【数据结构与算法】图的基本概念回顾
图的定义
图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),G表示一个图,V(vertex)是图G中顶点的集合,E(edge)是图G中边的集合。
- 图中的数据元素称为结点。
- 在图结构中,顶点集合V有穷非空。
- 在图结构中,任意两个顶点之间都可能有关系,顶点间的逻辑关系用边来表示,边集可以为空。
图的基本术语
用n表示图中顶点数目,用e表示边的数目,下面是一些关于图的术语总结:
-
无向图和有向图
图按有方向和无方向分为无向图和有向图

无向图中,顶点间的连接关系称为无向边,无向边可以表示成无序对,如**(A,B)也可以写成(B,A)**。
有向图中,顶点间的连接关系称为有向边,也称为弧,用有序对表示,如**
-
无向完全图和有向完全图
无向完全图:在无向图中,任意两个顶点都存在边。含有n个顶点的无向完全图有 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)条边。
有向完全图:在有向图中,任意两个顶点之间都存在方向互为相反的两条弧。含有n个顶点的有向完全图有 n ( n − 1 ) n(n-1) n(n−1)条边。

-
子图
灰色背景均为子图

-
稀疏图和稠密图
有很少条边或弧的图称为稀疏图,反之称为稠密图,这里没有明确的标准,是相对而言的。
-
权和网
在有的图中,每条边或弧可以标上具有某种含义的数值,该数值称为该边或弧上的权,这种带权的图通常称为网。
-
邻接点
对于无向图G,如果图的边**(v,v´)∈E**,则称v 和v´互为邻接点,即v 和v´相邻接。边**(v,v´)依附于顶点v 和v´**,或者说边**(v,v´)与顶点v 和v´相关联**。
-
度、入度和出度
顶点的度是指和v相关联的边的数目,记为 T D ( v ) TD(v) TD(v)。对于有向图,顶点v的度分为入度和出度,入度是以顶点v为头的弧的数目,记为 I D ( v ) ID(v) ID(v),出度是以顶点v为尾的弧的数目,记为 O D ( v ) OD(v) OD(v),顶点v的度为:
T D ( v ) = I D ( v ) + O D ( v ) TD(v)=ID(v)+OD(v) TD(v)=ID(v)+OD(v)
一般地,如果顶点 v i v_i vi的度记为 T D ( v i ) TD(v_i) TD(vi),那么一个有n个顶点,e条边的图,满足如下关系:
e = 1 2 ∑ i = 1 n T D ( v i ) e=\frac{1}{2}\sum_{i=1}^{n}{TD(v_i)} e=21i=1∑nTD(vi)
-
回路或环
第一个顶点和最后一个顶点相同的路径称为回路的环。
-
简单路径、简单回路或简单环
序列中顶点不重复出现的路径称为简单路径。回路的环中除了第一个顶点和最后一个顶点之外,其他顶点不重复出现,则称为简单回路或简单环。
-
路径和路径的长度
路径的长度是路径上边或弧的数目。
-
连通、连通图和连通分量
在无向图G中,如果从顶点v到v´有路径,则称v和v´是连通的。如果对于图中任意两个顶点 v i , v j ∈ E v_i,v_j∈E vi,vj∈E, v i 和 v j v_i和v_j vi和vj都是连通的,则称G是连通图,如图1不是连通图,而图二是连通图。
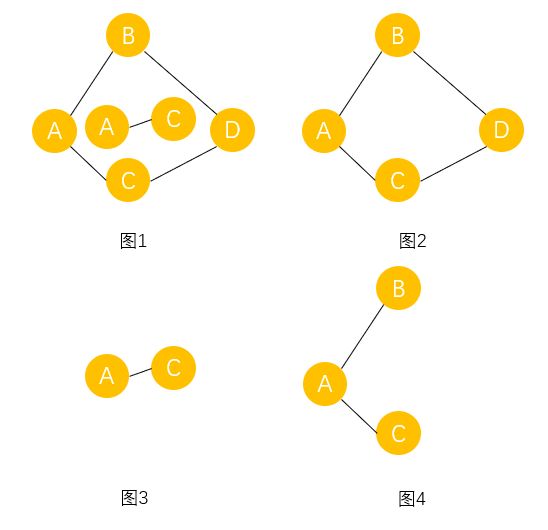
无向图中的极大连通子图称为连通分量,图2和图3都是图1的连通分量。
-
强连通图和强连通分量
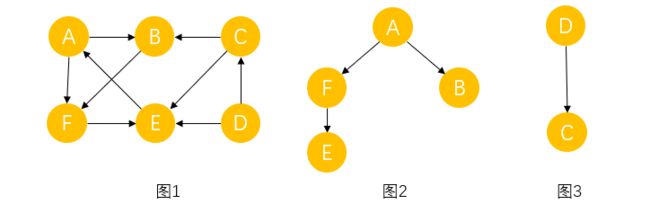
在有向图G中,如果对于每一对 v i , v j ∈ V , v i ≠ v j v_i,v_j∈V,v_i≠v_j vi,vj∈V,vi=vj,从 v i 到 v j v_i到v_j vi到vj和从 v j 到 v i v_j到v_i vj到vi都存在路径,则称G是强连通图。有向图中的极大强连通子图称做有向图的强连通分量。,如下图,图1不是强连通图,因为从D到A没有路径,但图2和图3是图1的强连通分量。

-
连通图的生成树
连通图的生成树是一个极小连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。如下图,就是连通图的生成树。

-
有向树和生成森林
如果一个有向图恰有一个顶点的入度为0,其余顶点的入度均为1,则是一颗有向树。如下图的图2和图3都是一颗有向树,A和D的入度为0,可理解为树中的根结点。一个有向图的生成森林是由若干颗有向树组成,含有图中全部顶点,但只有足以构成若干颗不相交有向树的弧,如图1所示。
图的类型定义
图是一种数据结构,加上一组基本操作,就构成了抽象数据类型。抽象数据类型图的定义如下:
ADT图(Graph)
Data
顶点的有穷非空集合和边的集合
Operation
CreateGraph(*G,V,VR) :按照顶点集V和边孤集VR的定义构造图
DestroyGraph(*G) :图G存在则销毁
LocateVex(G,u) :若图G中存在顶点u,则返回图中的位置
GetVex(G,v) :返回图G中顶点v的值
PutVez(G,v,value) :将图G中顶点v赋值value
FirstAdjVex(G,*v) :返回顶点v的一个邻接顶点,若顶点在G中无邻接顶点返回空
NextAdjVex(G,v,*w) :返回顶点v相对于顶点w的下一个邻接顶点,若w是v的最后一个邻接点则返回“空”
ISertVex(*G,v) :在图G中添加新顶点v
DeleteVex(*G,v) :删除图G中顶点v及其相关的弧
InsertArc(*G,v,w) :在图G中增添弧<v,w>,若G是无向图,还需要增添对称弧<w,v>
DeleteArc(*G,v,w) :在图G中删除弧<v,w>,若G是无向图,还需要增添对称弧<w,v>
DFSTraverse(G) :对图G中进行深度优先遍历,在遍历过程对每个顶点调用
HFSTraverse (G) :对图G中进行广度优先遍历.在遍历过程对每个顶点调用
endADT
图的存储结构
邻接矩阵
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中的边或弧的信息。
设图G有n个顶点,则邻接矩阵是一个n×n的方阵,两个顶点有关系则用1表示,否则用0表示,定义如下:
A [ i ] [ j ] = { 1 , 若 ( v i , v j ) ∈ E 或 < v i , v j > ∈ E 0 , 反 之 A[i][j]=\begin{cases} 1, & 若(v_i,v_j)∈E或
如下图,左图是一个无向图,用右图的一维数组+二维数组表示

如上图可知,顶点数组为vertex[4]={ v 0 , v 1 , v 2 , v 3 v_0,v_1,v_2,v_3 v0,v1,v2,v3},边数组为arc[4] [4],每一行之和代表该顶点的度,边数组的对角线元素为0,这是因为不存在顶点到自身的边,如果要求某个顶点的邻接点,将该顶点对应的行扫描一遍,1对应位置的即为邻接点。值得注意的是,无向图的边数组是一个对称矩阵。
下面我们来分析有向图,1表示一个顶点到另一个顶点有弧,0则表示没有:

同样地,有向图的顶点数组为vertex[4]={ v 0 , v 1 , v 2 , v 3 v_0,v_1,v_2,v_3 v0,v1,v2,v3},边数组为arc[4] [4],每行之和代表该顶点的出度,每列之和代表该顶点的度,边数组的对角线元素仍为0,如果要求某个顶点的邻接点,将该顶点对应的行扫描一遍,1对应的位置即为邻接点。注意,有向图的边数组不是对称矩阵。
好了,介绍完了图,我们再来介绍一下网,前面已经介绍过了,每条边上带权的图叫作网。
设图G是网,有n个顶点,若某个顶点到另一个顶点没有边或弧,则用 ∞ ∞ ∞表示, ∞ ∞ ∞表示一个计算机允许的、大于所有边上权值的值,因此,有如下定义:
A [ i ] [ j ] = { W i , j , 若 ( v i , v j ) 或 < v i , v j > ∈ E ∞ , 反 之 A[i][j]=\begin{cases} W_{i,j}, & 若(v_i,v_j)或

那么现在我们来实现图的创建:
#define MaxInt 32767 //表示极大值,即∞
#define MVNum 100 //最大顶点数
typedef char VerTexType; //假设顶点数据类型为字符型
typedef int ArcType; //假设边的权值类型为整型
typedef struct
{
VerTexType vexs[MVNum]; //顶点表,一维数组
ArcType arcs[MVNum][MVNum]; //邻接矩阵,二维数组
int vexnum,arcnum; //图的当前点数和边数
}AMGraph;
有了这个结构体,接下来我们用邻接矩阵表示法创建一个无向网为例来说明创建图的算法。
算法分为四步:
- 输入顶点总数和总边数;
- 依次输入顶点信息;
- 初始化邻接矩阵,使邻接矩阵的每条边上的权值均为 ∞ ∞ ∞
- 依次输入与每条边相关联的顶点和权值,确定两个顶点在图中的位置后,赋予相应边一个权值,同时它的对称边赋予相同的权值,如 ( v 0 , v 1 ) 和 ( v 1 , v 0 ) (v_0,v_1)和(v_1,v_0) (v0,v1)和(v1,v0)互为对称边。
//采用邻接矩阵表示法,创建无向图
void CreateUDN(AMGraph *G)
{
int i,j,k,w;
scanf("%d,%d",&G->vexnum,&G->arcnum); //输入总顶点数和总边数
for(i=0;i<G->vexnum;i++) //依次输入顶点信息
scanf("%d",G->vexs[i]);
for(i=0;i<G->vexnum;i++) //初始化邻接矩阵,边的权值均置为极大值Maxint
for(j=0;j<G->vexnum;j++)
G->arcs[i][j] = MaxInt;
for(k=0;k<G->arcnum;k++) //构造邻接矩阵
{
scanf("%d,%d,%d",&i,&j,&w); //输入一条边依附的顶点和权值
G->arcs[i][j] = w;
G->arcs[i][j] = G->arcs[j][i] //无向图,对称矩阵
}
}
上述代码中,n个顶点和e条边的无向图的创建,时间复杂度为 O ( n + n 2 + e ) O(n+n^2+e) O(n+n2+e),其中对邻接矩阵的初始化耗费了 O ( n 2 ) O(n^2) O(n2)的时间,虽然这是一种不错的图存储结构,但如果对于边数相对于顶点较少的图,就会造成了极大的空间浪费,因为此时矩阵中大部分是 ∞ ∞ ∞,下面我们来讨论另一种结构。
邻接表
邻接表是图的一种链式存储结构。
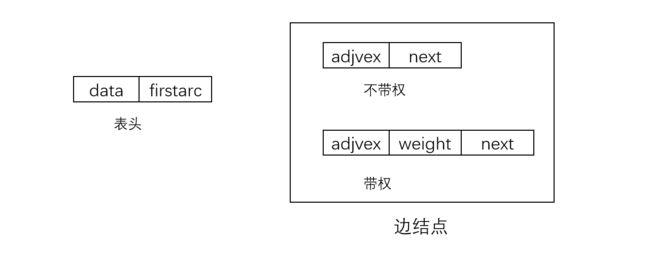
邻接表由表头结点和边结点两部分组成:
-
表头结点用一个一维数组存储,结点包含数据和指向第一个邻接点的指针组成,用数组存储便于查找顶点的边信息。
-
每个顶点的邻接点用单链表存储,无向图称该单链表为顶点 v i v_i vi的边表,有向图则称为顶点 v i v_i vi作为弧尾的出边表。若图不带权,单链表中的边结点包含两部分,**一部分是边结点在数组中的位置(下标),另一部分是指向下一个边结点的指针。**若图带权,边结点则含有三个部分,增加的部分用于存储权的信息。
在这种结构中,每个顶点所对应的单链表结点数就是该顶点的度,如果要判断从顶点 v i v_i vi到 v j v_j vj是否存在边,则只需检索 v i v_i vi对应链表的结点的adjvex域中有无j即可。

对于有向图,邻接表是类似的,但因为我们是以顶点弧尾来存储边表的,所以结点个数只能代表出度,若要知道入度,我们还需以顶点弧头来存储边表,得到一个逆邻接表,逆邻接表中某一顶点对应单链表的结点数就是该结点的入度,如下图:
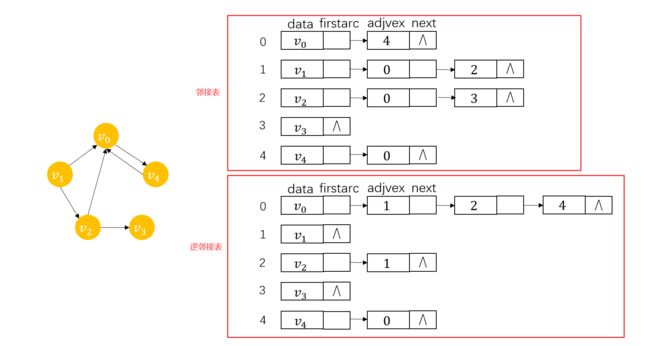
对于带权的网图,我们在边结点中增加weight域来存储权即可。
经过上面的分析,我们来创建相应的结构体:
typedef int VertexType;
typedef int ArcType; // 类型根据需要自行定义
typedef struct ArcNode //定义边结点
{
int adjvex; //存储邻接点下标
ArcType weight; //存储权,这里不是网图,不需要用
struct ArcNode* next; //指向下一个结点的指针
}ArcNode;
typedef struct VertexNode //顶点表头结点
{
VertexType data; //存储顶点信息
ArcNode* firstarc; //用于指向第一个邻接点的指针
}VertexNode,AdjList[MAXVEX];
typedef struct
{
AdjList adjList;
int vexnum,arcnum; //邻接表当前顶点数和边数
}GraphAdjList;
下面创建无向图的邻接表:
void CreateGraph(GraphAdjList *G)
{
int i,j,k;
ArcNode *e;
scanf("%d,%d",&G->numvex,&G->arcnum); //输入顶点数和边数
for(i=0;i < G->numvex;i++) //输入顶点信息
{
scanf("%d",&G->adjList[i].data);
G->adjList[i].firstarc = NULL; //将顶点表头结点的指针置空
}
for(k=0;k< G->arcnum;k++) //建立边表
{
scanf("%d,%d",&i,&j); //输入与边(v_i,v_j)相关的两个顶点的序号
e=(ArcNode*)malloc(sizeof(ArcNode)); //创建边结点
//头插法
e->adivex = j; //邻接序号为j
e->next = G->adjList[i].firstarc; //e的指针域指向当前顶点指向的下一个邻接点
G->adjList[i].firstarc = e; //当前顶点的指针指向e
e=(ArcNode*)malloc(sizeof(ArcNode));
e->adivex = i; //邻接序号为i
e->next = G->adjList[i].firstarc; //e的指针域指向当前顶点指向的下一个邻接点
G->adjList[i].firstarc = e; //当前顶点的指针指向e
}
}
这里用到了链表的头插法,如果不清楚的话可以看看我之前的博客,我是链接
十字链表
十字链表 (Orthogonal List) 是有向图的另一种链式存储结构。
上面对于有向图,我们采用了邻接表和逆邻接表解决出度和入度的问题,而十字链表就可以将这两种表整合到一起。
我们将弧结点和顶点结点的结构体定义如下:
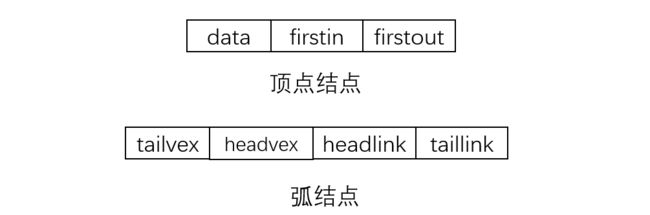
顶点结点:firstin是入边表的头指针,firstout表示出边表的头指针。
弧结点:tailvex和headvex分别指向弧尾和弧头在顶点表中的下标,headlink指向终点相同的下一条弧,taillink指向起点相同的下一条弧。
图的遍历
图的遍历是指的是从图中的任一顶点出发,对图中的所有顶点访问一次且只访问一次。
深度优先搜索算法
深度优先搜索(Depth First Search,DFS),类似树的前序遍历,是前序遍历的推广。
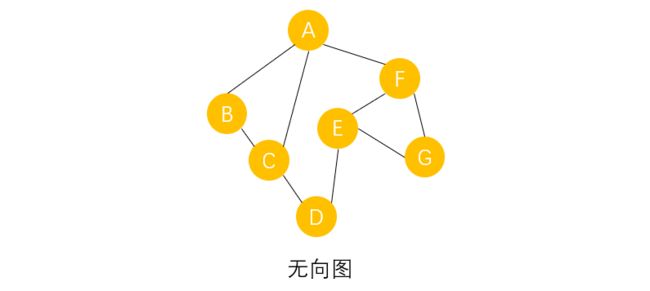
以上面这个无向图为例,说一下深度优先算法的运作过程:
- 从顶点A开始,访问过顶点A后,现在面临三种选择,要么去顶点B,要么去C或者F,现在我们规定,优先访问右边未被访问过的邻接点,这里的右边是指假设我们站在点A,面临三条路选择时的右手边,于是访问B。
- 访问完B后,只有一条路选择,于是访问C,C有两条路选择,但优先选择右手边未访问的邻接点,于是访问D,然后继续访问E、F,然后访问A。
- 顶点A已经访问过了,但还有未被访问的邻接点,接下来访问A最右边的顶点B,发现B也访问过了,而B的邻接点也都被访问了,返回A处,再访问顶点C,顶点C也被访问过了,C的邻接点也都被访问了,于是返回A处。接着访问顶点F,顶点F已被访问过,但还有未被访问的邻接点,接着访问顶点G,G的邻接点已全部访问完毕。
- 至此,全部顶点已经访问完毕,得到的顶点访问序列为 A B C D E F G ABCDEFG ABCDEFG
现在我们用代码来实现这一遍历过程,图的存储用的是邻接矩阵的方式
int visited[MAX];
void DFS (AMGraph G,int i)
{
int j;
visited[i] = 1; //若已被访问过则标记为1
printf("%c ",G.vexs[i]); //可更改为其他对顶点的操作
for(j = 0;j<G.vexnum;j++)
{
if(G.arcs[i][j] == 1 && !visited[j]) //邻接点存在且未被访问
DFS(G,j); //递归
}
}
//深度优先搜索遍历
void DFSTraverse(AMGraph G)
{
int i;
for(i = 0;i<G.vexnum;i++)
visited[i] = 0; //初始化所有节点均认为未被访问
for(i = 0;i < G.vexnum;i++)
{
if(!visited[i])
DFS(G,i);
}
}
若图的存储用的是邻接表的方式,则是以下算法
//递归操作
void DFS(GraphAdjList GL; int i)
{
ArcNode *p; //边结点
visited[i] = 1;
P = GL->adjList[i].firstarc;
while(p)
{
if(!visited[p->adjvex]) //顶点未被访问
DFS(GL,p->adjvex);
p = p->next;
}
}
//遍历邻接表
void DFSTraverse(GraphAdjList GL)
{
int i;
for(i = 0; i< GL->vexnum; i++)
visited[i] = 0; //初始化所有节点均认为未被访问
for(i = 0; i < GL->vexnum; i++)
{
if(!visited[i])
DFS(GL,)
}
}
广度优先算法
广度优先搜索(Breadth First Search, BFS)遍历类似于树的层次遍历,是树的层序遍历的推广。

还是以上图为例,分析层序遍历的遍历过程:
我们先将上图变形为下图,顶点A位于第一层,与顶点A有边的顶点B、C、F位于第二层,同理与顶点B、C、F有边的D、E、G位于第三层。

然后利用队列先进先出的特点对图进行遍历:
- 顶点A入队,顶点A出队。
- 顶点B、C、F入队。
- 顶点B出队,然后顶点C出队,顶点D入队。
- 顶点F出队,顶点E、G入队。
- 顶点D出队,顶点E出队,顶点G出队,至此,图的遍历结束,遍历顺序为ABCFDEG。
对于BFS原理我之前发过一篇带例题的文章,里面讲解的更详细,感兴趣可移步阅读,链接放这里了。
接下来我们看看邻接矩阵的广度优先算法:
void BFSTraverse(AMGraph G)
{
int i,j;
Queue Q;
for(i = 0; i<G.vexnum;i++)
visited[i] = 0;
//初始化队列
InitQueue(&Q);
for(i=0; i < G.vexnum;i++)
{
if(!visited[i]) //若未访问过则进行访问
{
visited[i] = 1; //进行标记
PushQueue(&Q,i); //顶点入队
while(QueueSize(Q))//若队列不为空,则继续循环
{
PopQueue(&Q,&i);//队头出队,用i保存数组下标
for(j=0;j<G.vexnum;j++)//访问刚刚出队顶点的邻接点
{
if(G.arcs[i][j] == 1 && !visited[j]) //邻接点存在且未被访问
{
visited[j]=1; //标记
PushQueue(&Q,j); //顶点入列
}
}
}
}
}
}
邻接表的的广度优先算法:
void BFSTraverse(GraphAdjList GL)
{
int i;
ArcNode *p;
Queue Q;
for(i = 0; i<G.vexnum;i++)
visited[i] = 0;
InitQueue(&Q);
for(i=0; i < G.vexnum;i++)
{
if(!visited[i])
{
visited[i] = 1;
PushQueue(&Q,i);
while(QueueSize(Q))
{
PopQueue(&Q,&i);
p = GL->adjList[i].firstarc; //记录刚刚删除顶点指向的第一个邻接点
while(p)
{
if(!visited(p->adjvex)) //该顶点未被访问
{
visitde[p->adjvex] = 1;
PushQueue(&Q,p->adjvex);
}
p = p->next;
}
}
}
}
}
深度优先算法与广度优先算法的优缺点:
深度优先:速度慢但占用内存少。
广度优先:速度快但占用内存多;
参考资料:
- 大话数据结构
- 《数据结构》C语言版(清华严蔚敏考研版)