数据驱动分析实践六- 预测销量
数据驱动分析实践六
预测销量
在本篇文章之前,我们所有的预测模型都是面对客户的,例如流失率、下一个购买日等。现在我们可以看看宏观层面的事情,看看客户级别的问题是如何影响销量的。
时序预测是机器学习技术的重要组成部分,例如ARIMA(Autoregressive Integrated Moving Average)、SARIMA(Seasonal Autoregressive Integrated Moving-Average ),VAR(Vector Autoregression )。读者可以参见本人关于时序分析的另外几篇文章:
本文中我们将使用较为流行的深度学习时序预测算法LSTM(Long Short-Term Memory ),长短期记忆网络来实践基于销售量的时序预测分析。
销量预测的好处不言而喻,它可以帮助我们建立基准和适合的计划。
这个过程主要历经三个步骤:
- 数据整理和清洗
- 数据平稳化转换
- 建立LSTM模型并加以评估
数据整理和清洗
from __future__ import division
from datetime import datetime, timedelta,date
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings("ignore")
import chart_studio.plotly as py
import plotly.offline as pyoff
import plotly.graph_objs as go
#import Keras
import keras
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
from keras.utils import np_utils
from keras.layers import LSTM
from sklearn.model_selection import KFold, cross_val_score, train_test_split
#initiate plotly
pyoff.init_notebook_mode()
#read the data in csv
df_sales = pd.read_csv('sale_data_train.csv')
#convert date field from string to datetime
df_sales['date'] = pd.to_datetime(df_sales['date'])
#show first 10 rows
df_sales.head(10)
我们的任务是预测月销售量,所以需要聚合成月数据。
#represent month in date field as its first day
df_sales['date'] = df_sales['date'].dt.year.astype('str') + '-' + df_sales['date'].dt.month.astype('str') + '-01'
df_sales['date'] = pd.to_datetime(df_sales['date'])#groupby date and sum the sales
df_sales = df_sales.groupby('date').sales.sum().reset_index()
df_sales.head()
数据转换
为了使我们的预测更加精确和简单,我们将做如下操作:
- 如果数据是非平稳的,就将其转换为平稳的。
- 将时序转换为可监督的
- 缩放数据
平稳化
#plot monthly sales
plot_data = [
go.Scatter(
x=df_sales['date'],
y=df_sales['sales'],
)
]
plot_layout = go.Layout(
title='Montly Sales'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
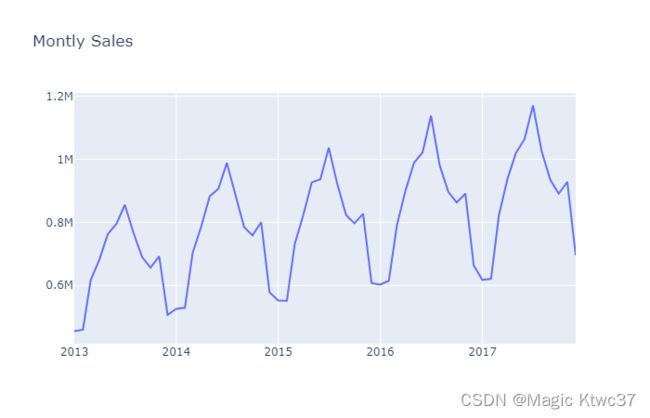
很明显,此数据并非平稳时序,每月的上涨趋势十分显著。我们将采用一阶差分使其平稳化。
#create a new dataframe to model the difference
df_diff = df_sales.copy()#add previous sales to the next row
df_diff['prev_sales'] = df_diff['sales'].shift(1)#drop the null values and calculate the difference
df_diff = df_diff.dropna()
df_diff['diff'] = (df_diff['sales'] - df_diff['prev_sales'])
df_diff.head(10)

#plot sales diff
plot_data = [
go.Scatter(
x=df_diff['date'],
y=df_diff['diff'],
)
]
plot_layout = go.Layout(
title='Montly Sales Diff'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)

好,现在已经平稳了。我们可以开始构建预测模型所需的特征集了。我们需要用前面月份的销售量数据来预测下一个月的销售量,不同的模型选择的回看期间不同,我们这里使用12个。
#create dataframe for transformation from time series to supervised
df_supervised = df_diff.drop(['prev_sales'],axis=1)#adding lags
for inc in range(1,13):
field_name = 'lag_' + str(inc)
df_supervised[field_name] = df_supervised['diff'].shift(inc)#drop null values
df_supervised = df_supervised.dropna().reset_index(drop=True)
df_supervised.head()

有了特征集以后,我们希望了解一下这些特征是否是有用的。我们可以使用Adjust R-Squared来检查一下。
# Import statsmodels.formula.api
import statsmodels.formula.api as smf# Define the regression formula
model = smf.ols(formula='diff ~ lag_1', data=df_supervised)# Fit the regression
model_fit = model.fit()# Extract the adjusted r-squared
regression_adj_rsq = model_fit.rsquared_adj
print(regression_adj_rsq)
0.02893426930900389
lag_1只能解释3%的波动,我们再看看其他的。
model = smf.ols(formula='diff ~ lag_1+lag_2+lag_3+lag_4+lag_5', data=df_supervised)# Fit the regression
model_fit = model.fit()# Extract the adjusted r-squared
regression_adj_rsq = model_fit.rsquared_adj
print(regression_adj_rsq)
0.4406493613886947
增加更多的lag特征使解释能力提高到44%。
model = smf.ols(formula='diff ~ lag_1+lag_2+lag_3+lag_4+lag_5+lag_6+lag_7+lag_8+lag_9+lag_10+lag_11+lag_12', data=df_supervised)# Fit the regression
model_fit = model.fit()# Extract the adjusted r-squared
regression_adj_rsq = model_fit.rsquared_adj
print(regression_adj_rsq)
0.9795722233296558
哇!这个解释力度使我们对于构建模型充满信心了。
#import MinMaxScaler and create a new dataframe for LSTM model
from sklearn.preprocessing import MinMaxScaler
df_model = df_supervised.drop(['sales','date'],axis=1)#split train and test set
train_set, test_set = df_model[0:-6].values, df_model[-6:].values
#apply Min Max Scaler
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler = scaler.fit(train_set)
# reshape training set
train_set = train_set.reshape(train_set.shape[0], train_set.shape[1])
train_set_scaled = scaler.transform(train_set)# reshape test set
test_set = test_set.reshape(test_set.shape[0], test_set.shape[1])
test_set_scaled = scaler.transform(test_set)
构建LSTM模型
X_train, y_train = train_set_scaled[:, 1:], train_set_scaled[:, 0:1]
X_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test, y_test = test_set_scaled[:, 1:], test_set_scaled[:, 0:1]
X_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1])
model = Sequential()
model.add(LSTM(4, batch_input_shape=(1, X_train.shape[1], X_train.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(X_train, y_train, nb_epoch=100, batch_size=1, verbose=1, shuffle=False)
Use tf.cast instead.
Epoch 1/100
41/41 [] - 1s 26ms/step - loss: 0.2007
Epoch 2/100
41/41 [] - 0s 2ms/step - loss: 0.1417
Epoch 3/100
41/41 [] - 0s 2ms/step - loss: 0.1144
Epoch 4/100
41/41 [] - 0s 2ms/step - loss: 0.1026
Epoch 5/100
41/41 [] - 0s 2ms/step - loss: 0.0953
Epoch 6/100
41/41 [] - 0s 2ms/step - loss: 0.0889
Epoch 7/100
41/41 [] - 0s 1ms/step - loss: 0.0829
Epoch 8/100
41/41 [] - 0s 1ms/step - loss: 0.0771
Epoch 9/100
41/41 [] - ETA: 0s - loss: 0.076 - 0s 1ms/step - loss: 0.0715
Epoch 10/100
41/41 [] - 0s 2ms/step - loss: 0.0663
y_pred = model.predict(X_test,batch_size=1)
看一下结果
y_pred[:5]
array([[ 0.6277616 ],
[-0.48253912],
[-0.3593394 ],
[-0.00751264],
[ 0.22653458]], dtype=float32)
y_test[:5]
array([[ 0.55964922],
[-0.61313659],
[-0.36228353],
[-0.14316792],
[ 0.23779333]])
看上去有些相似,但是不能告诉我们有多精确。我们需要对数据进行反缩放。
#reshape y_pred
y_pred = y_pred.reshape(y_pred.shape[0], 1, y_pred.shape[1])#rebuild test set for inverse transform
pred_test_set = []
for index in range(0,len(y_pred)):
print(np.concatenate([y_pred[index],X_test[index]],axis=1))
pred_test_set.append(np.concatenate([y_pred[index],X_test[index]],axis=1))#reshape pred_test_set
pred_test_set = np.array(pred_test_set)
pred_test_set = pred_test_set.reshape(pred_test_set.shape[0], pred_test_set.shape[2])#inverse transform
pred_test_set_inverted = scaler.inverse_transform(pred_test_set)
[[ 0.6277616 0.26695937 0.44344626 0.60355899 1.10628178 0.13866328
-0.10745675 -1.02635392 0.24535439 -0.05787474 -0.31370458 -0.67437352
0.68397168]]
[[-0.48253912 0.55964922 0.26695937 0.44344626 0.68877355 1.10628178
0.13866328 -0.12204966 -1.02635392 0.24535439 -0.05787474 -0.31370458
-0.67437352]]
[[-0.35933939 -0.61313659 0.55964922 0.26695937 0.52015228 0.68877355
1.10628178 0.12731349 -0.12204966 -1.02635392 0.24535439 -0.05787474
-0.31370458]]
[[-0.00751264 -0.36228353 -0.61313659 0.55964922 0.33428672 0.52015228
0.68877355 1.10768225 0.12731349 -0.12204966 -1.02635392 0.24535439
-0.05787474]]
[[ 0.22653458 -0.14316792 -0.36228353 -0.61313659 0.64253037 0.33428672
0.52015228 0.68467253 1.10768225 0.12731349 -0.12204966 -1.02635392
0.24535439]]
[[-1.02220893 0.23779333 -0.14316792 -0.36228353 -0.59257833 0.64253037
0.33428672 0.51382935 0.68467253 1.10768225 0.12731349 -0.12204966
-1.02635392]]
# create dataframe that shows the predicted sales
result_list = []
sales_dates = list(df_sales[-7:].date)
act_sales = list(df_sales[-7:].sales)
for index in range(0,len(pred_test_set_inverted)):
result_dict = {}
result_dict['pred_value'] = int(pred_test_set_inverted[index][0] + act_sales[index])
result_dict['date'] = sales_dates[index+1]
result_list.append(result_dict)
df_result = pd.DataFrame(result_list)
df_result.head()
画图把预测数据和真实数据比较一下
#merge with actual sales dataframe
df_sales_pred = pd.merge(df_sales,df_result,on='date',how='left')#plot actual and predicted
plot_data = [
go.Scatter(
x=df_sales_pred['date'],
y=df_sales_pred['sales'],
name='actual'
),
go.Scatter(
x=df_sales_pred['date'],
y=df_sales_pred['pred_value'],
name='predicted'
)
]
plot_layout = go.Layout(
title='Sales Prediction'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
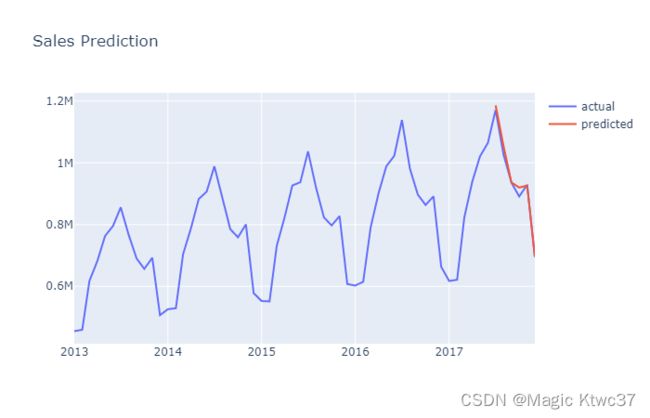
这个简单的模型看上去取得了非常不错的效果。如果想要进一步改善这个模型,可以考虑增加假日、断点和其他季节性影响因素作为特征。
通过这个模型,我们有了我们的预测基准线,但是我们如何预测销售量提升的效果呢,这将会在下一篇文章讨论。
未完待续,…