数据驱动分析实践一 了解数据,定义指标
数据驱动分析 实践一
了解数据,定义指标
前言
在一个真实的商业场景中,经营者通常需要:
- 了解他当时所面对的经营情况,既:对比历史,了解现在
- 分析原因,既:洞察真相
- 制定策略,提高增长,既:规划和执行
- 检查结果,既:反馈循环 这四步需要循环迭代以使商业经营不断纠错、不断适应新的经济环境的变化。 但是在大数据分析、模型构建等技术发展时代,我们通常会借助人工智能和数据分析手段来辅助完成。
本文开始以python语言进行数据驱动、客户分析的实践,内容包括
1 了解数据,定义指标
2 客户分段分析
3 CLV 预测分析 4 客户流失预测分析
5 下一个购买日预测
6 预测销量
7 市场响应模型
8 提升模型
9 A/B 测试设计和执行
本系列主要是围绕前面所讨论的CLV和Customer Segmentaion等进行实践,主要技术涉及数据分析和机器学习等。 本文为第一篇,主要是在探索数据的同时,我们学习和了解一个重要的指标类 North Star Metrics.
一. 了解数据,定义指标
每一位企业领导者都希望为企业带来增长,但是如何做到呢?是需要更多的客户、更多的订单、更高的营收还是更高的效率呢?答案可能是不明确的,可能都需要,但是什么是最重要的呢?每一个企业都需要清楚定位所需解决的核心问题,而在数据分析领域的第一步就是找到我们需要回答的那个正确的问题。
这里我们介绍北极星指标(North Star Metric),一个描述你的产品给客户带来的核心价值的指标,它依赖于具体的产品、目标、行业位置等。例如,Airbnb的北极星指标是每晚的订房数量,而Facebook是日活跃用户。
这里,我们将使用一个在线零售数据集。对于在线零售业,北极星指标为月收入(Monthly Revenue).
月收入
导入包
# import libraries
from __future__ import division
from datetime import datetime, timedelta
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import chart_studio.plotly as py
import plotly.offline as pyoff
import plotly.graph_objs as go
%matplotlib inline
读入数据
pyoff.init_notebook_mode()
tx_data = pd.read_excel('Online Retail.xlsx')
tx_data.head(10)

这里使用了一份在线零售数据集,其中的关键信息为
- CustomerID
- UnitPrice
- Quantity
- InvoiceNo
我们在衡量用户价值的同时,首先要先判断一下我们的产品能够给用户提供的核心价值是什么,这需要一个量化指标。基于这个目的,我们介绍North Star Metrics.
看一下Sean Ellis对North Star Metrics的描述:
The North Star Metric is the single metric that best captures the core value that your product delivers to customers.
笔者理解,North Star Metrics 北极星指数是依赖于公司的产品、所处环境、目标等。Airbnb的北极星指数是夜间订阅数,而Facebook是日活跃用户。对于零售数据,我们可以选择月收入作为北极星指标。
月收入=活跃用户数×交易单数×每单平均收入
北极星指标等式为
= × × = × × Revenue=ActiveCustomerCount×Ordercount×AverageRevenueperorder
计算月收入
#converting the type of Invoice Date Field from string to datetime.
tx_data['InvoiceDate'] = pd.to_datetime(tx_data['InvoiceDate'])
#creating YearMonth field for the ease of reporting and visualization
tx_data['InvoiceYearMonth'] = tx_data['InvoiceDate'].map(lambda date: 100*date.year + date.month)
#calculate Revenue for each row and create a new dataframe with YearMonth - Revenue columns
tx_data['Revenue'] = tx_data['UnitPrice'] * tx_data['Quantity']
tx_revenue = tx_data.groupby(['InvoiceYearMonth'])['Revenue'].sum().reset_index()
tx_revenue

可视化
#X and Y axis inputs for Plotly graph. We use Scatter for line graphs
plot_data = [
go.Scatter(
x=tx_revenue['InvoiceYearMonth'],
y=tx_revenue['Revenue'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Montly Revenue'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)

很明显月收入在8月份开始大幅增长,12月份回落是因为数据不完整。
月收入增长率
接下来,我们看一下月收入增长率的情况
#using pct_change() function to see monthly percentage change
tx_revenue['MonthlyGrowth'] = tx_revenue['Revenue'].pct_change()
#showing first 5 rows
tx_revenue.head()
#visualization - line graph
plot_data = [
go.Scatter(
x=tx_revenue.query("InvoiceYearMonth < 201112")['InvoiceYearMonth'],
y=tx_revenue.query("InvoiceYearMonth < 201112")['MonthlyGrowth'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Montly Growth Rate'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
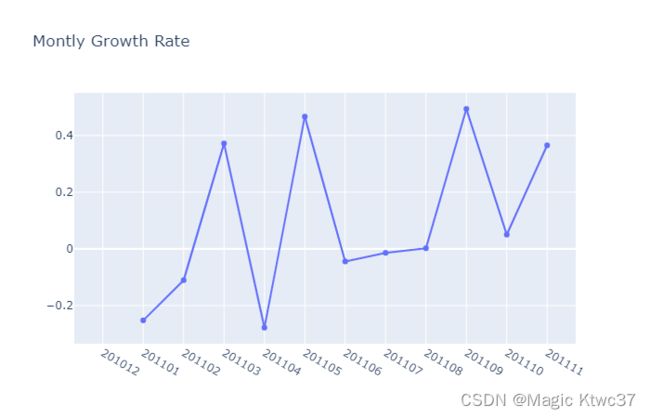
可以看到,11月份增长率达到36.5%。但是我们需要详细调查一下四月份,为什么这个月出现大幅下降。
月活跃用户
从这里开始,我们聚焦在UK的销售纪录。用CustomerID来唯一确定用户。
#creating a new dataframe with UK customers only
tx_uk = tx_data.query("Country=='United Kingdom'").reset_index(drop=True)
#creating monthly active customers dataframe by counting unique Customer IDs
tx_monthly_active = tx_uk.groupby('InvoiceYearMonth')['CustomerID'].nunique().reset_index()
#plotting the output
plot_data = [
go.Bar(
x=tx_monthly_active['InvoiceYearMonth'],
y=tx_monthly_active['CustomerID'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Monthly Active Customers'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
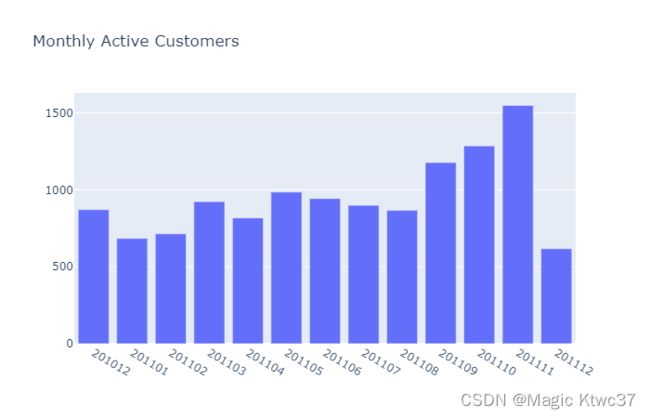
tx_monthly_active

四月份月活用户从三月份的923跌落到817,-11.5%.
月交易单量
在月交易单量的分析中,我们看到了同样趋势。
tx_monthly_sales = tx_uk.groupby('InvoiceYearMonth')['Quantity'].sum().reset_index()
tx_monthly_sales

plot_data = [
go.Bar(
x=tx_monthly_sales['InvoiceYearMonth'],
y=tx_monthly_sales['Quantity'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Monthly Total # Order'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)

正如所料,交易单数在四月份也下降了,从279K到257K,-8%.
每单平均收入
我们再来看一下单个订单平均收入。
# create a new dataframe for average revenue by taking the mean of it
tx_monthly_order_avg = tx_uk.groupby('InvoiceYearMonth')['Revenue'].mean().reset_index()
#plot the bar chart
plot_data = [
go.Bar(
x=tx_monthly_order_avg['InvoiceYearMonth'],
y=tx_monthly_order_avg['Revenue'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Monthly Order Average'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
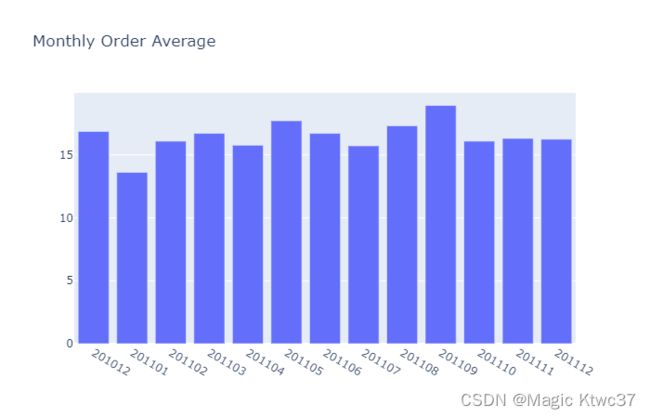
#print the dataframe
tx_monthly_order_avg

四月份也下降了,从16.7到15.8.
到现在为止,我们已经观察了一些重要的指标。
行业上还有其他一些相对重要的指标,下面我们来调查一下:
- 新客户比例
- 留存率
新客户比例
首先我们需要定义一下什么是新客户。所谓新客户就是在当月是其第一次消费的客户。
#create a dataframe contaning CustomerID and first purchase date
tx_min_purchase = tx_uk.groupby('CustomerID').InvoiceDate.min().reset_index()
tx_min_purchase.columns = ['CustomerID','MinPurchaseDate']
tx_min_purchase['MinPurchaseYearMonth'] = tx_min_purchase['MinPurchaseDate'].map(lambda date: 100*date.year + date.month)
#merge first purchase date column to our main dataframe (tx_uk)
tx_uk = pd.merge(tx_uk, tx_min_purchase, on='CustomerID')
tx_uk.head()
#create a column called User Type and assign Existing
#if User's First Purchase Year Month before the selected Invoice Year Month
tx_uk['UserType'] = 'New'
tx_uk.loc[tx_uk['InvoiceYearMonth']>tx_uk['MinPurchaseYearMonth'],'UserType'] = 'Existing'
#calculate the Revenue per month for each user type
tx_user_type_revenue = tx_uk.groupby(['InvoiceYearMonth','UserType'])['Revenue'].sum().reset_index()
#filtering the dates and plot the result
tx_user_type_revenue = tx_user_type_revenue.query("InvoiceYearMonth != 201012 and InvoiceYearMonth != 201112")
plot_data = [
go.Scatter(
x=tx_user_type_revenue.query("UserType == 'Existing'")['InvoiceYearMonth'],
y=tx_user_type_revenue.query("UserType == 'Existing'")['Revenue'],
name = 'Existing'
),
go.Scatter(
x=tx_user_type_revenue.query("UserType == 'New'")['InvoiceYearMonth'],
y=tx_user_type_revenue.query("UserType == 'New'")['Revenue'],
name = 'New'
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='New vs Existing'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
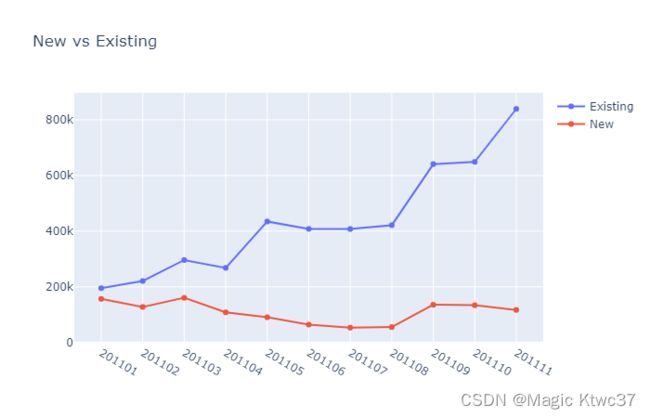
老客户有上升趋势,而新客户有一点下降趋势。
看一下新客户比例
#create a dataframe that shows new user ratio - we also need to drop NA values (first month new user ratio is 0)
tx_user_ratio = tx_uk.query("UserType == 'New'").groupby(['InvoiceYearMonth'])['CustomerID'].nunique()/tx_uk.query("UserType == 'Existing'").groupby(['InvoiceYearMonth'])['CustomerID'].nunique()
tx_user_ratio = tx_user_ratio.reset_index()
tx_user_ratio = tx_user_ratio.dropna()
#print the dafaframe
tx_user_ratio
#plot the result
plot_data = [
go.Bar(
x=tx_user_ratio.query("InvoiceYearMonth>201101 and InvoiceYearMonth<201112")['InvoiceYearMonth'],
y=tx_user_ratio.query("InvoiceYearMonth>201101 and InvoiceYearMonth<201112")['CustomerID'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='New Customer Ratio'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)

如同所料,新客户比例在下降。到了11月份下降到了20%。
月留存率
我们需要仔细观察分析这个指标,因为它说明我们提供的商品和服务对客户的粘性以及市场适合情况。
ℎ =上个月的留存客户/总的活跃用户
#identify which users are active by looking at their revenue per month
tx_user_purchase = tx_uk.groupby(['CustomerID','InvoiceYearMonth'])['Revenue'].sum().reset_index()
#create retention matrix with crosstab
tx_retention = pd.crosstab(tx_user_purchase['CustomerID'], tx_user_purchase['InvoiceYearMonth']).reset_index()
#create an array of dictionary which keeps Retained & Total User count for each month
months = tx_retention.columns[2:]
retention_array = []
for i in range(len(months)-1):
retention_data = {}
selected_month = months[i+1]
prev_month = months[i]
retention_data['InvoiceYearMonth'] = int(selected_month)
retention_data['TotalUserCount'] = tx_retention[selected_month].sum()
retention_data['RetainedUserCount'] = tx_retention[(tx_retention[selected_month]>0) & (tx_retention[prev_month]>0)][selected_month].sum()
retention_array.append(retention_data)
#convert the array to dataframe and calculate Retention Rate
tx_retention = pd.DataFrame(retention_array)
tx_retention['RetentionRate'] = tx_retention['RetainedUserCount']/tx_retention['TotalUserCount']
#plot the retention rate graph
plot_data = [
go.Scatter(
x=tx_retention.query("InvoiceYearMonth<201112")['InvoiceYearMonth'],
y=tx_retention.query("InvoiceYearMonth<201112")['RetentionRate'],
name="organic"
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Monthly Retention Rate'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)

tx_retention.head()

留存率在六月和八月到达高峰,然后又下降了。
同批留存 Cohort based retention ratio¶
另外一个较为重要的衡量留存的指标是Cohort based retention ratio, 笔者将其译为同批留存率。这里的Cohort定义为第一次购买发生在相同年月的客户,称为同批客户。同批留存率衡量每个月的同批客户的留存率,通过这个指标,我们可以了解老客户和新客户留存的不同,还有是否最近的改变对客户体验有所影响。
#create our retention table again with crosstab() and add firs purchase year month view
tx_retention = pd.crosstab(tx_user_purchase['CustomerID'], tx_user_purchase['InvoiceYearMonth']).reset_index()
tx_retention = pd.merge(tx_retention,tx_min_purchase[['CustomerID','MinPurchaseYearMonth']],on='CustomerID')
new_column_names = [ 'm_' + str(column) for column in tx_retention.columns[:-1]]
new_column_names.append('MinPurchaseYearMonth')
tx_retention.columns = new_column_names
#create the array of Retained users for each cohort monthly
retention_array = []
for i in range(len(months)):
retention_data = {}
selected_month = months[i]
prev_months = months[:i]
next_months = months[i+1:]
for prev_month in prev_months:
retention_data[prev_month] = np.nan
total_user_count = tx_retention[tx_retention.MinPurchaseYearMonth == selected_month].MinPurchaseYearMonth.count()
retention_data['TotalUserCount'] = total_user_count
retention_data[selected_month] = 1
query = "MinPurchaseYearMonth == {}".format(selected_month)
for next_month in next_months:
new_query = query + " and {} > 0".format(str('m_' + str(next_month)))
retention_data[next_month] = np.round(tx_retention.query(new_query)['m_' + str(next_month)].sum()/total_user_count,2)
retention_array.append(retention_data)
tx_retention = pd.DataFrame(retention_array)
tx_retention.index = months
#showing new cohort based retention table
tx_retention
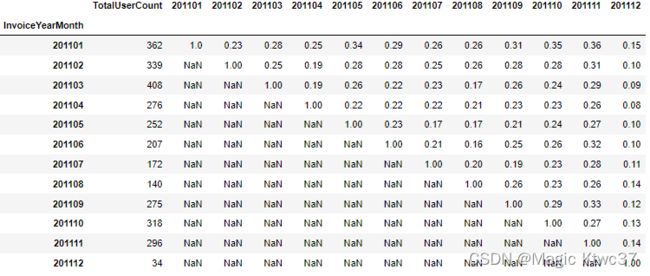
从数据上看,第一月的那批客户的留存率是最高的。
未完,待续…