姓名:韩宜真
学号:17020120095
转载自:https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650794799&idx=5&sn=34afcf8fb6020bc0f529f5911cb4c0bc&chksm=871a2f51b06da6478d42d2b033b48a495845f1f84a7e9984e0c786b70de8378c629937a9840e&mpshare=1&scene=23&srcid=1216pMETXDspM1d1XmoAGxjY&sharer_sharetime=1608098322587&sharer_shareid=3f1a3081900d54d7638a82ca5b9e8a0d#rd
【嵌牛导读】本文介绍了一种自监督注意力机制。
【嵌牛鼻子】稠密光流估计 自监督的深度学习
【嵌牛提问】自监督注意力机制是如何实现目标跟踪的?
【嵌牛正文】想要了解什么是自监督注意力机制,我们可能需要先去了解什么是光流估计(optical flow estimation),以及它为何被人类和计算机视觉系统作为一种目标跟踪方法。
与人类视觉系统类似,计算机视觉系统也广泛应用于视频监控和自动驾驶等领域。跟踪算法的目标是在给定的视频序列中重新定位它在初始帧中识别的一组特定对象。
在与跟踪算法相关的研究文献中,主要分为两大类:1)视觉对象跟踪(Visual Object Tracking, VOT);2)半监督视频对象分割(Semisupervised Video Object Segmentation, Semi-VOS)。
就这两类跟踪算法而言,VOT 通过重新定位视频序列中的目标边界框来实现目标跟踪,而 Semi-VOS 通过像素级分割掩码实现更细粒度的目标跟踪。
在 medium 的一篇博客中,数据科学家和视觉计算研究者 Rishab Sharma 为读者重点讲述 Semi-VOS 算法背后的最初构想,即稠密光流估计,以及这种跟踪方法是如何通过自监督注意机制实现的。
具体而言,本文首先介绍了光流的概念,并研究了它在目标跟踪中的应用。接着介绍了这个概念如何启发深度学习跟踪系统,以及自监督和视觉注意力在这些系统的开发中如何发挥关键作用。
文中所讨论的技术主要应用于行人跟踪、自动车辆导航以及许多新的应用。如果你在为数据集的制作发愁,或许自监督注意力机制可以帮助到您。

稠密光流估计
首先科普一下光流的小知识。
作为目标和摄像机之间相对运动的结果,光流可以被定义为视频序列的连续帧之间的物体运动。此外,光流又分为稀疏光流以及稠密光流。
稀疏光流仅导出帧中几个感兴趣像素的流向量,这些像素通常描述目标的某个边或角,而稠密光流可以导出给定帧内所有像素的流向量,从而以更高的计算量和更低的速度获得更高的精度。

网球运动员的稠密光流估计效果。
稠密光流可以通过各种算法实现,其中要数 Farneback 算法最为简单。OpenCV 为该算法提供了寻找稠密光流的函数。你只需点一下运行,就能真切体验到 Farneback 算法,代码片段如下图所示:
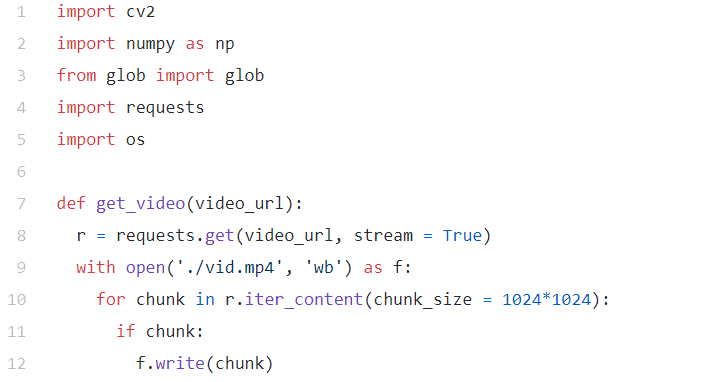
输出结果如下动图所示:
光流可视化。
Farneback 算法可以通过比较视频序列中的两个连续帧,来估计某些图像特征的运动。
具体而言,该算法首先使用多项式展开变换(polynomial expansion transform)通过二次多项式逼近图像帧的窗口。多项式展开变换是专门在空间域中设计的信号变换,可用于任何维度的信号。该方法观察多项式变换的平移,以根据多项式展开系数估计位移场。随后,此方法在一系列迭代优化之后计算稠密光流。
在实现代码中,该算法从两通道向量矩阵中(dx/dt 和 dy/dt)计算光流的方向和大小,然后通过 HSV 颜色模型,将计算出的方向和大小进行可视化。该颜色模型设置为最大值 255 时体验最佳。
用深度学习进行稠密光流估计
关于光流的优化问题一直存在。近年来,随着深度学习的发展,许多研究者采用深度学习算法来解决光流优化问题,将连续的视频帧作为输入来计算运动中物体的光流。
虽然这类算法一次只处理两个连续的帧,但视频的本质是在这两个帧中捕获的。而视频与图像的主要区别在于,视频除了具有图像的空间结构外,还具有时间结构。
因此,连续帧流可以被解释为以特定时间分辨率(specific temporal resolution, fps)操作的图像集合。这意味着视频中的数据不仅是在空间上编码的,而且是按顺序编码的,这使得对视频进行分类非常有趣,同时也具有挑战性。
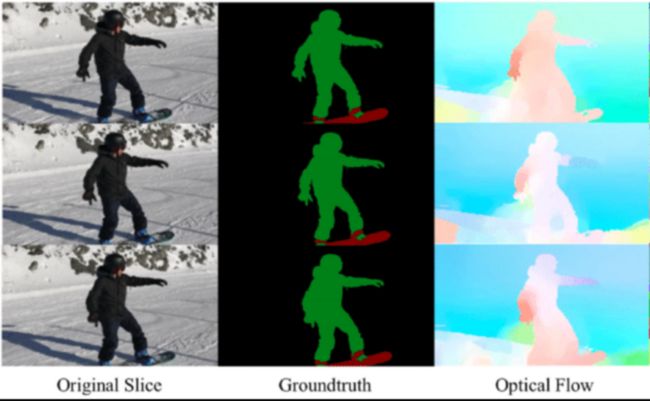
一般来说,深度神经网络需要大量的数据来训练模型以及优化算法。但对于光流估计来说,训练数据难以获得, 主要原因是很难精确地标记视频片段,以使图像中每个点的精确运动达到亚像素精度。
为了解决视频数据的标记问题,研究人员采用计算机图形学,通过指令来模拟大量的真实世界。当指令已知时,视频帧序列中每个像素的运动都是已知的。光流被广泛地应用在基于目标检测的车辆跟踪和交通分析等场景,以及通过基于特征的光流技术从固定摄像机或车辆摄像机进行的多目标跟踪领域。
自监督的深度学习进行目标跟踪
在视频分析领域中,视觉跟踪非常重要。但同时,由于需要巨大的数据标注量,使得深度学习难以进行。但无论如何,为了获得高性能的跟踪结果,大规模的训练数据集是必不可少的,而这反过来又需要大量的投入,从而使得深度学习方法变得更加不切实际和昂贵。
为了解决训练数据集问题,研究人员希望找到一种方法,能通过大量未标记和原始视频数据,使机器在没有人工监督的情况下进行学习(标记数据)。这种自监督学习的探索始于谷歌研究团队的一项研究提案,该提案建议通过训练一个视频着色模型,进而生成视觉跟踪系统,同时该任务不需要任何额外的标记数据(自监督)。
然而,有研究表明,与其让模型预测输入灰度帧(grayscale frame)的颜色,不如让模型学会从一组参考帧中复制颜色,因此产生了一种指向机制,该机制能够在时间设置中跟踪视频序列的空间特征。
这些自监督方法的可视化以及实验表明,尽管网络是在没有任何人工监督的情况下训练的,但在网络内部自动出现了一种视觉特征跟踪机制。
在对未标记视频进行训练之后,自监督模型能够跟踪视频帧序列初始帧中指定的任何分割区域。
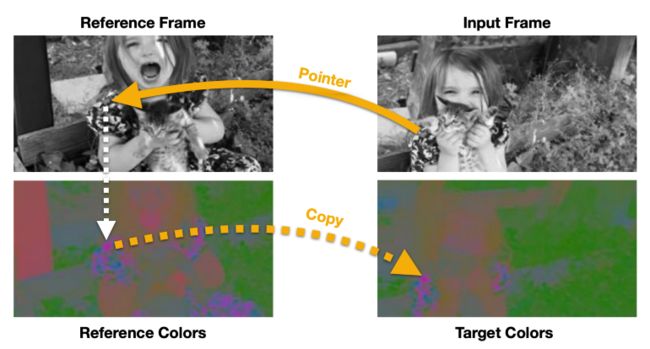
跟踪自监督学习的目标是学习适合于匹配视频帧序列的特征嵌入。利用帧序列的自然时空连贯性(spatial-temporal coherence)来学习对应流。对应流可以理解为连续帧之间存在的特征相似流。
简单地说,该方法学习了一种指针机制,该机制可以通过从一组参考帧中复制像素信息来重建目标图像。因此,要建立这样的模型,研究人员在设计时需要注意以下两点:
必须防止模型学习这个任务无效解(trivial solution),例如基于低级颜色特征匹配连续帧;
必须使跟踪器飘移不那么严重。跟踪器漂移(tracker drifting, TD)主要是由目标遮挡、复杂的目标变形和随机光照变化引起的。跟踪器飘移问题通常是在长时间窗口上训练递归模型来解决,该窗口具有周期一致性和定时采样特点。

在设计此类模型时同样需要注意以下几点。首先,对应匹配(correspondence matching)是这些模型的基本组成部分,这一点非常重要。因此,在通过逐像素匹配进行帧重建时,该模型很可能会学习到一个简单的解决方案。
其次,为了防止模型过拟合一个简单的解决方案,需要添加颜色抖动(color jittering)和通道丢弃(channel-wise dropout),这样模型就会依赖低级颜色信息,并且对任何颜色的抖动具有鲁棒性。
最后,对于 TD 的处理,基于长时间窗的递归训练是解决跟踪器漂移问题的最佳方法。
上述方法可以提高模型的鲁棒性。此外,该方法不仅能够利用视频的时空连贯性,而且可以用颜色作为其监督信号。
底层的自监督注意力
如果深入研究这里学到的指针机制,我们会得出结论,它实际上是一种注意力机制。是的,它就是著名的 QKV「三剑客」,即查询 - 键 - 值(Query-Key-Value),这是大多数注意力机制的基础。
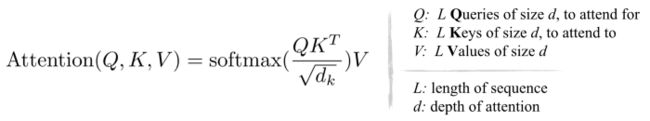
我们知道,自监督模型的目标是通过有效编码特征表示来学习鲁棒的对应匹配。
简单地说,有效复制的能力是通过训练代理任务来实现的,其中模型学习通过线性组合参考帧中的像素数据来重建目标帧,并且利用权重来测量像素之间的对应强度。
然而,分解这个过程就会发现,每个输入帧都有一个三元组(Q, K, V)。Q、K、V 分别表示查询、键和值。为了重建 T^1 帧中的像素 I^1,注意力机制用于从原始序列中先前帧的子集复制像素。
只是这种情况下,查询向量(Q)是当前帧的(I^1)特征嵌入(目标帧),键向量是前一帧(I^0)的特征嵌入(参考帧)。现在,如果计算查询和键(Q、K)之间的点积(.),并对计算出的乘积取一个 softmax,就可以得到当前帧(I^1)和前一个参考帧(I^0)之间的相似性。
在推理过程中,将计算出的相似度矩阵与参考实例分割掩码(V)相乘,将为目标帧提供一个指针,从而实现稠密光流估计。因此这个指针是 Q、K 和 V 的组合,是在这个自监督系统框架下运行的注意力机制。
每个人都需要注意力,猫也不例外。
训练注意力机制的一个关键因素是建立适当的信息瓶颈。为了避免注意力机制可能使用的任何学习捷径,我们可以采用前文提到的输入颜色信息丢失和通道丢失技术。然而,颜色空间的选择在自监督训练注意力机制方面仍然起着重要作用。
许多研究工作已经证实了这样一个假设:使用去相关颜色空间可以得到更好的自监督稠密光流估计的特征表示。
简单来说,使用 LAB 格式的图像比 RGB 格式更好。这是因为所有的 RGB 通道都包含亮度信息,使其与实验室中的亮度高度相关,因此成为弱信息瓶颈。
限制注意力机制以最小化物理内存成本
上述注意机制通常具有较高的物理内存开销。因此,对应匹配中处理处理高分辨率信息会导致大内存需求和较慢的速度。

为了规避内存开销,我们利用 ROI 定位技术从内存库中估计候选窗口,而非本地存储库。直观地说,对于时间相近的帧,帧序列自然存在时空连贯性。由于现在目标帧中的像素仅与参考帧的空间相邻像素进行比较,所以这种 ROI 定位限制了注意力。
可比像素(comparative pixel)的数目由限制注意力的放大窗口的大小决定。窗口的膨胀率与内存库中当前帧、过去帧之间的时间距离成正比。在计算限制注意区域的相似矩阵后,可以非局部地计算细粒度匹配得分。
因此,利用所提出的限制注意力机制,该模型可以有效地处理高分辨率信息,而不会产生大量的物理内存开销。