python之理解排序
排序是以某种顺序从集合中存放元素的过程。例如,单词列表可以按字母顺序或按长度排序。城市列表可以按人口或邮政编码排序。在前面的理解搜索可以看出能够从排序列表中获益的算法(之前的二分查找)。
有许多开发和分析的排序算法。排序算法的效率与正在处理的项的数量有关,对于小集合,复杂的排序算法可能会更麻烦,开销太高。而对大的集合,则希望有更多可能的改进。
在分析特定的算法之前,我们应该考虑可用于算法分析的操作。首先,必须分析两个值之间的大小,然后是当值相对于彼此不在正确的位置时,还要去交换他们,这种交换是一种昂贵的操作,并且交换的总数对于评估算法的整体效率也是很重要。
1、冒泡排序
1.1 冒泡排序
冒泡排序需要更多次的遍历列表,它比较相邻的项并交换那些无序的项。每次遍历将下一个最大的值放在正确的位置。实际效果就是,每个项冒泡到正确的位置。
每次循环原作步骤:
- 1、比较相邻的元素,如果第一个比第二个大,就交换他们两个。
- 2、对每一对相邻元素做同样的工作,从开始第一对到结尾的的最后一对。最后的元素即为最大的数了。
- 3、重复循环。
一次循环图解:
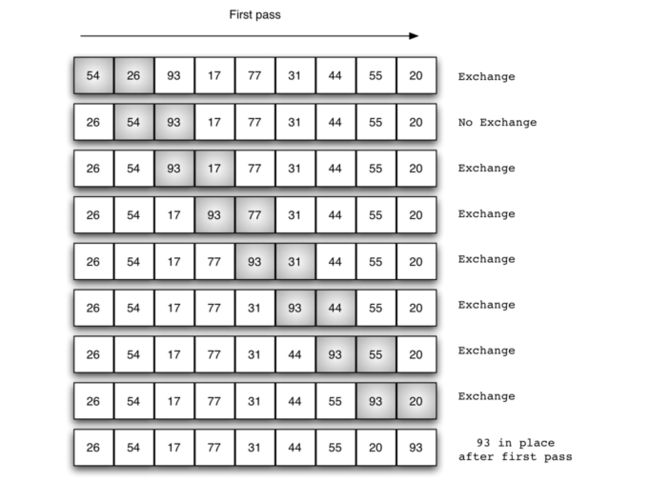
在第二次遍历的时候,最大的值已经出现在最大的位置。有n-1项等待着再次排序,即有n-2对需要相互比较。由于每次通过将下一个最大值放在合适的位置,所需遍历的总数将是n-1。在完成n-1编比较交换之后,最小(大)的项肯定在正确的位置,下一次循环中不需要进一步的处理。
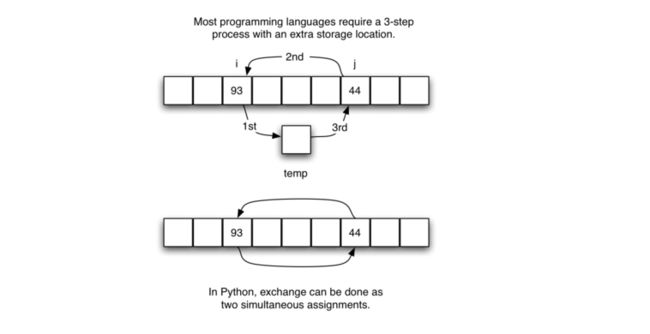
两个项的交换,在各门语言中通用如下:
temp = alist[i]
alist[i] = alist[j]
alist[j] = temp
借助一个中间变量,将列表中的第i项和第j项交换。在python中更简洁的编写方式,称为同时分配的赋值语句:
alist[i], alist[j] = alist[j], alist[i]
代码编写:
def bubble_sort(alist):
print(alist)
list_length = len(alist)
while list_length > 0:
for i in range(list_length-1):
if alist[i] > alist[i+1]:
# temp = alist[i]
# alist[i] = alist[i+1]
# alist[i+1] = temp
alist[i], alist[i+1] = alist[i+1], alist[i]
list_length = list_length - 1
print(alist)
bubble_sort([20, 30, 40, 90, 50, 60, 70, 80, 100, 110])
for循环版本:
def bubble_sort(alist):
print(alist)
list_length = len(alist)
for i in range(list_length-1):
for j in range(list_length-i-1):
if alist[i] > alist[i+1]:
alist[i], alist[i+1] = alist[i+1], alist[i]
print(alist)
bubble_sort([20, 30, 40, 90, 50, 60, 70, 80, 100, 110])
结果:
[20, 30, 40, 90, 50, 60, 70, 80, 100, 110]
[20, 30, 40, 50, 60, 70, 80, 90, 100, 110]
1.2 分析冒泡
分析冒泡,我们可以注意到,初始列表总是在第一次进行n-1次的遍历以排序大小为n的列表。每次循环之后,将产生一个已经排序好的项在正确的位置,即在下一次循环时,将减少一次待比较的项,总的次数如下:

比较的总数为n-1个整数的和,为T(n)=1/2n^2-1/2n,T(n)为执行时间,n为问题的规模。当随着n增加,T(n)变化最快的部分为n2,那么`O(f(n))=O(n^2)`,O(n)为数量级。即这样看来这仍旧是O(n2)比较。在最好的情况下,如果列表已经排序,则不会进行交换,但是最坏的情况下,每次都会导致交换元素。平均来说,我们交换了一般时间。
冒泡排序通常被认为是最低效的排序方法,因为它必须在最终位置被知道交换项。这些浪费的交换操作是非常昂贵的。然而,因为冒泡排序遍历列表的整个未排序的部分,它有能力做大多数排序算法不能做的事情。特别地,如果遍历期间没有交换,则我们知道该列表已排序。如果发现列表已经排序,可以修改冒泡排序提前停止。这意味着对于只需要遍历几次列表,冒泡排序具有识别排序列表和停止的优点。这种常称为短冒泡。
def bubble_sort(alist):
print(alist)
list_length = len(alist) - 1
besorted = True
while list_length > 0 and besorted:
besorted = False
for i in range(list_length):
if alist[i] > alist[i+1]:
besorted = True
alist[i], alist[i + 1] = alist[i + 1], alist[i]
list_length = list_length - 1
print(alist)
bubble_sort([20, 30, 40, 90, 50, 60, 70, 80, 100, 110])
结果:
[20, 30, 40, 90, 50, 60, 70, 80, 100, 110]
[20, 30, 40, 50, 60, 70, 80, 90, 100, 110]
2、选择排序
2.1 选择排序
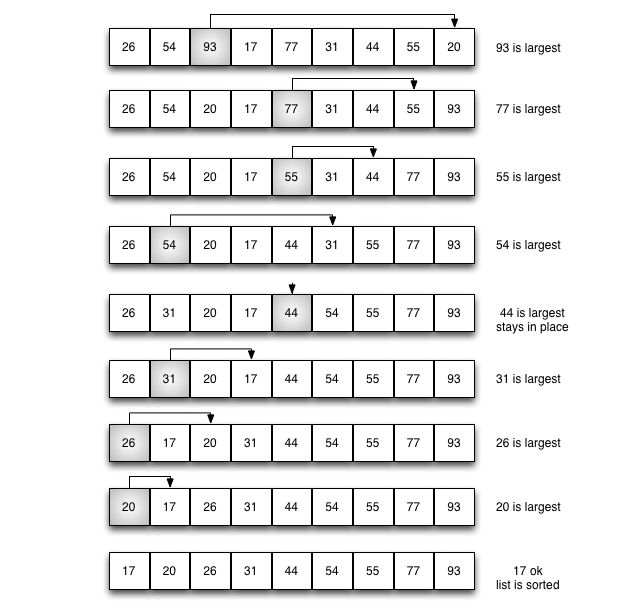
选择排序改进了冒泡排序,其机理是每次只进行一次遍历。为了做到这一点,一个选择排序在它遍历时寻找最大的值,并在完成遍历后,将其放在正确的位置。与冒泡排序一样,在第一次遍历之后,最大的项在正确的位置。第二遍之后,下一个最大的就位,遍历n-1次后排序n个项,因为最终项必须在n-1次遍历之后。
下图展示整个排序的过程:
代码:
def choose_sort(alist):
print(alist)
list_length = len(alist) - 1
for slotindex in range(list_length, 0, -1):
maxindex = 0
# 计数到 stop 结束,但不包括 stop
for next_index in range(1, slotindex+1):
if alist[next_index] > alist[maxindex]:
maxindex = next_index
alist[slotindex], alist[maxindex] = alist[maxindex], alist[slotindex]
print(alist)
choose_sort([54, 26, 93, 17, 77, 31, 44, 55, 20])
结果:
[54, 26, 93, 17, 77, 31, 44, 55, 20]
[17, 20, 26, 31, 44, 54, 55, 77, 93]
你可能会看到选择排序与冒泡排序有相同数量的比较,因此也是O(n^2)。然而,由于交换数量的减少,选择排序通常在基准研究中执行的更快。事实上,对上面的列表,冒泡排序执行了20次,选择排序执行了8次。
3、插入排序
插入排序是一种简单直观的排序算法。它们的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应的位置插入。插入排序在实现上,在从后向前扫描过程中,需要反复把已排序的元素逐步向后挪位,为最新元素提供插入空间。
插入排序,尽管它的数量级仍旧是o(n^2),但它的工作机理又有些变化。它在列表的较低位置维护一个排序的子列表。然后将每个新项插入到先前的子列表,使得排序的子列表称为一个较大的项。如下图:
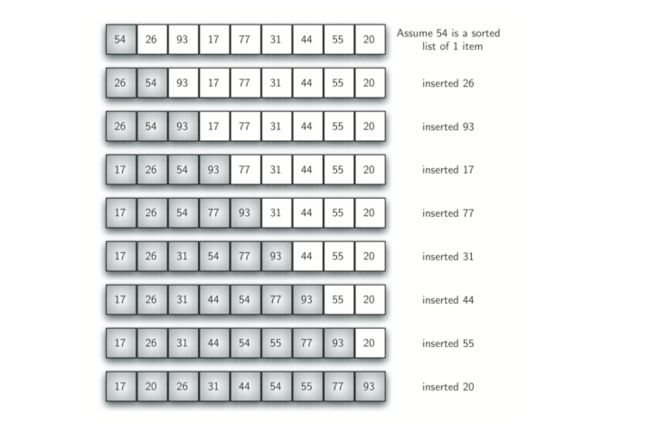
我们假设有一个项(位置0)的列表已经被排序。在每次遍历的时候,对于每个项1至n-1,将针对已排序的子列表中的项检查当前项。当我们回顾已经排序的子列表时,我们将那些更大的项移动到右边。当我们到达较小的项或子列表的末尾时,可以插入当前项。
下图详细展示了第5次遍历,在该算法的第一点,存在由17,26,54,77,93组成的五个项的子列表。当我们插入31到已排序的项。第一次与93比较导致93右移位。同理,77和53右移位。遇到26时,移动过程停止,并且31被放置在开放位置。即我们拥有6个项的排序子列表。

def insert_sort(alist):
print(alist)
list_length = len(alist)
for index in range(1, list_length):
current_pos = index
current_value = alist[index]
while current_pos > 0 and alist[current_pos-1] > current_value:
alist[current_pos] = alist[current_pos-1]
current_pos = current_pos - 1
alist[current_pos] = current_value
print(alist)
insert_sort([54, 26, 93, 17, 77, 31, 44, 55, 20])
结果:
[54, 26, 93, 17, 77, 31, 44, 55, 20]
[17, 20, 26, 31, 44, 54, 55, 77, 93]
4、希尔排序
4.1 希尔排序
希尔排序,有时被称为递增递减排序,它通过将原始列表分为较多的子列表来改进插入排序,每个子列表又使用插入排序进行排序。选择这些子列表的方式是希尔排序的关键。不是将列表拆分为连续项的子列表,希尔排序使用增量i(有时称为gap),通过选择i个项的所有项来创建子列表。
可以在下图中看到,该列表有9个项,如果我们使用3的增量,有三个子列表,每个子列表可以通过插入排序进行排序。完成这些排序之后,我们会得到一个新列表,虽然这个列表没有完全排序,但通过排序子列表,我们已将项目移动到了更接近他们实际的位置。

下图又展示了一个增量为1的希尔排序,即标准插入排序。注意,通过执行之前的子列表排序,我们减少了将列表置于其最终顺序所需的移位操作,对于这种情况,我们只需要进行4次操作即可完成该过程。
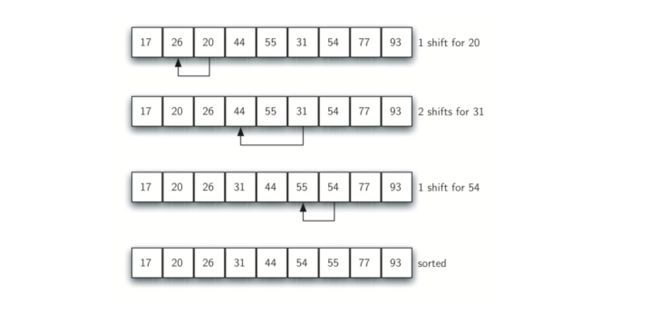
4.2 希尔排序过程
希尔排序的基本思想是将列表列在一个子列表中,并分别对其进行插入排序,不断重复这一过程,改变的是每个增量步长去进行。
下面假设一个列表 [13, 14, 94, 33, 82, 25, 59, 94, 65, 23, 45, 27, 73, 25, 39, 10],假如我们以增量步长为5进行排序,我们可以通过将这列表有5列的表中来更好的进行排序,即这个样子:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10
然后插入排序对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45
上面这些项进行拼接成新的列表[10, 14, 73, 25, 23, 13, 27, 94, 33, 39, 25, 59, 94, 65, 82, 45]。下面再已增量步长为3进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45
插入排序之后:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94
反复循环,之后增量步长为1,即一次完整的插入排序。
4.3 希尔排序实现
def shell_sort(alist):
n = len(alist)
# 初始步长
gap = n // 2
while gap > 0:
for startpos in range(gap):
insert_sort(alist, startpos, gap)
print("After increments of size", gap, "The list is", alist)
gap = gap // 2
def insert_sort(sublist, startpos, gap):
for index in range(startpos+gap, len(sublist), gap):
curr_pos = index
curr_value = sublist[index]
while curr_pos > 0 and sublist[curr_pos-gap] > curr_value:
sublist[curr_pos] = sublist[curr_pos-gap]
curr_pos = curr_pos-gap
sublist[curr_pos] = curr_value
print(startpos, gap, sublist)
结果:
0 4 [20, 26, 93, 17, 54, 31, 44, 55, 77]
1 4 [20, 26, 93, 17, 54, 31, 44, 55, 77]
2 4 [20, 26, 55, 17, 54, 31, 93, 44, 77]
3 4 [20, 26, 55, 17, 54, 31, 93, 44, 77]
After increments of size 4 The list is [20, 26, 55, 17, 54, 31, 93, 44, 77]
0 2 [20, 26, 54, 17, 55, 31, 77, 44, 93]
1 2 [20, 93, 54, 26, 55, 31, 77, 44, 17]
After increments of size 2 The list is [20, 93, 54, 26, 55, 31, 77, 44, 17]
0 1 [17, 20, 26, 31, 44, 54, 55, 77, 93]
After increments of size 1 The list is [17, 20, 26, 31, 44, 54, 55, 77, 93]
咋一看,可能会觉着希尔排序不会比插入排序更好,因为它最后一步执行了完整的插入排序。然而结果是,该最终插入排序不需要进行更多的比较或移位,该列表已经被较早的增量插入排序预排序。即每个遍历产生比之前一个更有序的列表。这使得最终遍历非常有效。
希尔排序最终的时间复杂度落在O(n)和O(n^2)之间的某处,但这个稳定性无法评估。
5、归并排序
5.1 归并排序
我们再将注意力转向使用分而治之的策略,下面学习的是归并排序。它是一种递归算法,不断地将列表拆分为一半。如果列表为空或是有一个项,则按定义(基本情况)进行排序。如果列表有多个项,我们分割列表,并递归调用两个半部分的合并排序。一旦对这两半排序完成,就执行称为合并的基本操作。合并是获取两个较小的排列列表并将它们组合为单个排序的新列表的过程。
基本操作过程如下图:

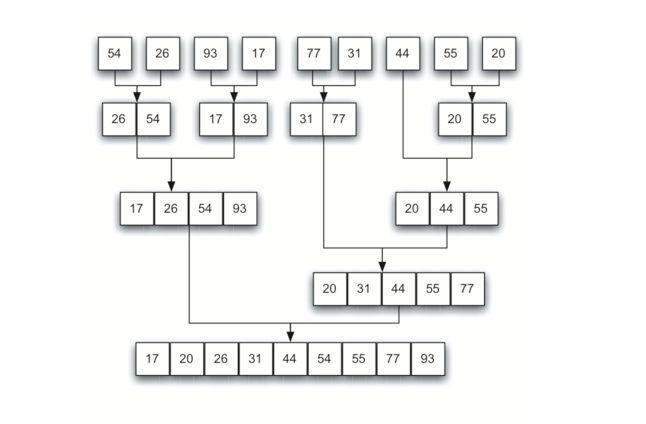
5.2 归并实现
def merge_sort(alist):
if len(alist) <= 1:
return alist
# 二分分解
print(alist)
num = len(alist)//2
print(num)
left = merge_sort(alist[:num])
print(left)
right = merge_sort(alist[num:])
print(right)
# 合并
return merge(left, right)
def merge(left, right):
# left与right的下标指针
l, r = 0, 0
result = []
while l < len(left) and r < len(right):
if left[l] < right[r]:
result.append(left[l])
l += 1
else:
result.append(right[r])
r += 1
result += left[l:]
result += right[r:]
return result
alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]
sorted_alist = merge_sort(alist)
print(sorted_alist)
结果:
[54, 26, 93, 17, 77, 31, 44, 55, 20]
4
[54, 26, 93, 17]
2
[54, 26]
1
[54]
[26]
[26, 54]
[93, 17]
1
[93]
[17]
[17, 93]
[17, 26, 54, 93]
[77, 31, 44, 55, 20]
2
[77, 31]
1
[77]
[31]
[31, 77]
[44, 55, 20]
1
[44]
[55, 20]
1
[55]
[20]
[20, 55]
[20, 44, 55]
[20, 31, 44, 55, 77]
[17, 20, 26, 31, 44, 54, 55, 77, 93]
上面可以看出,一旦左半部分和右半部分上调用merge_sort函数,就假定它们已经被排序。merge函数负责将两个较小的排序列表合并成一个较大的排序列表。这里注意它的实现是通过循环从排序列表中找出最小的项目,产生一个排序后的新列表后返回。
为了分析归并排序,我们需要考虑组成其实现的两个不同的过程。首先,列表被分为两半。我们已经计算过(搜索 - 二分查找)将列表划分为一半需要log^n次,其中n是列表的长度。第二个过程是合并。列表中的每个项最终被处理并放置在排序的列表上。即大小为n的列表的合并需要n个操作。此结果分析是log^n的 拆分,其中每个操作花费n,总共nlog^n,即归并排序是O(nlog^n)的算法。
6、快速排序
6.1 快速排序
快速排序又称为划分交换排序,通过一次排序将要排序的数据通过分割点分割成两个独立的部分,其中左半部分的数据都比分割点项小,另右半部分的数据都比分割点数据大。
排序算法使用分而治之来获得与归并排序相同的有点,而不适用额外的存储。然而,作为权衡,有可能列表不能被分为两半。当这种情况发生,我们将看到性能下降。
以下是一般的操作步骤:
- 从列表中挑出一个数,称为
枢轴值(基准值),通常直接用第一个项了。 - 重新排列列表,所有元素比基准值小的放在基准值前面,大的放在基准值后面。分区结束之后,该基准值就处于两个子列表的中间。
- 两个子列表分别递归进行快速排序。
下面将列出利用列表[54, 26, 93, 17, 77, 31, 44, 55, 20]进行快速排序。
利用首项54作为第一个基准值。分区将在列表中剩余数据项的开始和结束两个特定位置标记(我们称之为左标记与右标记)开始(下图中的1和8)。分区的目标是移动相对于基准值位于错误测的项,同时也收敛于基准值。

我们先增加左标记,知道我们找到一个大于基准值的值。然后我们递减右标,知道我们找到小于基准值的值。我们找到两个相对于最终分列点位置不适当的项。对上面的例子,这发生在93和20,然后我们交换这连个项目,递归重复这一过程。
递归下去最终的结果是在右标记变得小于左标记的点,我们停止。右标记的位置现在即时分割点(拆分点)。基准值可以与拆分点的拆分点交换,交换后分割点就位。分割点左右的所有项都小于基准值,后侧所有项都大于基准值。现在以分割点划分列表,可以在两半子列表上递归调用快速排序。
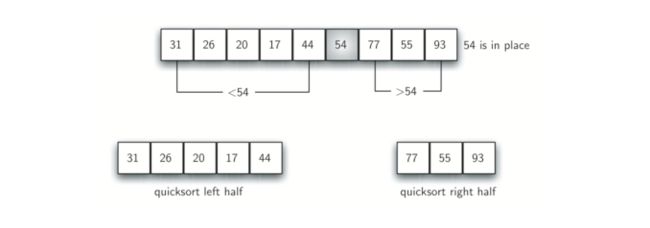
6.2 快速排序实现
def quick_sort(alist):
quick_sort_helper(alist, 0, len(alist)-1)
def quick_sort_helper(alist, first, last):
if first < last:
split_point = partition(alist, first, last)
quick_sort_helper(alist, first, split_point-1)
quick_sort_helper(alist, split_point+1, last)
def partition(alist, first, last):
pivot_value = alist[first]
leftmark = first + 1
rightmark = last
done = False
while not done:
while leftmark <= rightmark and alist[leftmark] <= pivot_value:
leftmark = leftmark + 1
while rightmark >= leftmark and alist[rightmark] >= pivot_value:
rightmark = rightmark - 1
if rightmark < leftmark:
done = True
else:
alist[leftmark], alist[rightmark] = alist[rightmark], alist[leftmark]
alist[rightmark], alist[first] = alist[first], alist[rightmark]
return rightmark
alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]
quick_sort(alist)
print(alist)
结果:
[17, 20, 26, 31, 44, 54, 55, 77, 93]
印证列表是可变的。
6.3 快速排序性能
对于长度为n的列表,如果分区总是出现在列表中间,则会再次出现logn分区。为了找到分割点,需要针对基准值查n个项的每一个。结果是nlogn。此外,在快速排序过程中不需要额外的存储器。
然而在最坏的情况下,分列点可能不再中间,并且可能非常偏向左边或右边,留下非常不均匀的分割。这种情况下,对n个项的列表进行排序划分为对0个项的列表和n-1个项的列表进行排序。然后将n-1个划分的列表排序为大小为0的列表和大小为n-2的列表,结果是递归所需的所有开销O(n)排序。
7 感谢
全文学习使用。
原文地址:排序与搜索