组到指定列名的数据框中
- pyspark.sql.Column DataFrame中的列
- pyspark.sql.Row DataFrame数据的行
- pyspark.sql.GroupedData 由DataFrame.groupBy()创建的聚合方法集
- pyspark.sql.DataFrameNaFunctions 处理丢失数据(空数据)的方法
- pyspark.sql.DataFrameStatFunctions 统计功能的方法
pyspark.sql.functionsDataFrame可用的内置函数pyspark.sql.types可用的数据类型列表- pyspark.sql.Window 用于处理窗口函数
1 pyspark.sql.SQLContext
class pyspark.sql.SQLContext(sparkContext, sqlContext=None)
SQLContext可以用来创建DataFrame、注册DataFrame为表、在表上执行SQL、缓存表、读取parquet文件。
参数:
- sparkContext - 支持sqlcontext的sparkcontext
- sqlContext - 一个可选的JVM Scala sqlcontext,若设置,我们不需要在JVM实例化一个新的sqlcontext,而是都调用这个对象。
1.1 applySchema(rdd, schema)、inferSchema(rdd, samplingRatio=None)
注:已过时,使用createDataFrame()代替
1.2 cacheTable(tableName)
缓存表到内存中
1.3 clearCache()
从内存缓存删除所有缓存表。
sparkSession怎么缓存df和释放缓存?
如果在循环里不释放会导致缓存越来越大,这不太好哦,所以我们使用完就释放吧!
# 缓存方法
df.cache()
# 释放缓存的方法
df.unpersist()
# sparkSession对象
# spark = SparkSession.builder.appName(session).enableHiveSupport().getOrCreate()
# 检查是否成功缓存的方法:建立一个临时视图
>>> df2.createTempView('temp_df2')
>>> spark.catalog.isCached('temp_df2') # 检查下内存里没有,因为还没缓存
False
>>> df2.cache() # 缓存下
DataFrame[account_id: bigint, region: string]
>>> spark.catalog.isCached('temp_df2') # 检查下内存里确实有
True
>>> df.unpersist()# 释放缓存
DataFrame[account_id: bigint, region: string]
>>> spark.catalog.isCached('temp_df2') # 真的释放了
False
1.4 createDataFrame(data, schema=None, samplingRatio=None)
从元组/列表RDD或列表或pandas.DataFrame创建DataFrame
当模式是列名的列表时,每个列的类型会从数据中推断出来。
当模式没有时,将尝试从数据中推断模式(列名和类型),数据应该是行或命名元组或字典的RDD。
如果模式推理是必要的,samplingRatio用来确定用于模式推理的行比率。如果没有samplingratio,将使用第一行。
参数:
- data - 行或元组或列表或字典的RDD、list、pandas.DataFrame.
- schema – 一个结构化类型或者列名列表,默认是空
- samplingRatio – 用于推断的行的样本比率
返回: DataFrame
>>> l=[('Alice',1)]
>>> sqlContext.createDataFrame(l).collect()
[Row(_1=u'Alice', _2=1)]
>>> sqlContext.createDataFrame(l,['name','age']).collect()
[Row(name=u'Alice', age=1)]
>>> d=[{'name':'Alice','age':1}]
>>> sqlContext.createDataFrame(d).collect()
[Row(age=1, name=u'Alice')]
>>> rdd=sc.parallelize(l)
>>> rdd=sparkContext.parallelize.parallelize(l)
>>> sqlContext.createDataFrame(rdd).collect()
[Row(_1=u'Alice', _2=1)]
>>> df=sqlContext.createDataFrame(rdd,['name','age'])
>>> df.collect()
[Row(name=u'Alice', age=1)]
>>> sqlContext.createDataFrame(df.toPandas()).collect()
[Row(name=u'Alice', age=1)]
>>> sqlContext.createDataFrame(pandas.DataFrame([[1, 2]])).collect()
[Row(0=1, 1=2)]
1.5 createExternalTable(tableName, path=None, source=None, schema=None, **options)
创建基于数据源中的数据的外部表.
返回与外部表关联的DataFrame
数据源由源和一组选项指定。如果未指定源,那么将使用由spark.sql.sources.default 配置的默认的数据源配置。
通常,一个模式可以被提供作为返回的DataFrame的模式,然后创建外部表。
返回: DataFrame
1.6 dropTempTable(tableName)
从目录中删除临时表
>>> sqlContext.registerDataFrameAsTable(df, "table1")
>>> sqlContext.dropTempTable("table1")
1.7 getConf(key, defaultValue)
返回指定键的Spark SQL配置属性值。
如果键没有指定返回默认值。
1.8 jsonFile(path, schema=None, samplingRatio=1.0)
从一个文本文件中加载数据,这个文件的每一行均为JSON字符串。
注:在1.4中已过时,使用DataFrameReader.json()代替。
1.9 jsonRDD(rdd, schema=None, samplingRatio=1.0)
从一个已经存在的RDD中加载数据,这个RDD中的每一个元素均为一个JSON字符串。
如果提供了模式,将给定的模式应用到这个JSON数据集。否则,它根据数据集的采样比例来确定模式
>>> json=sc.parallelize(["""{"name":"jack","addr":{"city":"beijing","mail":"10001"}}""","""{"name":"john","addr":{"city":"shanghai","mail":"10002"}}"""])
>>> df1 = sqlContext.jsonRDD(json)
>>> df1.collect()
[Row(addr=Row(city=u'beijing', mail=u'10001'), name=u'jack'), Row(addr=Row(city=u'shanghai', mail=u'10002'), name=u'john')]
>>> df2 = sqlContext.jsonRDD(json,df1.schema)
>>> df2.collect()
[Row(addr=Row(city=u'beijing', mail=u'10001'), name=u'jack'), Row(addr=Row(city=u'shanghai', mail=u'10002'), name=u'john')]
1.10 load(path=None, source=None, schema=None, **options)
返回数据源中的数据集为DataFrame.
注:在1.4中已过时,使用DataFrameReader.load()代替。
1.11 newSession()
返回一个新的SQLContext做为一个新的会话,这个会话有单独的SQLConf,注册临时表和UDFs,但共享sparkcontext和缓存表。
1.12 parquetFile(*paths)
加载Parquet文件,返回结果为DataFrame
注:在1.4中已过时,使用DataFrameReader.parquet()代替。
1.13 range(start, end=None, step=1, numPartitions=None)
创建只有一个名为id的长类型的列的DataFrame,包含从开始到结束的按照一定步长的独立元素。
参数:
- start - 开始值
- end - 结束值
- step - 增量值(默认:1)
- numPartitions – DataFrame分区数
返回: DataFrame
>>> sqlContext.range(1, 7, 2).collect()
[Row(id=1), Row(id=3), Row(id=5)]
如果仅有一个参数,那么这个参数被作为结束值。
>>> sqlContext.range(3).collect()
[Row(id=0), Row(id=1), Row(id=2)]
1.14 read
返回一个DataFrameReader,可用于读取数据为DataFrame。
1.15 registerDataFrameAsTable(df, tableName)
注册给定的DataFrame作为目录中的临时表。
临时表只在当前SQLContext实例有效期间存在。
>>> sqlContext.registerDataFrameAsTable(df, "table1")
1.16 registerFunction(name, f, returnType=StringType)
注册python方法(包括lambda方法),作为UDF,这样可以在 SQL statements中使用。
除了名称和函数本身之外,还可以选择性地指定返回类型。当返回类型没有指定时,默认自动转换为字符串。对于任何其他返回类型,所生成的对象必须与指定的类型匹配。
参数:
- name - UDF名称
- f – python方法
- 返回类型 数据类型对象
>>> sqlContext.registerFunction("stringLengthString", lambda x: len(x))
>>> sqlContext.sql("SELECT stringLengthString('test')").collect()
[Row(_c0=u'4')]
>>> from pyspark.sql.types import IntegerType
>>> sqlContext.registerFunction("stringLengthInt", lambda x: len(x), IntegerType())
>>> sqlContext.sql("SELECT stringLengthInt('test')").collect()
[Row(_c0=4)]
>>> from pyspark.sql.types import IntegerType
>>> sqlContext.udf.register("stringLengthInt", lambda x: len(x), IntegerType())
>>> sqlContext.sql("SELECT stringLengthInt('test')").collect()
[Row(_c0=4)]
1.17 setConf(key, value)
设置给定的Spark SQL配置属性
1.18 sql(sqlQuery)
返回DataFrame代表给定查询的结果
参数:
- sqlQuery - sql语句
返回: DataFrame
>>> l=[(1,'row1'),(2,'row2'),(3,'row3')]
>>> df = sqlContext.createDataFrame(l,['field1','field2'])
>>> sqlContext.registerDataFrameAsTable(df, "table1")
>>> df2 = sqlContext.sql("SELECT field1 AS f1, field2 as f2 from table1")
>>> df2.collect()
[Row(f1=1, f2=u'row1'), Row(f1=2, f2=u'row2'), Row(f1=3, f2=u'row3')]
1.19 table(tableName)
返回指定的表为DataFrame
返回: DataFrame
>>> l=[(1,'row1'),(2,'row2'),(3,'row3')]
>>> df = sqlContext.createDataFrame(l,['field1','field2'])
>>> sqlContext.registerDataFrameAsTable(df, "table1")
>>> df2 = sqlContext.table("table1")
>>> sorted(df.collect()) == sorted(df2.collect())
True
1.20 tableNames(dbName=None)
返回数据库的表名称列表
参数:dbName – 字符串类型的数据库名称.默认为当前的数据库。
返回: 字符串类型的表名称列表
>>> l=[(1,'row1'),(2,'row2'),(3,'row3')]
>>> df = sqlContext.createDataFrame(l,['field1','field2'])
>>> sqlContext.registerDataFrameAsTable(df, "table1")
>>> "table1" in sqlContext.tableNames()
True
>>> "table1" in sqlContext.tableNames("db")
True
1.21 tables(dbName=None)
返回一个包含表名称的DataFrame从给定的数据库。
如果数据库名没有指定,将使用当前的数据库。
返回的DataFrame包含两列: 表名称和是否临时表 (一个Bool类型的列,标识表是否为临时表)。
参数:dbName – 字符串类型的使用的数据库名
返回: DataFrame
>>> l=[(1,'row1'),(2,'row2'),(3,'row3')]
>>> df = sqlContext.createDataFrame(l,['field1','field2'])
>>> sqlContext.registerDataFrameAsTable(df, "table1")
>>> df2 = sqlContext.tables()
>>> df2.filter("tableName = 'table1'").first()
Row(tableName=u'table1', isTemporary=True)
1.22 udf
返回一个注册的UDF为UDFRegistration。
返回: UDFRegistration
1.23 uncacheTable(tableName)
从内存的缓存表中移除指定的表。
2 pyspark.sql.HiveContext
省略
class pyspark.sql.HiveContext(sparkContext, hiveContext=None)
3 pyspark.sql.DataFrame
class pyspark.sql.DataFrame(jdf, sql_ctx)
分布式的收集数据分组到命名列中。
一个DataFrame相当于在Spark SQL中一个相关的表,可在SQLContext使用各种方法创建,如:
people = sqlContext.read.parquet("...")
一旦创建, 可以使用在DataFrame、Column中定义的不同的DSL方法操作。
从data frame中返回一列使用对应的方法:
ageCol = people.age
一个更具体的例子:
# To create DataFrame using SQLContext
people = sqlContext.read.parquet("...")
department = sqlContext.read.parquet("...")
people.filter(people.age > 30).join(department, people.deptId == department.id)).groupBy(department.name, "gender").agg({"salary": "avg", "age": "max"})
3.1 agg(*exprs)
没有组的情况下聚集整个DataFrame (df.groupBy.agg()的简写)。
>>> l=[('jack',5),('john',4),('tom',2)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.agg({"age": "max"}).collect()
[Row(max(age)=5)]
>>> from pyspark.sql import functions as F
>>> df.agg(F.min(df.age)).collect()
[Row(min(age)=2)]
3.2 alias(alias)
返回一个设置别名的新的DataFrame。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> from pyspark.sql.functions import * # 这里面有col()
>>> df_as1 = df.alias("df_as1")
>>> df_as2 = df.alias("df_as2")
>>> joined_df = df_as1.join(df_as2, col("df_as1.name") == col("df_as2.name"), 'inner')
>>> joined_df.select(col("df_as1.name"), col("df_as2.name"), col("df_as2.age")).collect()
[Row(name=u'Alice', name=u'Alice', age=2), Row(name=u'Bob', name=u'Bob', age=5)]
3.3 cache()
用默认的存储级别缓存数据(MEMORY_ONLY_SER).
Spark Cache的几点思考
3.4 coalesce(numPartitions)
返回一个有确切的分区数的分区的新的DataFrame。
与在一个RDD上定义的合并类似, 这个操作产生一个窄依赖。 如果从1000个分区到100个分区,不会有shuffle过程, 而是每100个新分区会需要当前分区的10个。
>>> df.coalesce(1).rdd.getNumPartitions()
1
3.5 collect()
返回所有的记录数为行的列表。
>>> df.collect()
[Row(age=2, name=u'Alice'), Row(age=5, name=u'Bob')]
3.6 columns
返回所有列名的列表。
>>> df.columns
['age', 'name']
3.7 corr(col1, col2, method=None)
计算一个DataFrame相关的两列为double值。通常只支持皮尔森相关系数。DataFrame.corr()和DataFrameStatFunctions.corr()类似。
参数:
- col1 – 第一列的名称
- col2 – 第二列的名称
- method – 相关方法.当前只支持皮尔森相关系数
3.8 count()
返回DataFrame的行数。
>>> df.count()
2
3.9 cov(col1, col2)
计算由列名指定列的样本协方差为double值。DataFrame.cov()和DataFrameStatFunctions.cov()类似。
参数:
- col1 – 第一列的名称
- col2 – 第二列的名称
3.10 crosstab(col1, col2)
计算给定列的分组频数表,也称为相关表。每一列的去重值的个数应该小于1e4.最多返回1e6个非零对.每一行的第一列会是col1的去重值,列名称是col2的去重值。第一列的名称是KaTeX parse error: Expected group after '_' at position 5: col1_̲col2. 没有出现的配对将以零作为计数。DataFrame.crosstab() and DataFrameStatFunctions.crosstab()类似。
参数:
- col1 – 第一列的名称. 去重项作为每行的第一项
- col2 – 第二列的名称. 去重项作为DataFrame的列名称
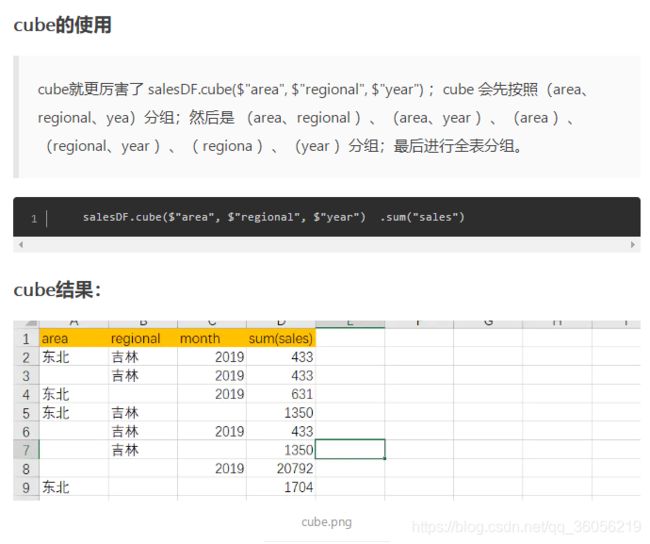
3.11 cube(*cols)
创建使用指定列的当前DataFrame的多维立方体,这样可以聚合这些数据。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.cube('name', df.age).count().show()
+-----+----+-----+
| name| age|count|
+-----+----+-----+
| null| 2| 1|
|Alice|null| 1|
| Bob| 5| 1|
| Bob|null| 1|
| null| 5| 1|
| null|null| 2|
|Alice| 2| 1|
+-----+----+-----+
3.12 describe(*cols)
计算数值列的统计信息。
包括计数,平均,标准差,最小和最大。如果没有指定任何列,这个函数计算统计所有数值列。
>>> df.describe().show()
+-------+------------------+
|summary| age|
+-------+------------------+
| count| 2|
| mean| 3.5|
| stddev|2.1213203435596424|
| min| 2|
| max| 5|
+-------+------------------+
>>> df.describe(['age', 'name']).show()
+-------+------------------+-----+
|summary| age| name|
+-------+------------------+-----+
| count| 2| 2|
| mean| 3.5| null|
| stddev|2.1213203435596424| null|
| min| 2|Alice|
| max| 5| Bob|
+-------+------------------+-----+
3.13 distinct()
返回行去重的新的DataFrame。
>>> l=[('Alice',2),('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.distinct().count()
2
3.14 drop(col)
返回删除指定列的新的DataFrame。
参数: col – 要删除列的字符串类型名称,或者要删除的列。
>>> df.drop('age').collect()
[Row(name=u'Alice'), Row(name=u'Bob')]
>>> df.drop(df.age).collect()
[Row(name=u'Alice'), Row(name=u'Bob')]
>>> l1=[('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> l2=[('Bob',85)]
>>> df2 = sqlContext.createDataFrame(l2,['name','height'])
>>> df.join(df2, df.name == df2.name, 'inner').drop(df.name).collect()
[Row(age=5, height=85, name=u'Bob')]
>>> df.join(df2, df.name == df2.name, 'inner').drop(df2.name).collect()
[Row(age=5, name=u'Bob', height=85)]
3.15 dropDuplicates(subset=None)
返回去掉重复行的一个新的DataFrame,通常只考虑某几列。
drop_duplicates()和dropDuplicates()类似。
>>> from pyspark.sql import Row
>>> df = sc.parallelize([Row(name='Alice', age=5, height=80),Row(name='Alice', age=5, height=80),Row(name='Alice', age=10, height=80)]).toDF()
>>> df.dropDuplicates().show()
+---+------+-----+
|age|height| name|
+---+------+-----+
| 5| 80|Alice|
| 10| 80|Alice|
+---+------+-----+
>>> df.dropDuplicates(['name', 'height']).show()
+---+------+-----+
|age|height| name|
+---+------+-----+
| 5| 80|Alice|
+---+------+-----+
3.16 drop_duplicates(subset=None)
与以上相同。
3.17 dropna(how=‘any’, thresh=None, subset=None)
返回一个删除null值行的新的DataFrame。dropna()和dataframenafunctions.drop()类似。
参数:
- how – ‘any’或者’all’。如果’any’,删除包含任何空值的行。如果’all’,删除所有值为null的行
- thresh – int,默认为None,如果指定这个值,删除小于阈值的非空值的行。这个会重写’how’参数
- subset – 选择的列名称列表
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> dfnew = df.cube('name', df.age).count()
>>> dfnew.show()
+-----+----+-----+
| name| age|count|
+-----+----+-----+
| null| 2| 1|
|Alice|null| 1|
| Bob| 5| 1|
| Bob|null| 1|
| null| 5| 1|
| null|null| 2|
|Alice| 2| 1|
+-----+----+-----+
>>> dfnew.na.drop().show()
+-----+---+-----+
| name|age|count|
+-----+---+-----+
| Bob| 5| 1|
|Alice| 2| 1|
+-----+---+-----+
3.18 dtypes
返回所有列名及类型的列表。
>>> df.dtypes
[('age', 'int'), ('name', 'string')]
3.19 explain(extended=False)
将(逻辑和物理)计划打印到控制台以进行调试。
参数: extended – boolean类型,默认为False。如果为False,只打印物理计划
>>> df.explain()
== Physical Plan ==
Scan ExistingRDD[age#0,name#1]
>>> df.explain(True)
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
...
== Physical Plan ==
...
3.20 fillna(value, subset=None)
替换空值,和na.fill()类似,DataFrame.fillna()和dataframenafunctions.fill()类似。
参数:
- value - 要代替空值的值有int,long,float,string或dict.如果值是字典,subset参数将被忽略。值必须是要替换的列的映射,替换值必须是int,long,float或者string.
- subset - 要替换的列名列表。在subset指定的列,没有对应数据类型的会被忽略。例如,如果值是字符串,subset包含一个非字符串的列,这个非字符串的值会被忽略
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> dfnew = df.cube('name', df.age).count()
>>> dfnew.show()
+-----+----+-----+
| name| age|count|
+-----+----+-----+
| null| 2| 1|
|Alice|null| 1|
| Bob| 5| 1|
| Bob|null| 1|
| null| 5| 1|
| null|null| 2|
|Alice| 2| 1|
+-----+----+-----+
>>> dfnew.na.fill(50).show()
+-----+---+-----+
| name|age|count|
+-----+---+-----+
| null| 2| 1|
|Alice| 50| 1|
| Bob| 5| 1|
| Bob| 50| 1|
| null| 5| 1|
| null| 50| 2|
|Alice| 2| 1|
+-----+---+-----+
>>> dfnew.na.fill({'age': 50, 'name': 'unknown'}).show()
+-------+---+-----+
| name|age|count|
+-------+---+-----+
|unknown| 2| 1|
| Alice| 50| 1|
| Bob| 5| 1|
| Bob| 50| 1|
|unknown| 5| 1|
|unknown| 50| 2|
| Alice| 2| 1|
+-------+---+-----+
3.21 filter(condition)
用给定的条件过滤行。
where()和filter()类似。
参数: 条件 - 一个列的bool类型或字符串的SQL表达式。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.filter(df.age > 3).collect()
[Row(age=5, name=u'Bob')]
>>> df.where(df.age == 2).collect()
[Row(age=2, name=u'Alice')]
>>> df.filter("age > 3").collect()
[Row(age=5, name=u'Bob')]
>>> df.where("age = 2").collect()
[Row(age=2, name=u'Alice')]
3.22 first()
返回第一行。
>>> df.first()
Row(age=2, name=u'Alice')
3.23 flatMap(f)
返回在每行应用F函数后的新的RDD,然后将结果压扁。
是df.rdd.flatMap()的简写。
>>> df.flatMap(lambda p: p.name).collect()
[u'A', u'l', u'i', u'c', u'e', u'B', u'o', u'b']
3.24 foreach(f)
应用f函数到DataFrame的所有行。
是df.rdd.foreach()的简写。
>>> def f(person):
... print(person.name)
>>> df.foreach(f)
Alice
Bob
3.25 foreachPartition(f)
应用f函数到DataFrame的每一个分区。
是 df.rdd.foreachPartition()的缩写。
>>> def f(people):
... for person in people:
... print(person.name)
>>> df.foreachPartition(f)
Alice
Bob
3.26 freqItems(cols, support=None)
参数:
- cols – 要计算重复项的列名,为字符串类型的列表或者元祖
- support – 要计算频率项的频率值。默认是1%。参数必须大于1e-4.
3.27 groupBy(*cols)
使用指定的列分组DataFrame,这样可以聚合计算。可以从GroupedData查看所有可用的聚合方法。
groupby()和groupBy()类似。
参数:cols – 分组依据的列。每一项应该是一个字符串的列名或者列的表达式。
>>> df.groupBy().avg().collect()
[Row(avg(age)=3.5)]
>>> df.groupBy('name').agg({'age': 'mean'}).collect()
[Row(name=u'Alice', avg(age)=2.0), Row(name=u'Bob', avg(age)=5.0)]
>>> df.groupBy(df.name).avg().collect()
[Row(name=u'Alice', avg(age)=2.0), Row(name=u'Bob', avg(age)=5.0)]
>>> df.groupBy(['name', df.age]).count().collect()
[Row(name=u'Bob', age=5, count=1), Row(name=u'Alice', age=2, count=1)]
3.28 groupby(*cols)
和以上一致
3.29 head(n=None)
返回前n行
参数: n – int类型,默认为1,要返回的行数。
返回值: 如果n大于1,返回行列表,如果n为1,返回单独的一行。
>>> df.head()
Row(age=2, name=u'Alice')
>>> df.head(1)
[Row(age=2, name=u'Alice')]
3.30 insertInto(tableName, overwrite=False)
插入DataFrame内容到指定表。
注:在1.4中已过时,使用DataFrameWriter.insertInto()代替。
3.31 intersect(other)
返回新的DataFrame,包含仅同时在当前框和另一个框的行。
相当于SQL中的交集。
3.32 intersect(other)
如果collect()和take()方法可以运行在本地(不需要Spark executors)那么返回True
3.33 join(other, on=None, how=None)
使用给定的关联表达式,关联另一个DataFrame。
以下执行df1和df2之间完整的外连接。
参数:
- other – 连接的右侧
- on – 一个连接的列名称字符串, 列名称列表,一个连接表达式(列)或者列的列表。如果on参数是一个字符串或者字符串列表,表示连接列的名称,这些名称必须同时存在join的两个表中, 这样执行的是一个等价连接。
- how – 字符串,默认’inner’。inner,outer,left_outer,right_outer,left_semi之一
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> l2=[('Tom',80),('Bob',85)]
>>> df2 = sqlContext.createDataFrame(l2,['name','height'])
>>> df.join(df2, df.name == df2.name, 'outer').select(df.name, df2.height).collect()
[Row(name=None, height=80), Row(name=u'Alice', height=None), Row(name=u'Bob', height=85)]
>>> df.join(df2, 'name', 'outer').select('name', 'height').collect()
[Row(name=u'Tom', height=80), Row(name=u'Alice', height=None), Row(name=u'Bob', height=85)]
>>> l3=[('Alice',2,60),('Bob',5,80)]
>>> df3 = sqlContext.createDataFrame(l3,['name','age','height'])
>>> cond = [df.name == df3.name, df.age == df3.age]
>>> df.join(df3, cond, 'outer').select(df.name, df3.age).collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
>>> df.join(df2, 'name').select(df.name, df2.height).collect()
[Row(name=u'Bob', height=85)]
>>> l4=[('Alice',1),('Bob',5)]
>>> df4 = sqlContext.createDataFrame(l4,['name','age'])
>>> df.join(df4, ['name', 'age']).select(df.name, df.age).collect()
[Row(name=u'Bob', age=5)]
3.34 limit(num)
将结果计数限制为指定的数字。
>>> df.limit(1).collect()
[Row(age=2, name=u'Alice')]
>>> df.limit(0).collect()
[]
3.35 map(f)
通过每行应用f函数返回新的RDD。
是 df.rdd.map()的缩写。
>>> df.map(lambda p: p.name).collect()
[u'Alice', u'Bob']
3.36 mapPartitions(f, preservesPartitioning=False)
通过每个分区应用f函数返回新的RDD
是df.rdd.mapPartitions()的缩写。
>>> rdd = sc.parallelize([1, 2, 3, 4], 4)
>>> def f(iterator): yield 1
...
>>> rdd.mapPartitions(f).sum()
4
3.37 na
返回DataFrameNaFunctions用于处理缺失值。
3.38 orderBy(*cols, **kwargs)
返回按照指定列排序的新的DataFrame。
参数:
- cols – 用来排序的列或列名称的列表
- ascending – 布尔值或布尔值列表(默认 True). 升序排序与降序排序。指定多个排序顺序的列表。如果指定列表, 列表的长度必须等于列的长度。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.sort(df.age.desc()).collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
>>> df.sort("age", ascending=False).collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
>>> df.orderBy(df.age.desc()).collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
>>> from pyspark.sql.functions import *
>>> df.sort(asc("age")).collect()
[Row(name=u'Alice', age=2), Row(name=u'Bob', age=5)]
>>> df.orderBy(desc("age"), "name").collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
>>> df.orderBy(["age", "name"], ascending=[0, 1]).collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
3.39 persist(storageLevel=StorageLevel(False, True, False, False, 1))
设置存储级别以在第一次操作运行完成后保存其值。这只能用来分配新的存储级别,如果RDD没有设置存储级别的话。如果没有指定存储级别,默认为(memory_only_ser)。
3.40 printSchema()
打印schema以树的格式
>>> df.printSchema()
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
3.41 randomSplit(weights, seed=None)
按照提供的权重随机的划分DataFrame。
参数:
- weights – doubles类型的列表做为权重来划分DataFrame。权重会被恢复如果总值不到1.0, weights: 是一个数组根据weight(权重值)将一个RDD划分成多个RDD,权重越高划分得到的元素较多的几率就越大。数组的长度即为划分成RDD的数量
- seed – random的随机数。
>>> l4=[('Alice',1),('Bob',5),('Jack',8),('Tom',10)]
>>> df4 = sqlContext.createDataFrame(l4,['name','age'])
>>> splits = df4.randomSplit([1.0, 2.0],24)
>>> splits[0].count()
1
>>> splits[1].count()
3
3.42 rdd
返回内容为行的RDD。
3.43 registerAsTable(name)
注:在1.4中已过时,使用registerTempTable()代替。
3.44 registerTempTable(name)
使用给定的名字注册该RDD为临时表
这个临时表的有效期与用来创建这个DataFrame的SQLContext相关
>>> df.registerTempTable("people")
>>> df2 = sqlContext.sql("select * from people")
>>> sorted(df.collect()) == sorted(df2.collect())
True
3.45 repartition(numPartitions, *cols)
按照给定的分区表达式分区,返回新的DataFrame。产生的DataFrame是哈希分区。
numPartitions参数可以是一个整数来指定分区数,或者是一个列。如果是一个列,这个列会作为第一个分区列。如果没有指定,将使用默认的分区数。
1.6版本修改: 添加可选参数可以指定分区列。如果分区列指定的话,numPartitions也是可选的。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.repartition(10).rdd.getNumPartitions()
10
>>> data = df.unionAll(df).repartition("age")
>>> data.show()
+-----+---+
| name|age|
+-----+---+
|Alice| 2|
|Alice| 2|
| Bob| 5|
| Bob| 5|
+-----+---+
>>> data = data.repartition(7, "age")
>>> data.show()
+-----+---+
| name|age|
+-----+---+
| Bob| 5|
| Bob| 5|
|Alice| 2|
|Alice| 2|
+-----+---+
>>> data.rdd.getNumPartitions()
7
>>> data = data.repartition("name", "age")
>>> data.show()
+-----+---+
| name|age|
+-----+---+
| Bob| 5|
| Bob| 5|
|Alice| 2|
|Alice| 2|
+-----+---+
3.46 replace(to_replace, value, subset=None)
返回用另外一个值替换了一个值的新的DataFrame。DataFrame.replace() 和 DataFrameNaFunctions.replace() 类似。
参数:
- to_replace –整形,长整形,浮点型,字符串,或者列表。要替换的值。如果值是字典,那么值会被忽略,to_replace必须是一个从列名(字符串)到要替换的值的映射。要替换的值必须是一个整形,长整形,浮点型,或者字符串
- value – 整形,长整形,浮点型,字符串或者列表。要替换为的值。要替换为的值必须是一个整形,长整形,浮点型,或者字符串。如果值是列表或者元组,值应该和to_replace有相同的长度。
- subset – 要考虑替换的列名的可选列表。在subset指定的列如果没有匹配的数据类型那么将被忽略。例如,如果值是字符串,并且subset参数包含一个非字符串的列,那么非字符串的列被忽略。
>>> l4=[('Alice',10,80),('Bob',5,None),('Tom',None,None),(None,None,None)]
>>> df4 = sqlContext.createDataFrame(l4,['name','age','height'])
>>> df4.na.replace(10, 20).show()
+-----+----+------+
| name| age|height|
+-----+----+------+
|Alice| 20| 80|
| Bob| 5| null|
| Tom|null| null|
| null|null| null|
+-----+----+------+
>>> df4.na.replace(['Alice', 'Bob'], ['A', 'B'], 'name').show()
+----+----+------+
|name| age|height|
+----+----+------+
| A| 10| 80|
| B| 5| null|
| Tom|null| null|
|null|null| null|
+----+----+------+
3.47 rollup(*cols)
使用指定的列为当前的DataFrame创建一个多维汇总, 这样可以聚合这些数据。
>>> l=[('Alice',2,80),('Bob',5,None)]
>>> df = sqlContext.createDataFrame(l,['name','age','height'])
>>> df.rollup('name', df.age).count().show()
+-----+----+-----+
| name| age|count|
+-----+----+-----+
|Alice|null| 1|
| Bob| 5| 1|
| Bob|null| 1|
| null|null| 2|
|Alice| 2| 1|
+-----+----+-----+
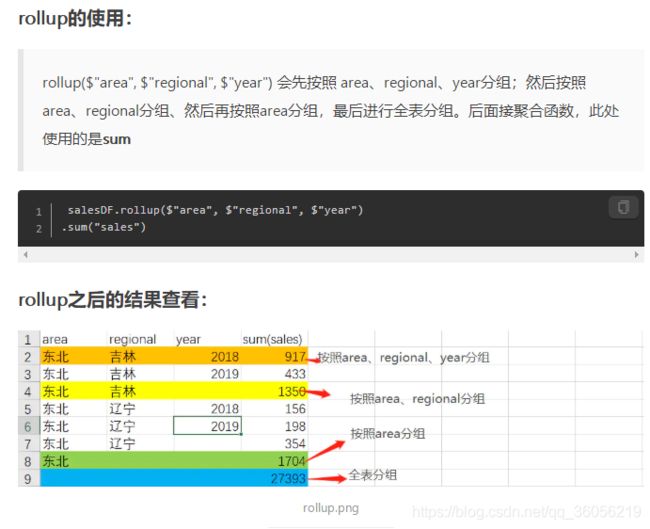
Spark DataFrame中rollup和cube使用
3.48 sample(withReplacement, fraction, seed=None)
返回DataFrame的子集采样。
参数:
- withReplacement:元素可以多次抽样(在抽样时替换)
- fraction:期望样本的大小作为RDD大小的一部分
当withReplacement=false时:选择每个元素的概率,介于[0,1] ;
当withReplacement=true时:选择每个元素的期望次数; 必须>=0
(1)元素不可以多次抽样:withReplacement=false,每个元素被抽取到的概率为0.5:fraction=0.5
(2)元素可以多次抽样:withReplacement=true,每个元素被抽取到的期望次数为2:fraction=2 - seed:随机数生成器的种子
>>> df.sample(False, 0.5, 42).count()
2
3.49 sampleBy(col, fractions, seed=None)
根据每个层次上给出的分数,返回没有替换的分层样本。
返回没有替换的分层抽样 基于每层给定的一小部分 在给定的每层的片段
参数:
- col – 定义层的列
- fractions – 每层的抽样数。如果没有指定层, 将其数目视为0.
- seed – 随机数
返回值: 返回代表分层样本的新的DataFrame
>>> from pyspark.sql.functions import col
>>> dataset = sqlContext.range(0, 100).select((col("id") % 3).alias("key"))
>>> sampled = dataset.sampleBy("key", fractions={0: 0.1, 1: 0.2}, seed=0)
>>> sampled.groupBy("key").count().orderBy("key").show()
+---+-----+
|key|count|
+---+-----+
| 0| 5|
| 1| 9|
+---+-----+
3.50 save(path=None, source=None, mode=‘error’, **options)
保存DataFrame的数据到数据源。
注:在1.4中已过时,使用DataFrameWriter.save()代替。
3.51 saveAsParquetFile(path)
保存内容为一个Parquet文件,代表这个schema。
注:在1.4中已过时,使用DataFrameWriter.parquet() 代替。
3.52 saveAsTable(tableName, source=None, mode=‘error’, **options)
将此DataFrame的内容作为表保存到数据源。
注:在1.4中已过时,使用DataFrameWriter.saveAsTable() 代替。
3.53 schema
返回DataFrame的schema为types.StructType。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.schema
StructType(List(StructField(name,StringType,true),StructField(age,LongType,true)))
3.54 select(*cols)
提供一组表达式并返回一个新的DataFrame。
参数:cols – 列名(字符串)或表达式(列)列表。 如果其中一列的名称为“*”,那么该列将被扩展为包括当前DataFrame中的所有列。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.select('*').collect()
[Row(name=u'Alice', age=2), Row(name=u'Bob', age=5)]
>>> df.select('name', 'age').collect()
[Row(name=u'Alice', age=2), Row(name=u'Bob', age=5)]
>>> df.select(df.name, (df.age + 10).alias('age')).collect()
[Row(name=u'Alice', age=12), Row(name=u'Bob', age=15)]
3.55 selectExpr(*expr)
投射一组SQL表达式并返回一个新的DataFrame。
这是接受SQL表达式的select()的变体。
>>> df.selectExpr("age * 2", "abs(age)").collect()
[Row((age * 2)=4, abs(age)=2), Row((age * 2)=10, abs(age)=5)]
3.56 show(n=20, truncate=True)
将前n行打印到控制台。
参数:
- n – 要显示的行数
- truncate – 是否截断长字符串并对齐单元格
>>> df
DataFrame[name: string, age: bigint]
>>> df.show()
+-----+---+
| name|age|
+-----+---+
|Alice| 2|
| Bob| 5|
+-----+---+
3.57 sort(*cols, **kwargs)
返回按指定列排序的新DataFrame。
参数:
- cols – 要排序的列或列名称列表
- ascending – 布尔值或布尔值列表(默认为True)。 排序升序降序。 指定多个排序顺序的列表。 如果指定了列表,列表的长度必须等于列的长度
>>> df.sort(df.age.desc()).collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
>>> df.sort("age", ascending=False).collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
>>> df.orderBy(df.age.desc()).collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
>>> from pyspark.sql.functions import *
>>> df.sort(asc("age")).collect()
[Row(name=u'Alice', age=2), Row(name=u'Bob', age=5)]
>>> df.orderBy(desc("age"), "name").collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
>>> df.orderBy(["age", "name"], ascending=[0, 1]).collect()
[Row(name=u'Bob', age=5), Row(name=u'Alice', age=2)]
3.58 sortWithinPartitions(*cols, **kwargs)
返回一个新的DataFrame,每个分区按照指定的列排序
参数:
- cols – 要排序的列或列名称列表
- ascending – 布尔值或布尔值列表(默认为True)。 排序升序降序。 指定多个排序顺序的列表。 如果指定了列表,列表的长度必须等于列的长度
>>> df.sortWithinPartitions("age", ascending=False).show()
+-----+---+
| name|age|
+-----+---+
|Alice| 2|
| Bob| 5|
+-----+---+
3.59 stat
返回统计功能的DataFrameStatFunctions。
3.60 subtract(other)
返回一个新的DataFrame,这个DataFrame中包含的行不在另一个DataFrame中。
这相当于SQL中的EXCEPT。
3.61 take(num)
返回前num行的行列表
>>> df.take(2)
[Row(name=u'Alice', age=2), Row(name=u'Bob', age=5)]
3.62 toDF(*cols)
返回一个新类:具有新的指定列名称的DataFrame。
参数: cols – 新列名列表(字符串)。
>>> df.toDF('f1', 'f2').collect()
[Row(f1=u'Alice', f2=2), Row(f1=u'Bob', f2=5)]
3.63 toJSON(use_unicode=True)
将DataFrame转换为字符串的RDD。
每行都将转换为JSON格式作为返回的RDD中的一个元素。
>>> df.toJSON().first()
u'{"name":"Alice","age":2}'
3.64 toPandas()
将此DataFrame的内容返回为Pandas pandas.DataFrame。
这只有在pandas安装和可用的情况下才可用。
>>> df.toPandas()
age name
0 2 Alice
1 5 Bob
3.65 unionAll(other)
返回包含在这个frame和另一个frame的行的联合的新DataFrame。
这相当于SQL中的UNION ALL。
3.66 unpersist(blocking=True)
将DataFrame标记为非持久性,并从内存和磁盘中删除所有的块。
3.67 where(condition)
使用给定表达式过滤行。
where()是filter()的别名。
参数:condition – 一个布尔类型的列或一个SQL表达式的字符串。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.filter(df.age > 3).collect()
[Row(name=u'Bob', age=5)]
>>> df.where(df.age == 2).collect()
[Row(name=u'Alice', age=2)]
>>> df.filter("age > 3").collect()
[Row(name=u'Bob', age=5)]
>>> df.where("age = 2").collect()
[Row(name=u'Alice', age=2)]
3.68 withColumn(colName, col)
通过添加列或替换具有相同名称的现有列来返回新的DataFrame。
参数:
- colName – 字符串,新列的名称
- col – 新列的列表达式
>>> df.withColumn('age2', df.age + 2).collect()
[Row(name=u'Alice', age=2, age2=4), Row(name=u'Bob', age=5, age2=7)]
3.69 withColumnRenamed(existing, new)
通过重命名现有列来返回新的DataFrame。
参数:● existing – 字符串,要重命名的现有列的名称
● col – 字符串,列的新名称
>>> df.withColumnRenamed('age', 'age2').collect()
[Row(name=u'Alice', age2=2), Row(name=u'Bob', age2=5)]
3.70 write
用于将DataFrame的内容保存到外部存储的接口。
返回:DataFrameWriter
4 pyspark.sql.GroupedData
class pyspark.sql.GroupedData(jdf, sql_ctx)
由DataFrame.groupBy()创建的DataFrame上的一组聚合方法
4.1 agg(*exprs)
计算聚合并将结果作为DataFrame返回。
可用的集合函数是avg,max,min,sum,count。
如果exprs是从字符串到字符串的单个字典映射,那么键是要执行聚合的列,值是聚合函数。
另外,exprs也可以是聚合列表达式的列表。
参数:● exprs – 从列名(字符串)到聚集函数(字符串)的字典映射或列的列表。
>>> gdf = df.groupBy(df.name)
>>> gdf.agg({"*": "count"}).collect()
[Row(name=u'Alice', count(1)=1), Row(name=u'Bob', count(1)=1)]
>>> from pyspark.sql import functions as F
>>> gdf.agg(F.min(df.age)).collect()
[Row(name=u'Alice', min(age)=2), Row(name=u'Bob', min(age)=5)]
4.2 avg(*args)
计算每个组的每个数字列的平均值。
mean()是avg()的别名。
参数:cols – 列名称列表(字符串),非数字列被忽略。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.groupBy().avg('age').collect()
[Row(avg(age)=3.5)]
>>> l3=[('Alice',2,85),('Bob',5,80)]
>>> df3 = sqlContext.createDataFrame(l3,['name','age','height'])
>>> df3.groupBy().avg('age', 'height').collect()
[Row(avg(age)=3.5, avg(height)=82.5)]
4.3 count()
统计每个组的记录数。
>>> df.groupBy(df.age).count().collect()
[Row(age=2, count=1), Row(age=5, count=1)]
4.4 max(*args)
计算每个组的每个数字列的最大值。
>>> df.groupBy().max('age').collect()
[Row(max(age)=5)]
>>> df3.groupBy().max('age', 'height').collect()
[Row(max(age)=5, max(height)=85)]
4.5 mean(*args)
计算每个组的每个数字列的平均值。
mean()是avg()的别名。
参数:● cols – 列名称列表(字符串),非数字列被忽略。
>>> df.groupBy().mean('age').collect()
[Row(avg(age)=3.5)]
>>> df3.groupBy().mean('age', 'height').collect()
[Row(avg(age)=3.5, avg(height)=82.5)]
4.6 min(*args)
计算每个组的每个数字列的最小值。
参数:● cols – 列名称列表(字符串),非数字列被忽略。
>>> df.groupBy().min('age').collect()
[Row(min(age)=2)]
>>> df3.groupBy().min('age', 'height').collect()
[Row(min(age)=2, min(height)=80)]
4.7 pivot(pivot_col, values=None)
旋转当前[[DataFrame]]的列并执行指定的聚合。 有两个版本的透视函数:一个需要调用者指定不同值的列表以进行透视,另一个不需要。 后者更简洁但效率更低,因为Spark需要首先在内部计算不同值的列表。
参数:
- pivot_col – 要旋转的列的名称
- values – 将被转换为输出DataFrame中的列的值的列表。
// 计算每个课程每年的收入总和作为一个单独的列
>>> l4=[(2012,'dotNET',10000),(2012,'dotNET',5000),(2012,'Java',20000),(2013,'dotNET',48000),(2013,'Java',30000)]
>>> df4 = sqlContext.createDataFrame(l4,['year','course','earnings'])
>>> df4.groupBy("year").pivot("course", ["dotNET", "Java"]).sum("earnings").collect()
[Row(year=2012, dotNET=15000, Java=20000), Row(year=2013, dotNET=48000, Java=30000)]
// 或者不指定列值(效率较低)
>>> df4.groupBy("year").pivot("course").sum("earnings").collect()
[Row(year=2012, Java=20000, dotNET=15000), Row(year=2013, Java=30000, dotNET=48000)]
4.8 sum(*args)
计算每个组的每个数字列的总和。
参数:● cols – 列名称列表(字符串),非数字列被忽略。
>>> df.groupBy().sum('age').collect()
[Row(sum(age)=7)]
>>> df3.groupBy().sum('age', 'height').collect()
[Row(sum(age)=7, sum(height)=165)]
5 pyspark.sql.Column
class pyspark.sql.Column(jc)
DataFrame中的一列。
列实例可以通过以下方式创建:
# 1. Select a column out of a DataFrame
df.colName
df["colName"]
# 2. Create from an expression
df.colName + 1
1 / df.colName
5.1 alias(*alias)
使用新名称返回此列的别名(在返回多个列的表达式情况下如explode)。
>>> df.select(df.age.alias("age2")).collect()
[Row(age2=2), Row(age2=5)]
5.2 asc()
基于给定列名称的升序返回一个排序表达式。
5.3 astype(dataType)
将列转换为dataType类型。
>>> df.select(df.age.astype("string").alias('ages')).collect()
[Row(ages=u'2'), Row(ages=u'5')]
>>> from pyspark.sql.types import StringType
>>> df.select(df.age.astype(StringType()).alias('ages')).collect()
[Row(ages=u'2'), Row(ages=u'5')]
5.4 between(lowerBound, upperBound)
一个布尔表达式,如果此表达式的值位于给定列之间,则该表达式的值为true。
>>> df.select(df.name, df.age.between(2, 4)).show()
+-----+--------------------------+
| name|((age >= 2) && (age <= 4))|
+-----+--------------------------+
|Alice| true|
| Bob| false|
+-----+--------------------------+
5.5 bitwiseAND(other)
二元运算符
5.6 bitwiseOR(other)
二元运算符
5.7 bitwiseXOR(other)
二元运算符
>>> from pyspark.sql import Row
>>> df = spark.createDataFrame([Row(a=170, b=75)])
>>> df.select(df.a.bitwiseOR(df.b)).show()
+-------+
|(a | b)|
+-------+
| 235|
+-------+
>>> df.select(df.a.bitwiseAND(df.b)).show()
+-------+
|(a & b)|
+-------+
| 10|
+-------+
>>> df.select(df.a.bitwiseXOR(df.b)).show()
+-------+
|(a ^ b)|
+-------+
| 225|
+-------+
>>> df.select(bitwiseNOT((df.a))).show()
+----+
| ~a|
+----+
|-171|
+----+
>>> df.select(df.a.__add__(df.b)).show()
+-------+
|(a + b)|
+-------+
| 245|
+-------+
>>> df.select(df.a.__sub__(df.b)).show()
+-------+
|(a - b)|
+-------+
| 95|
+-------+
>>> df.select(df.a.__mul__(df.b)).show()
+-------+
|(a * b)|
+-------+
| 12750|
+-------+
>>> df.select(df.a.__div__(df.b)).show()
+------------------+
| (a / b)|
+------------------+
|2.2666666666666666|
+------------------+
5.8 cast(dataType)
将列转换为dataType类型。
>>> df.select(df.age.cast("string").alias('ages')).collect()
[Row(ages=u'2'), Row(ages=u'5')]
>>> df.select(df.age.cast(StringType()).alias('ages')).collect()
[Row(ages=u'2'), Row(ages=u'5')]
5.9 desc()
基于给定列名称的降序返回一个排序表达式。
5.10 endswith(other)
二元运算符
val df = sc.parallelize(List(("Mike","1986","1976"), ("Andre","1980","1966"), ("Pedro","1989","2000"))).toDF("info", "year1", "year2")
df.show
# +-----+-----+-----+
# | info|year1|year2|
# +-----+-----+-----+
# | Mike| 1986| 1976|
# |Andre| 1980| 1966|
# |Pedro| 1989| 2000|
# +-----+-----+-----+
val conditions = df.columns.map(df(_).endsWith("6")).reduce(_ or _)
df.withColumn("condition", conditions).filter($"condition" === true).drop("condition").show
# +-----+-----+-----+
# | info|year1|year2|
# +-----+-----+-----+
# |Andre| 1980| 1966|
# | Mike| 1986| 1976|
# +-----+-----+-----+
5.11 getField(name)
在StructField中通过名称获取字段的表达式。
>>> from pyspark.sql import Row
>>> df = sc.parallelize([Row(r=Row(a=1, b="b"))]).toDF()
>>> df.select(df.r.getField("b")).show()
+----+
|r[b]|
+----+
| b|
+----+
>>> df.select(df.r.a).show()
+----+
|r[a]|
+----+
| 1|
+----+
5.12 getItem(key)
从列表中获取位置序号项,或者通过字典的key获取项的表达式。
>>> df = sc.parallelize([([1, 2], {"key": "value"})]).toDF(["l", "d"])
>>> df.select(df.l.getItem(0), df.d.getItem("key")).show()
+----+------+
|l[0]|d[key]|
+----+------+
| 1| value|
+----+------+
>>> df.select(df.l[0], df.d["key"]).show()
+----+------+
|l[0]|d[key]|
+----+------+
| 1| value|
+----+------+
5.13 inSet(*cols)
一个布尔表达式,如果此表达式的值由参数的评估值包含,则该值被评估为true。
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df[df.name.inSet("Bob", "Mike")].collect()
[Row(name=u'Bob', age=5)]
>>> df[df.age.inSet([1, 2, 3])].collect()
[Row(name=u'Alice', age=2)]
注:在1.5中已过时,用Column.isin()代替。
5.14 isNotNull()
如果当前表达式不为null,则为真。
5.15 isNull()
如果当前表达式为null,则为真。
5.16 isin(*cols)
一个布尔表达式,如果此表达式的值由参数的评估值包含,则该值被评估为true。
>>> df[df.name.isin("Bob", "Mike")].collect()
[Row(name=u'Bob', age=5)]
>>> df[df.age.isin([1, 2, 3])].collect()
[Row(name=u'Alice', age=2)]
5.17 like(other)
二元运算符
5.18 otherwise(value)
评估条件列表并返回多个可能的结果表达式之一。 如果不调用Column.otherwise(),则不匹配条件返回None。
例如,请参阅pyspark.sql.functions.when()
参数:
value – 一个文字值或一个Column表达式。
>>> from pyspark.sql import functions as F
>>> df.select(df.name, F.when(df.age > 3, 1).otherwise(0)).show()
+-----+---------------------------------+
| name|CASE WHEN (age > 3) THEN 1 ELSE 0|
+-----+---------------------------------+
|Alice| 0|
| Bob| 1|
+-----+---------------------------------+
5.19 over(window)
定义一个窗口列。
参数:window – 一个WindowSpec
返回:一列
注:Window方法仅再HiveContext1.4支持。
5.20 rlike(other)
二元运算符
sparksql 正则匹配总结
5.21 startswith(other)
二元运算符
5.22 substr(startPos, length)
返回一个新列,它是列的一个子字符串。
参数:
- startPos – 其实位置 (int或者Column)
- length – 子串的长度(int或者Column)
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.select(df.name.substr(1, 3).alias("col")).collect()
[Row(col=u'Ali'), Row(col=u'Bob')]
5.23 when(condition, value)
评估条件列表并返回多个可能的结果表达式之一。 如果不调用Column.otherwise(),则不匹配条件返回None。
例如,请参阅pyspark.sql.functions.when()。
参数:
- condition – 一个布尔类型的列表达式
- value – 一个文字值或一个列表达式
>>> from pyspark.sql import functions as F
>>> df.select(df.name, F.when(df.age > 4, 1).when(df.age < 3, -1).otherwise(0)).show()
+-----+--------------------------------------------------------+
| name|CASE WHEN (age > 4) THEN 1 WHEN (age < 3) THEN -1 ELSE 0|
+-----+--------------------------------------------------------+
|Alice| -1|
| Bob| 1|
+-----+--------------------------------------------------------+
6 class pyspark.sql.Row
class pyspark.sql.Row
DataFrame中的一行,其中的字段可以像属性一样访问。
Row可以用来通过使用命名参数来创建一个行对象,字段将按名称排序。
>>> from pyspark.sql import Row
>>> row = Row(name="Alice", age=11)
>>> row
Row(age=11, name='Alice')
>>> row['name'], row['age']
('Alice', 11)
>>> row.name, row.age
('Alice', 11)
# Row也可以用来创建另一个Row像类一样,然后它可以被用来创建Row对象,比如
>>> Person = Row("name", "age")
>>> Person
<Row(name, age)>
>>> Person("Alice", 11)
Row(name='Alice', age=11)
6.1 asDict(recursive=False)
作为字典返回
参数:recursive – 将嵌套的Row转换为字典(默认值:False)。
>>> Row(name="Alice", age=11).asDict() == {'name': 'Alice', 'age': 11}
True
>>> row = Row(key=1, value=Row(name='a', age=2))
>>> row.asDict() == {'key': 1, 'value': Row(age=2, name='a')}
True
>>> row.asDict(True) == {'key': 1, 'value': {'name': 'a', 'age': 2}}
True
7 pyspark.sql.DataFrameNaFunctions
class pyspark.sql.DataFrameNaFunctions(df)
在DataFrame中处理丢失的数据的功能。
7.1 drop(how=‘any’, thresh=None, subset=None)
返回一个新的DataFrame,省略含有空值的行。DataFrame.dropna()和 DataFrameNaFunctions.drop()是彼此的别名。
参数:
- how – ‘any’或者’all’.如果为’any’, 如果它包含任何空值,则丢掉一行。如果为’all’,只有当它的所有值都为空时才丢掉一行
- thresh – 默认值为None,如果指定为int,删除小于阈值的非空值的行。 这将覆盖how参数
- subset – 要考虑的列名的可选列表。
>>> l4=[('Alice',10,80),('Bob',5,None),('Tom',None,None),(None,None,None)]
>>> df4 = sqlContext.createDataFrame(l4,['name','age','height'])
>>> df4.na.drop().show()
+-----+---+------+
| name|age|height|
+-----+---+------+
|Alice| 10| 80|
+-----+---+------+
7.2 fill(value, subset=None)
DataFrame.fillna() and DataFrameNaFunctions.fill() are aliases of each other.
替换null值,是na.fill()的别名。 DataFrame.fillna()和DataFrameNaFunctions.fill()是彼此的别名。
参数:
- value –整形,长整形,浮点型,字符串,或者字典。用来替换空值的值。如果值是字典,则subset将被忽略,值必须是从列名(字符串)到要替换值的映射。替换值必须是整形,长整形,浮点型或字符串。
- subset – 要替换的列名的可选列表。在subset指定的列,如果不具有匹配的数据类型会被忽略。例如,如果value是一个字符串,并且subset包含一个非字符串列,那么非字符串列将被忽略。
>>> df4.na.fill(50).show()
+-----+---+------+
| name|age|height|
+-----+---+------+
|Alice| 10| 80|
| Bob| 5| 50|
| Tom| 50| 50|
| null| 50| 50|
+-----+---+------+
>>> df4.na.fill({'age': 50, 'name': 'unknown'}).show()
+-------+---+------+
| name|age|height|
+-------+---+------+
| Alice| 10| 80|
| Bob| 5| null|
| Tom| 50| null|
|unknown| 50| null|
+-------+---+------+
7.3 replace(to_replace, value, subset=None)
返回用另外一个值替换了一个值的新的DataFrame。DataFrame.replace() 和 DataFrameNaFunctions.replace()是彼此的别名。
参数:
- to_replace –整形,长整形,浮点型,字符串,或者列表。要替换的值。如果值是字典,那么值会被忽略,to_replace必须是一个从列名(字符串)到要替换的值的映射。要替换的值必须是一个整形,长整形,浮点型,或者字符串
- value – 整形,长整形,浮点型,字符串或者列表。要替换为的值。要替换为的值必须是一个整形,长整形,浮点型,或者字符串。如果值是列表或者元组,值应该和to_replace有相同的长度。
- subset – 要考虑替换的列名的可选列表。在subset指定的列如果没有匹配的数据类型那么将被忽略。例如,如果值是字符串,并且subset参数包含一个非字符串的列,那么非字符串的列被忽略。
>>> l4=[('Alice',10,80),('Bob',5,None),('Tom',None,None),(None,None,None)]
>>> df4 = sqlContext.createDataFrame(l4,['name','age','height'])
>>> df4.na.replace(10, 20).show()
+-----+----+------+
| name| age|height|
+-----+----+------+
|Alice| 20| 80|
| Bob| 5| null|
| Tom|null| null|
| null|null| null|
+-----+----+------+
>>> df4.na.replace(['Alice', 'Bob'], ['A', 'B'], 'name').show()
+----+----+------+
|name| age|height|
+----+----+------+
| A| 10| 80|
| B| 5| null|
| Tom|null| null|
|null|null| null|
+----+----+------+
8 pyspark.sql.DataFrameStatFunctions
class pyspark.sql.DataFrameStatFunctions(df)
DataFrame的统计函数的功能。
8.1 corr(col1, col2, method=None)
以双精度值计算DataFrame的两列的相关性。目前只支持皮尔森相关系数. DataFrame.corr() and DataFrameStatFunctions.corr() 互为别名。
参数:
- col1 – 第一列的名称
- col2 – 第二列的名称
- method – 相关方法,目前只支持“皮尔森”
8.2 cov(col1, col2)
计算给定列的样本协方差(由它们的名称指定)作为双精度值。DataFrame.cov() and DataFrameStatFunctions.cov() 互为别名。
参数:
- col1 – 第一列的名称
- col2 – 第二列的名称
8.3 crosstab(col1, col2)
计算给定列的成对频率表. 也被称为应急表. 每列的去重后不同值的数量应小于1e4. 最多1e6非零对频率将被返回. 每行的第一列将是col1的不同值,列名将是col2的不同值.第一列的名称应该为$col1_$col2. 没有出现的对数将为零. DataFrame.crosstab() and DataFrameStatFunctions.crosstab() 互为别名
参数:
- col1 – 第一列的名称. 去重项将成为每一行的第一项
- col2 – 第二列的名称. 去重项将成为DataFrame的列名称
8.4 freqItems(cols, support=None)
找到列的频繁项,可能有误差。使用“http://dx.doi.org/10.1145/762471.762473, proposed by Karp, Schenker, and Papadimitriou”中描述的频繁元素计数算法。 DataFrame.freqItems() and DataFrameStatFunctions.freqItems()互为别名。
注:此功能用于探索性数据分析,因为我们不保证所生成的DataFrame的模式的向后兼容性。
参数:
- cols – 用于计算频繁项的列的名称,为字符串的列表或元组
- support –“频繁”项目的频率。 默认值是1%,必须大于1e-4。
9 pyspark.sql.Window
class pyspark.sql.Window
用于在DataFrame中定义窗口的实用函数。
例如:
>>> # PARTITION BY country ORDER BY date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
>>> window = Window.partitionBy("country").orderBy("date").rowsBetween(-sys.maxsize, 0)
>>> # PARTITION BY country ORDER BY date RANGE BETWEEN 3 PRECEDING AND 3 FOLLOWING
>>> window = Window.orderBy("date").partitionBy("country").rangeBetween(-3, 3)
9.1 orderBy(*cols)
用定义的顺序创建一个WindowSpec。
9.2 partitionBy(*cols)
用定义的分区创建一个WindowSpec。
10 pyspark.sql.WindowSpec
class pyspark.sql.WindowSpec(jspec)
定义分区,排序和框边界的窗口规范。
使用Window中的静态方法创建一个WindowSpec
10.1 orderBy(*cols)
定义WindowSpec中的排序列。
参数:cols – 列或表达式的名称
10.2 partitionBy(*cols)
定义WindowSpec中的分区列。
参数:cols – 列或表达式的名称
10.3 rangeBetween(start, end)
定义从开始(包含)到结束(包含)的框边界。
start, end都是相对于当前行。 例如,“0”表示“当前行”,而“-1”表示在当前行之前一次,“5”表示当前行之后五次关闭。
参数:
- start – 开始边界(包括)。 如果这是-sys.maxsize(或更低),则该框架是无限的
- end – 结束边界(包括)。如果这是sys.maxsize(或更高),则该框架是无限的
10.4 rowsBetween(start, end)
定义从开始(包含)到结束(包含)的框边界。
start, end都是相对于当前行。 例如,“0”表示“当前行”,而“-1”表示在当前行之前一次,“5”表示当前行之后五次关闭。
参数:
- start – 开始边界(包括)。 如果这是-sys.maxsize(或更低),则该框架是无限的
- end – 结束边界(包括)。如果这是sys.maxsize(或更高),则该框架是无限的。
11 pyspark.sql.DataFrameReader
class pyspark.sql.DataFrameReader(sqlContext)
用于从外部存储系统(例如文件系统,键值存储等)加载DataFrame的接口。 使用SQLContext.read()来访问这个。
11.1 format(source)
指定输入数据源格式。
参数:source – string,数据源名称,例如:‘json’,‘parquet’。
people.json文件内容:
{“name”:“Michael”}
{“name”:“Andy”, “age”:30}
{“name”:“Justin”, “age”:19}
>>> df = sqlContext.read.format('json').load('/test/people.json')
>>> df.dtypes
[('age', 'bigint'), ('name', 'string')]
11.2 jdbc
(url,table,column=None,lowerBound=None,upperBound=None,numPartitions=None,predicates=None,properties=None)
构建一个DataFrame表示通过JDBC URL url命名的table和连接属性连接的数据库表。
column参数可用于对表进行分区,然后根据传递给此函数的参数并行检索它。
predicates参数给出了一个适合包含在WHERE子句中的列表表达式; 每一个都定义了DataFrame的一个分区。
注:不要在大型集群上并行创建太多分区; 否则Spark可能会使外部数据库系统崩溃。
参数:
- url – 一个JDBC URL
- table – 表名称
- column – 用于分区的列
- lowerBound – 分区列的下限
- upperBound – 分区列的上限
- numPartitions – 分区的数量
- predicates – 表达式列表
- properties – JDBC数据库连接参数,任意字符串的标签/值的列表。通常至少应该包括一个“用户”和“密码”属性
返回 : 一个DataFrame
11.3 json(path, schema=None)
加载一个JSON文件(每行一个对象)或一个存储JSON对象的字符串RDD(每个记录一个对象),并返回结果为:classDataFrame。
如果未指定schema参数,则此函数会经过一次输入以确定输入模式。
参数:
- path - 字符串表示JSON数据集的路径,或者存储JSON对象的字符串的RDD
- schema – 输入模式的可选StructType
你可以设置以下特定于JSON的选项来处理非标准的JSON文件:
- primitivesAsString (默认false): 将所有原始值推断为字符串类型
- allowComments (默认false): 忽略JSON记录中的Java / C++样式注释
- allowUnquotedFieldNames (默认false): 允许未加引号的JSON字段名称
- allowSingleQuotes (默认true): 允许除双引号外的单引号
- allowNumericLeadingZeros (默认false): 允许数字中的前导零(例如00012)
>>> df1 = sqlContext.read.json('/test/people.json')
>>> df1.dtypes
[('age', 'bigint'), ('name', 'string')]
>>> rdd = sc.textFile('/test/people.json')
>>> df2 = sqlContext.read.json(rdd)
>>> df2.dtypes
[('age', 'bigint'), ('name', 'string')]
11.4 load(path=None, format=None, schema=None, **options)
从数据源加载数据并将其作为:classDataFrame返回。
参数:
- path - 可选字符串或文件系统支持的数据源的字符串列表
- format – 数据源格式的可选字符串。 默认为“parquet”
- schema – 输入模式的可选StructType。
- options – 所有其他字符串选项。
注:parquet_partitioned文件夹路径为:spark-1.6.2-bin-hadoop2.6\python\test_support\sql\parquet_partitioned
people.json和people1.json文件路径为:spark-1.6.2-bin-hadoop2.6\python\test_support\sql
>>> df = sqlContext.read.load('/test/parquet_partitioned', opt1=True,opt2=1, opt3='str')
>>> df.dtypes
[('name', 'string'), ('year', 'int'), ('month', 'int'), ('day', 'int')]
>>> df = sqlContext.read.format('json').load(['/test/people.json','/test/people1.json'])
>>> df.dtypes
[('age', 'bigint'), ('aka', 'string'), ('name', 'string')]
11.5 option(key, value)
为基础数据源添加一个输入选项。
11.6 options(**options)
为基础数据源添加多个输入选项。
11.7 orc(path)
加载ORC文件,将结果作为DataFrame返回。
注:目前ORC支持只能与HiveContext一起使用。
11.8 parquet(*paths)
加载parquet文件, 将结果作为DataFrame返回。
>>> df = sqlContext.read.parquet('/test/parquet_partitioned')
>>> df.dtypes
[('name', 'string'), ('year', 'int'), ('month', 'int'), ('day', 'int')]
11.9 schema(schema)
指定输入的schema.
某些数据源(例如JSON)可以从数据自动推断输入模式。通过在这里指定模式,底层数据源可以跳过模式推断步骤,从而加速数据加载。
参数:schema – 一个StructType对象
11.10 table(tableName)
以DataFrame的形式返回指定的表。
参数:tableName – 字符串的表名称
>>> df = sqlContext.read.parquet('/test/parquet_partitioned')
>>> df.registerTempTable('tmpTable')
>>> sqlContext.read.table('tmpTable').dtypes
[('name', 'string'), ('year', 'int'), ('month', 'int'), ('day', 'int')]
11.11 text(paths)
加载一个文本文件并返回一个名为"value"的单个字符串列的[[DataFrame]]。
文本文件中的每一行都是生成的DataFrame中的新行。
参数:● paths – 字符串或字符串列表,用于输入路径。
>>> df = sqlContext.read.text('/test/text-test.txt')
>>> df.collect()
[Row(value=u'hello'), Row(value=u'this')]
12 pyspark.sql.DataFrameWriter
class pyspark.sql.DataFrameWriter(df)
用于将[[DataFrame]]写入外部存储系统(例如文件系统,键值存储等)的接口。使用DataFrame.write()来访问这个。
12.1 format(source)
指定基础输出数据源。
参数: source – 字符串,数据源的名称,例如 ‘json’,‘parquet’。
>>> df.write.format('json').save(os.path.join(tempfile.mkdtemp(), 'data'))
12.2 insertInto(tableName, overwrite=False)
将DataFrame的内容插入到指定的表中。
它要求DataFrame类的架构与表的架构相同。
可以覆盖任何现有的数据。
12.3 jdbc(url, table, mode=None, properties=None)
通过JDBC将DataFrame的内容保存到外部数据库表中。
注:不要在大型集群上并行创建太多分区; 否则Spark可能会使外部数据库系统崩溃。
参数:
- url – 一个形式为jdbc:subprotocol:subname的JDBC URL
- table – 外部数据库中表的名称
- mode – 指定数据已经存在时保存操作的行为:
- append: 将此DataFrame的内容附加到现有数据。
- overwrite: 覆盖现有数据。
- ignore: 如果数据已经存在,静默地忽略这个操作。
- error (默认): 如果数据已经存在,则抛出异常。
- properties – JDBC数据库连接参数,任意字符串标签/值的列表。 通常至少应该包括一个“用户”和“密码”属性。
12.4 json(path, mode=None)
以指定的路径以JSON格式保存DataFrame的内容。
参数:
- path – 任何Hadoop支持的文件系统中的路径
- mode –指定数据已经存在时保存操作的行为
- append: 将此DataFrame的内容附加到现有数据
- overwrite: 覆盖现有数据。
- ignore: 如果数据已经存在,静默地忽略这个操作。
- error (默认): 如果数据已经存在,则抛出异常。
l=[(‘Alice’,2),(‘Bob’,5)]
df = sqlContext.createDataFrame(l,[‘name’,‘age’])
df.write.json(‘file:///data/dfjson’)
[root@slave1 dfjson]# ll
total 8
-rw-r--r-- 1 root root 0 Nov 24 12:08 part-r-00000-edbd9c5e-87b2-41f4-81ba-cd59c8ca490e
-rw-r--r-- 1 root root 25 Nov 24 12:08 part-r-00001-edbd9c5e-87b2-41f4-81ba-cd59c8ca490e
-rw-r--r-- 1 root root 0 Nov 24 12:08 part-r-00002-edbd9c5e-87b2-41f4-81ba-cd59c8ca490e
-rw-r--r-- 1 root root 23 Nov 24 12:08 part-r-00003-edbd9c5e-87b2-41f4-81ba-cd59c8ca490e
-rw-r--r-- 1 root root 0 Nov 24 12:08 _SUCCESS
[root@slave1 dfjson.json]# cat part*
{"name":"Alice","age":2}
{"name":"Bob","age":5}
12.5 mode(saveMode)
指定数据或表已经存在的行为。
选项包括:
append: 将此DataFrame的内容附加到现有数据。
overwrite: 覆盖现有数据。
error: 如果数据已经存在,则抛出异常。
ignore: 如果数据已经存在,静默地忽略这个操作。
>>> df.write.mode('append').parquet(os.path.join(tempfile.mkdtemp(), 'data'))
12.6 option(key, value)
添加一个底层数据源的输出选项。
12.7 options(**options)
添加底层数据源的多个输出选项。
12.8 orc(path, mode=None, partitionBy=None)
以指定的路径以ORC格式保存DataFrame的内容。
注:目前ORC支持只能与HiveContext一起使用。
参数:
- path – 任何Hadoop支持的文件系统中的路径
- mode –指定数据已经存在时保存操作的行为:
append: 将此DataFrame的内容附加到现有数据。
overwrite: 覆盖现有数据。
ignore: 如果数据已经存在,静默地忽略这个操作。
error (默认): 如果数据已经存在,则抛出异常。 - partitionBy – 分区列的名称
>>> orc_df = hiveContext.read.orc('python/test_support/sql/orc_partitioned')
>>> orc_df.write.orc(os.path.join(tempfile.mkdtemp(), 'data'))
12.9 parquet(path, mode=None, partitionBy=None)
将DataFrame的内容以Parquet格式保存在指定的路径中。
参数:
- path – 任何Hadoop支持的文件系统中的路径
- mode – 指定数据已经存在时保存操作的行为。
append: 将此DataFrame的内容附加到现有数据。
overwrite: 覆盖现有数据。
ignore: 如果数据已经存在,静默地忽略这个操作。
error (默认): 如果数据已经存在,则抛出异常。 - partitionBy – 分区列的名称。
>>> df.write.parquet("file:///data/dfparquet")
[root@slave1 dfparquet]# ll
total 24
-rw-r--r-- 1 root root 285 Nov 24 12:23 _common_metadata
-rw-r--r-- 1 root root 750 Nov 24 12:23 _metadata
-rw-r--r-- 1 root root 285 Nov 24 12:23 part-r-00000-36364710-b925-4a3a-bd11-b295b6bd7c2e.gz.parquet
-rw-r--r-- 1 root root 534 Nov 24 12:23 part-r-00001-36364710-b925-4a3a-bd11-b295b6bd7c2e.gz.parquet
-rw-r--r-- 1 root root 285 Nov 24 12:23 part-r-00002-36364710-b925-4a3a-bd11-b295b6bd7c2e.gz.parquet
-rw-r--r-- 1 root root 523 Nov 24 12:23 part-r-00003-36364710-b925-4a3a-bd11-b295b6bd7c2e.gz.parquet
-rw-r--r-- 1 root root 0 Nov 24 12:23 _SUCCESS
12.10 partitionBy(*cols)
按文件系统上的给定列对输出进行分区。
如果指定,则输出将在文件系统上进行布局,类似于Hive的分区方案。
参数:cols – 列的名称.
>>> df.write.partitionBy('year', 'month').parquet(os.path.join(tempfile.mkdtemp(), 'data'))
12.11 save(path=None, format=None, mode=None, partitionBy=None, **options)
将DataFrame的内容保存到数据源。
数据源由format和一组options指定。 如果未指定format,则将使用由spark.sql.sources.default配置的缺省数据源。
参数:
- path – Hadoop支持的文件系统中的路径
- format – 用于保存的格式
- mode – 指定数据已经存在时保存操作的行为
append: 将此DataFrame的内容附加到现有数据。
overwrite: 覆盖现有数据。
ignore: 如果数据已经存在,静默地忽略这个操作。
error (默认): 如果数据已经存在,则抛出异常。 - partitionBy – 分区列的名称
- options – all other string options
>>> l=[('Alice',2),('Bob',5)]
>>> df = sqlContext.createDataFrame(l,['name','age'])
>>> df.write.mode('append').save("file:///data/dfsave")
12.12 saveAsTable(name, format=None, mode=None, partitionBy=None, **options)
将DataFrame的内容保存为指定的表格。
在表已经存在的情况下,这个函数的行为依赖于由mode函数指定的保存模式(默认为抛出异常)。 当模式为覆盖时,[[DataFrame]]的模式不需要与现有表的模式相同。
append: 将此DataFrame的内容附加到现有数据。
overwrite: 覆盖现有数据。
error: 如果数据已经存在,则抛出异常。
ignore: 如果数据已经存在,静默地忽略这个操作。
参数:
- name – 表名
- format – 用于保存的格式
- mode – 追加,覆盖,错误,忽略之一(默认:错误)
- partitionBy – 分区列的名称
- options – 所有其他字符串选项
12.13 text(path)
将DataFrame的内容保存在指定路径的文本文件中
DataFrame必须只有一个字符串类型的列。每行成为输出文件中的新行
13 pyspark.sql.types
数据类型的基类
【Python笔记】pyspark.sql.types
14 pyspark.sql.functions
内建函数的集合
【Python笔记】pyspark.sql.functions