一: mysql基础知识
事物:
- 开发中,业务存在一组操作(ABCD),要么全部成功,要么全部不成功。
事物的特性
原子性(整体性)
一致性(数据)
隔离性(并发)--4种隔离级别
持久性(结果)
并发产生的问题:(不考虑事物的隔离性,会出现以下问题)
- 脏读:
一个事务读到另一个事务未提交的数据。
(一个事务读取了另一个事务改写但还未提交的数据,如果这些数据被回滚,则读到的数据是无效的.)
- 不可重复读:
一个事务读到另一个事务已经提交的数据。(update)
(在同一事务中,多次读取同一数据返回的结果有所不同。
换句话说就是,后续读取可以读到另一事务已提交的更新数据。
相反,“可重复读”在同一事务中多次读取数据时,能够保证所读数据一样,
也就是,后续读取不能读到另一事务已提交的更新数据)
3.幻读
一个事务读到另一个事务已经提交的数据。(insert) -- 理论
参考:(虚读解释的很明白了)https://www.cnblogs.com/shujiying/p/13100324.html
事务的四种隔离级别:
- read uncommitted 读未提交
一个事务读到另一个事务未提交的数据,存在3个问题。(存在脏读,不可重复读,幻读)
- read committed 读已提交
一个事务读到另一个事务已提交的数据,解决:脏读、存在:2个问题 (存在不可重复读,幻读,) - repeatable read(RR) 可重复读。
```
解决:脏读、不可重复读,存在:1个问题 (存在幻读)
解决幻读:RR级别下只要对 SELECT 操作也手动加行(X)锁即可类似 SERIALIZABLE 级别(它会对 SELECT 隐式加锁)
```
- serializable 串行化。 单事务。
案例演示
案例--演示问题以及解决方案
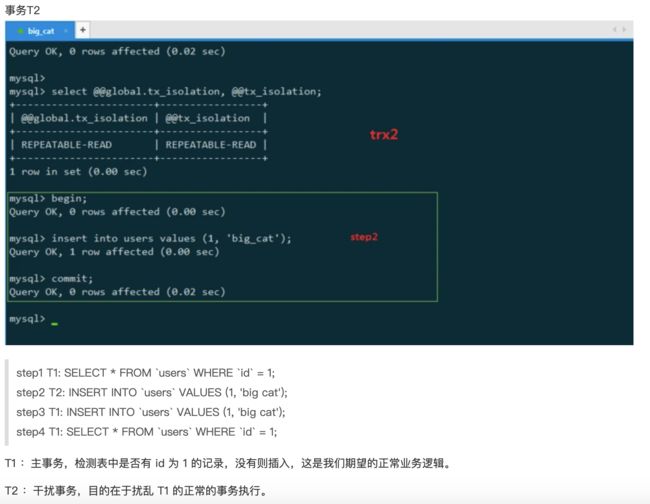
(一).演示脏读----一个事务读取到另一个事务未提交数据
1.设置事务的隔离级别是 read uncommitted(读未提交)
set session transaction isolation level read uncommitted;
2.在A窗口执行下面语句
先开启事物。。因为mysql是自动提交事物的
start transaction;
update account set money=money-500 where name='aaa';
update account set money=money+500 where name='bbb';
3.在B窗口执行下面操作
select * from account;
可以查看到aaa给bbb汇了500块钱. 查看到了另一个事务的未提交数据.
4.在A窗口中rollback,commit;
5.将刚才执行的数据撤回
(1).解决脏读问题,演示不可重复读问题-----设置事务的隔离级别为 read committed (读已提交)
-解决:脏读、存在:2个问题 (存在不可重复读,虚读,)
1.设置事务隔离级别(在AB窗口)
set session transaction isolation level read committed;
start transaction; (开启事物,不让mysql进行默认提交)
2.在A窗口执行下面语句
update account set money=money-500 where name='aaa';
update account set money=money+500 where name='bbb';
3.在B窗口中执行下面语句
select * from account;
不能查看到A中未提交数据.
4.当A窗口中提交数据,在B窗口中再查询,就可以读取到A提交的数据.
这时就出现了不可重复读----一个事务读取到了另一个事务已提交的数据。
(2).解决不可重复读(Repeatable read)
1.设置事务隔离级别为可重复读(在AB窗口)
set session transaction isolation level Repeatable read;
2.在A窗口执行下面语句
update account set money=money-500 where name='aaa';
update account set money=money+500 where name='bbb';
3.在B窗口查看
select * from account;
解决了脏读(查询不到a未提交的数据)
4.在A窗口将事务commit;
5.在B窗口,也不能读取到A提交的信息,解决了不可重复读。
(3) --------演示一下可重复读隔离级别会发生幻读现象-----------------------------
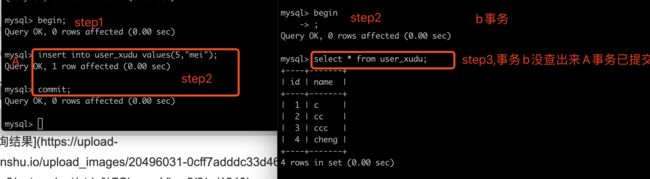
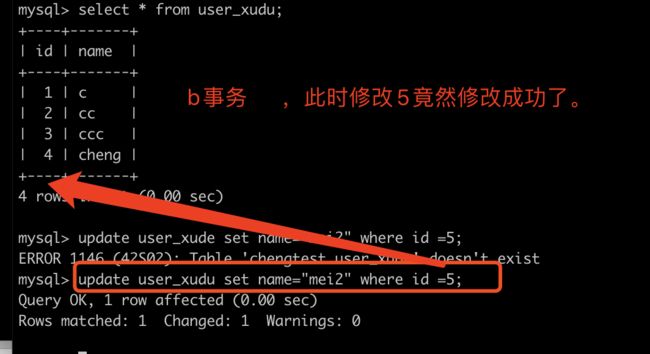
(AB窗口同事开启事务,在A窗口直接新增一条数据,然后提交事务。。这时在B窗口直接对A事务已提交的那条数据进行更改操作,发现竟然更改成功了,然后再查询一下,竟然查询出来了。我的B事务还没提交呢。。所以这就产生了虚读的问题了)
参考博文:[https://www.jianshu.com/p/4c02a3a2e9d2](https://www.jianshu.com/p/4c02a3a2e9d2)
(4).设置事务隔离级别为serializable,它可以解决所有问题
set session transaction isolation level serializable;
它会锁表,只要当前事务未提交,其它事务不可能对这个表进行操作.
演示虚读:(1)
注:A事务的step 2标错了。。应该是step2.1
演示幻读2:(此比较简单好理解)
https://www.cnblogs.com/shujiying/p/13100324.html(参考这片博文很详细)
如何解决幻读?
二:Mysql的数据库引擎 (问到了好几次)
https://blog.csdn.net/longjialin93528/article/details/80693748 (这篇文章会有详细的介绍)
查看数据库引擎: show engines
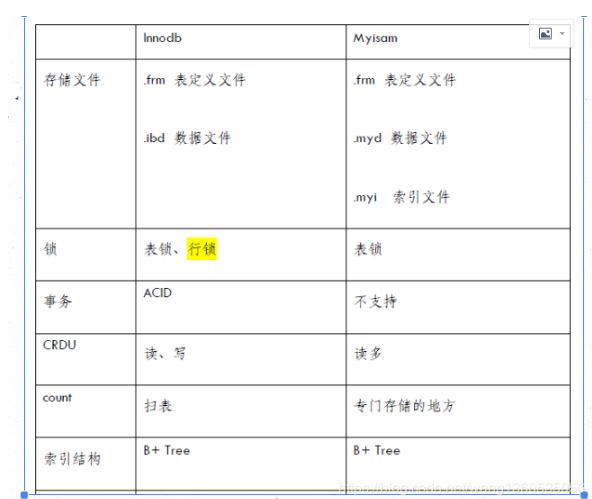
1.InnoDB
InnoDB是一个事务型存储引擎,提供了对数据库ACID事务的支持,并实现了SQL标准的四种隔离级别,具有行级锁定以及外键支持。该引擎的设计目标便是处理大容量数据的数据库系统,MySQL在运行时InnoDB会在内存中建立缓冲池,用于缓存数据及索引。
2.MyIsam MyIsam引擎是MySQL主流引擎之一,但它相比起InnoDB,没有提供对数据库事务的支持,不支持细粒度的锁(行锁)及外键,当表Insert与update时需要锁定整个表,因此效率会低一些,在高并发时可能会遇到瓶颈,但MyIsam引擎独立与操作系统,可以在windows及linux上使用。MyIsam极度强调快速读取。
3.Memory
如果需要快速的访问数据,并且这些数据不会被修改,重启以后丢失也没有关系。
使用存在内存中的内容来创建表。每个MEMORY表只实际对应一个磁盘文件。MEMORY类型的表访问非常得快,因为它的数据是放在内存中的,并且默认使用HASH索引。
八:MySQL行级锁、表级锁、页级锁详细介绍。
页级:引擎 BDB。
表级:引擎 MyISAM , 理解为锁住整个表,可以同时读,写不行
行级:引擎 INNODB , 单独的一行记录加锁(行级锁并不是直接锁记录,而是锁索引。索引分为主键索引和非主键索引两种,如果一条sql 语句操作了主键索引,Mysql 就会锁定这条主键索引;如果一条语句操作了非主键索引,MySQL会先锁定该非主键索引,再锁定相关的主键索引。)
上述三种锁的特性可大致归纳如下:
1) 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
2) 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
3) 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
MySQL表级锁有两种模式:表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)。什么意思呢,就是说对MyISAM表进行读操作时,它不会阻塞其他用户对同一表的读请求,但会阻塞 对同一表的写操作;而对MyISAM表的写操作,则会阻塞其他用户对同一表的读和写操作。
InnoDB有两种模式的行锁:
1)共享锁:允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
( Select * from table_name where ......lock in share mode)
2)排他锁:允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和 排他写锁。(select * from table_name where.....for update)
为了允许行锁和表锁共存,实现多粒度锁机制;同时还有两种内部使用的意向锁(都是表锁),分别为意向共享锁和意向排他锁。
InnoDB行锁是通过给索引项加锁来实现的,即只有通过索引条件检索数据,InnoDB才使用行级锁,否则将使用表锁!
三: 索引
索引的概念
是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能十分的重要。
索引主要有
普通索引
主键索引
唯一索引
组合索引
(1)为啥索引常用B+树作为底层数据结构 (想一想sql语句一般都有啥功能。)
精确查找 范围查找 排序 。想一想各个数据结构能很好满足这3种情况嘛
(2)除了B+树索引,你还知道什么索引
(3)为啥推荐自增 id 作为主键,自建主键不行吗
(4)什么是页分裂,页合并
(5)怎么根据索引查找行记录
索引的数据结构类型
B+树。
( 题外话:防止原文链接忘记,将会引用大篇幅原文,只供自己学习使用,其他小伙伴可以查看原文学习此处内容)
本文将会从以下几个方面来讲解 B+ 树
- 定义问题
- 几种常见的数据结构对比
- 页分裂与页合并
定义问题
要知道索引底层为啥使用 B+ 树,得看它解决了什么问题,我们可以想想,日常我们用到的比较多的 SQL 有哪些呢。假设我们有一张以下的用户表:
CREATE TABLE `user` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL COMMENT '姓名',
`idcard` varchar(20) DEFAULT NULL COMMENT' 身份证号码',
`age` tinyint(10) DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`id`))
ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息';
一般我们会有如下需求:
1、根据用户 id 查用户信息
select * from user where id = 123;
2、根据区间值来查找用户信息
select * from user where id > 123 and id < 234;
3、按 id 逆序排列,分页取出用户信息
select * from user where id < 1234 order by id desc limit 10;
从以上的几个常用 SQL 我们可以看到索引所用的数据结构必须满足以下三个条件
- 根据某个值精确快速查找
- 根据区间值的上下限来快速查找此区间的数据
- 索引值需要排好序,并支持快速顺序查找和逆序查找
接下来我们以主键索引(id 索引)为例来看看如何用相应的数据结构来构造它
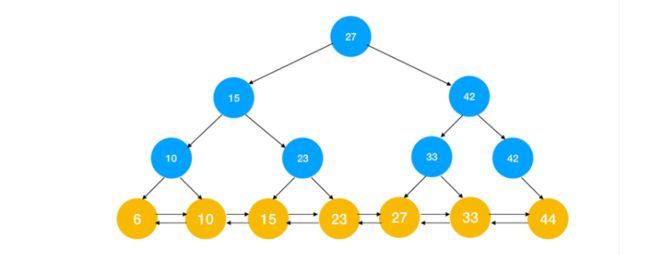
1、散列表(哈希表):(了解,为了引出B+树)
哈希索引:适合-精确查找。只有精确匹配索引所有列的查询才有效。只支持等值查询,不支持任何范围的查找
散列表(也称哈希表)是根据关键码值(Key value)而直接进行访问的数据结构,它让码值经过哈希函数的转换映射到散列表对应的位置上,查找效率非常高。哈希索引就是基于散列表实现的。
假设我们对名字建立了哈希索引,则查找过程如下图所示:

对于每一行数据,存储引擎都会对所有的索引列(上图中的 name 列)计算一个哈希码(上图散列表的位置),散列表里的每个元素指向数据行的指针,由于索引自身只存储对应的哈希值,所以索引的结构十分紧凑,这让哈希索引查找速度非常快!
但是哈希索引也有它的劣势,如下:
针对哈希索引,只有精确匹配索引所有列的查询才有效,比如我在列(A,B)上建立了哈希索引,如果只查询数据列 A,则无法使用该索引。哈希索引并不是按照索引值顺序存储的,所以也就无法用于排序,也就是说无法根据区间快速查找哈希索引只包含哈希值和行指针,不存储字段值,所以不能使用索引中的值来避免读取行。不过,由于哈希索引多数是在内存中完成的,大部分情况下这一点不是问题哈希索引只支持等值比较查询,包括 =,IN(),不支持任何范围的查找。如 age > 17
综上所述,哈希索引只适用于特定场合, 如果用得对,确实能再带来很大的性能提升,如在 InnoDB 引擎中,有一种特殊的功能叫「自适应哈希索引」,如果 InnoDB 注意到某些索引列值被频繁使用时,它会在内存基于 B+ 树索引之上再创建一个哈希索引,这样就能让 B+树也具有哈希索引的优点,比如快速的哈希查找。
2、链表(了解,为了引出B+树)
双向链表支持顺序查找和逆序查找,如图下

但显然不支持我们说的按某个值或区间的快速查找,另外我们知道表中的数据是要不断增加的,索引也是要及时插入更新的,链表显然也不支持数据的快速插入,所以能否在链表的基础上改造一下,让它支持快速查找,更新,删除。
- B+树
只有叶子节点存储数据,非叶子节点存储索引。数据已经按照一定规则进行排序,并且是一个双向链表。满足了快速查找值,区间,顺序逆序查找。
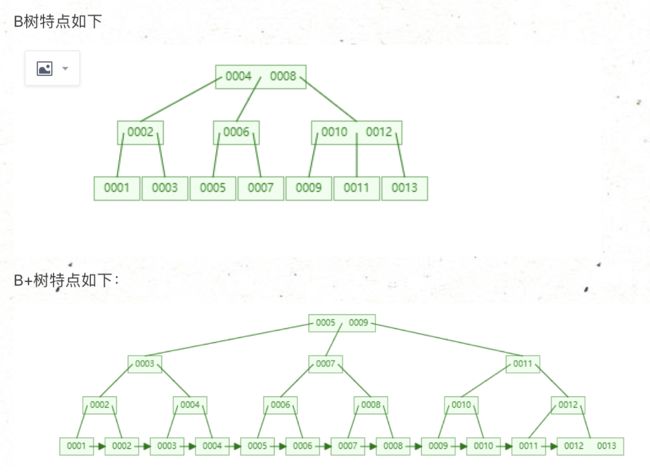
可以看到,非叶子节点只存了索引值,只在最后一行才存放了行记录,这样极大地减小了索引了大小,而且只要找到索引值就找到了行记录,也提升了效率,
这种在叶节点存放一整行记录的索引被称为聚簇索引,其他的就称为非聚簇索引。
参考博文:https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_10113899188833731188%22%7D&n_type=0&p_from=1
mysql页的概念参考
https://segmentfault.com/a/1190000008545713
什么情况下会引起索引失效问题。
前提:假如联合索引a b c 根据(abc)(ab) (ac) (bc) (ba)会使用到索引吗?
答: 条件中一定要出现a (abc ab / ac--会使用到a索引 /ba会使用到索引(sql语句会将其优化为ab))
1.索引的最左前缀匹配原则,非常重要的匹配原则。
create index ix_name_email on s1(name,email,)
(1) 最左前缀匹配:
必须按照从左到右的顺序匹配
可以命中索引 select * from s1 where name='egon';
select * from s1 where name='egon' and email='asdf';
不可以命中索引 select * from s1 where email='[email protected]';
(2)=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器 会帮你优化成索引可以识别的形式。但是也要遵循最左匹配原则,比如b,c就不能匹配索引了.
扩展:索引无法命中的条件需要注意
(1) like '%xx'
建立索引
CREATE INDEX idx_nameAgePos ON staff(name, age, pos);
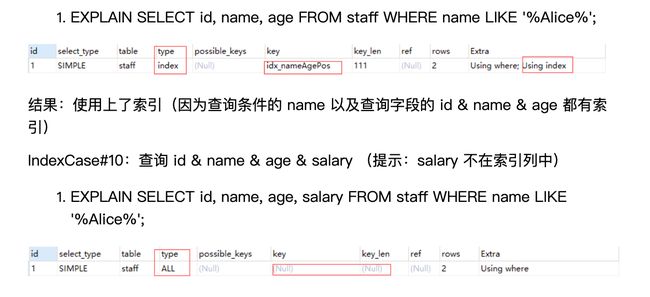
(2)使用函数
(3)or
当or条件中有未建立索引的列才失效
(4) 类型不一致 如果列是字符串类型,传入条件是必须用引号引起来,不然不会走索引
(5) -order by 排序条件为索引,则select字段必须也是索引字段,否则无法命中
当根据索引排序时候,select查询的字段如果不是索引,则不走索引
--不走索引
select name from s1 order by email desc;
--走索引
select email from s1 order by email desc;
特别的:如果对主键排序,则还是走索引:
select * from tb1 order by nid desc;
(6)组合索引最左前缀 如果组合索引为:(name,email) name and email -- 使用索引 name -- 使用索引 email -- 不使用索引
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
十一 mysql优化内容 (面试被问到。。。有时间看书将这个知识点补上,然后用到工作中去) 你们平常mysql是怎么进行优化的
https://blog.csdn.net/u013087513/article/details/77899412