大数据集群环境搭建详细步骤,涉及zookeeper,hadoop,hive,hbase,kafka
背景
公司需要搭建一套大数据集群环境用于测试,本文记录其详细过程,方便后面参考
环境信息
一主两从,均为ubuntu18.04
主:192.168.10.203(mufengcn)
从:192.168.10.202(mufengcn),192.168.10.200(tsroot)
注:假定括号内为ssh用户名,均为非root用户名(真实服务器,文中涉及到的用户名图文是不对应的,我只是把文案中涉及到的用户名批量替换了下~)
准备
设置主机名及配置hosts
依次设置主机名,如:
sudo hostname bigdata203
sudo vi /etc/hostname

三台机器分别配置hosts
vi /etc/hosts
192.168.10.203 bigdata203
192.168.10.200 bigdata200
192.168.10.202 bigdata202

时间同步
设置相同时区:ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
同步时间:
参考连接:https://blog.csdn.net/vic_qxz/article/details/80344855
大概意思是,将一台服务器作为时间同步服务器,另外两台作为客户端直接同步。
-
将192.168.10.200作为时间同步服务器
安装ntp: sudo apt-get install ntp 启动ntp: /etc/init.d/ntp start验证启动成功:

-
在192.168.10.203和192.168.10.202上安装客户端ntpdate
sudo apt-get install ntpdate手动同步时间测试:
sudo ntpdate 192.168.10.200

-
配置cron任务
确定cron服务正常启动: service cron status

在客户端(192.168.10.203,192.168.10.202)配置定时任务:crontab -e
下面表达式代表:每分钟同步一次时间,并将正确或错误消息输入到/home/mufengcn/ntpdate.log中
* * * * * sudo -n /usr/sbin/ntpdate 192.168.10.200 >>/home/mufengcn/ntpdate.log 2>&1查看当前用户的定时任务:crontab -l
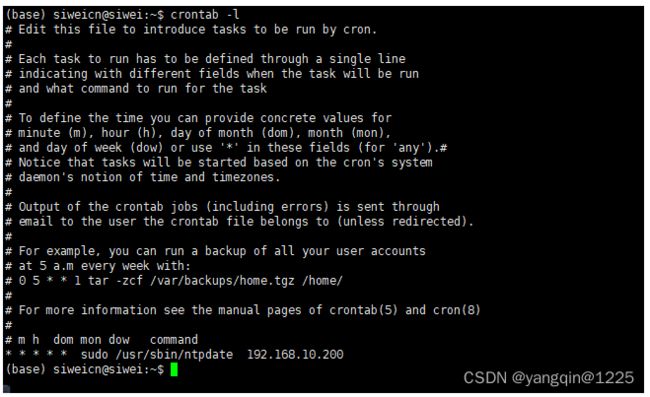
定时任务中需要sudo命令,应该设置免密:
sudo visudo -f /etc/sudoers
Defaults visiblepw
sudo visudo -f /etc/sudoers.d/ntpdate
mufengcn ALL=NOPASSWD: /usr/sbin/ntpdate
mufengcn 为当前所使用的用户名
-
查看定时任务执行情况
开启日志打印:sudo vi /etc/rsyslog.d/50-default.conf
取消注释:

重启:sudo service rsyslog restart
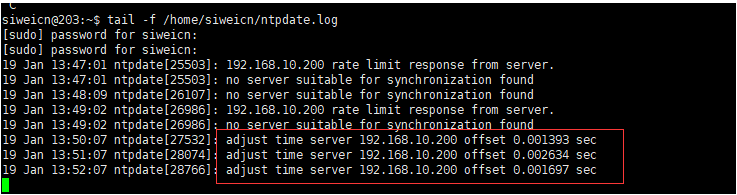
查看定时任务执行情况:tail -f /var/log/cron.log

查看ntpdate结果:tail -f /home/mufengcn/ntpdate.log
常见问题
- 时间同步失败,no server suitable for synchronization found.参考以下连接调试
https://blog.csdn.net/weidan1121/article/details/3953021

- /etc/sudoers一定要用visudo 去修改,因为该工具修改错误时有语法提示。如果不小心用vi将/etc/sudoers修改错了,会导致系统不能使用sudo命令。此时的解决方案参考:
https://baijiahao.baidu.com/s?id=1623745008749543253&wfr=spider&for=pc&isFailFlag=1
关闭防火墙
sudo systemctl stop ufw.service
sudo systemctl disable ufw.service
免密登录
需要主节点向从节点复制东西免密,即将主节点的id_rsa.pub追加到从节点的authorized_keys
在主节点执行:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
把主节点的~/.ssh/authorized_keys拷贝到从节点的 ~/.ssh/authorized_keys即可
常见问题
- 假设bigdata203连不上bigdata200,可以先在bigdata200上调试(即自己连自己):
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh -vvvT bigdata200

如上图所示,使用publickey认证时,正确的结果是:receive packet: type 60
解决方案:在bigdata200机器上执行
sudo chmod o-rwx /home/tsroot/ -R
- 假设bigdata200自身连接没问题,但是bigdata203上连不上bigdata200,那么继续查看调试信息,会发现是因为两台机器用户名不一样。在bigdata203上使用ssh连接bigdata200。默认是使用的当前登录用户名(mufengcn)连接的,而bigdata200没有mufengcn这个用户,所以失败

解决方案:
在bigdata203添加文件~/.ssh/config,配置用户名

hadoop集群安装
地址:http://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/
需提前安装好java,jdk 1.8即可。
架构示意如下:

配置
主节点
hadoop-env.sh
export JAVA_HOME=/home/mufengcn/yangqin/jdk1.8.0_181
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://bigdata203:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/data/hadoop_repovalue>
property>
configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>bigdata203:50090value>
property>
configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>bigdata203value>
property>
configuration>
works
指定从节点信息:
bigdata200
bigdata202
后面两个配置文件修改,应该追加到最前面,方便脚本引用
sbin/start-dfs.sh sbin/stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
sbin/start-yarn.sh sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
从节点
将主节点整个配置拷贝到从节点即可
启动
在三台机机器,配置hadoop环境变量:vi /etc/profile
HADOOP_HOME=/home/mufengcn/yangqin/soft/hadoop-3.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
使环境变量生效: source /etc/profile
主节点运行:
格式化HDFS: hdfs namenode -format
启动: start-all.sh

初次启动失败,可能是目录权限的原因:手工到从节点创建/data/hadoop_repo目录即可,并修改所属组为当前登录用户,如:
sudo mkdir -p /data/hadoop_repo
sudo chown tsroot:tsroot -R /data/hadoop_repo/
验证
主节点查看
jps -m: 可以看到主节点启动了NameNode,SecondaryNameNode,ResourceManager

从节点查看
jps -m: 可以看到从节点只启动了DataNode,NodeManager

前台访问
hdfs: http://bigdata203:9870/

yarn: http://bigdata203:8088/

hive安装
地址: http://archive.apache.org/dist/hive/hive-3.1.2/
Hive相当于Hadoop的客户端工具,安装时不一定非要放在集群的节点中,可以放在任意一个集群客户端节点上都可以,先解压放入到/home/mufengcn/yangqin/soft/apache-hive-3.1.2-bin
配置
cd apache-hive-3.1.2-bin/conf/
mv hive-env.sh.template hive-env.sh
mv hive-default.xml.template hive-site.xml
hive-env.sh
export JAVA_HOME=/home/mufengcn/yangqin/jdk1.8.0_181
export HIVE_HOME=/home/mufengcn/yangqin/soft/apache-hive-3.1.2-bin
export HADOOP_HOME=/home/mufengcn/yangqin/soft/hadoop-3.2.0
hive-site.xml(找到并修改即可)
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://mysqlIp:3306/hive?serverTimezone=Asia/Shanghaivalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.cj.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPastsordname>
<value>adminvalue>
property>
<property>
<name>hive.querylog.locationname>
<value>/data/hive_repo/querylogvalue>
property>
<property>
<name>hive.exec.local.scratchdirname>
<value>/data/hive_repo/scratchdirvalue>
property>
<property>
<name>hive.downloaded.resources.dirname>
<value>/data/hive_repo/resourcesvalue>
property>
在Hadoop的core-site.xml文件中增加下面配置
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
元数据库初始化
将mysql驱动程序放入hive的lib中
bin/schematool -dbType mysql -initSchema
插入数据:

zookeeper集群安装
http://archive.apache.org/dist/zookeeper/zookeeper-3.5.8/
解压放入/home/mufengcn/yangqin/soft/apache-zookeeper-3.5.8
配置
cd apache-zookeeper-3.5.8-bin/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
dataDir=/home/mufengcn/yangqin/soft/apache-zookeeper-3.5.8-bin/data
server.0=bigdata203:2888:3888
server.1=bigdata202:2888:3888
server.2=bigdata200:2888:3888
分别在bigdata200,bigdata202,bigdata203执行:
echo 2 > data/myid
echo 1 > data/myid
echo 0 > data/myid
启动
主从节点分别启动
bin/zkServer.sh start
验证
如果能看到QuorumPeerMain进程就说明zookeeper启动成功
jps
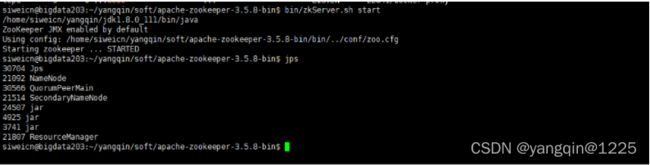
通过zkServer.sh status查看主从节点(leader和follower)

常用命令
进入shell: bin/zkCli.sh
创建test节点,存储hello数据:create /test hello
查看test节点内容: get /test
删除节点: deleteall
kafka安装
http://archive.apache.org/dist/kafka/2.4.1/
注意:由于Kafka需要依赖于Zookeeper,所以在这我们需要先把Zookeeper安装部署起来
解压:

配置
vi server.properties
broker.id=0
log.dirs=/home/mufengcn/yangqin/soft/kafka_2.12-2.4.1/kafka-logs
zookeeper.connect=bigdata203:2181,bigdata202:2181,bigdata200:2181
broker.id的值默认是从0开始的,集群中所有节点的broker.id从0开始递增即可
启动
三台机器依次启动
bin/kafka-server-start.sh -daemon config/server.properties
常用命令
启动:bin/kafka-server-start.sh -daemon config/server.properties
查看topic:bin/kafka-topics.sh --list --zookeeper localhost:2181
生产者:bin/kafka-console-producer.sh --broker-list 192.168.10.203:9092 --topic YQ_Topic
消费者:bin/kafka-console-consumer.sh --bootstrap-server 192.168.10.203:9092 --topic YQ_Topic --from-beginning
hbase集群安装
地址:http://archive.apache.org/dist/hbase/2.2.7/
配置
hbase-env.sh
export JAVA_HOME=/home/mufengcn/yangqin/jdk1.8.0_111
export HADOOP_HOME=/home/mufengcn/yangqin/soft/hadoop-3.2.0
export HBASE_MANAGES_ZK=false
export HBASE_LOG_DIR=/home/mufengcn/yangqin/soft/hbase-2.2.7/logs
hbase-site.xml
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.tmp.dirname>
<value>/home/mufengcn/yangqin/soft/hbase-2.2.7/tmpvalue>
property>
<property>
<name>hbase.unsafe.stream.capability.enforcename>
<value>falsevalue>
property>
<property>
<name>hbase.rootdirname>
<value>hdfs://bigdata203:9000/hbasevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>bigdata203,bigdata202,bigdata200value>
property>
<property>
<name>zookeeper.znode.parentname>
<value>/hbasevalue>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
property>
因为bigdata200的用户为tsroot,bigdata203的用户为mufengcn,所以有可能导致bigdata200没有权限向hadoop目录写入数据而启动失败

关闭权限验证即可
hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>bigdata203:50090value>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
启动
bin/start-hbase.sh
验证
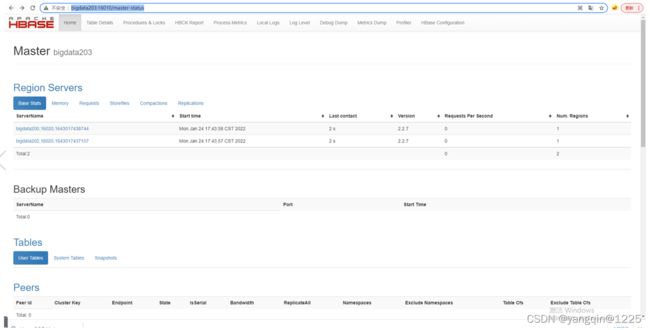
后台查看:hbase shell

前台访问:http://bigdata203:16010/master-status