文章原创,最近更新:2018-04-20
1.无监督学习-聚类
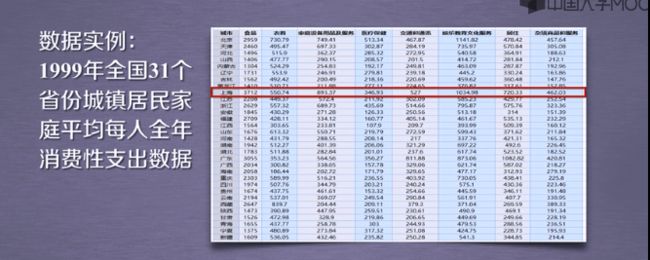
2.聚类之K-Means+31省市居民家庭消费调查
3.聚类之Dbscan+学生上网时间分布聚类实例
Python机器学习应用-北京理工大学-礼欣、嵩天
前言:
这个课程比较一般,主讲人感觉对着PPT念了一遍,对概念分析也不怎么清晰.不推荐看整一套视频.
1.无监督学习-聚类
1.1无监督学习的目标

1.2聚类的定义
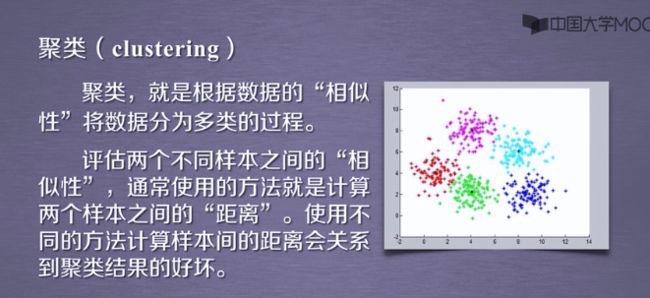
1.3欧氏距离
欧氏距离是最常用的一种距离度量方法,源于欧氏空间中两点的距离,也就是我们初中学的两点之间的距离计算方式.

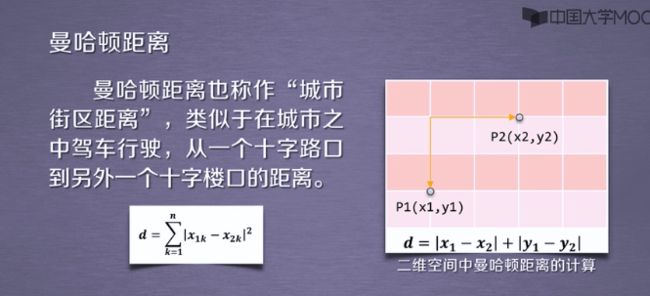
1.4曼哈顿距离
曼哈顿距离类似与空间直角坐标系中,两个点x轴的距离+y轴的距离.
1.5马式距离
马式距离相对自己而言比较陌生.

补充内容:
链接内容详细补充了马氏距离:
https://blog.csdn.net/panglinzhuo/article/details/77801869
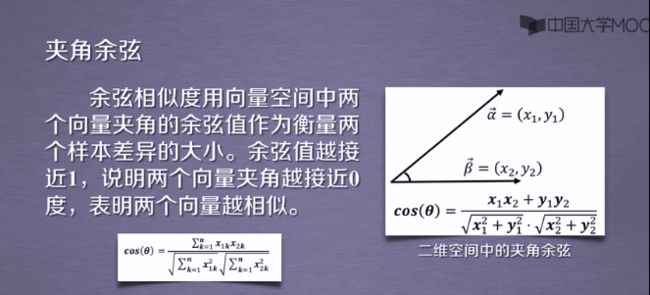
1.6夹角余弦
这是高中常见的数学公式,
1.7Sklearn VS. 聚类





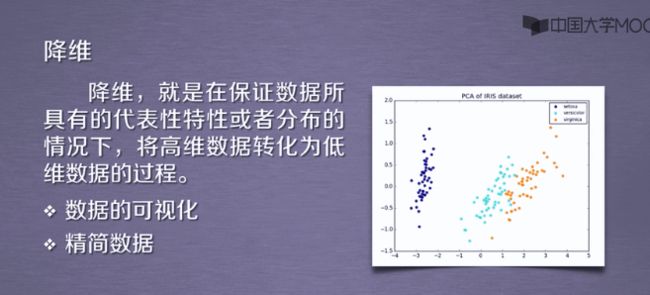
1.8降维


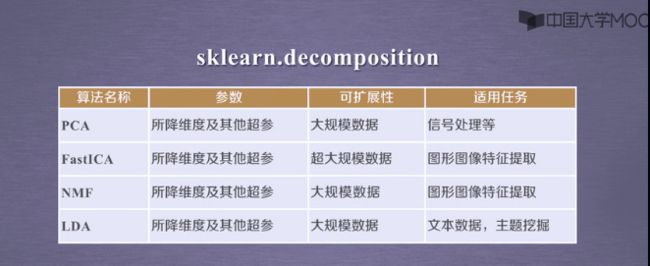

2.聚类之K-Means+31省市居民家庭消费调查
2.1K-Means方法

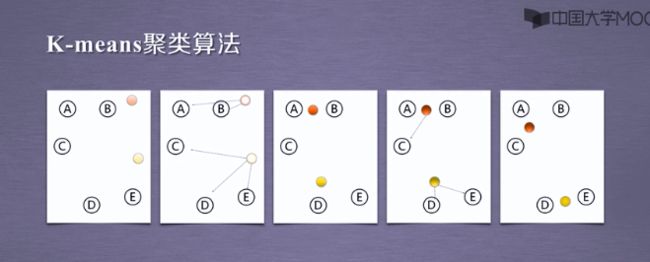
2.2K-Means的应用












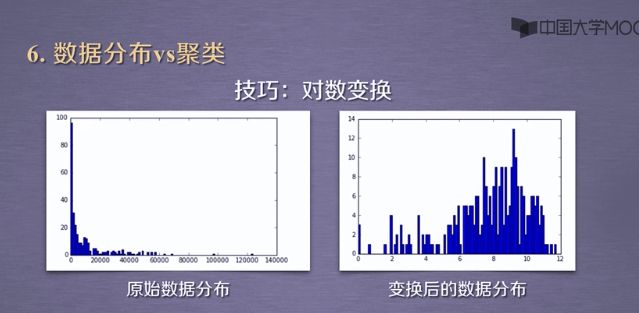
拓展&改进



1.利用loadData方法读取数据
2.创建实例
3.调用Kmeans()、fit_predict()方法进行计算
def loadData(filePath):
fr = open(filePath,'r+')
lines = fr.readlines()
retData = []
retCityName = []
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append([float(items[i]) for i in range(1,len(items))])
return retData,retCityName
if __name__ == '__main__':
data,cityName = loadData('city.txt')
km = KMeans(n_clusters=4)
label = km.fit_predict(data)
expenses = np.sum(km.cluster_centers_,axis=1)
#print(expenses)
CityCluster = [[],[],[],[]]
for i in range(len(cityName)):
CityCluster[label[i]].append(cityName[i])
for i in range(len(CityCluster)):
print("Expenses:%.2f" % expenses[i])
print(CityCluster[i])
3.聚类之Dbscan+学生上网时间分布聚类实例
3.1DBSCAN密度聚类


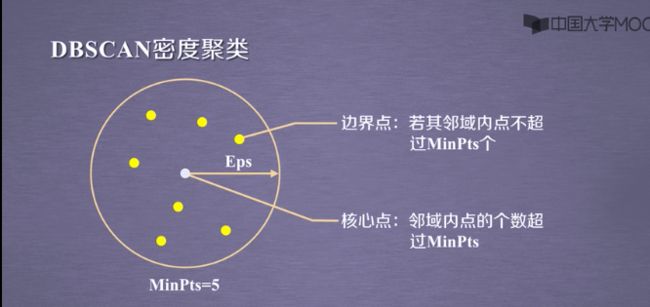
设置MinPts的点≤5个
3.2DBSCAN密度算法流程:

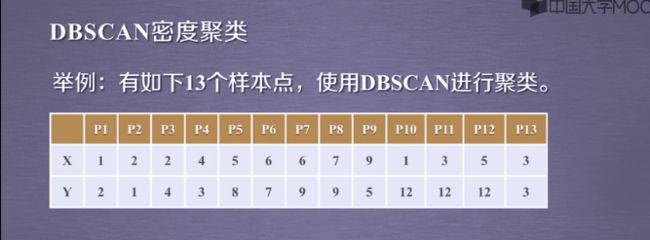
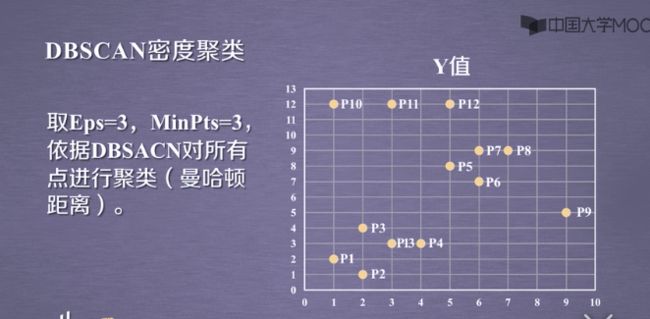
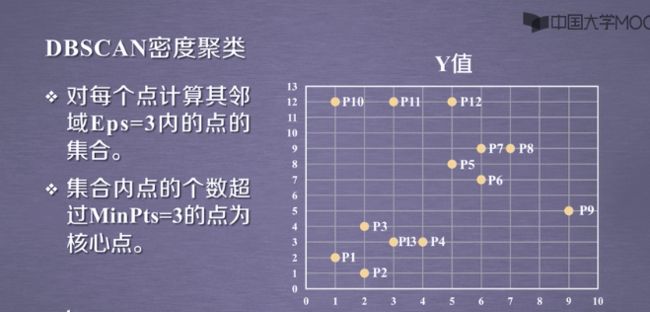
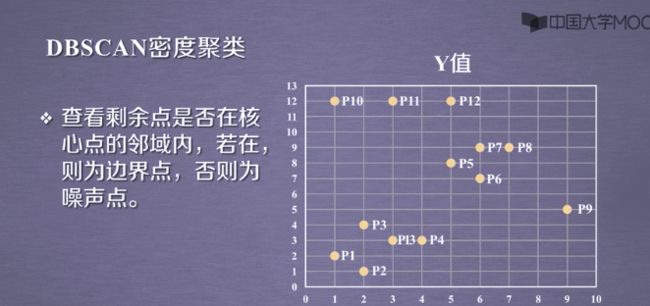
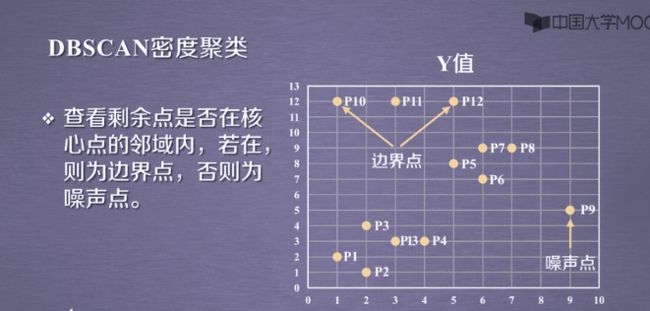

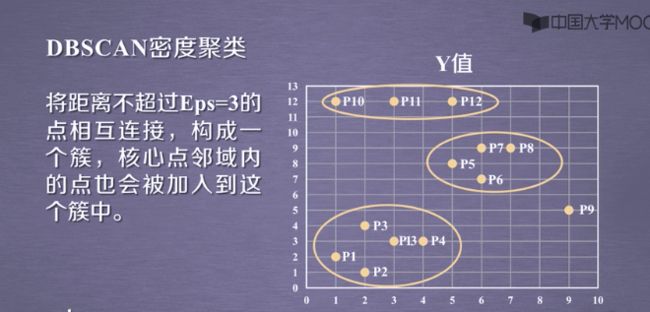
3.3DBSCAN的应用实例:


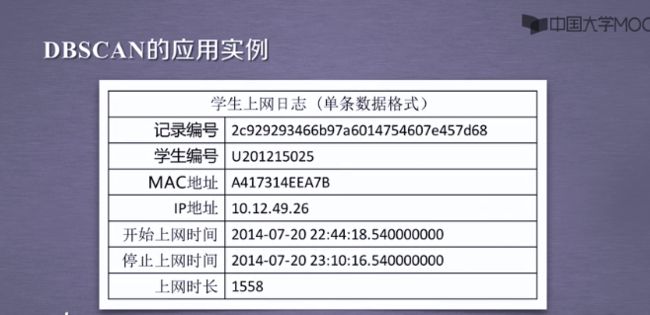
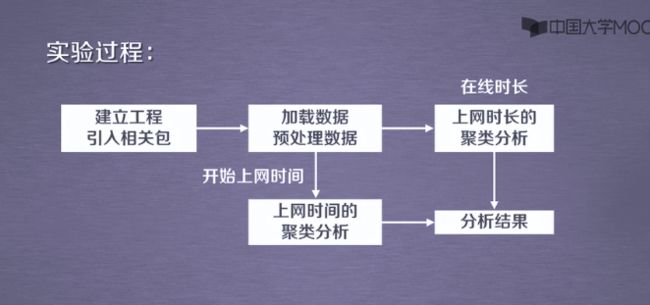

采用欧氏距离的方式
建立工程,导入sklearn相关包
import numpy as np
import sklearn.cluster as skc
from sklearn import metrics
import matplotlib.pyplot as plt

读入数据并进行处理
mac2id=dict()
onlinetimes=[]
f=open('TestData.txt',encoding='utf-8')
for line in f:
mac=line.split(',')[2]
onlinetime=int(line.split(',')[6])
starttime=int(line.split(',')[4].split(' ')[1].split(':')[0])
if mac not in mac2id:
mac2id[mac]=len(onlinetimes)
onlinetimes.append((starttime,onlinetime))
else:
onlinetimes[mac2id[mac]]=[(starttime,onlinetime)]
real_X=np.array(onlinetimes).reshape((-1,2))

上网时间聚类,创建DBSCAN算法实例,并进行训练,获得标签
X=real_X[:,0:1]
db=skc.DBSCAN(eps=0.01,min_samples=20).fit(X)
labels = db.labels_

输出标签,查看结果
print('Labels:')
print(labels)
raito=len(labels[labels[:] == -1]) / len(labels)
print('Noise raito:',format(raito, '.2%'))
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print('Estimated number of clusters: %d' % n_clusters_)
print("Silhouette Coefficient: %0.3f"% metrics.silhouette_score(X, labels))
for i in range(n_clusters_):
print('Cluster ',i,':')
print(list(X[labels == i].flatten()))
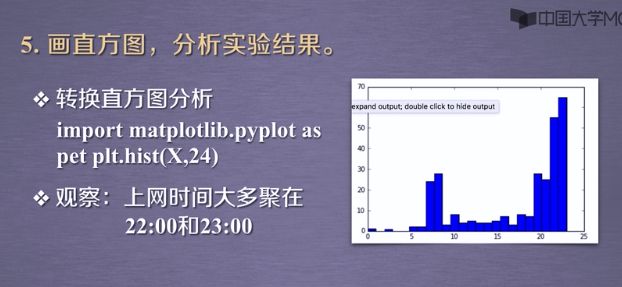
plt.hist(X,24)
plt.show()



上网时间大多聚集在22:00和23:00